作者:天翼云 谭龙
关键词:SPDK、NVMeOF、Ceph、CPU负载均衡
SPDK是intel公司主导开发的一套存储高性能开发套件,提供了一组工具和库,用于编写高性能、可扩展和用户态存储应用。它通过使用一些关键技术实现了高性能:
1. 将所有必需的驱动程序移到用户空间,以避免系统调用并且支持零拷贝访问
2. IO的完成通过轮询硬件而不是依赖中断,以降低时延
3. 使用消息传递,以避免IO路径中使用锁
SPDK是一个框架而不是分布式系统,它的基石是用户态(user space)、轮询(polled-mode)、异步(asynchronous)和无锁的NVMe驱动,其提供了零拷贝、高并发直接用户态访问SSD的特性。SPDK的最初目的是为了优化块存储落盘性能,但伴随持续的演进,已经被用于优化各种存储协议栈。SPDK架构分为协议层、服务层和驱动层,协议层包含NVMeOF Target、vhost-nvme Target、iscsi Target、vhost-scsi Target以及vhost-blk Target等,服务层包含LV、Raid、AIO、malloc以及Ceph RBD等,driver层主要是NVMeOF initiator、NVMe PCIe、virtio以及其他用于持久化内存的driver等。
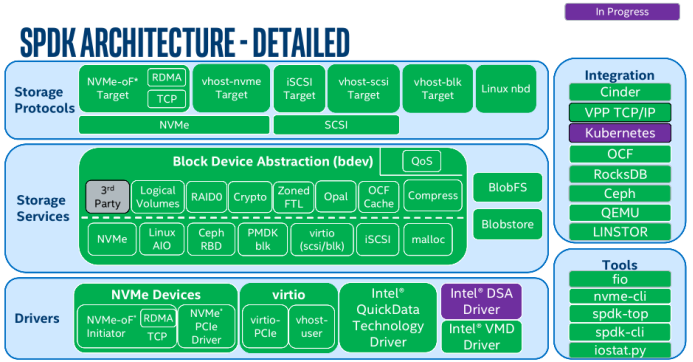
SPDK架构
Ceph是目前应用比较广泛的一种分布式存储,它提供了块、对象和文件等存储服务,SPDK很早就支持连接Ceph RBD作为块存储服务,我们在使用SPDK测试RBD做性能测试时发现性能到达一定规格后无法继续提升,影响产品的综合性能,经过多种定位方法并结合现场与代码分析,最终定位问题原因并解决,过程如下。
1.测试方法:启动SPDK nvmf_tgt并绑定0~7号核,./build/bin/nvmf_tgt -m 0xff,创建8个rbd bdev,8个nvmf subsystem,每个rbd bdev作为namespace attach到nvmf subsystem上,开启监听,initiator端通过nvme over rdma连接每一个subsystem,生成8个nvme bdev,使用fio对8个nvme bdev同时进行性能测试。
2.问题:我们搭建了一个48 OSD的Ceph全闪集群,集群性能大约40w IOPS,我们发现最高跑到20w IOPS就上不去了,无论增加盘数或调节其他参数均不奏效。
3.分析定位:使用spdk_top显示0号核相对其他核更加忙碌,继续加压,0号核忙碌程度增加而其他核则增加不明显。

查看poller显示rbd只有一个poller bdev_rbd_group_poll,与nvmf_tgt_poll_group_0都运行在id为2的thread上,而nvmf_tgt_poll_group_0是运行在0号核上的,故bdev_rbd_group_poll也运行在0号核。
[root@test]# spdk_rpc.py thread_get_pollers
{
"tick_rate": 2300000000,
"threads": [
{
"timed_pollers": [
{
"period_ticks": 23000000,
"run_count": 77622,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_tgt_accept"
},
{
"period_ticks": 9200000,
"run_count": 194034,
"busy_count": 194034,
"state": "waiting",
"name": "rpc_subsystem_poll"
}
],
"active_pollers": [],
"paused_pollers": [],
"id": 1,
"name": "app_thread"
},
{
"timed_pollers": [],
"active_pollers": [
{
"run_count": 5919074761,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_poll_group_poll"
},
{
"run_count": 40969661,
"busy_count": 0,
"state": "waiting",
"name": "bdev_rbd_group_poll"
}
],
"paused_pollers": [],
"id": 2,
"name": "nvmf_tgt_poll_group_0"
},
{
"timed_pollers": [],
"active_pollers": [
{
"run_count": 5937329587,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_poll_group_poll"
}
],
"paused_pollers": [],
"id": 3,
"name": "nvmf_tgt_poll_group_1"
},
{
"timed_pollers": [],
"active_pollers": [
{
"run_count": 5927158562,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_poll_group_poll"
}
],
"paused_pollers": [],
"id": 4,
"name": "nvmf_tgt_poll_group_2"
},
{
"timed_pollers": [],
"active_pollers": [
{
"run_count": 5971529095,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_poll_group_poll"
}
],
"paused_pollers": [],
"id": 5,
"name": "nvmf_tgt_poll_group_3"
},
{
"timed_pollers": [],
"active_pollers": [
{
"run_count": 5923260338,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_poll_group_poll"
}
],
"paused_pollers": [],
"id": 6,
"name": "nvmf_tgt_poll_group_4"
},
{
"timed_pollers": [],
"active_pollers": [
{
"run_count": 5968032945,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_poll_group_poll"
}
],
"paused_pollers": [],
"id": 7,
"name": "nvmf_tgt_poll_group_5"
},
{
"timed_pollers": [],
"active_pollers": [
{
"run_count": 5931553507,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_poll_group_poll"
}
],
"paused_pollers": [],
"id": 8,
"name": "nvmf_tgt_poll_group_6"
},
{
"timed_pollers": [],
"active_pollers": [
{
"run_count": 5058745767,
"busy_count": 0,
"state": "waiting",
"name": "nvmf_poll_group_poll"
}
],
"paused_pollers": [],
"id": 9,
"name": "nvmf_tgt_poll_group_7"
}
]
}
再结合代码分析,rbd模块加载时会将创建io_channel的接口bdev_rbd_create_cb向外注册,rbd bdev在创建rbd bdev时默认做bdev_examine,这个流程会创建一次io_channel,然后销毁。在将rbd bdev attach到nvmf subsystem时,会调用创建io_channel接口,因为nvmf_tgt有8个线程,所以会调用8次创建io_channel接口,但disk->main_td总是第一次调用者的线程,即nvmf_tgt_poll_group_0,而每个IO到达rbd模块后bdev_rbd_submit_request接口会将IO上下文调度到disk->main_td,所以每个rbd的线程都运行在0号核上。
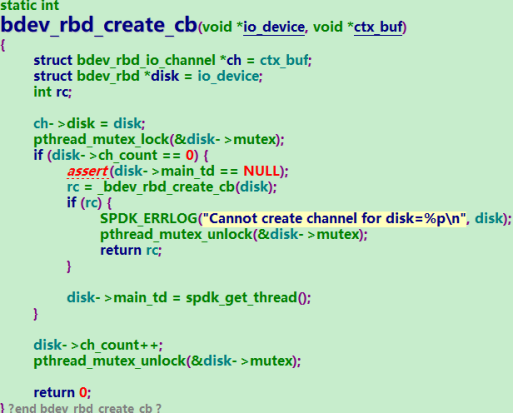

综合环境现象与代码分析,最终定位该问题的原因是:由于spdk rbd模块在创建盘时bdev_rbd_create_cb接口会将每个盘的主线程disk->main_td分配到0号核上,故导致多盘测试时CPU负载不均衡,性能无法持续提高。
4.解决方案:既然问题的原因是CPU负载不均衡导致,那么我们的思路就是让CPU更加均衡的负责盘的性能,使得每个盘分配一个核且尽可能均衡。具体到代码层面,我们需要给每个盘的disk->main_td分配一个线程,且这个线程均匀分布在0~7号核上。我们知道bdev_rbd_create_cb是在每次需要创建io_channel时被调用,第一次bdev_examine的调用线程是spdk主线程app_thread,之后的调用均是在调用者线程上执行,比如当rbd bdev attach到nvmf subsystem时,调用者所在线程为nvmf_tgt_poll_group_#,因为这些线程本身就是均匀的创建在0~7号核上,故我们可以复用这些线程给rbd模块继续使用,将这些线程保存到一个global thread list,使用round-robin的方式依次分配给每个盘使用,该方案代码已推送到SPDK社区:。打上该patch后,可以观察到CPU负载变得均衡,性能突破20w,达到集群40w能力。
5.思考回溯:该问题是如何出现或引入的?我们分析rbd模块的合入记录,发现在和对rbd的结构做了较大的变化,主要原因是rbd image有一把独占锁exclusive_lock,通过rbd info volumes/rbd0可查看,这把锁的作用是防止多客户端同时对一个image写操作时并发操作,当一个客户端持有这把锁后,其他客户端需要等待该锁释放后才可写入,所以多客户端同时写导致抢锁性能非常低,为此这两个patch做了两个大的改动:1)对每个rbd bdev,无论有多少个io_channel,最后只调用一次rbd_open,即只有一个rbd客户端,参见接口bdev_rbd_handle的调用上下文;2)对每个盘而言,IO全部收敛到一个线程disk->main_td发送给librbd。
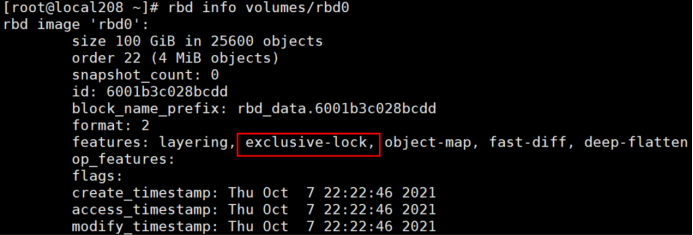
因为每个盘的disk->main_td均为第一个io_channel调用者的线程上下文,所以他们的线程都在同一个核上,导致IO从上游到达rbd模块后全部汇聚到一个核上,负载不均衡导致性能无法继续提高。
6.总结:在定位性能问题时,CPU利用率是一个重要的指标,spdk_top是一个很好的工具,它可以实时显示每个核的繁忙程度以及被哪些线程占用,通过观察CPU使用情况,结合走读代码流程,能够更快定位到问题原因。










