shell编程基础(shell脚本学习笔记)
文章目录
函数
一、函数基础
1.函数的定义和调用
函数是Shell脚本中自定义的一系列执行命令,使用函数最大的好处是可避免出现大量重复代码,同时增强了脚本的可读性。
在Shell中定义函数的方法如下 (其中function为定义函数的关键字,可以省略) :
#shell中的函数定义
#其中function为关键字,FUNCTION_NAME为函数名
function FUNCTION_NAME(){
command1 #函数体中可以有多个语句,不允许有空语句
command2
...
}
#省略关键字function,效果一致
FUNCTION_NAME(){
command1
command2
...
}
例如我们可以设计一个函数来计算指定文件的行数:
$ cat countLine.sh
#!/bin/bash
FILE='xxxxxxxxx' # 指定要检查的文件
function countLine(){
local i=0
while read line
do
let ++i
done<$FILE
echo "$FILE have $i lines"
}
echo "Call function countLine"
countLine # 函数调用
2.函数的返回值
函数的返回值又叫函数的退出状态,实际上是一种通信方式。
Shell中的函数可以使用“返回值”的方式来给调用者反馈信息(使用return关键字),不要忘了获取上一个命令返回值的方式是使用$?–这是获取函数返回值的主要方式。
下面我们以判断文件是否存在的函数为例:
$ cat check.sh
#!/bin/bash
echo -n "请输入文件名:"
read FILE
function checkFileExist(){
if [ -f $FILE ]; then
return 0
else
return 1
fi
}
echo "call function checkFileExist"
checkFileExist
if [ $? -eq 0 ]; then
echo "$FILE exist"
else
echo "$FILE not exist"
fi
二、带参数的函数
1.位置参数
有的时候某个脚本的变量写死了,这就造成每次运行脚本时就要修改代码,这是很麻烦的。像上面的countLine.sh脚本中定义了countLine函数,但是可以看到这个脚本实际上写死了FILE变量,这会造成想要判断不同的文件的行数,需要修改脚本中的FILE变量—也就是要对代码本身的内容进行修改,这也是典型的代码和数据没有分开而导致的问题。事实上,可以通过定义带参数的函数解决这个问题。在Shell中,向函数传递参数也是使用位置参数来实现的。
使用带参数的函数修改之前的check.sh脚本为check_2.sh,注意后面执行脚本时的传参方式。
$ cat check_2.sh
#!/bin/bash
function checkFileExist(){
if [ -f $1 ]; then
return 0
else
return 1
fi
}
echo "Call function countLine"
checkFileExist $1 # 函数调用
if [ $? -eq 0 ]; then
echo "$1 exist"
else
echo "$1 not exist"
fi
#执行脚本时,通过直接向脚本传递文件全路径的方式传递参数
#可以看到这种方式不会因为测试文件的不一样而修改脚本本身的内容,非常简单
$bash check_2.sh /etc/passwd
Call function countLine
/etc/passwd exist
2.指定位置参数值
除了在脚本运行时给脚本传入位置参数外,还可以使用内置命令set命令给脚本指定位置参数的值(又叫重置)。一旦使用set设置了传入参数的值,脚本将忽略运行时传入的位置参数(实际上是被set命令重置了位置参数的值)。
$ cat set1.sh
#!/bin/bash
set 1 2 3 4 5 6 #设置脚本的6个位置参数,其值分别是1 2 3 4 5 6
COUNT=1
for i in $@
do
echo "Here \$$COUNT is $i"
let "COUNT++"
done
#运行结果如下
#给脚本传入参数a b c d e f,但是由于脚本运行时“重置”了位置参数的值,所以打印出来的位置参数为脚本中设置的值
$ bash set01.sh a b c d e f
Here $1 is 1
Here $2 is 2
Here $3 is 3
Here $4 is 4
Here $5 is 5
Here $6 is 6
3.移动位置参数
在Shell中使用shift命令移动位置参数,在不加任何参数的情况下,shift命令可让位置参数左移一位。
$ cat shift_1.sh
#!/bin/bash
until [ $#-eq 0 ]
do
#打印当前的第一个参数$1,和参数的总个数$#
echo "Now \$1 is: $1,total parameter is:$#"
shift #移动位置参数
done
#运行结果
$ bash shift_1.sh a b c d
Now $1 is: a,total parameter is:4
Now $1 is: b,total parameter is:3
Now $1 is: c,total parameter is:2
Now $1 is: d,total parameter is:1
可以在shift命令后跟上向左移动的位数,比如说shift 2就是将位置参数整体向左移动两位。将上面的脚本修改一下后,运行结果如下:
#如果将shift_1.sh脚本中的shift改为shift 2,则位置参数将会每次移动两位,运行结果如下
$ bash shift_03.sh a b c d
Now $1 is: a,total parameter is:4
Now $1 is: c,total parameter is:2
三、函数库
对某些很常用的功能,必须考虑将其独立出来,集中存放在一些独立的文件中,这些文件就称为“函数库”。这么做的好处是在后期开发的过程中可以直接利用这些库函数写出高质量的代码。库函数的本质也是“函数”,所以它的定义方式和普通函数没有任何区别,但为了和一般函数区分开来,在实践中建议库函数使用下划线开头。
1.自定义函数库
由于Shell是一门面向过程的脚本型语言,而且用户主要是Linux系统管理人员,所以并没有非常活跃的社区,这也造成了Shell缺乏第三方函数库,所以在很多时候需要系统管理人员根据实际工作的需要自行开发函数库。下面建立一个叫lib01.sh的函数库,该函数库目前只有一个函数,用于判断文件是否存在。
$ cat lib01.sh
_checkFileExists(){
if [-f $1 ]; then
echo "File:$1 exists"
else
echo "File:$1 not exist"
fi
}
其他脚本在希望直接调用_checkFileExists函数时,可以通过直接加载lib01.sh函数库的方式实现。加载方式有如下两种:
#使用“点”命令
$ . /PATH/TO/LIB
#使用source命令
$ source /PATH/TO/LIB
假设现在有个脚本想要直接调用_checkFileExists函数,可以通过加载lib01.sh函数库来实现。
$ cat callLib01.sh
#!/bin/bash
source ./lib01.sh #引用当前目录下的lib01.sh函数库
_checkFileExists /etc/notExistFile #调用函数库中的函数
_checkFileExists /etc/passwd
#执行结果
$ bash callLib01.sh
File:/etc/notExistFile not exist
File:/etc/passwd exists
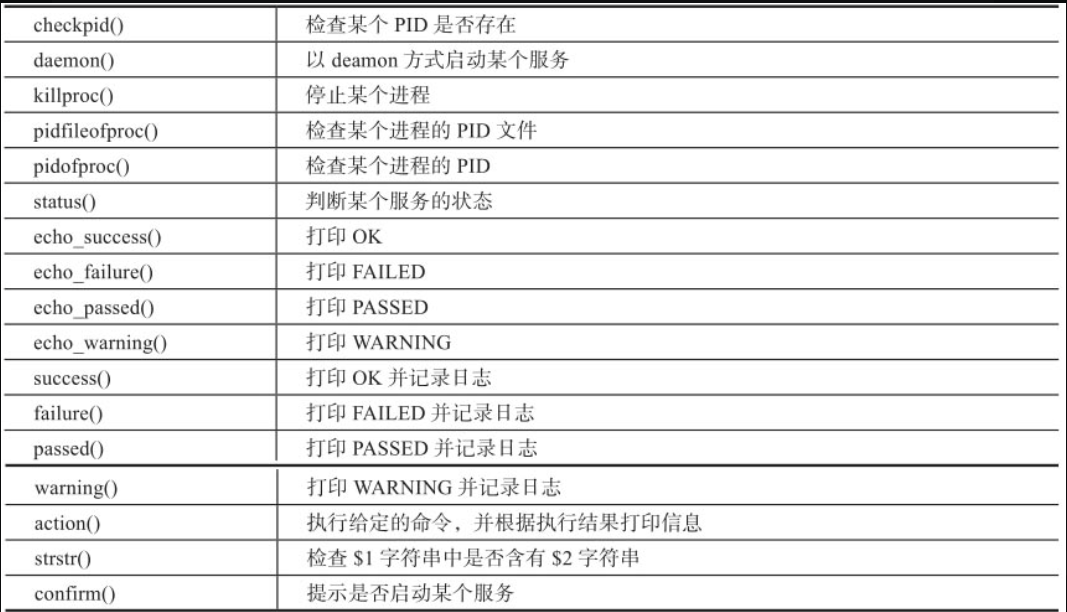
2.函数库/etc/init.d/functions简介
很多Linux发行版中都有/etc/init.d目录,这是系统中放置所有开机启动脚本的目录,这些开机脚本在脚本开始运行时都会加载/etc/init.d/functions或/etc/rc.d/init.d/functions函数库(实际上这两个函数库的内容是完全一样的)。
下表介绍functions函数库中的常用函数:
四、递归函数
在说明什么是“递归函数”之前,让我们先讲一段小故事:1987年在陕西省宝鸡市的法门寺残塔中发现了一个神秘的盒子,现场考古人员打开后发现里面又是一个盒子,如此一共打开了8个盒子中的盒子,最终发现了一枚佛祖舍利(后证实是个假舍利)。如果把“打开盒子”这种行为当作是一次“函数调用”,这里就一共调用了8次,如果把整个过程从运行程序的角度来描述就是:调用“打开盒子”函数打开第一个盒子,如果发现里面还是盒子,则继续调用“打开盒子”函数打开第二只盒子,以此类推,直到不再有盒子为止——这种“类推”的方法用程序中的术语解释就是“递归”,具有“递归”功能的函数则被称为“递归函数”。递归函数的典型特征为:在函数体中继续调用函数自身。
那么这里就出现了一个问题,如果这种递归毫无止境地执行下去,是不是就成了“无限循环”了?答案是肯定的,所以递归函数一定要有结束递归的条件,当满足该条件时,递归就会终止。典型的递归函数的结构如下所示:
function recursion() {
recursion
conditionThatEndTheRecursion #停止递归的条件
}
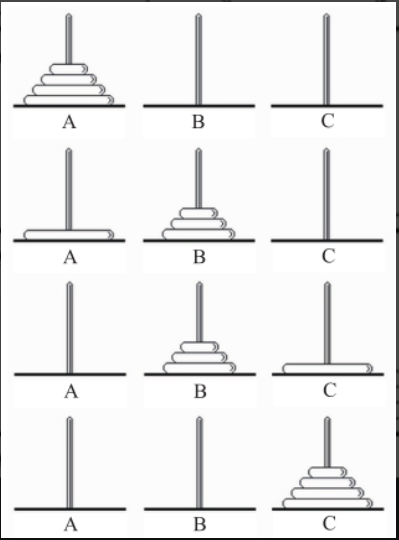
如果还是不清楚递归函数如何使用,那么我们就以一个典型的例子"汉诺塔"游戏为例,看看递归函数到底是整莫一回事。
该游戏源自印度一个古老的传说:在印度北部的贝拿勒斯神庙中,一块黄铜板上插着三根宝石针,其中一根从下到上穿了由大到小的64个金盘片,这就是所谓的汉诺塔。僧侣们不分白天黑夜地按照下面的法则移动这些金盘片,但必须满足以下两个条件:
- 一个只能移动一个盘片;
- 所有宝石针上的盘片只能是小的在大的上面。
僧侣们预言,当所有的金盘片都从最初所在的那根宝石针上移动到另一根上的时候,便是世界的尽头。实际上这只是一个传说。但我们可以用科学的算法算出这个游戏的复杂度为f(64)=2^64-1,如果按照正确的方法移动盘片,并且可以做到每秒移动一次,那也要耗费5845亿年—届时可能真的是世界的尽头了。
假设有n个盘片,我们的任务就是将A柱上的n个盘片搬移到C柱上。将动作分解为一下几步:
第一步,将A柱上的n-1个盘片搬移到B柱上(递归搬移);
第二步,将A柱上的一个盘片搬移到C柱上;
第三步,B柱上的n-1个盘片搬移到C柱上(递归搬移)。
代码如下:
$ cat hanoi01.sh
#! /bin/bash
function hanoi01()
{
local num=$1
if [ "$num" -eq "1" ];then
echo "Move:$2----->$4"
else
hanoi01 $((num-1)) $2 $4 $3
echo "Move:$2----->$4"
hanoi01 $((num-1)) $3 $2 $4
fi
}
echo -n "请输入盘片数:"
read number
hanoi01 $number A B C
$ bash hanoi01.sh
请输入盘片数:4
Move:A----->B
Move:A----->C
Move:B----->C
Move:A----->B
Move:C----->A
Move:C----->B
Move:A----->B
Move:A----->C
Move:B----->C
Move:B----->A
Move:C----->A
Move:B----->C
Move:A----->B
Move:A----->C
Move:B----->C










