基于PaddleSeg的眼底血管分割——使用飞桨助力医学影像分析
一、项目背景
研究表明,各类眼科疾病以及心脑血管疾病会对视网膜血管造成形变、出血等不同程度的影响。随着生活水平的提高,这类疾病的发病率呈现逐年增长的趋势。临床上,医疗人员能够从检眼镜采集的彩色眼底图像中提取视网膜血管,然后通过对血管形态状况的分析达到诊断这类疾病的目的。
但是,由于受眼底图像采集技术的限制,图像中往往存在大量噪声,再加之视网膜血管自身结构复杂多变,使得视网膜血管的分割变得困难重重。
传统方法中依靠人工手动分割视网膜血管,不仅工作量巨大极为耗时,而且受主观因素影响严重。
因此,利用计算机技术,找到一种能够快速、准确分割视网膜血管的算法,实现对眼底图像血管特征的实时提取,对辅助医疗人员诊断眼科疾病、心脑血管疾病等具有重要作用。
二、数据集介绍
本项目使用的数据集照片来自荷兰的糖尿病视网膜病变筛查项目。筛查人群包括400名年龄在25-90岁之间的糖尿病患者。但只有40张照片被选取,其中33张没有显示任何糖尿病视网膜病变的迹象,7张显示轻度早期糖尿病视网膜病变的迹象。
AI Studio上已经有DRIVE糖尿病人眼底血管分割数据集了,但是该数据集的数据量非常少,只有20张训练集。
因此,我在处理数据时做了一些处理来增加我的训练集数据量。
数据集图片格式转换
原数据集里的眼底图像:

原数据集手工分好的的血管图像:
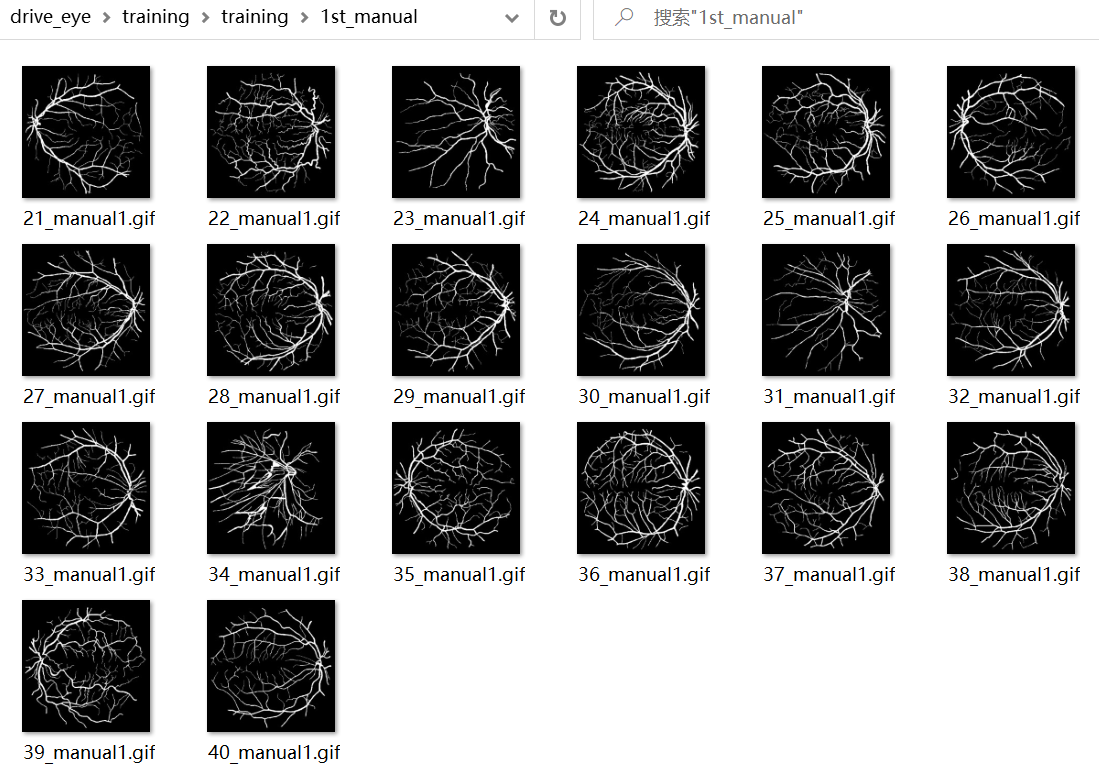
仔细看一下图片格式:
- 眼底图像格式是.tif
- 手工标注的血管图像格式是.gif
这里我做了图片格式的转换:
- 把眼底图像格式转换为.jpg
- 把手工标注的血管图像格式转换为.png
这里做格式转换的目的是我想把数据集放到PaddleX里试着运行一下,但它的图片格式只支持png, jpg, jpeg, bmp格式,因此,我这里做了一个格式转换。
血管标签图像二值化
如果直接将格式转换后的格式送入模型,会发现最多有256个标签,这是因为PaddleSeg采用单通道的标注图片,每一种像素值代表一种类别,像素标注类别需要从0开始递增,例如0,1,2,3表示有4种类别,所以标注类别最多为256类。
但其实我们只需要找到血管的位置,因此血管就作为一个类,其背景作为另一个类别,这样总共有2个类别。下面来看一下如何使用opencv做图像二值化处理。
先来看看如何使用opencv读取图片,下面是未处理的图片0.png,位于work目录下:
# 使用opencv读取图像
import cv2
import matplotlib.pyplot as plt
img = cv2.imread("work/0.png") # 读取的图片路径
plt.imshow(img)
plt.show()

# 使用opencv读取图像
import cv2
import matplotlib.pyplot as plt
img = cv2.imread("work/0.png") # 读取的图片路径
# 转换为灰度图
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.imshow(img_gray)
plt.show()

# 使用opencv读取图像
import cv2
import matplotlib.pyplot as plt
img = cv2.imread("work/0.png") # 读取的图片路径
# 转换为灰度图
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 将灰度极差的一半作为阈值
difference = (img_gray.max() - img_gray.min()) // 2
# 将图像二值化
_, img_binary = cv2.threshold(img_gray, difference, 1, cv2.THRESH_BINARY)
print("阈值:", _)
plt.imshow(img_binary)
plt.show()
阈值: 127.0

将上面的代码整理一下,可以整理出如下代码:
import cv2
import matplotlib.pyplot as plt
#循环灰度图片并保存
def grayImg():
for x in range(200):
#读取图片
img = cv2.imread("FundusVessels/Annotations/{}.png".format(str(x)))
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
difference = (img_gray.max() - img_gray.min()) // 2
_, img_binary = cv2.threshold(img_gray, difference, 1, cv2.THRESH_BINARY)
# print("阈值:", _)
#保存灰度后的新图片
cv2.imwrite("FundusVessels/{}.png".format(str(x)), img_binary)
plt.imshow(img_binary)
plt.show()
grayImg()
以上代码可以将像素值在0-255的图像转换成0-1二值图像。最后我已经将整理好的数据集上传至AI Studio,同时也加载到该项目上了:
https://aistudio.baidu.com/aistudio/datasetdetail/56726
我们也可以把数据集导入PaddleX可视化地看一下:
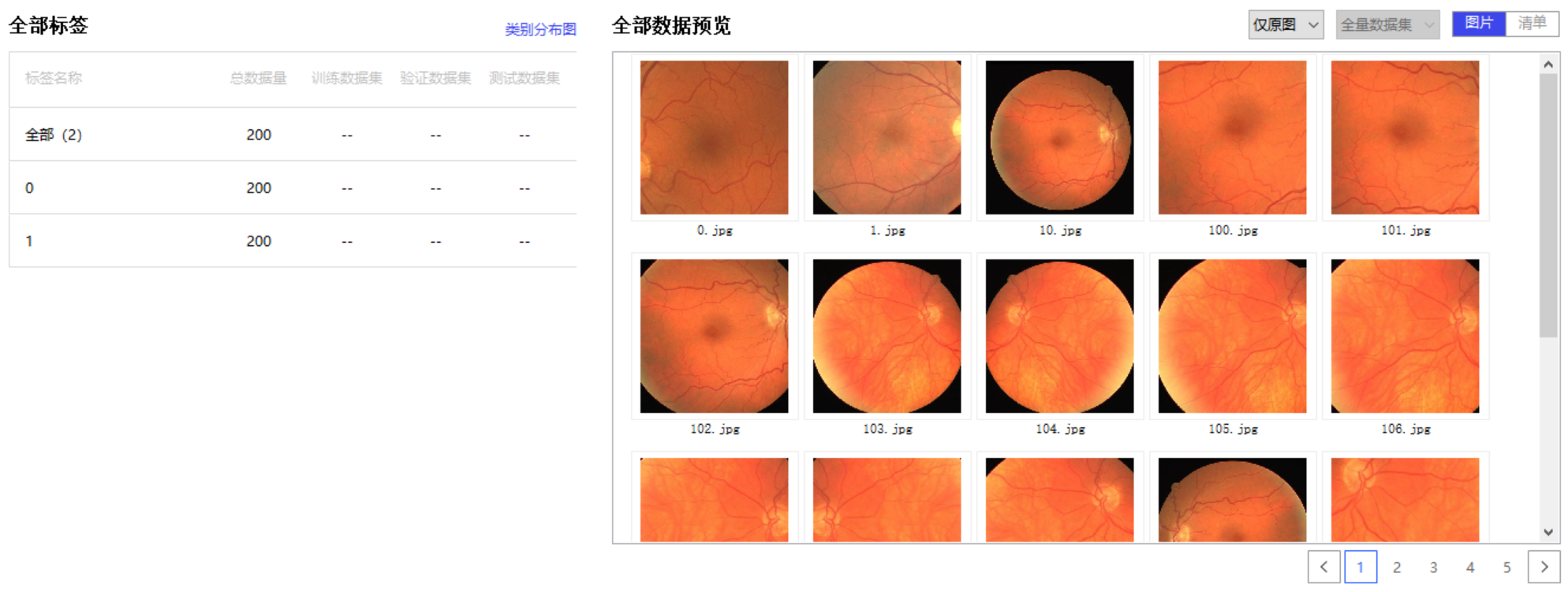
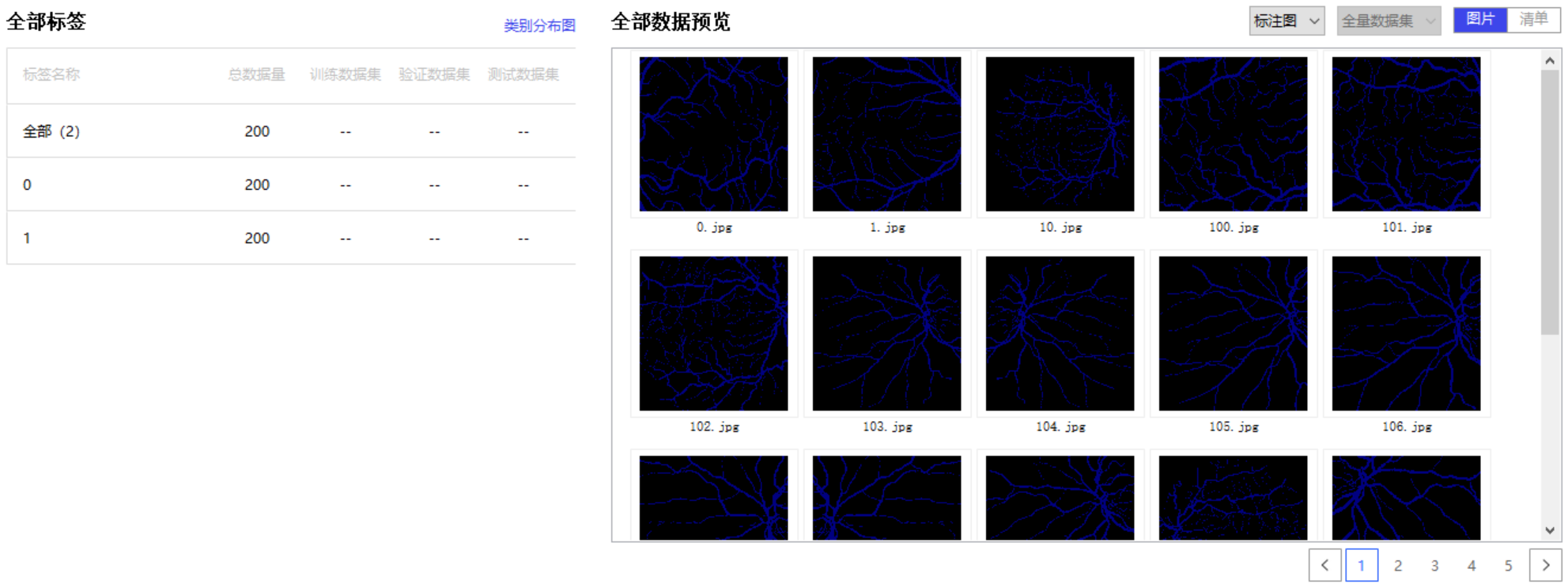
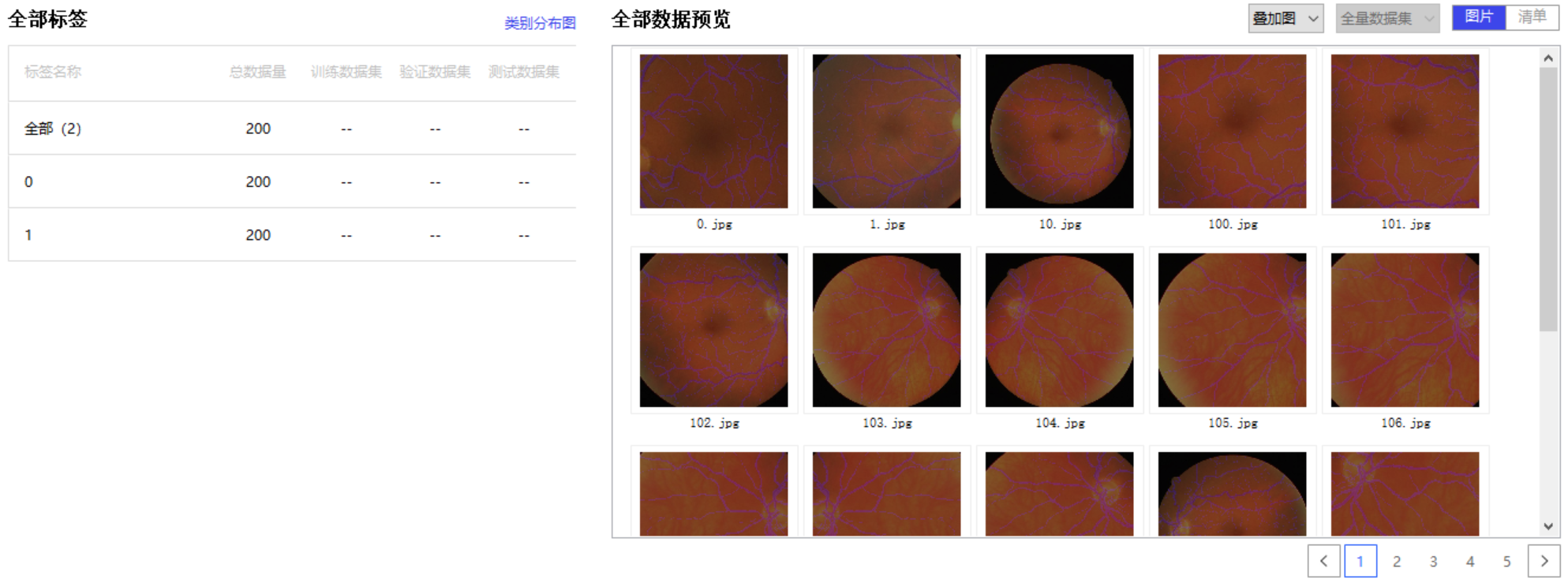
生成图像列表
PaddleSeg采用通用的文件列表方式组织训练集、验证集和测试集。在训练、评估、可视化过程前必须准备好相应的文件列表。
文件列表组织形式如下
原始图片路径 [SEP] 标注图片路径
其中[SEP]是文件路径分割符,可以在DATASET.SEPARATOR配置项中修改, 默认为空格。文件列表的路径以数据集根目录作为相对路径起始点,DATASET.DATA_DIR即为数据集根目录。
如下图所示,左边为原图的图片路径,右边为图片对应的标注路径:
# 解压数据集
!unzip data/data56918/FundusVessels.zip
# 生成图像列表
import os
path_origin = 'FundusVessels/JPEGImages/'
path_seg = 'FundusVessels/Annotations/'
pic_dir = os.listdir(path_origin)
f_train = open('train_list.txt', 'w')
f_val = open('val_list.txt', 'w')
for i in range(len(pic_dir)):
if i % 30 != 0:
f_train.write(path_origin + pic_dir[i] + ' ' + path_seg + pic_dir[i].split('.')[0] + '.png' + '\n')
else:
f_val.write(path_origin + pic_dir[i] + ' ' + path_seg + pic_dir[i].split('.')[0] + '.png' + '\n')
f_train.close()
f_val.close()
二、PaddleSeg的安装
PaddleSeg是基于PaddlePaddle生态下的语义分割库,可结合丰富的预训练模型更便捷高效地进行语义分割。
本项目已经挂载了PaddleSeg压缩包,解压即可使用。
注: 在AI studio中运行shell命令需要在最开始添加!
# 解压从PaddleSeg Github仓库下载好的压缩包
!unzip -o work/PaddleSeg.zip
# 运行脚本需在PaddleSeg目录下
%cd PaddleSeg
# 安装所需依赖项
!pip install -r requirements.txt
三、配置文件进行训练
这里我们需要使用两个文件:
- 训练文件:PaddleSeg/pdseg/train.py
- 训练的配置文件:PaddleSeg/configs/unet_optic.yaml
这里使用U-Net,大家可以尝试使用其他网络进行配置。
.yaml文件的配置
下面是我配置的.yaml文件,
# 数据集配置
DATASET:
DATA_DIR: ""
NUM_CLASSES: 2
TEST_FILE_LIST: "train_list.txt"
TRAIN_FILE_LIST: "train_list.txt"
VAL_FILE_LIST: "val_list.txt"
VIS_FILE_LIST: "train_list.txt"
# 预训练模型配置
MODEL:
MODEL_NAME: "unet"
DEFAULT_NORM_TYPE: "bn"
# 其他配置
TRAIN_CROP_SIZE: (565, 584)
EVAL_CROP_SIZE: (565, 584)
AUG:
AUG_METHOD: "unpadding"
FIX_RESIZE_SIZE: (565, 584)
BATCH_SIZE: 4
TRAIN:
# PRETRAINED_MODEL_DIR: "./pretrained_model/unet_bn_coco/"
MODEL_SAVE_DIR: "./saved_model/unet_optic/"
SNAPSHOT_EPOCH: 2
TEST:
TEST_MODEL: "./saved_model/unet_optic/final"
SOLVER:
NUM_EPOCHS: 10
LR: 0.001
LR_POLICY: "poly"
OPTIMIZER: "adam"
开始训练
训练命令的格式参考:
python PaddleSeg/pdseg/train.py --cfg configs/unet_optic.yaml \
--use_gpu \
--do_eval \
--use_vdl \
--vdl_log_dir train_log \
BATCH_SIZE 4 \
SOLVER.LR 0.001
!python PaddleSeg/pdseg/train.py --cfg PaddleSeg/configs/unet_optic.yaml
{'AUG': {'AUG_METHOD': 'unpadding',
'FIX_RESIZE_SIZE': (565, 584),
'FLIP': False,
'FLIP_RATIO': 0.5,
'INF_RESIZE_VALUE': 500,
'MAX_RESIZE_VALUE': 600,
'MAX_SCALE_FACTOR': 2.0,
'MIN_RESIZE_VALUE': 400,
'MIN_SCALE_FACTOR': 0.5,
'MIRROR': True,
'RICH_CROP': {'ASPECT_RATIO': 0.33,
'BLUR': False,
'BLUR_RATIO': 0.1,
'BRIGHTNESS_JITTER_RATIO': 0.5,
'CONTRAST_JITTER_RATIO': 0.5,
'ENABLE': False,
'MAX_ROTATION': 15,
'MIN_AREA_RATIO': 0.5,
'SATURATION_JITTER_RATIO': 0.5},
'SCALE_STEP_SIZE': 0.25,
'TO_RGB': False},
'BATCH_SIZE': 4,
'DATALOADER': {'BUF_SIZE': 256, 'NUM_WORKERS': 8},
'DATASET': {'DATA_DIM': 3,
'DATA_DIR': '',
'IGNORE_INDEX': 255,
'IMAGE_TYPE': 'rgb',
'NUM_CLASSES': 2,
'PADDING_VALUE': [127.5, 127.5, 127.5],
'SEPARATOR': ' ',
'TEST_FILE_LIST': 'train_list.txt',
'TEST_TOTAL_IMAGES': 193,
'TRAIN_FILE_LIST': 'train_list.txt',
'TRAIN_TOTAL_IMAGES': 193,
'VAL_FILE_LIST': 'val_list.txt',
'VAL_TOTAL_IMAGES': 7,
'VIS_FILE_LIST': 'train_list.txt'},
'EVAL_CROP_SIZE': (565, 584),
'FREEZE': {'MODEL_FILENAME': '__model__',
'PARAMS_FILENAME': '__params__',
'SAVE_DIR': 'freeze_model'},
'MEAN': [0.5, 0.5, 0.5],
'MODEL': {'BN_MOMENTUM': 0.99,
'DEEPLAB': {'ASPP_WITH_SEP_CONV': True,
'BACKBONE': 'xception_65',
'BACKBONE_LR_MULT_LIST': None,
'DECODER': {'CONV_FILTERS': 256,
'OUTPUT_IS_LOGITS': False,
'USE_SUM_MERGE': False},
'DECODER_USE_SEP_CONV': True,
'DEPTH_MULTIPLIER': 1.0,
'ENABLE_DECODER': True,
'ENCODER': {'ADD_IMAGE_LEVEL_FEATURE': True,
'ASPP_CONVS_FILTERS': 256,
'ASPP_RATIOS': None,
'ASPP_WITH_CONCAT_PROJECTION': True,
'ASPP_WITH_SE': False,
'POOLING_CROP_SIZE': None,
'POOLING_STRIDE': [1, 1],
'SE_USE_QSIGMOID': False},
'ENCODER_WITH_ASPP': True,
'OUTPUT_STRIDE': 16},
'DEFAULT_EPSILON': 1e-05,
'DEFAULT_GROUP_NUMBER': 32,
'DEFAULT_NORM_TYPE': 'bn',
'FP16': False,
'HRNET': {'STAGE2': {'NUM_CHANNELS': [40, 80], 'NUM_MODULES': 1},
'STAGE3': {'NUM_CHANNELS': [40, 80, 160],
'NUM_MODULES': 4},
'STAGE4': {'NUM_CHANNELS': [40, 80, 160, 320],
'NUM_MODULES': 3}},
'ICNET': {'DEPTH_MULTIPLIER': 0.5, 'LAYERS': 50},
'MODEL_NAME': 'unet',
'MULTI_LOSS_WEIGHT': [1.0],
'OCR': {'OCR_KEY_CHANNELS': 256, 'OCR_MID_CHANNELS': 512},
'PSPNET': {'DEPTH_MULTIPLIER': 1, 'LAYERS': 50},
'SCALE_LOSS': 'DYNAMIC',
'UNET': {'UPSAMPLE_MODE': 'bilinear'}},
'NUM_TRAINERS': 1,
'SLIM': {'KNOWLEDGE_DISTILL': False,
'KNOWLEDGE_DISTILL_IS_TEACHER': False,
'KNOWLEDGE_DISTILL_TEACHER_MODEL_DIR': '',
'NAS_ADDRESS': '',
'NAS_IS_SERVER': True,
'NAS_PORT': 23333,
'NAS_SEARCH_STEPS': 100,
'NAS_SPACE_NAME': '',
'NAS_START_EVAL_EPOCH': 0,
'PREPROCESS': False,
'PRUNE_PARAMS': '',
'PRUNE_RATIOS': []},
'SOLVER': {'BEGIN_EPOCH': 1,
'CROSS_ENTROPY_WEIGHT': None,
'DECAY_EPOCH': [10, 20],
'GAMMA': 0.1,
'LOSS': ['softmax_loss'],
'LOSS_WEIGHT': {'BCE_LOSS': 1,
'DICE_LOSS': 1,
'LOVASZ_HINGE_LOSS': 1,
'LOVASZ_SOFTMAX_LOSS': 1,
'SOFTMAX_LOSS': 1},
'LR': 0.001,
'LR_POLICY': 'poly',
'LR_WARMUP': False,
'LR_WARMUP_STEPS': 2000,
'MOMENTUM': 0.9,
'MOMENTUM2': 0.999,
'NUM_EPOCHS': 10,
'OPTIMIZER': 'adam',
'POWER': 0.9,
'WEIGHT_DECAY': 4e-05},
'STD': [0.5, 0.5, 0.5],
'TEST': {'TEST_MODEL': './saved_model/unet_optic/final'},
'TRAIN': {'MODEL_SAVE_DIR': './saved_model/unet_optic/',
'PRETRAINED_MODEL_DIR': '',
'RESUME_MODEL_DIR': '',
'SNAPSHOT_EPOCH': 2,
'SYNC_BATCH_NORM': False},
'TRAINER_ID': 0,
'TRAIN_CROP_SIZE': (565, 584)}
#Device count: 1
batch_size_per_dev: 4
2020-10-24 12:56:05,329-INFO: If regularizer of a Parameter has been set by 'fluid.ParamAttr' or 'fluid.WeightNormParamAttr' already. The Regularization[L2Decay, regularization_coeff=0.000040] in Optimizer will not take effect, and it will only be applied to other Parameters!
W1024 12:56:05.553278 21897 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 9.2, Runtime API Version: 9.0
W1024 12:56:05.557957 21897 device_context.cc:260] device: 0, cuDNN Version: 7.6.
Pretrained model dir not exists, training from scratch...
Use multi-thread reader
epoch=1 step=20 lr=0.00097 loss=0.3196 step/sec=2.958 | ETA 00:02:35
epoch=1 step=40 lr=0.00093 loss=0.2341 step/sec=3.114 | ETA 00:02:21
epoch=2 step=60 lr=0.00089 loss=0.1845 step/sec=3.064 | ETA 00:02:17
epoch=2 step=80 lr=0.00085 loss=0.1879 step/sec=3.106 | ETA 00:02:08
Save model checkpoint to ./saved_model/unet_optic/2
epoch=3 step=100 lr=0.00082 loss=0.1657 step/sec=2.347 | ETA 00:02:41
epoch=3 step=120 lr=0.00078 loss=0.1631 step/sec=3.100 | ETA 00:01:56
epoch=3 step=140 lr=0.00074 loss=0.1708 step/sec=3.095 | ETA 00:01:49
epoch=4 step=160 lr=0.00070 loss=0.1522 step/sec=3.047 | ETA 00:01:45
epoch=4 step=180 lr=0.00066 loss=0.1638 step/sec=3.088 | ETA 00:01:37
Save model checkpoint to ./saved_model/unet_optic/4
epoch=5 step=200 lr=0.00063 loss=0.1485 step/sec=2.354 | ETA 00:01:58
epoch=5 step=220 lr=0.00059 loss=0.1493 step/sec=3.084 | ETA 00:01:24
epoch=5 step=240 lr=0.00055 loss=0.1462 step/sec=3.082 | ETA 00:01:17
epoch=6 step=260 lr=0.00051 loss=0.1460 step/sec=3.034 | ETA 00:01:12
epoch=6 step=280 lr=0.00047 loss=0.1460 step/sec=3.050 | ETA 00:01:05
Save model checkpoint to ./saved_model/unet_optic/6
epoch=7 step=300 lr=0.00043 loss=0.1480 step/sec=2.347 | ETA 00:01:16
epoch=7 step=320 lr=0.00039 loss=0.1397 step/sec=3.082 | ETA 00:00:51
epoch=8 step=340 lr=0.00035 loss=0.1359 step/sec=3.030 | ETA 00:00:46
epoch=8 step=360 lr=0.00031 loss=0.1368 step/sec=3.078 | ETA 00:00:38
epoch=8 step=380 lr=0.00026 loss=0.1386 step/sec=3.078 | ETA 00:00:32
Save model checkpoint to ./saved_model/unet_optic/8
epoch=9 step=400 lr=0.00022 loss=0.1311 step/sec=2.340 | ETA 00:00:34
epoch=9 step=420 lr=0.00018 loss=0.1272 step/sec=3.076 | ETA 00:00:19
epoch=10 step=440 lr=0.00013 loss=0.1381 step/sec=3.008 | ETA 00:00:13
epoch=10 step=460 lr=0.00009 loss=0.1280 step/sec=3.072 | ETA 00:00:06
epoch=10 step=480 lr=0.00004 loss=0.1315 step/sec=3.075 | ETA 00:00:00
Save model checkpoint to ./saved_model/unet_optic/10
Save model checkpoint to ./saved_model/unet_optic/final四、模型评估
该命令与训练的命令格式一致。
!python PaddleSeg/pdseg/eval.py --cfg PaddleSeg/configs/unet_optic.yaml
由以上的输出中可以看出我们的模型效果:
[EVAL]step=1 loss=0.15743 acc=0.9396 IoU=0.7404 step/sec=2.02 | ETA 00:00:23
[EVAL]step=2 loss=0.14508 acc=0.9417 IoU=0.7482 step/sec=7.37 | ETA 00:00:06
[EVAL]#image=7 acc=0.9417 IoU=0.7482
[EVAL]Category IoU: [0.9371 0.5592]
[EVAL]Category Acc: [0.9445 0.9105]
[EVAL]Kappa:0.6865
五、模型导出
通过训练得到一个满足要求的模型后,如果想要将该模型接入到C++预测库或者Serving服务,我们需要通过pdseg/export_model.py来导出该模型。
该脚本的使用方法和train.py/eval.py/vis.py完全一样。
# 模型导出
!python PaddleSeg/pdseg/export_model.py --cfg PaddleSeg/configs/unet_optic.yaml TEST.TEST_MODEL ./saved_model/unet_optic/final
预测模型会导出到freeze_model目录,用于C++或者Python预测的模型配置会导出到freeze_model/deploy.yaml下
六、PaddleSeg Python 预测部署
在预测前,我们需要使用pip安装Python依赖包:
!pip install -r PaddleSeg/deploy/python/requirements.txt
使用以下命令进行预测:
python infer.py --conf=/path/to/deploy.yaml --input_dir=/path/to/images_directory
运行后程序会扫描input_dir 目录下所有指定格式图片,并生成预测mask和可视化的结果。
对于图片a.jpeg, 预测mask 存在a_jpeg.png 中,而可视化结果则在a_jpeg_result.png 中。
# 模型预测
!python PaddleSeg/deploy/python/infer.py --conf=freeze_model/deploy.yaml --input_dir=work/test
输入图片:
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = cv2.imread("work/test/1.jpg")
plt.imshow(img)
plt.show()

预测结果:
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = cv2.imread("work/test/1_jpg_result.png")
plt.imshow(img)
plt.show()

七、总结与升华
前不久,安定医院在做脑科学的研究,招募志愿者,我报名且有幸被录取去安定医院做志愿者,在此期间,我了解到目前的医学生在做医学影像分析,用的也是神经网络,但毕竟是学科交叉,对医学生来说还是有一定的困难的。
因此,我在想,能不能做些什么帮助他们。回来以后,我找了很多医学影像的数据集,最后选择了这个糖尿病人的眼底血管数据集,我想把这个项目当作使用PaddleSeg研究医学影像图像分割的Hello World。
八、个人介绍
- 北京联合大学 机器人学院 自动化专业 2018级 本科生 郑博培
- 百度飞桨开发者技术专家 PPDE
- 深圳柴火创客空间 认证会员
- 百度大脑 智能对话训练师










