LSM-Tree - LevelDb Skiplist跳表
跳表介绍
跳表(SkipList)是由William Pugh提出的。他在论文《Skip lists: a probabilistic alternative to balanced trees》中详细地介绍了有关跳表结构、插入删除操作的细节。
文档:Skiplist跳表原始论文 - pugh-skiplists-cacm1990.pdf
链接:http://note.youdao.com/noteshare?id=667aed96f012edcada047baf75aa1769&sub=B427E00C818B428ABD38A813180AF9A8
背景
在线性的数据数据结构中我们经常可以想到数组和链表,数组是插入慢查询快,而链表是插入快,查询要稍微慢一些,而跳表主要是针对链表查询速度进行优化的一种数据结构,多层级的跳表实际上是对底层链表的索引,非常典型的空间换时间,把链表的查询时间尽量控制在O(logN)。
实现
由于使用了类似索引点数据维护方式,所以新增和删除需要同时维护跳表结构,跳表利用概率平衡的方式简化新增和删除操作,和树操作利用左旋和右旋等操作维持数据平衡不同,跳表利用了类似猜硬币的方式抉择出在哪一层插入或者删除节点和更新索引。
从下面的abcde图中,我们可以看一下跳表的演进:
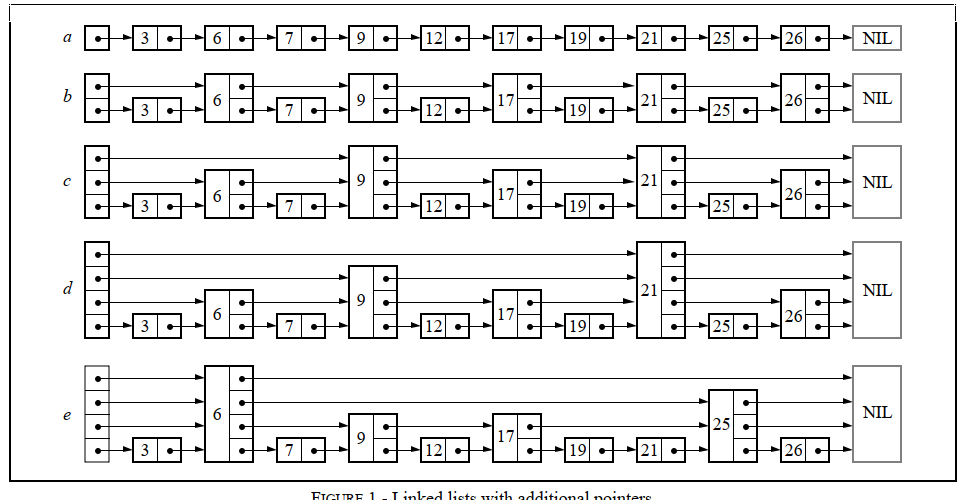
首先a是一个典型的链表结构,对于查询来说需要O(n)的时间,链表长度越长查询越慢。
b在a的基础上,每次隔2个节点加一个额外的指针,通过这样的操作,每次查询时间就减少了【n/2】+次数。
c、d、e继续按照这样的思路继续加额外指针,最终只留下从头到尾的一层指针结束。
但是可以看到如果按照统一的思路每一层这样加节点对于维护整个节点的效率十分低,我们将拥有额外指针的节点看作一个K层节点,按照图中整理可以看到对于1层的节点占了50%,2层为25%,3层为12.5%......如果插入新节点能按照这样的规律进行插入删除,那么效率提升就不会出现很大的性能影响。
维护辅助指针会带来更大的复杂度,索引在每一层的节点中都会指向当前层所在的下一个节点,也就是说每一层都是一个链表。
时间复杂度如何计算的?
推导公式如下:
n/2^k => n / 2^k = 2 => h = log2n -1 => O(logn)
k代表节点层数,h表示最高级
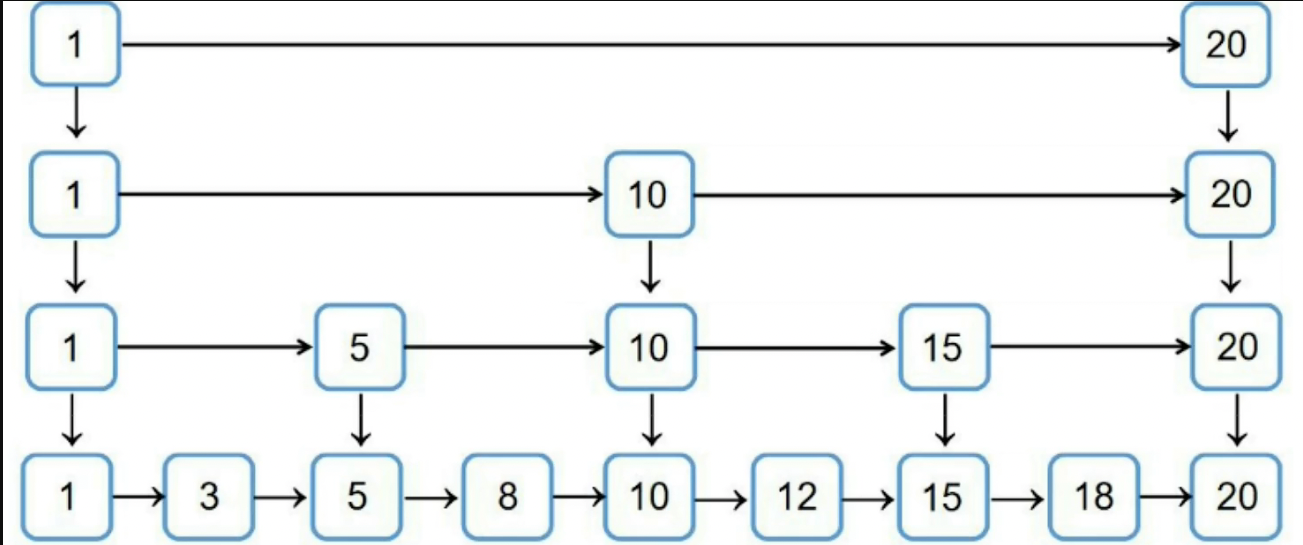
原始的链表有n个元素,则一级索引有n/2 个元素、二级索引有 n/4 个元素、k级索引就有 n/(2^k)个元素。最高级索引一般有2个元素(头指向尾),最高级索引指向2 = n/(2^h),即 h =(log2)n-1,最高级的索引h为索引层高度+原数据高度,最终跳表高度为 h = (log2) n。
经过索引的优化之后,整个查询的时间复杂度可以近似看作O(logn) ,和 二分查找的效率类似。
空间复杂度如何计算?
随着层数的增加,建立索引的空间开销是越来越小的,一层索引为 n/2,二层索引为 n/4,三层为 n/8 .....最后 n/2 + n/4 + n/8 +.... + 2(最高层一般为2个节点)最后因为分母相加可以认为是近似 O(n) 的空间复杂度。
查询
下面是跳表的增删改查的处理流程,由于删除和插入都依赖查询,我们先从查询开始介绍:
查询的操作方式可以看下面的绘图,比如如果需要查找存在于中间的节点17,则会根据线条顺序查找,这里简述查询顺序:
- 从索引的最高层进行查找,直接找到下一个节点。
- 如果当前内容大于节点内容,则直接找下一个节点比较。
- 如果当前节点等于查找节点则直接返回。
- 如果当前节点大于节点,并且下一个节点大于当前节点,并且层高不为0,则继续往层高更低的一个层级节点查找同时回到更低层级前一个节点,如果层高为0,则返回当前节点,当前节点的key要大于查找的key。
查找比较好理解,就是用索引快速跨越多个链表节点减少搜索次数,然后层数下探找到相关的节点,注意拥有索引的节点,通常在上层节点会有指向下层的指针。
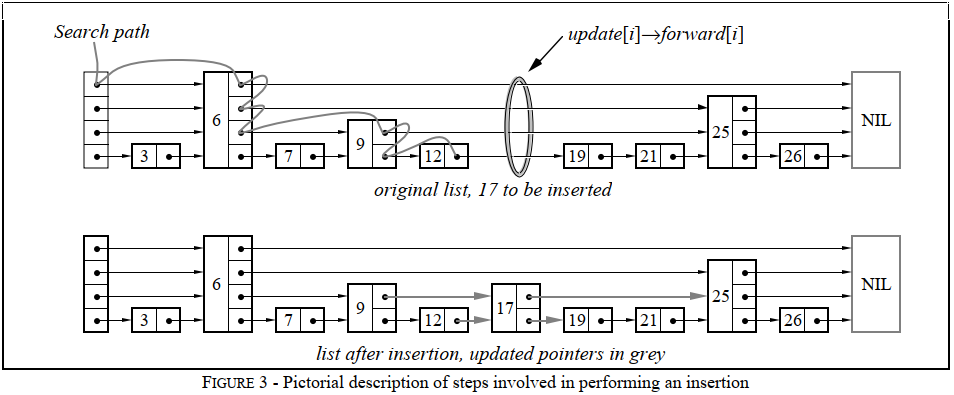
插入
插入操作比较关键,因为这里涉及到非常影响跳表性能的索引节点选举动作。按照之前的查找操作步骤,插入操作需要每次记录每一层的前任节点。
关键点:插入的关键点在于选举那个节点增加层高来维持二分查找的效率,在找到位置之后,通常使用随机抛硬币的方式随机为节点增加层高,层级越高被选中的概率通常会指数倍的降低,之后根据三个参数:种子(用于实现概率随机)以及当前节点的层数和概率值P或者其他的随机值算法进行计算,但是为了防止单节点层高过高,通常会限制最终层高防止单一节点的层高超过上限。
根据墨菲定律,无论单一节点层高过高可能性再低,都需要做限制。
这里挑了LevelDB跳表数据结构的一段代码进行介绍:
func (p *DB) randHeight() (h int) {
// 限制跳表扩展的最高层级
const branching = 4
h = 1
for h < tMaxHeight && p.rnd.Int()%branching == 0 {
h++
}
return
}插入节点之后,会根据记录的前任节点在每一层的位置按照跳表规则建立新节点的索引。
跳表插入新节点本身的更新十分非常简单,只需要把当前节点下一个节点指向插入节点的下一个节点的下一个节点,插入节点的下一个节点指向当前节点 即可。

插入操作时间复杂度
如果是单链表,那么一次遍历就可以完成,结果永远都是O(1),对于跳表的插入,最坏的情况也就是需要在所有层都更新索引,这种情况是O(logN)。
删除
删除也是依赖查询完成的,根据查询找到待删除节点之后在每一层按照查询的规则把当前节点删除即可。
删除的时间复杂度快慢取决于于查询的层数,假设需要删除N个元素,而每一层其实都是一个单向的链表,单链表的查询是O(1),同时是因为跳表最优是近似二分查找的效率,索引层数为logn,删除的层数也是logN,N取决于层级。
最终删除元素的总时间包含:
查找元素的时间 + _删除 logn个元素的时间 = O(logn) + O(logn) = 2O(logn),忽略常数部分最终结果为 O(logn)。
使用场景
其实多数和Key-Value有关的LST-Tree 数据结构都有类似的跳表实现,因为链表在业务方面使用可能比较少,但是在数据结构和数据库设计上面却是至关重要的地位:
- HBase
- Redis
- LevelDB
小结
- 跳表让链表也能够完成二分查找的操作
- 元素的插入会根据抛硬币和权重分配随机选举Level
- 最底层永远是原始链表,而上层则是索引数据
- 索引节点通常会多一个指针指向下层节点,但是不是所有的程序设计都是按照这种方式,有其他的处理方式间接实现此功能(具体可以看redis 的 zset源代码)
- 跳表查询、插入、删除的时间复杂度为O(log n),与平衡二叉树接近
LevelDb跳表实现
在之前讨论合并压缩文件使用了归并排序的方式进行键合并,而内部的数据库除了归并排序之外还使用了比较关键的[[LSM-Tree - LevelDb Skiplist跳表]]来进行有序键值管理。
跳表在Redis和Kafka中都有实现,这里的Skiplist其实也是类似的,可以看作C++版本的跳表案例。
这部分就不看作者的文档了,我们直接源码开干。
基础结构
首先我们需要清楚LevelDB的跳表包含了什么东西?在代码的一开始定义了 Node节点用来表示链表节点,以及 Iterator迭代器的内容进行迭代,内部定义了std::atomic<Node*> next_[1] 长度等于节点高度的数组。
next_[0]是最底层的节点(用于跳表跨层获取数据),核心是作者自认为写的一般的Random 随机器(通过位操作生成随机的一个位号码)。
LevelDB的整个实现比较简洁规范,在设计上定义了很多函数来简化复杂代码的增加,建议看不懂就多看几遍跳表的理论。
重要方法
#levelDB插入操作 #levelDB查询操作
在了解过[[LSM-Tree - LevelDb Skiplist跳表]]之后,我们发现对于跳表这种数据结构来说,核心部分在于查询和插入两个部分,当然查询是理解插入点前提,但是对于插入抛硬币选举的实现有必要深究一下。
查询操作
查询操作比较好理解,和跳表的数据结构规定差不多,和[[LSM-Tree - LevelDb Skiplist跳表]]的实现类似:
可以发现和跳表原始的实现方式如出一辙,这里相当于复读理论的内容:
- 从索引的最高层进行查找,直接找到下一个节点。
- 如果当前内容大于节点内容,则直接找下一个节点比较。
- 如果当前节点等于查找节点则直接返回。
- 如果当前节点大于节点,并且下一个节点大于当前节点,并且层高不为0,则继续往层高更低的一个层级节点查找同时回到更低层级前一个节点,如果层高为0,则返回当前节点,当前节点的key要大于查找的key。
// 返回层级最前的节点,该节点位于键的位置或之后。如果没有这样的节点,返回nullptr。如果prev不是空的,则在[0...max_height_1]中的每一级,将prev[level]的指针填充到前一个 节点的指针来填充[0...max_height_1]中的每一级的 "level"。
template <typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node*
SkipList<Key, Comparator>::FindGreaterOrEqual(const Key& key,
Node** prev) const {
Node* x = head_;
// 防止无限for循环
int level = GetMaxHeight() - 1;
while (true) {
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {
// 如果当前节点在层级之后,则查找下一个链表节点
x = next;
} else {
if (prev != nullptr) prev[level] = x;
if (level == 0) {
return next;
} else {
// 层级下沉
level--;
}
}
}
}插入操作
插入操作的代码如下,注意跳表需要在插入之前对于节点进行加锁的操作。
template <typename Key, class Comparator>
void SkipList<Key, Comparator>::Insert(const Key& key) {
// 因为前置节点最多有kMaxHeight层,所以直接使用kMaxHeight 简单粗暴
Node* prev[kMaxHeight];
// 返回层级最前的节点,该节点位于键的位置或之后。如果没有这样的节点,返回nullptr。如果prev不是空的,则在[0...max_height_1]中的每一级,将prev[level]的指针填充到前一个 节点的指针来填充[0...max_height_1]中的每一级的 "level"。
Node* x = FindGreaterOrEqual(key, prev);
// 不允许进行重复插入操作(同步加锁)
assert(x == nullptr || !Equal(key, x->key));
// **新增层级选举**,使用随机函数和最高层级限制,按照类似抛硬币的规则选择是否新增层级。
// 随机获取一个 level 值
int height = RandomHeight();
// 当前随机level是否大于 当前点跳表层数
if (height > GetMaxHeight()) {
// 头指针下探到最低层
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
/*
这部分建议多读读原注释。
机器翻译:在没有任何同步的情况下突变max_height_是可以的。与并发读取器之间没有任何同步。一个并发的读者在观察到的新值的并发读者将看到max_height_的旧值。的新水平指针(nullptr),或者在下面的循环中设置一个新的值。下面的循环中设置的新值。在前一种情况下,读者将立即下降到下一个级别,因为nullptr会在所有的键之后。在后一种情况下,读取器将使用新的节点
理解:意思是说这一步不需要并发加锁,这是因为并发读读取到更新的跳表层数,哪怕现在这个节点没有插入,也会返回nullptr,在leveldb的比较器当中的nullpt会在最前面,默认看作比所有的key都要大,所以会往下继续找,这样就可以保证写入和读取都是符合预期的。
*/
max_height_.store(height, std::memory_order_relaxed);
}
// 新增跳表节点
x = NewNode(key, height);
for (int i = 0; i < height; i++) {
// NoBarrier_SetNext()就够了,因为当我们在prev[i]中发布一个指针 "x "时,我们会添加一个障碍。我们在prev[i]中发布一个指向 "x "的指针。
// 更新指针引用
// 为了保证并发读的准确性,需要先设置节点指针然后再设置原始表的prev 指针
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
// 内部会强制进行同步
prev[i]->SetNext(i, x);
}
}跳表实现的难点在于层数的确定,而LevelDB的难点在于插入节点如何保证并发写入的时候能够正确的并发读。
RandomHeight() 新增层级选举:
在LevelDb中层级选举的核心的代码是:height < kMaxHeight && rnd_.OneIn(kBranching),内部在控制跳表层数最多不超过kMaxHeight层的情况下,对于4取余的操作实现构造 P = 3/4 的几何分布,最终判断是否新增层数。
原始情况下跳表增加1层为 1/2,2层为1/4,3层为1/8,4层为1/16。LevelDB的11层最高层限制key的数量,但是11层的节点概率通常会非常非常小。
最终LevelDB选择的结果是3/4 的节点为 1 层节点,3/16 的节点为 2 层节点,3/64 的节点为 3 层节点,依此类推。
层级选举的特点:
- 插入新节点的指针数通过独立计算一个概率值决定,使全局节点的指针数满足几何分布即可。
- 插入时不需要做额外的节点调整,只需要先找到其需要放的位置,然后修改他和前驱的指向即可。
template <typename Key, class Comparator>
int SkipList<Key, Comparator>::RandomHeight() {
// 在kBranching中以1的概率增加高度
static const unsigned int kBranching = 4;
int height = 1;
// rnd_.OneIn(kBranching):"1/n "的时间会返回真没其他情况会返回假
// 相当于层数会按照4 的倍数减小, 4层是3层的4分之一,简单理解为 每次加一层概率就要乘一个 1/4。
while (height < kMaxHeight && rnd_.OneIn(kBranching)) {
height++;
}
assert(height > 0);
assert(height <= kMaxHeight);
return height;
}从上面的代码可以看到概率P使用了1/4计算方式,使用1/4的好处是让层数更为分散,典型的时间换空间的操作,虽然会牺牲一部分空间,但是获得更高的性能,在此情况下,可以最多支持 n = (1/p)^kMaxHeight 个节点的情况。
对于LevelDB这种写快过读的业务,效率是最优考虑。
12层高的节点最多可以存储多少数据?那么可以直接使用4^12 计算约等于 16M。当然12层的概率微乎其微。
删除操作
LevelDB跳表是没有删除这个概念的,相对应的更新也是针对next指针的变动。
- 除非跳表被销毁,跳表节点只会增加而不会被删除,因为跳表根本不对外提供删除接口。
- 被插入到跳表中的节点,除了 next 指针其他域都是不可变的,并且只有插入操作会改变跳表。(以此来替代更新)
遍历操作
之前的[[LSM-Tree - LevelDb 源码解析]] 分析解释过整个跳表的遍历通过Iterator完成,内部使用了归并排序对于key进行排序,同时null ptr作为特殊值永远排在最前面。
LevelDB自带的迭代器实现较为丰富,除开迭代器经典的remove(),next()、haseNext()之外,还有Seek,SeekToFirst,SeekToLast、以及Prev向前遍历的操作
// Advances to the next position.
// REQUIRES: Valid()
void Next();
// Advances to the previous position.
// REQUIRES: Valid()
void Prev();
// Advance to the first entry with a key >= target
void Seek(const Key& target);
// Position at the first entry in list.
// Final state of iterator is Valid() iff list is not empty.
void SeekToFirst();
// Position at the last entry in list.
// Final state of iterator is Valid() iff list is not empty.
void SeekToLast();这里需要特意强调的是向前遍历这个操作并不是通过增加prev指针反向迭代的,而是从head开始查找,也是时间换空间。
最后有两个比较频繁的使用操作FindLast和FindLessThan,注释写的简单明了,就不多介绍了。
// Return the latest node with a key < key.
// Return head_ if there is no such node.
Node* FindLessThan(const Key& key) const;
// Return the last node in the list.
// Return head_ if list is empty.
Node* FindLast() const;总结
LevelDB的跳表设计难点主要体现在并发读写的维持以及节点的层级选举上面,这一部分是和原始的跳表差别比较大的地方,而其他地方基本可以看作原始跳表的理论设计的,所以把 LevelDB 作为跳表的模板代码学习也是十分推荐的。
参考资料
Skip List--跳表(全网最详细的跳表文章没有之一) - 简书 (jianshu.com)
跳表数据结构的实现,JAVA版本的链表可以看下面的代码:
algo/SkipList.java at master · wangzheng0822/algo · GitHub
相关阅读
- [LSM-Tree - LevelDb了解和实现]
- [《数据密集型型系统设计》LSM-Tree VS BTree]
- [LSM-Tree - LevelDb 源码解析]










