原创立文档免费下载
目标
正如标题所述,我们要免费下载原创立文档。
引用知乎的一篇文章:免费下载[原创力]的付费文档
针对的是不会写代码的朋友
思路
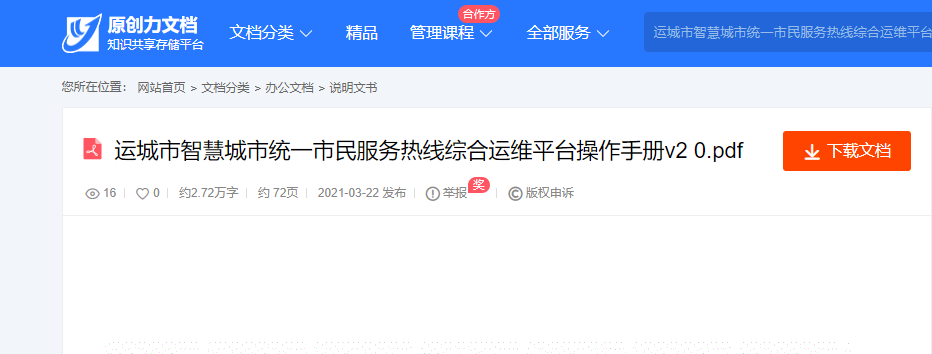
此次我们的目标是下载 运城市智慧城市统一市民服务热线综合运维平台操作手册v2 0.pdf
我们根据请求可以看到,该篇文章的每一页是以图片的形式显示的,所以我们就需要如何构造出请求,用于获取到所有的图片,之后将图片转换成pdf也就是思路。
所以思路:
下载所有的图片
我们发现,当page在1-6之间,返回的所有的数据都是1-6的数据。所以我们从page = 2 开始,每隔6页请求下一页数据,而且我们可以看到,总页数是72页的数据
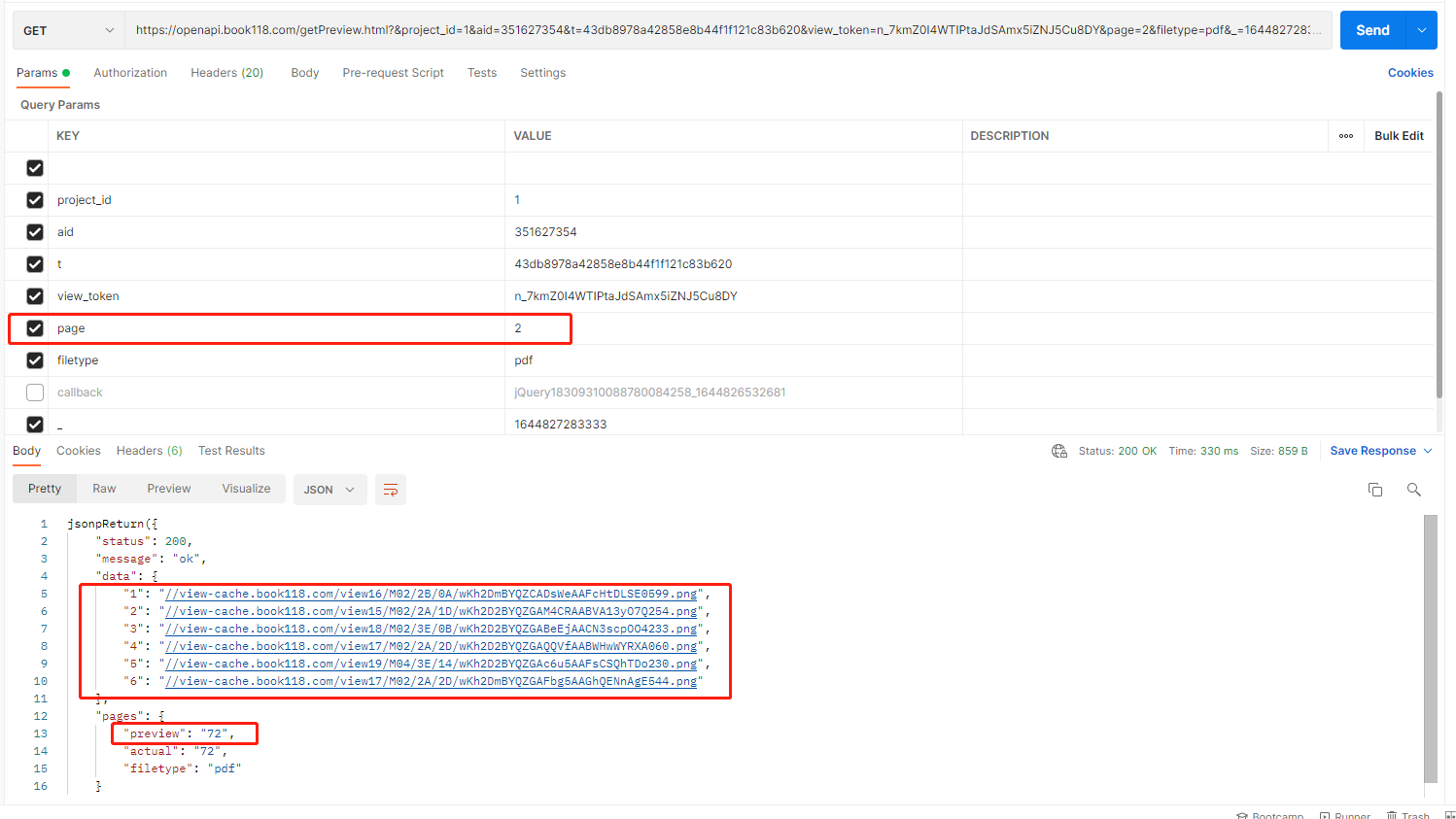
获取所有的图片地址
public void getFileName(){
// 1:先下载图片,之后
path = "C:\\test\\book118\\";
List<String> result = new ArrayList<>();
for (int page = 2; page <=72; page+=6 ){
String indexUlr = "https://openapi.book118.com/getPreview.html?&project_id=1&aid=351627354&t=43db8978a42858e8b44f1f121c83b620&view_token=n_7kmZ0I4WTIPtaJdSAmx5iZNJ5Cu8DY&page="+page+"&filetype=pdf&_=1644827283333";
String jsonStr = "";
try {
jsonStr = HttpUtils.get(indexUlr);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(jsonStr);
jsonStr = jsonStr.replace("jsonpReturn(","");
jsonStr = jsonStr.substring(0,jsonStr.lastIndexOf(");"));;
JSONObject JO = JSONObject.parseObject(jsonStr);
JSONObject dataJO = JO.getJSONObject("data");
Set<String> keySet = dataJO.keySet();
for (String key : keySet) {
String imgUrl = "http:" +dataJO.getString(key);
result.add(key +"\t" + imgUrl);
}
try {
Thread.sleep(5_000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
FileUtils.writeLines(new File("text.txt"),result);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("下载完成");
}
图片下载工具
public class DownLoadFileUtil {
//java 通过url下载图片保存到本地
public static void download(String urlString, String path,String fileName ) throws Exception {
// 构造URL
URL url = new URL(urlString);
// 打开连接
URLConnection con = url.openConnection();
// 输入流
InputStream is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
fileName = path + fileName + ".png"; //下载路径及下载图片名称
File file = new File(fileName);
FileOutputStream os = new FileOutputStream(file, true);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
System.out.println(fileName);
// 完毕,关闭所有链接
os.close();
is.close();
}
}
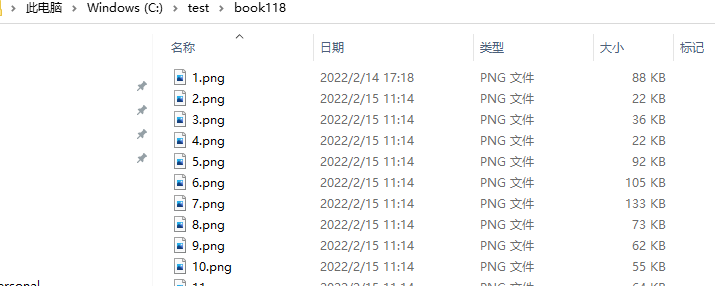
图片下载完成:
图片转换成pdf文档
public static void main(String[] args) throws Exception {
String fileName = "C:\\test\\book118\\%s.png";
String path = "C:\\test\\book118\\";
String[] paths = new String[72];
for (int i = 0; i < paths.length; i++) {
paths[i] = String.format(fileName,i+1);
}
File file = imageToPdf(paths);
file.delete();
}
public static File imageToPdf(String[] images) throws Exception {
File tempFile = File.createTempFile("expeortPDFt", ".pdf");
Document document = new Document();
PdfWriter.getInstance(document, new BufferedOutputStream(new FileOutputStream(tempFile)));
document.open();
for (String path : images) {
//获取图片对象
Image image = Image.getInstance(path);
float width = image.getWidth();
float height = image.getHeight();
if (width < height) {
//竖向
document.setPageSize(PageSize.A4);
//设置图片在PDF中的位置
image.setAbsolutePosition(30, 35);
//设置图片在PDF中的大小
//默认
image.scaleToFit(1024, 768);
} else {
//横向
document.setPageSize(PageSize.A4.rotate());
image.scaleToFit(770, 523);
float offsetX = (770 - image.getScaledWidth()) / 2;
float offsetY = (523 - image.getScaledHeight()) / 2;
image.setAbsolutePosition(36 + offsetX, 36 + offsetY);
}
document.newPage();
document.add(image);
}
document.close();
return tempFile;
}
pom相关的依赖信息
<properties>
<common-lang3.version>3.12.0</common-lang3.version>
<commons-io.version>2.8.0</commons-io.version>
</properties>
<dependencies>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.4.3</version>
</dependency>
<dependency>
<groupId>net.coobird</groupId>
<artifactId>thumbnailator</artifactId>
<version>0.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${common-lang3.version}</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>${commons-io.version}</version>
</dependency>
</dependencies>
总结:
思路:先下载图片,将图片转换成pdf
下载图片的时候,需要注意请求page的参数,每隔6个请求一次,不能频繁的请求,有可能获取不到数据,尽量多加一点睡眠时间
图片转pdf,读取图片需要有序,不然生成的pdf会是乱序的。









