文章目录
业务场景
- 网站里有大量文章信息,使用elasticsearch做全文检索
- 客户反馈,最近两天加的数据,在网站前台没有搜索到(为防止索引业务影响正常的信息维护业务,索引操作记入线程池,异步线程执行,出错时存入索引错误记录表,定时任务处理,故而索引库出错时,客户暂时感知不到)
- 开发检查后,发现索引写入报错,新增、更新、删除都报错,但是查询还可以
- 开发通知运维重启elasticsearch集群服务,重启后 索引库 变成
RED,无法恢复成GREEN - 运维又重启了几次,总有2个分片无法分配,集群无法恢复成
GREEN - 查看后发现有两个分片一直处于
unassigned,使用reroute后也无法重现成功分片 reroute可以参考我的上一篇elasticsearch博客:elasticsearch重启后,unassigned索引重新分片失败YELLO、RED恢复处理
查看分片失败原因
- 由于我是公司里最先引进和使用elasticsearch的,运维无法处理时,联系了我
- 对于集群
RED状态,要查看分片失败的具体原因,具体是哪个索引的哪些分片 - 首先查看集群状态
curl http://localhost:9200/_cluster/health?pretty
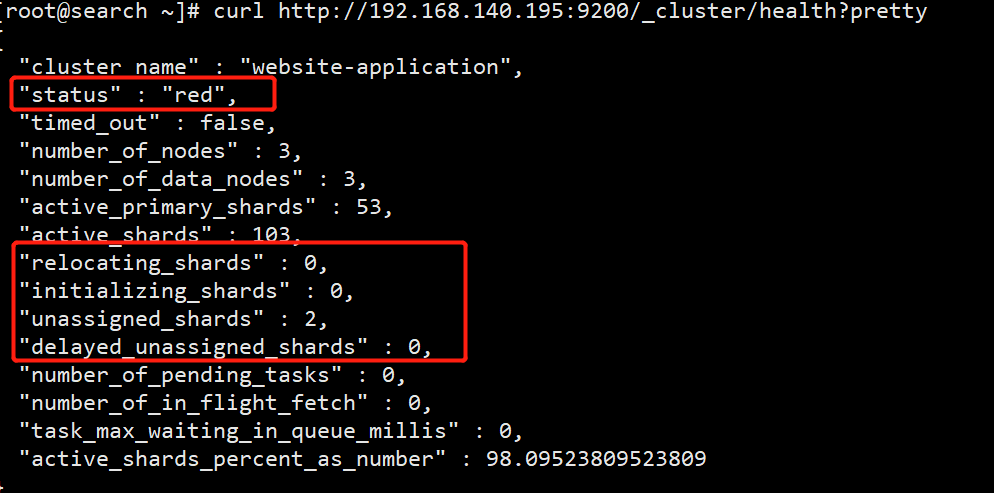
- 接着查看索引健康状态
curl http://localhost:9200/_cat/indices?pretty
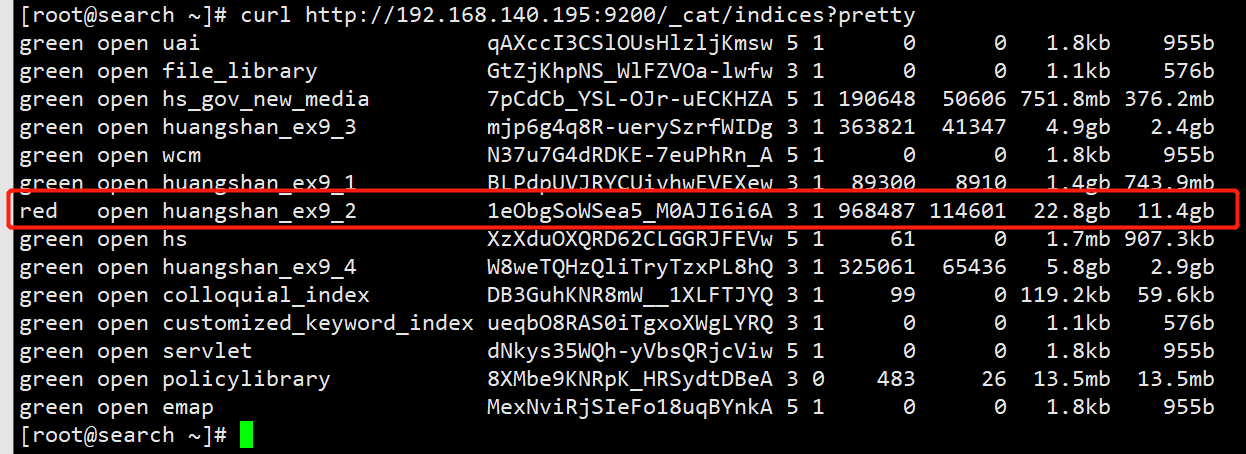
- 最后查看分片失败具体原因
curl http://localhost:9200/_cluster/allocation/explain?pretty
{
"index" : "huangshan_ex9_2",
"shard" : 1,
"primary" : true,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "CLUSTER_RECOVERED",
"at" : "2022-03-03T15:00:56.648Z",
"last_allocation_status" : "no_valid_shard_copy"
},
"can_allocate" : "no_valid_shard_copy",
"allocate_explanation" : "cannot allocate because all found copies of the shard are either stale or corrupt",
"node_allocation_decisions" : [
{
"node_id" : "0KQXu9ETSW6C28XwdFiVKQ",
"node_name" : "node-2-master-40-4-9200",
"transport_address" : "192.168.140.156:9300",
"node_decision" : "no",
"store" : {
"in_sync" : false,
"allocation_id" : "jlBieBfuSyutS7xUIMd_EA",
"store_exception" : {
"type" : "file_not_found_exception",
"reason" : "no segments* file found in SimpleFSDirectory@/home/es/data/nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index lockFactory=org.apache.lucene.store.NativeFSLockFactory@bdd7e5b: files: [write.lock]"
}
}
},
{
"node_id" : "DJ-qZio2TwGQT8xNM9tmlQ",
"node_name" : "node-1-master-40-3-9200",
"transport_address" : "192.168.140.195:9300",
"node_decision" : "no",
"store" : {
"in_sync" : true,
"allocation_id" : "cgVuWaTHTiu7clJznlVgAw",
"store_exception" : {
"type" : "corrupt_index_exception",
"reason" : "failed engine (reason: [recovery]) (resource=preexisting_corruption)",
"caused_by" : {
"type" : "i_o_exception",
"reason" : "failed engine (reason: [recovery])",
"caused_by" : {
"type" : "corrupt_index_exception",
"reason" : "checksum failed (hardware problem?) : expected=1c1tkg8 actual=g89llu (resource=name [_eg4z.cfs], length [295346024], checksum [1c1tkg8], writtenBy [6.6.0]) (resource=VerifyingIndexOutput(_eg4z.cfs))"
}
}
}
}
},
{
"node_id" : "Pdb_sRtlQ7Gnx6kQ3QQIfg",
"node_name" : "node-3-master-40-5-9200",
"transport_address" : "192.168.140.188:9300",
"node_decision" : "no",
"store" : {
"in_sync" : false,
"allocation_id" : "WhnSlN6YQU61efSeQ-DTJQ"
}
}
]
}
开始搜索
- 可以发现是索引
huangshan_ex9_2的分片分配失败,失败原因no_valid_shard_copy, 拿着去搜索了下,没搜到啥有用的东西,只好换关键词继续搜,具体原因要看下面的caused_by - 看到2个报错信息,都是第一次遇到,头疼,拿去翻译了下,结果出现了让人更加头疼的字眼
stale or corrupt、i_o_exception、hardware problem?,分片损坏、io异常、硬件问题? - 没其他办法,只能根据分片出错原因,根据这几个关键词去继续搜索
- 一个报错是
no segments* file found in SimpleFSDirectory@/home/es/data/nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index lockFactory=org.apache.lucene.store.NativeFSLockFactory@bdd7e5b: files: [write.lock],说是找不到这个文件,一开始去服务器上看了下,发现这个文件在,很疑惑,去看下一个报错去了(操蛋的是,我看错服务器了,看了另一个节点的这个文件夹,如果当时没看错,会发现这个文件确实不存在,可能问题就解决了) - 拿着
no segments* file found这个关键词去搜了下,搜到好多代码,Lucene相关的,和elasticsearch分片失败关系不大,对我没啥用
相关结果
- 另一个分片报错是
checksum failed (hardware problem?) : expected=1c1tkg8 actual=g89llu (resource=name [_eg4z.cfs], length [295346024], checksum [1c1tkg8], writtenBy [6.6.0]) (resource=VerifyingIndexOutput(_eg4z.cfs)) - 换另一个关键词
checksum failed (hardware problem?)继续搜索 - 又去网上搜了一堆,在elasticsearch中文社区,找到两篇文章索引分片突然崩溃下线,分片无法重新分配,Elasticsearch 无法写入数据 checksum failed (hardware problem?),和我的报错和现象都很像
- 但是这两篇帖子,没有给出具体的解决办法,有说硬盘坏道的,有说不是硬盘问题的,我找了运维,检查了下,没有硬盘坏道。当然,也给出了解决办法,索引删掉重建,但是我这个索引存储十几个G数据,重建代价有点大
- 继续搜索,在CSDN找到一篇修复 Elasticsearch 中损坏的索引,这篇文章,还比较贴合我的报错,也比较详细和靠谱,它文章里, 还有一篇官方讨论区的帖子Corrupted elastic index 。既然他给出了详细的方法,打算按照他的不止试试
- 在集群各个节点执行
find命令,果然在报错节点195找到了冲突文件
cd /usr/local/elasticsearch/elasticsearch-5.5.2/data
find ./ -name corrupted_*
./nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index/corrupted_Beh13uEIS-KDHWd2Cw1Gtg
尝试修复
尝试解决冲突
- 按照博客先进行恢复冲突的尝试
- 注意:数据恢复时,如果有写入,可能导致错误,先关闭索引,再操作
## 到lib目录
cd /usr/local/elasticsearch/elasticsearch-5.5.2/lib
## 执行恢复命令
java -cp lucene-core*.jar -ea:org.apache.lucene... org.apache.lucene.index.CheckIndex /usr/local/elasticsearch/elasticsearch-5.5.2/data/nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index -verbose -exorcise
- 我的执行结果和CSDN那位小哥博客里已有 No problem,说明压根没有冲突,不是这个问题影响的
删除冲突文件
- 无论是否恢复成功,都决定删除冲突文件,大不了丢失小部分数据
cd /usr/local/elasticsearch/elasticsearch-5.5.2/data
find ./ -name corrupted_*
cd ./nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index/
## 改个名
mv corrupted_Beh13uEIS-KDHWd2Cw1Gtg corrupted_Beh13uEIS-KDHWd2Cw1Gtg.bak
## 或者删除
rm -rf corrupted_Beh13uEIS-KDHWd2Cw1Gtg
主动重新分配
- 按照博客里的解决方法,这个时候应该就能恢复正常了,但是我启动后发现还是不行
- 试着执行
reroute命令,还是不行,还是原来的报错,但是冲突文件我已经删了
curl -XPOST 'http://192.168.140.195:9200/_cluster/reroute?retry_failed=true'
最终解决
- 既然不是冲突问题,那就是另一个问题了,继续回头查看第一个分片的报错信息
- 然后到服务器上的对应位置
/home/es/data/nodes/0/indices/1eObgSoWSea5_M0AJI6i6A/1/index看了下,我擦,确实没有segments*文件,只有一个write.lock - 既然如此,说明这是个空的分片,决定删除试试,反正集群会重新分片,删了也不会有什么坏的影响
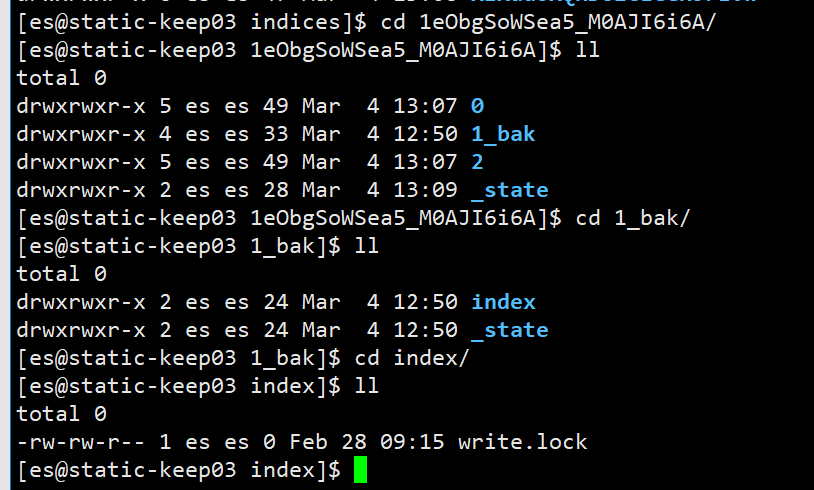
- 保险起见,暂时使用
move命令改了文件夹名称,万一产生严重错误,还能回滚。操作前,关闭elasticsearch集群 - 截图如下,由于是操作后的,只能看到
1_bak,可以看到里面只有index和_state文件夹,index里也只有write.lock
- 然后,启动集群各节点,它就好了。
总结
- 冲突文件
corrupted_*的创建时间,是在几天前的一个早晨产生的,后面该索引的写入应该已经出错了。问了运维和开发,都没有做什么特殊操作,具体出错的原因还是未知 - 后续再出现
corrupted_*时,可以按照上面的方法尝试恢复和删除,大概率解决问题 - 没有
segments*文件的index文件夹,创建时间是重启集群的时间,可能是重启后,因为上个错误导致新的分片失败,导致这个新分片锁定,无法产生segments*,只有包含write.lock的文件夹 - 再遇到类似报错,删除这个没有数据的报错分片即可
