面对对象编程补充(1)
前面三节给大家详细解释了Python的基本语法和函数,相信现在大家对python的了解更深了一步。接下来我们继续来完成对面对对象编程的内容补充。
编码风格和文档
编码规则
对于编码风格,我们采取的主要原则如下:
- python代码块通常用4个空格表示,虽然缩进量等同于一个tab,但是python解释器视四个空格和一个tab为两种不同的字符,同一个代码块中不可以混用。此外,许多能识别Python语言的编辑器会自动使用适量的空格代替制表符(tab)。
- 标识符的命名要有意义,试着选择能反映行为、责任或以其命名数据的名字:
- 类(不同于内置类)应当以首字母大写的单数名词作为名字。当多个单词连接起来形成一个类的名字时,每个单词的首字母要大写,这就是“骆驼拼写法”
- 函数,包括类的成员函数(方法)要小写。如果将多个单词组合起来,他们彼此间要使用下划线隔开(例如make_payment)。函数的名字通常是用来描述它的作用的动词。但是,如果这个函数的唯一目的是返回一个值,那么函数名应该是描述该返回值的名词。
- 标识某个对象(如参数、实例变量、本地变量)名字应为一个小写的名词。当然如果我们需要大写字母来表示一个数据结构的名称时,会不遵守这条规则(如tree T)。
- 传统上用大写字母加下划线隔开每个单词的标识符代表一个常量值(例如MAX_SIZE)。
- 以单下划线开头的标识符(例如:_secret)意在表明它们只为类或模块“内部”进行使用,不作为公共接口的一部分。
以上规则只是一种约定俗成,即使违反这些规则也不会影响代码的实际运行、但是,为了代码的规范性,大家在书写代码时应自觉遵守这些规则。
文档
python使用docstring机制为在源代码中直接插入文档提供完整的支持。以list类为例:
class list(object):
"""
Built-in mutable sequence.
If no argument is given, the constructor creates a new empty list.
The argument must be an iterable if specified.
"""
从形式上讲,任何出现在模块、类、函数(包括类方法)主体的第一个语句的字符串都被认为是docstring。按照惯例,这些字符串限定在三引号中。通常,概述目的的一行作为开头,而后是一个空行,最后是进一步的细节描述。还可以使用形如help(list)来生成一个与标识符对象(此处为list)关联的文档docstring。
类定义
类是面对对象程序设计中抽象的主要方法。类的实例化代表了每个数据块,类以及实现它的所有实例给成员函数(方法)提供了一系列行为。
self标识符
self是一个特殊参数,作为类的内部函数必须有的一个参数,以反应其当前状态。self存储类实例的地址,确保了当一个类有多个实例时,每个实例的具体参数不会被混用。通过self可以找到类内定义的其他内容,可以调用成员的特定实例,也可以作为返回值使用:
class Progression:
def im(self,start=0):
#定义起始值
self.current=start
self.x=10
def srr(self):
self.im(10)
print(self)
return self # 返回类型为Progression,内容是类实例的实际地址
a=Progression()
b=a.srr() # b被赋予为self参数内容,因此实例中使用“self.”可以找到的内容
# 此后也均可通过“b.”找到
print(a) # a是一个实例,print(a)可以打印a的地址
# 可以观察一下这里打印的内容和方法中打印的self内容是否相同
print(b.current) # 尝试通过“b.”找到current内容
# 输出为:<__main__.Progression object at 0x000001D370E0A400>
# <__main__.Progression object at 0x000001D370E0A400>
# 10
从以上结果可以看出,打印出的a内容和函数里打印的self一致,而b又被赋予了self的值,因此,实例内使用self.可以调用的内容,我们在此通过a.或b.都可以调用。
类中可以通过self找到的常量叫做属性,它们的作用域是整个类;如果是成员函数内定义的普通常量,它们的作用域便是对应的成员函数内部。
通过对im()方法的调用可以看出,self函数不用也不能通过调用过程进行赋值,而除了self以外的参数,和普通函数的特点一样,支持默认参数、可变参数等,调用类的成员函数时,要对除self外的所有的参数进行赋值。
构造函数
构造函数是类的内部函数的一种,长相为__init__。它的特点是生成类的实例时会自动运行,因此他所需要的参数必须在实例化的过程中提供,示例如下:
class Progression:
def __init__(self,start):
self.current=start
a=Progression(10)
print(a.current)
b=Progression() # 由于缺乏参数,无法实例化
结果如下:

继承
组织各软件包结构组件的一种自然方法是在一个分层方式中,在水平层次上把类似的抽象定义组合在一起。下层的组件更具体,上层组件更通用。在软件开发中,层次设计是非常有用的。在通用的层次上可以把共同的功能分组,从而促进代码的重复使用,进而将行为间的差别视为通用情况的扩展。继承关系就可以视为一种结构组件,更有多层继承、多重继承。面对对象术语中,通常描述现有的类为基类、父类或超类,而新定义的类为子类。
有两种方式可以让子类有别于父类:
- 子类可以通过提供一个新的父类定义过的方法(覆盖原方法)实现方法的特化一个现有的行为;
- 子类可以通过提供一些全新的方法扩展其父类。
继承中的一些细则我会在后面给大家补充,这里浅提一嘴主要是为了给大家讲述封装和保护成员。
python的异常层次结构
在之前的补充中,我们给大家介绍了很多python的异常,这里再做一个补充。首先,我们用raise抛出的异常不能是自己臆想的,否则python就无法正常的抛出异常;其次异常也是有层次的,结构(部分)如下:
封装和保护成员
封装
封装是面对对象编程的另一个重要原则,它的优点是可以给程序员实现组件建细节的自由。封装提供了健壮性和适应性,因为它可以允许改变程序的部分细节而不影响其他部分。
在之前的编码风格中给大家介绍过,在数据成员名称前加一个下划线,表明它被设计为非公有的。类的用户不应该直接访问这样的成员。非共有的设计能够让我们更好地对所有实力执行一致的状态。
保护成员
成员包括属性和方法两种,因此后面的叙述中提到的非公有(受保护)和私有的访问模式针对属性和方法均成立。
前文提到非公有,理论上非公有成员可以在基类和子类中使用,但会限制其不能再实例中调用。但是python并没有规范这一点,即使我们将其写为非公有的,依然可以在实例中直接调用。因此需要我们程序员自觉遵守规则,不要在基类和子类外部直接调用非共有成员。
除了非公有成员,还有一种私有成员。私有成员的受保护范围更大,只能在对应类的作用范围内使用,在子类中都无法调用。我们看一个例子:
class Progression: # 基类
_first=10 # 受保护的属性
__second=20 # 私有的属性
class ChildProgression(Progression): # 子类
def test(self):
print(self._first)
print(self.__second)
b=ChildProgression()
print(b._first)
b.test()
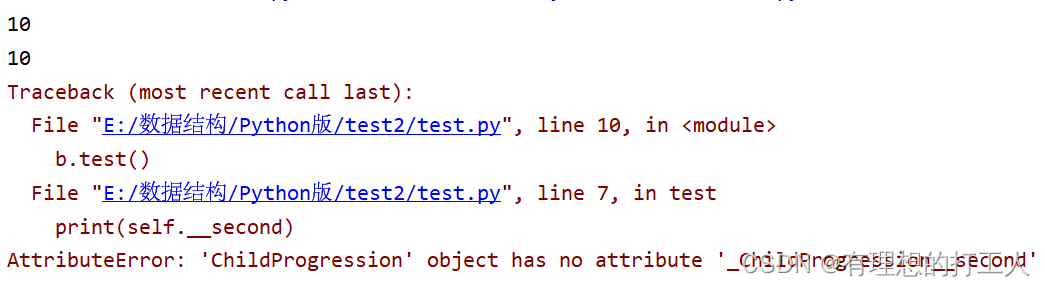
输出的第一个10代表了python允许类实例调用受保护的属性,第二个10代表子类也可以调用被保护的属性。证明python并没有做到保护成员。第七行和第十行的错误证明私有属性不能在子类中调用,大家也可以自行编写代码,证明该属性不能在实例中调用。这些结论对于属性成员成立,对于方法成员同样也适用,有兴趣的小伙伴可以自行尝试。
还有一点需要大家注意,如果一个类成员由双下划线开头,同样由双下划线结尾,那么他被看作是普通成员。
return self的实际应用
虽然return self返回的地址和类的实例化之后的地址是一致的,但是如果我们需要调用类方法方法中产生的内容,直接通过实例化得到的地址去寻找是行不通的,必须调用过该方法才行:
class Progression:
def use(self):
self.x=10
a=Progression()
print(a.x)
由于我们在通过地址调用x属性前并没有生成x属性,所以代码的运行会报错:
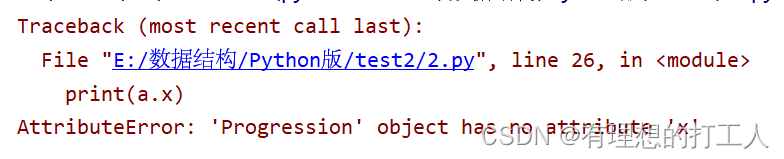
我们必须先调用use方法,才可以生成x属性:
class Progression:
def use(self):
self.x=10
a=Progression()
a.use() # 调用use方法,生成x属性
print(a.x)
# 输出为:10
但是这样就产生了一个麻烦,我们必须调用use方法之后再花一句话来进行打印。有什么方法可以一步到位吗?这就要靠return self了:
class Progression:
def use(self):
self.x=10
return self
a=Progression()
print(a.use().x)
# 输出为:10
下面我们再用一个例子对今天的内容做一个比较细致的总结:
class Progression:
_first=10
__second=20
def __im__(self,start=0):
#定义起始值
self._current=start
def __srr(self):
self.__im__(10)
self.x=self._first
self.y=self.__second
def use_srr(self):
self.__srr()
return self
a=Progression()
# a.__srr # 双下划綫的方法父类外部无法访问,子类中也无法访问
"""
return self最大的好处就是方便。如果不使用return self,我们只通过实例a来找到self.x属性
就必须先调用use_srr()方法,但是该方法返回值为None(没有返回值),
所以调用之后还需要再通过a.x才能找到。
"""
a.use_srr() # __srr()方法能在类的内部方法执行过程中使用,不能直接在实例中调用
print(a.x)
# 如果我们返回了self,就可以直接通过a.ues_srr().y直接获取y属性了
print(a.use_srr().y)
# 输出为:10
# 20
今天的探险就到这里了,如果概念部分大家没有太理解也没有关系,随之应用的增多,都会慢慢吸收的。
下一节,我们会继续探讨类的另一些特点,大家记得多多练习










