JDK8默认使用ParallelGC收集器,也就是在新生代使用Parallel Scavenge收集器,老年代使用Parallel Old收集器。ParallelGC是吞吐量优先的垃圾回收器,目标是达到一个可控制的吞吐量(吞吐量=用户代码运行时间/虚拟机运行时间)。
JDK9默认使用G1垃圾回收器;
ParNew是除Serial新生代垃圾收集器外,唯一可以和CMS配合的垃圾回收器。
CMS是获取最短回收停顿时间为目标的收集器。
- 初始标记:标记GC Roots直接关联的对象(暂停用户线程);
- 并发标记:获取初始标记的节点作为根节点,并发标记对象;
- 重新标记:修正并发标记过程中变动的对象(暂停用户线程);
- 并发清除:并发清除对象;
- 虚拟机栈引用的对象;
- 本地方法栈中Native方法引用的对象;
- 方法区类静态属性引用的对象;
- 方法区中常量引用的对象;
- CPU资源敏感:并发阶段,虽然不停顿用户线程,但是GC线程会占用CPU资源,导致系统变慢。
- 浮动垃圾:并发清除阶段用户线程运行产生的垃圾只能等待下次GC回收;
- 预留空间:垃圾回收阶段用户线程还在运行,所以不能等待老年代几乎被填满在进行收集,需要在老年代预留空间,若CMS运行期间预留的内存无法满足需要,虚拟机会临时启动Serial Old收集器重新进行老年代的垃圾回收。
- 内存碎片:CMS采用的是“标记-清除”算法,所以会产生大量的内存碎片。内存碎片过多时,会给大对象分配带来麻烦,提前触发Full GC。
可以设置-XX:UseCMSCompactAtFullCollectionCMS默认开启,在Full GC的时候采用合并整理的过程,但是合并整理无法并发会导致停顿时间变长。还有一个参数-XX:CMSFullGCsBeforeCompaction,这个参数是用来指向多少次不压缩的Full GC跟着来一次压缩的。
这个要结合实际项目分析,是吞吐量优先还是低停顿时间优先。
停顿时间短,那么垃圾回收的频率就高,会使系统吞吐量低。
- 停顿时间短:适合于用户交互的程序,良好的响应速度会提升用户体验;
- 高吞吐量:适合后台运算而不需要太多交互的任务,可以高效率利用CPU时间,尽快完成程序的运行任务。
G1收集器前其他收集器的范围都是新生代或者老年代,G1将整个Java堆划分为大小相等的独立区域(Region)。新生代和老年代不再是物理隔离的。
并发更彻底:CMS只能在老年代进行并发收集,但是回收新生代时,ParNew还是要暂停整个应用。而G1整个收集过程几乎都是并发的。
用户可设置暂停时间:G1可以跟踪各个Region里面垃圾堆价值的大小(回收所获得的空间以及回收所需的时间值)。在后台维护了优先列表。根据允许的收集时间,优先回收价值大的Region。(注意:G1每次并不会回收整个内存,而是根据暂停时间来决定回收多少内存)。
减少内存碎片化:G1采用的是“标记-整理”的垃圾回收算法,可有效避免内存碎片的问题。
不需要,G1中每个Region都会有一个与之对应的Remember Set,JVM发现程序对引用类型的数据进行写操作时,会中断写操作,检查引用的对象是否处于不同的Region中。如果是,将引用对象所处的Region放入到Remember Set中。当进行垃圾回收时,在GC Roots的枚举范围加入Remember Set即可保证不全堆扫描也不会有遗漏。
G1每次并不会回收整个内存,而是根据用户配置的暂停时间回收内存。在内存非常吃紧的情况下,对内存进行部分回收根本不够,始终要对整个堆进行回收,那么G1做的工作量不会比其他垃圾回收器少,而且因为本身算法复杂一些,可能比其他回收器还要差。故G1比较合适内存稍大的一些应用(一般来说至少4G以上),小内存的应用还是传统的垃圾回收器比如CMS比较合适。
- 初始标记:标记GC Roots直接关联的对象(暂停工作线程)。
- 并发标记:以初始标记的节点作为根节点,进行并发标记;
- 最终标记:修正并发标记期间变动的对象(暂停工作线程)。
- 筛选阶段:根据用户期望的GC停顿时间制定回收计划。
虚拟机将这段时间对象变化记录在Remembed Set Logs中,最终标记/重新标记 将Remembed Set Logs数据合并到Remember Set中。需要停顿线程,但可并行执行。
(1)根据应用,在不影响FullGC的情况下,适当的扩大新生代内存。
(2)提高Survivor区利用率;
(3)大对象直接进入老年代,但注意不能频繁出现短命大对象;
(4)使用稳定的堆,即最大堆等于最小堆;
(5)设置对象进入老年代的年龄;
(6)根据项目选择合适的垃圾回收器
本着Full GC尽量少的原则,让老年代尽量缓存常用目标,JVM默认3:8也就是这个道理。还需要根据应用,看应用在峰值时年老代会占多少内存,在不影响FulGC的前提下,根据实际情况加大年轻代。
(1)将新对象预留在年轻代
FullGC的成本远远高于YGC,因此在某些情况下尽可能将对象分配在年轻代。虽然在大多数情况下,JVM会尝试在Eden区分配对象,但是由于空间紧张等问题,很可能不得不将部分年轻对象提前向年老代压缩。因此在JVM调优时可以为应用程序分配一个合理的年轻代空间,以最大限度避免新对象直接进入年老代的情况发生。
通过设置一个较大的年轻代预留新对象,设置合理的Survivor区并提供Survivor区的使用率,可以将新对象保存在年轻代,一般来说,Survivor区空间不够,或者占用率达到50%时,就会使对象进入年老代(不管它的年龄有多大)。
一般可以设置-XX:TargetSurvivorRatio=90,这样的话,可以提高Survivor的利用率。
(2)大对象直接进入年老代
很多情况下,我们会选择将对象分配在年轻代,但是对于占用内存比较多的大对象而言,它的选择可能就不是这样的。因为大对象出现在年轻代很可能会扰乱年轻代GC,并破坏年轻代原有的对象结构。因为尝试年轻代分配大对象,很可能会导致空间不足,为了有足够的空间容纳大对象,JVM不得不将年轻代的对象挪到年老代。因为大对象占用空间多,所以可能需要移动大量年轻对象进入年老代,这对GC相当不利。
基于以上原因,可以将大对象直接分配到年老代,保存年轻代对象结构的完整性,这样可以提高GC的效率,(但是若大对象是一个短命的对象,而这种情况出现很频繁,那么对于GC来说可能是一场灾难,因此在软件开发过程中,应该尽可能避免使用短命的大对象)。
一般使用-XX:PetenureSizeThreshold参数实现,当对象大小超过这个值时,将直接在年老代分配。
(3)设置对象进入年老代的年龄
堆中每一个对象都有自己的年龄(一般保存在对象头中mark word中)对象在年轻代每经过一次复制算法,对象年龄+1。当对象年龄达到阈值,就移入年老代,成为老年对象。
这个阈值的最大值可以通过参数-XX:MaxTenuringThreshold来设置,默认15。
(4)稳定的堆
一般来说,稳定的堆大小对垃圾回收时有利的。
-Xmx:堆内存最大限制;
-Xms:对内存最小限制;
如果这样设置,系统在运行时堆大小理论上是恒定的,稳定的堆空间可以减少GC的次数。但是不稳定的堆也不是毫无用处的。稳定的堆大小虽然可以减少GC次数,但同时也增加了每次GC的时间。让堆大小在一个区间中震荡,在系统不需要使用大内存时,压缩堆空间,使GC有一个较小的堆,可以加快单次GC的速度。
(5)选择合适的垃圾回收器
若是系统吞吐量优先,可以选择Parallel Scavenge+Parallel Old。若是响应时间优先,可以选择ParNew+CMS。若是项目内存比较大,可以选择G1回收器。
- 强引用:最常见引用,把一个对象赋给一个引用变量,这个引用变量就是强引用。当一个对象被强引用变量引用时,它处于可达状态,即不可能被垃圾回收机制回收。强引用是造成JAVA内存泄漏主要原因之一。
- 软引用:通过
SoftReference类实现,对于软引用的对象来说,当系统内存足够时它不会被回收,当系统内存空间不足时它会被回收。软引用通常用在内存敏感的程序中。 - 弱引用:只要发生GC,就被回收。常见的ThreadLocalMap的key就是弱引用。
- 虚引用:不能单独使用,主要作用是跟踪对象被垃圾回收的状态。
2. 类加载器相关
启动类加载器(BootStrap):加载的是<JAVA_HOME>/lib中的class文件,也就是JDK的依赖。
拓展类加载器(Extension):加载的是<JAVA_HOME>/lib/ext目录下或者由系统变量-Djava.ext.dir指定位路径中的类库。
应用程序加载器(AppClassLoader):程序默认加载器,加载用户类路径上指定的类库。
如果一个类加载器收到类加载请求,它首先不会自己去尝试加载这个类,而是把这个请求分派父加载器去完成,每一层次的类加载器都是如此,因此所有类加载请求最终都应该传送到顶层的启动类加载器(BootStrap ClassLoader)中,只有父加载器反馈自己无法完成这个加载请求(即:它搜索范围中没有找到所需的类)时,子加载器自己才会尝试去加载。
双亲委派模型解决的是:各个类加载器基础类统一的问题(越基础的类由上层类加载器进行加载)。
当JDK定义了SPI接口。SPI的实现类一般是由应用加载器(Application ClassLoader)加载,而JDK提供的SPI接口是Bootstrap ClassLoader加载,也就导致了SPI接口无法找到对应的实现类,根本原因:并不是同一个类加载器加载。为了解决这种情况,JVM设计出线程上下文加载器,来打破双亲委派,即父类使用子类的类加载器来进行类加载。保证父子类由一个类加载器完成加载。
3. JVM内存结构
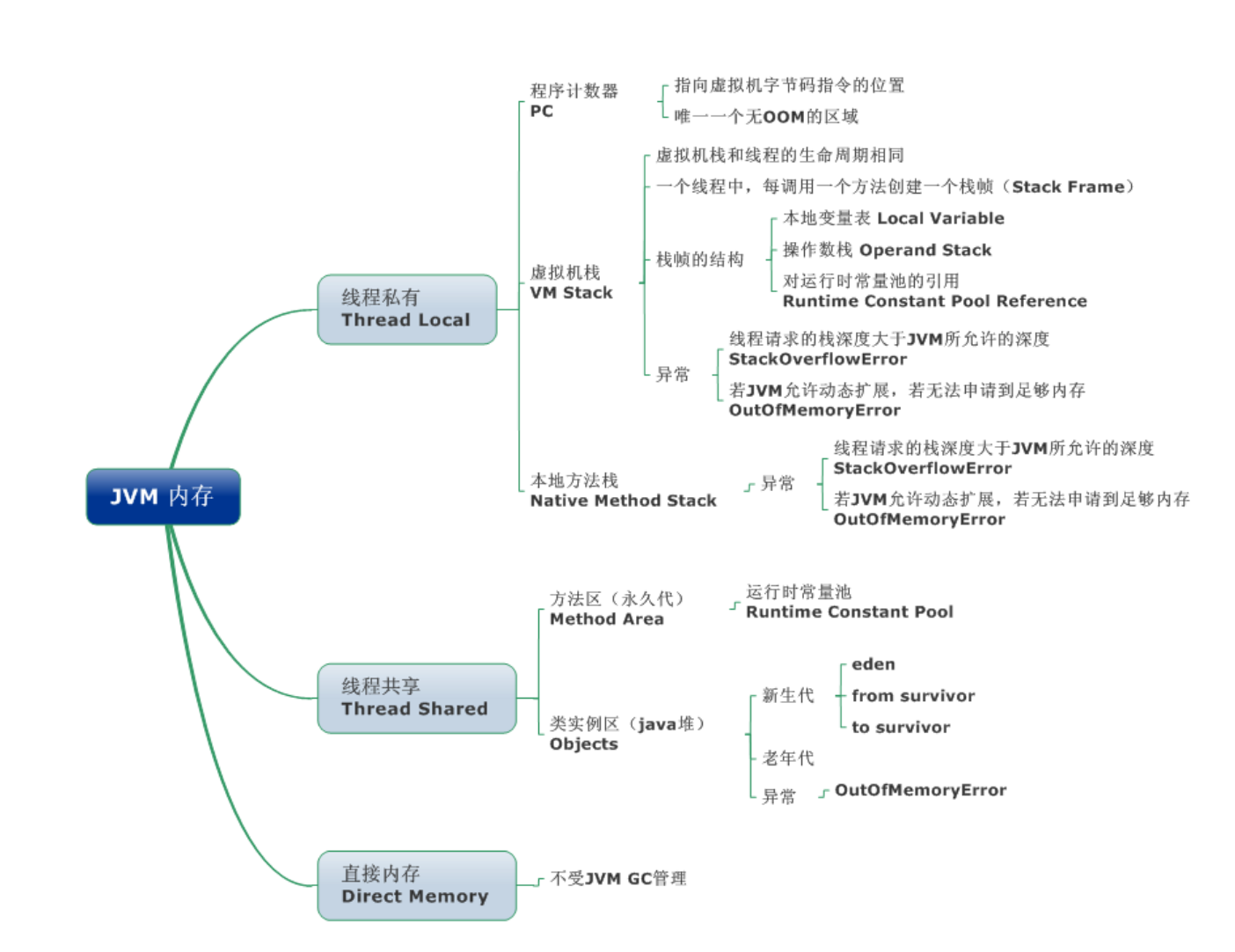
相关阅读
JVM那点事-垃圾收集算法
JVM那点事-垃圾收集器(1次10ms的GC和10次1ms的GC,你会选哪个?)
JVM那点事-对象的自救计划(对象被设为null会被回收吗?)










