transformer应用分为上游任务与下游任务。
上游任务指训练一个预训练模型,下游任务指在自然语言处理中完成的实际任务,如情感分析,标记,机器翻译。
1.transformer模型:
transformer和LSTM区别:LSTM一个字一个字训练,transformer采用并行训练
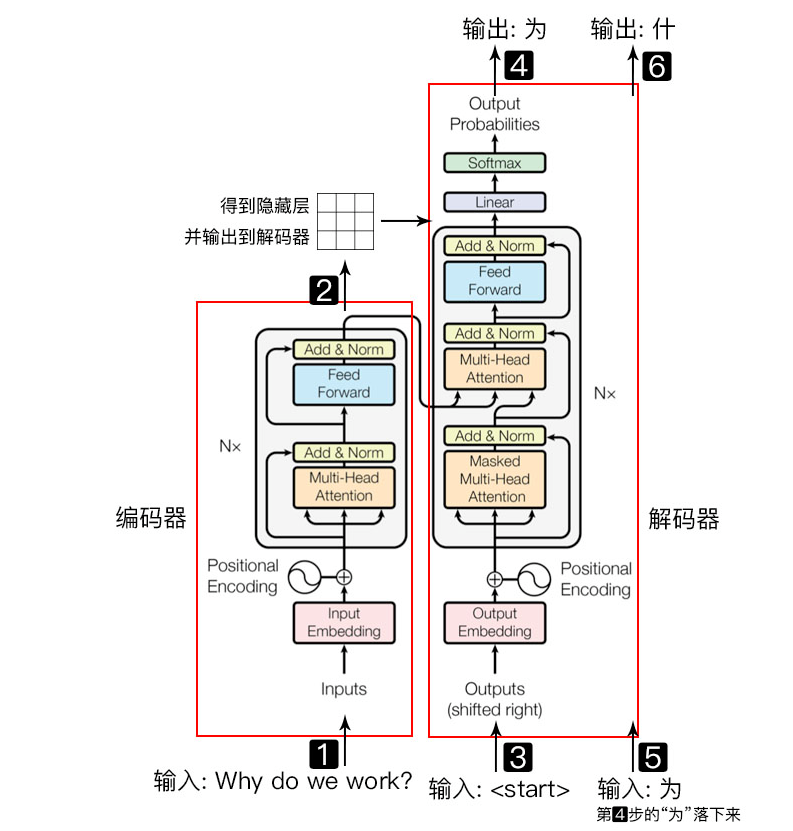
transformer模型主要分为两大部分, 分别是编码器和解码器, 编码器负责把自然语言序列映射成为隐藏层(下图中第2步用九宫格比喻的部分), 含有自然语言序列的数学表达. 然后解码器把隐藏层再映射为自然语言序列, 从而使我们可以解决各种问题, 如情感分类, 命名实体识别, 语义关系抽取, 摘要生成, 机器翻译等等, 下面我们简单说一下下图的每一步都做了什么:
- 输入自然语言序列到编码器: Why do we work?(为什么要工作);
- 编码器输出的隐藏层, 再输入到解码器;
- 输入$<start>$(起始)符号到解码器;
- 得到第一个字"为";
- 将得到的第一个字"为"落下来再输入到解码器;
- 得到第二个字"什";
- 将得到的第二字再落下来, 直到解码器输出$<end>$(终止符), 即序列生成完成.
Transformer编码器:

input embedding:从表中找到每个字的数学表达,即embedding dimension
batch size:句子个数
sequence leng th:句子长度
th:句子长度










