KL散度是描述两个概率分布相似度的一种度量。
KL散度起源于信息论。信息论的主要目标是量化数据中有多少信息。信息论中最重要的指标称为熵,通常表示为H。熵没有告诉我们可以实现这种压缩的最佳编码方案。信息的最佳编码是一个非常有趣的主题,但对于理解KL散度而言不是必需的。熵的关键在于,只要知道所需位数的理论下限,我们就可以准确地量化数据中有多少信息。现在我们可以对此进行量化,当我们将观察到的分布替换为参数化的近似值时,我们丢失了多少信息。
KL散度是对熵公式的略微修改。不仅仅是有我们的概率分布p,还有近似分布q。然后,计算每个log值的差异。
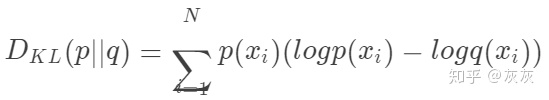
本质上,我们用KL散度看的是对原始分布中的数据概率与近似分布之间的对数差的期望。再说一次,如果我们考虑log2,我们可以将其解释为“我们预计有多少比特位的信息丢失”。我们可以根据期望重写公式:
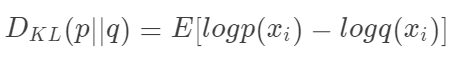
查看KL散度的更常见方法如下:
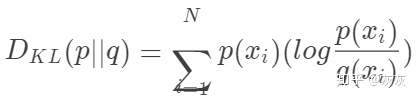
因为

利用KL散度,我们可以精确地计算出当我们近似一个分布与另一个分布时损失了多少信息。
KL散度不是距离。KL散度不是对称的,不能使用KL散度来测量两个分布之间的距离。










