确实发现大神的文章都比较简单明了实用 - ICCV2017
计算机视觉-Paper&Code - 知乎
Abstract
https://arxiv.org/abs/1708.02002 https://arxiv.org/abs/1708.02002
https://arxiv.org/abs/1708.02002
总结主要为以下几点
- OHEM算法虽然增加了错分类样本的数量,但是直接把容易样本扔掉了,可会导致过杀率上升,作者同时也做了对比实验,AP有3.+的提升
- Focal Loss可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本
下面这张图展示了 Focal Loss 取不同的gama时的损失函数下降。

Algorithm
文章对最基本的对交叉熵进行改进,作为本文实验的baseline,既然训练的时候正负样本的数量差距很大,那么一种做法就是给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重。因此通过设定alpha的值来控制正负样本对总的loss的共享权重。alpha取比较小的值来降低负样本(样本数多的一类样本)的权重。
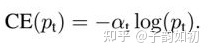
| loss | 样本多的类别 (如background) | 样本少的类别 |
|---|---|---|
| 正确分类 | 大幅下降 | 稍微下降 |
| 错误分类 | 正常下降 | 近乎保持不变 |
以上设计虽然可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重,因此引入1-pt减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。
关于gama调节作用解释如下:
当一个样本被正确分类的时候,pt接近于1,那么(1-Pt)会接近于0,则该损失值会很小,因此回传的梯度贡献就也很小了
当gama=0时候,就是上面的传统加权ce。gama值越大,难样本的loss权值则更大。实验里推荐最好的是gama=2,alpha=0.25
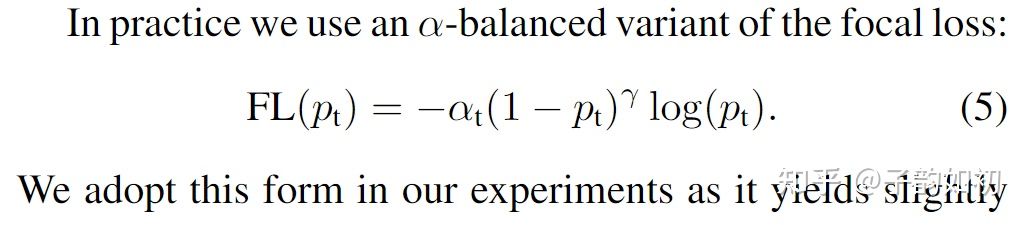
Summary
详细来说,检测算法训练初期会生成一大波的bbox。而一幅常规的图片中,一般仅仅只有几个需要检测的目标。因此绝大多数的bbox属于background
那么问题就来了因,为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高(不断的关注于background类,那么损失值就会越小,accuracy也就越高了)。因此会导致分类器训练失败,在验证集上检测精度自然就低了
且one stage detector直接在首波生成的类别极不平衡的bbox中就进行难度极大的细分类,意图直接输出bbox和标签。而原有交叉熵损失作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
对此二阶段就不会有一阶段这么大的问题,二阶段第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最初生成的anchor那样夸张了。就等于是从类别极不平衡变成了类别较不平衡。且在bbox筛选上例如Fasterrcnn会按给定数量和比例采样正负样本共采样指定个数样本
接着到了第二个stage时,在初筛过后的bbox上进行难度小得多的第二波细分类。这样一来,分类器得到了较好的训练,最终的检测精度就会高了。但是经过两个stage,操作计算复杂,检测速度就被严重拖慢了
Coding
code相对简单,如图。类CEloss可以考虑与dice loss等类IoUloss结合











