时隔上一篇技术文章更新差不多有3个星期了,原因的话在上一篇文章中写啦。废话不多说,开始我们的线程池源码的第二轮阅读。
回顾
简单回顾下上一篇线程池源码中涉及的两个方法,一个是execute() 执行任务的入口,还有一个是addWorker() 最通俗地理解就是是否需要添加新线程。而在addWoker() 的末尾有这样一段代码
if (workerAdded) {
t.start();
workerStarted = true;
}
明显地看到这里通过start() 方法开启了多线程,而如果想要看线程的执行逻辑,就需要去到对应类中查看run方法,这里的t就是Worker 类里面的一个成员变量,所以重点要看Worker 类中的run() 方法。
runWorker()
run() 方法的源码如图所示,最后是到了runWorker()

直接来看runWorker的源码
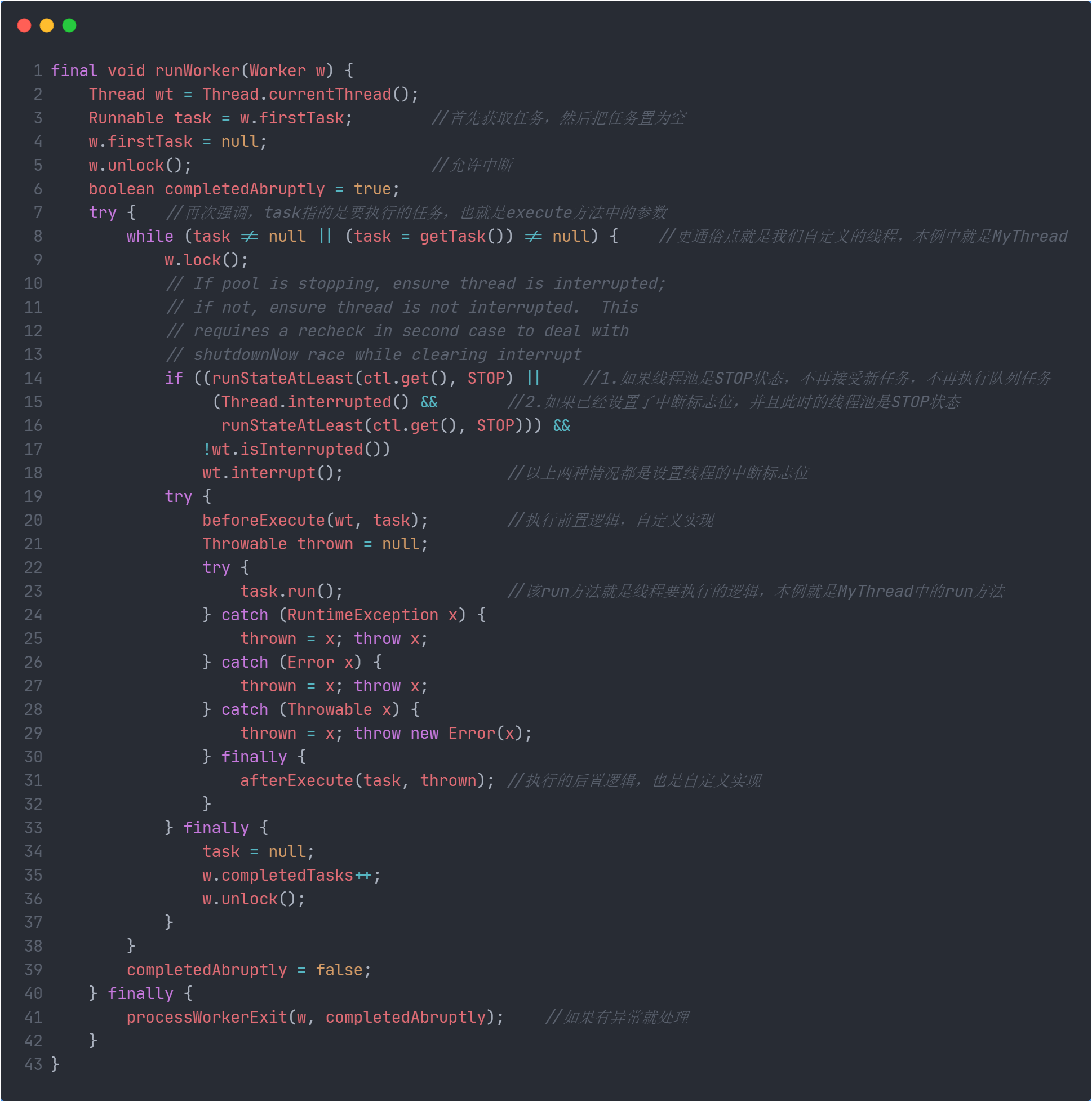
- 开始是一个循环,要么执行worker自带的第一个任务(firstTask),要么通过
getTask()获取任务 - 有任务首先得保证线程池是正常的,以下两种情况均调用
wt.interrupt()给线程设置中断标志位- 线程池处于STOP状态,也就是不接受新任务,也不执行队列中的任务
- 如果线程的标志位已经为true,那么清楚标志位,此时的线程池状态为STOP状态,这里看起来可能比较别扭,有了第一种情况为什么还要第二种,不理解的可以先略过,后面会讲的。
- 正常情况下是调用
beforeExecute()和afterExecute()包裹者task.run()
看一下是如何自定义前置和后置执行逻辑
public class ThreadPoolExamples {
public static void main(String[] args) {
ThreadPoolExecutor executor = new MyThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
MyThread myThread = new MyThread();
executor.execute(myThread);
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " is running");
}
}
class MyThreadPoolExecutor extends ThreadPoolExecutor {
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("【" + Thread.currentThread().getName() + " custom before execute】");
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("【" + Thread.currentThread().getName() + " is done】");
}
MyThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
}
首先就是要创建自己的MyThreadPoolExecutor 类,继承ThreadPoolExecutor ,然后重写beforeExecute() 和afterExecute() 定义自己的逻辑即可,看下测试结果
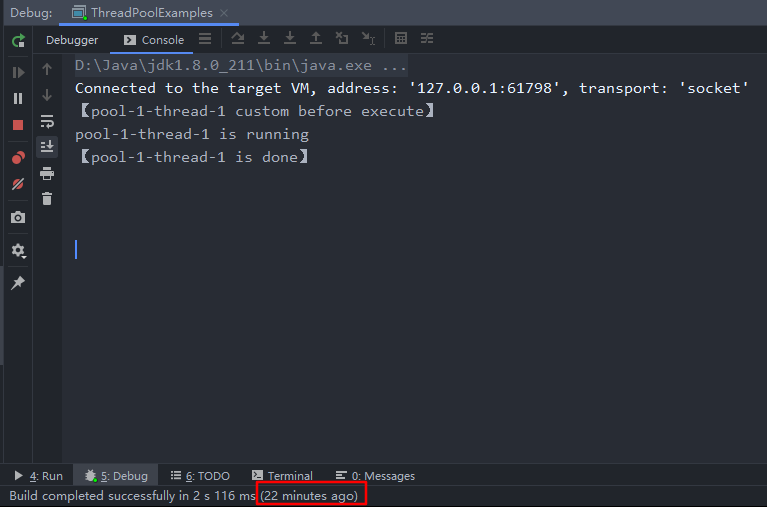
可以看到前置和后置都已经按照既定的逻辑在运行了,有趣的是,22分钟过去了(不要问我为什么这么久,拿外卖吃东西去了)线程池还是没有停,为什么会这样呢。
注意前面分析runWorker() 第一步的时候是一个循环,然后通过firstTask 或者getTask() 获取任务,如果两种方式都获取不到任务,线程池就应该退出,看来奥秘在getTask() 中。
getTask()
主要目的顾名思义就是获取到需要执行的任务,直接看源码
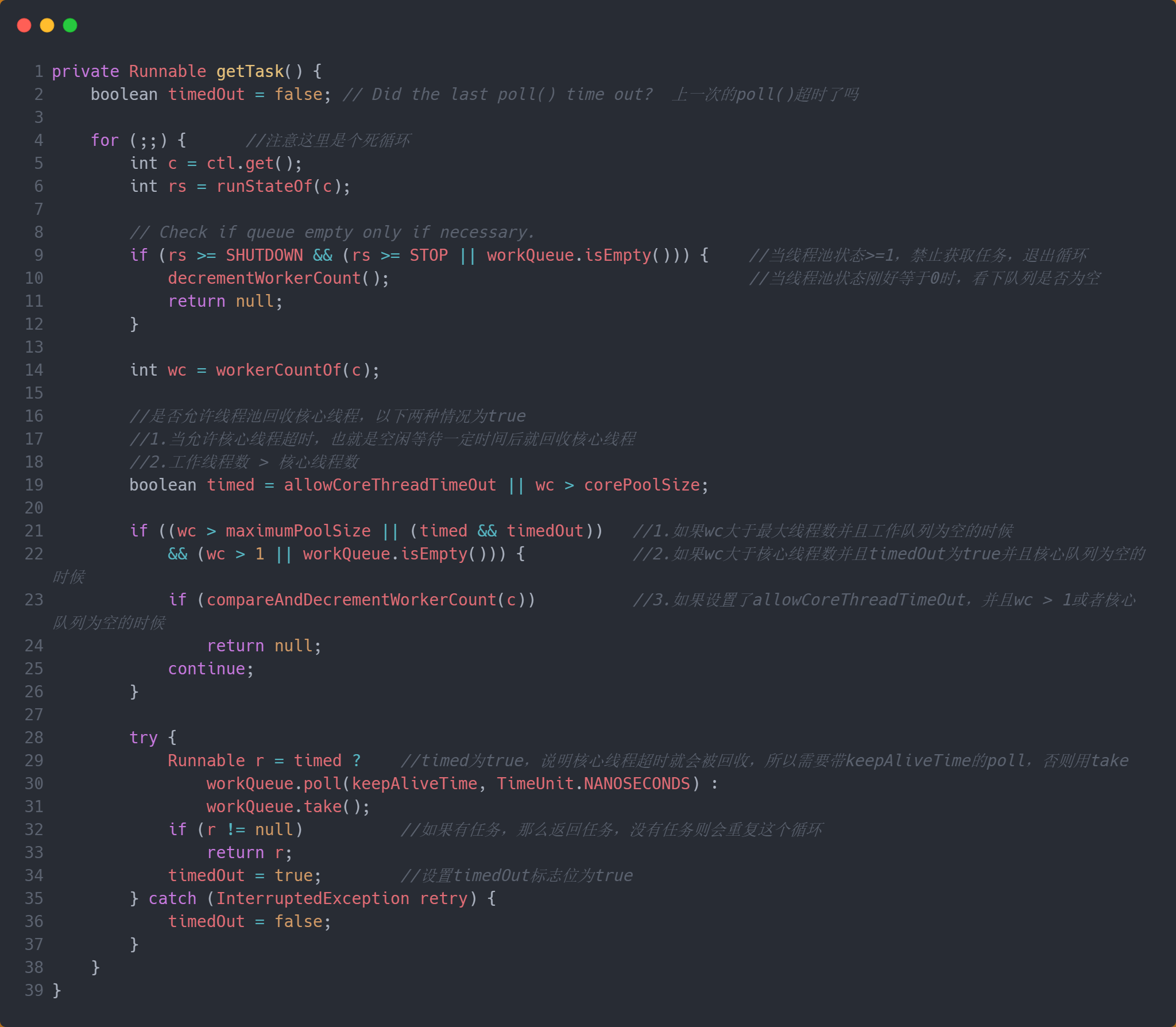
- 一进来也是一个死循环,可以先聚焦什么时候会退出循环,肯定是不正常的情况下会退出
- 当线程池状态不处于RUNNING或者SHUTDOWN的时候,或者是当线程处于SHUTDOWN但是工作队列中没有任务
- 当wc大于最大线程数并且工作队列为空的时候,或者当wc大于核心线程数并且timedOut为true并且核心队列为空的时候,或者如果设置了allowCoreThreadTimeOut,并且wc > 1或者核心队列为空的时候
- 除了不正常的情况,接下来就是从工作队列中获取任务,不过是根据timed的来决定是用
poll()还是take()。 - 如果能取出任务,就直接返回任务;如果没有任务,要么超时设置timedOut为ture,要么是抛出异常重置timedOut为false。
到这里,为什么说线程池能够节省资源呢,是因为其实它创建的线程的消耗只是体现在了Worker类的创建中,把其它要完成的任务放在工作队列里面,然后getTask() 获取任务,最后执行任务(调用task.run())
拒绝策略
这个是在最开始execute() 的时候调用的
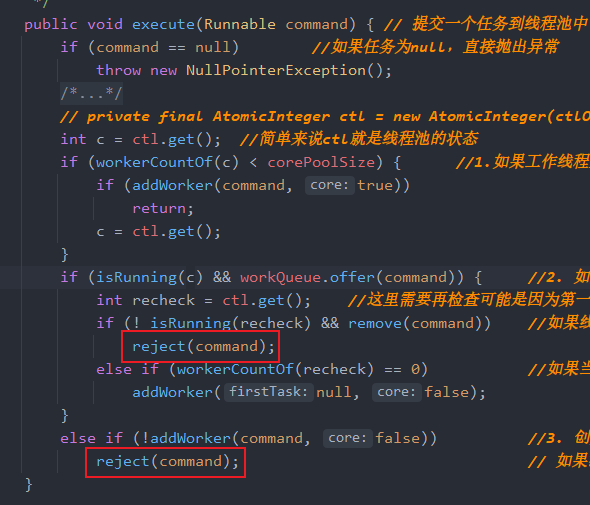
详细是如何请看下面的动图
可以看到,最后是调用了RejectedExecutionHandler 接口中的rejectedExecution(Runnable r, ThreadPoolExecutor executor); 方法,然后默认是有4种实现方式
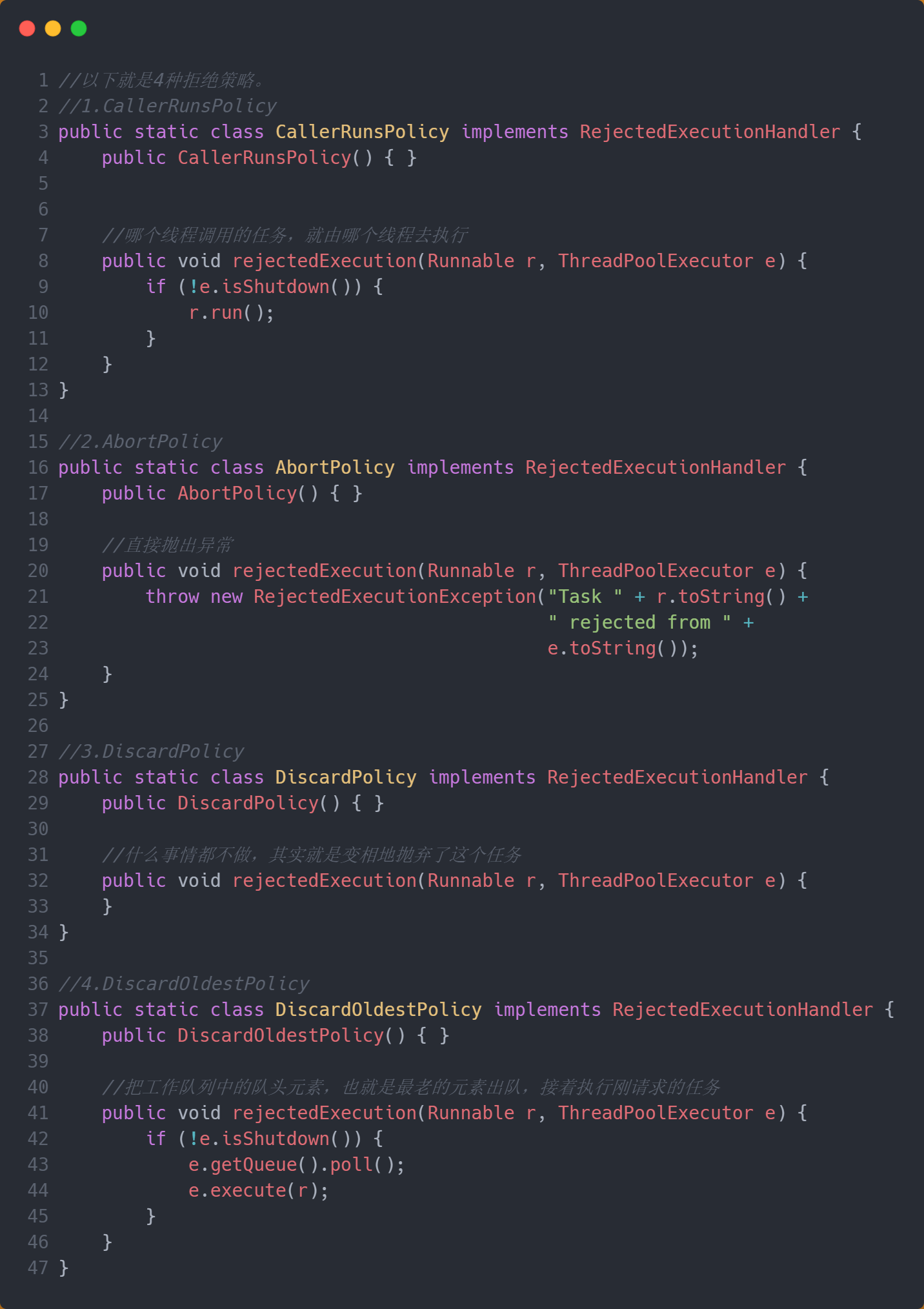
有开放的接口,那肯定是能自定义实现类的
class MyRejectedExecutionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("task is rejected");
}
}
该说的方法也基本都说了,用到的工作队列(BlockingQueue)在后面会另说,下一篇文章就总结下jdk的线程池啦!
创作不易,如果对你有帮助,欢迎点赞,收藏和分享啦!










