文章目录
传送门:
- 李沐论文精读系列一: ResNet、Transformer、GAN、BERT
- 李沐论文精读系列二:Vision Transformer、MAE、Swin-Transformer
- 李沐论文精读系列三:MoCo、对比学习综述(MoCov1/v2/v3、SimCLR v1/v2、DINO等)
- 李沐论文精读系列四:CLIP和改进工作串讲(LSeg、GroupViT、VLiD、 GLIPv1、 GLIPv2、CLIPasso)
- 李沐论文精读系列五:DALL·E2(生成模型串讲,从GANs、VE/VAE/VQ-VAE/DALL·E到扩散模型DDPM/ADM)
- 李沐论文精读系列六:端到端目标检测DETR、最简多模态ViLT
- 李沐论文精度系列之七:Two-Stream双流网络、I3D

一 、前言
1. 为什么要做视频?
- 视频包含更多信息,符合多模态发展趋势:视频包含了时序信息、声音&图像等多模态信息,而且自然界也都是连续信息而非静止的图像。
- 视频天生能提供一个很好的数据增强,因为同一个物体在视频中会经历各种形变、光照变换、遮挡等等,非常丰富而又自然,远比生硬的去做数据增强好得多
- 视频处理是未来突破的方向:目前计算机视觉领域,很多研究热衷于在ImageNet等几个榜单刷分,往往训练了很大的模型,使用很多的策略,也只能提高一点点,类似深度学习出现前CV领域中机器学习的现状,已经达到了一个瓶颈期。要想突破必须有新的网络结构,指标之一就是要能很好地处理视频数据。
总之,如何更好的利用视频数据,如何更好的做视频理解,可能是通往更强人工智能的必经之路。
2. 视频领域发展历程
《A Comprehensive Study of Deep Video Action Recognition》是2020年视频领域的一篇综述论文,总结了 Video Transformer之前的约200篇用深度学习做视频理解的论文。本文基于此,讲解视频理解领域的发展。下图时间线概括了从早期卷积神经网络做视频理解的DeepVideo,到双流网络及其变体、3D网络及其变体的一系列过程。最后会讨论一下基于 Video Transformer的工作。
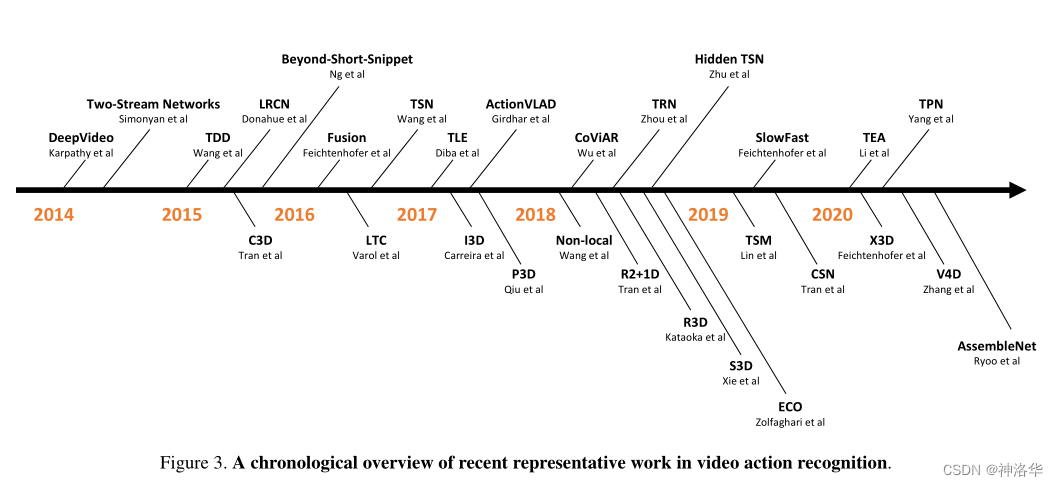
本文分四个部分来讲解:
- DeepVideo(早期视频领域的CNN工作)
- Two-Stream及其变体
- 3D CNN及其变体
- Video Transformer:将image transformer延伸到video transformer。其中很多方法都是从2或者3里面来的,尤其是借鉴了很多3D CNN里面的技巧。
二、 DeepVideo(IEEE 2014)
2.1 模型结构
DeepVideo是深度学习时代早期,使用CNN处理视频的代表工作,其主要研究的,就是如何将CNN从图片识别领域应用到视频识别领域。
视频和图片的唯一区别,就是多了一个时间轴,也就有很多的视频帧。下面是作者用CNN处理视频帧的的几种尝试:
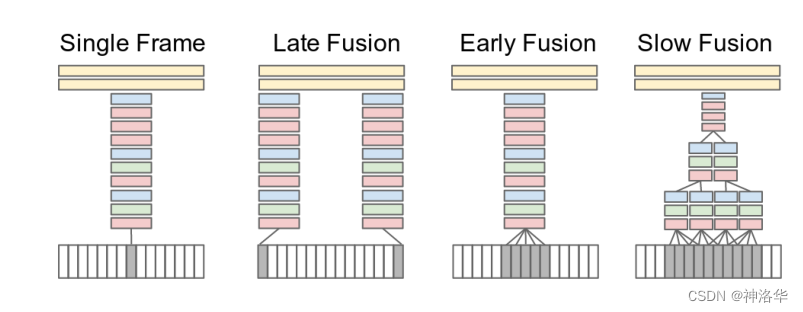
Single Frame:单帧方式的baseline。从视频帧中任取一帧,经过CNN层提取特征,再经过两个FC层得到图片分类结果。所以这种方式完全没有时序信息、视频信息在里面Late Fusion:多个单帧特征融合:- 之所以叫Late,就是在网络输出层面做的融合。
- 具体来说,就是任选一些帧,单独通过CNN得到图片特征(这些CNN权值共享);再将这些输出特征融合之后,过一个FC层得到分类结果。
- 这种单帧输入方式还是比较像图片分类,但毕竟融合了多帧的结果,还是包含一些时序信息的
Early Fusion:直接在输入层面做融合。- 将五张视频帧在RGB层面融合,融合后channel从3增加到15(CNN第一层的卷积核通道数也得改成15),后面结构不变
- 直接在输入层面就融合时序信息
Slow Fusion:网络中间的特征层面做融合。- 输入10个连续的视频帧,每4帧通过一个CNN抽特征,每个CNN都是权值共享,这样得到4个特征片段。再通过两个CNN网络,两两融合成为2个特征,直到最后融合成一个视频特征,加上两个FC层做分类。
- 网络从头到尾都是对整个视频在学习,这种方式最麻烦,效果也最好
2.2 实验结果
只是作者没想到的是,这四种方式的最终结果差别都不大,而且即使在Sports-1M(100万视频)这么大的数据集上预训练,最终UCF-101(13000+视频)这个小数据集上微调,结果也只有65%,效果还远远比不上之前的手工特征。

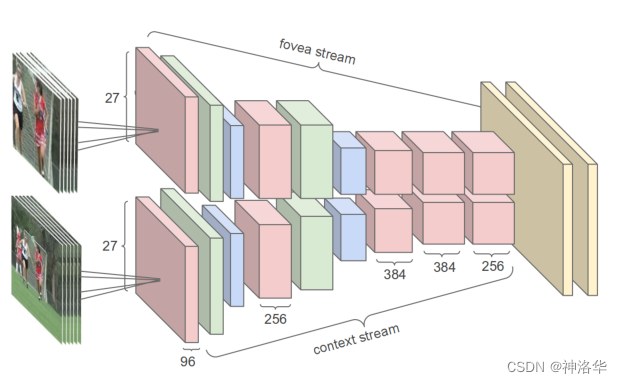
作者又试了一下,使用一些图片处理上的trick,比如输入多分辨率的图片,看能否在视频分类上也得到更好的结果。如下图所示,使用了两个网络(权值共享),输入分别是原图和center crop之后的图片,作者希望借此学习全局信息和中心重点区域信息。加入多分辨率操作,精度大概提升了一个点。
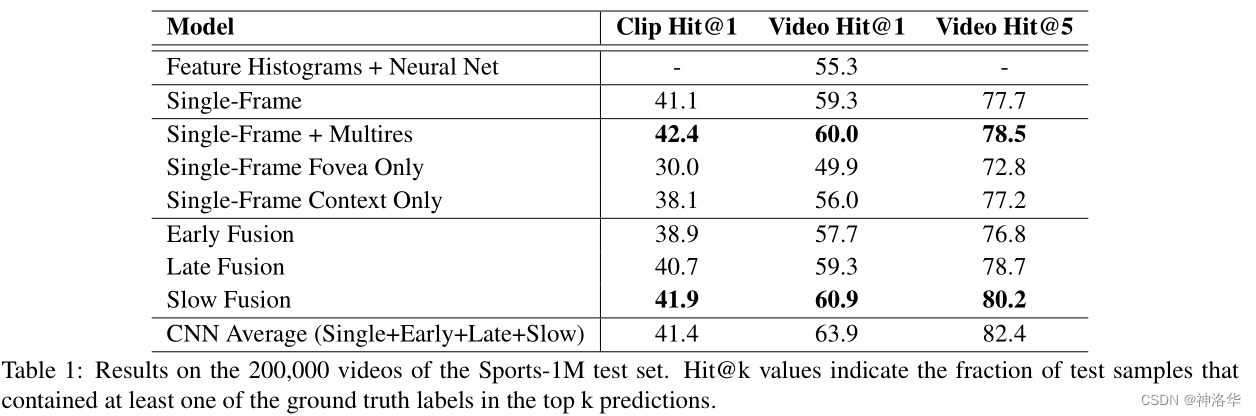
从下图可以看到,Early Fusion和Late Fusion效果还不如Single Frame的baseline,Slow Fusion经过一顿操作之后,才提高了一点点。
2.3 总结
DeepVideo把使用CNN直接处理视频的各种方式都试了一遍,为后续工作做了一个很好的铺垫。除此之外,作者还提出了一个特别大的视频数据集——Sports-1M数据集(有一百万视频,但是基本都是运动类,应用场景有些受限)。
三、双流网络及其变体
3.1 Two-Stream(NeurIPS 2014)
3.1.1 简介
视频相比图片的区别,就是多了一个时序信息(运动信息),如何处理好时序信息,是视频理解的关键。当一个网络无法很好地处理时序信息的时候,可以考虑再加一个网络专门处理时序信息就行。
光流包含了非常准确和强大的物体运动信息在里面,双流网络通过额外引入一个时间流网络,巧妙的利用光流提供的物体运动信息,而不用神经网络自己去隐式地学习运动特征,大大提高了模型的性能(UCF-101精度达到88%,基本和手工特征IDT的精度87.9%持平,远高于 DeepVideo 65.4%的精度)。
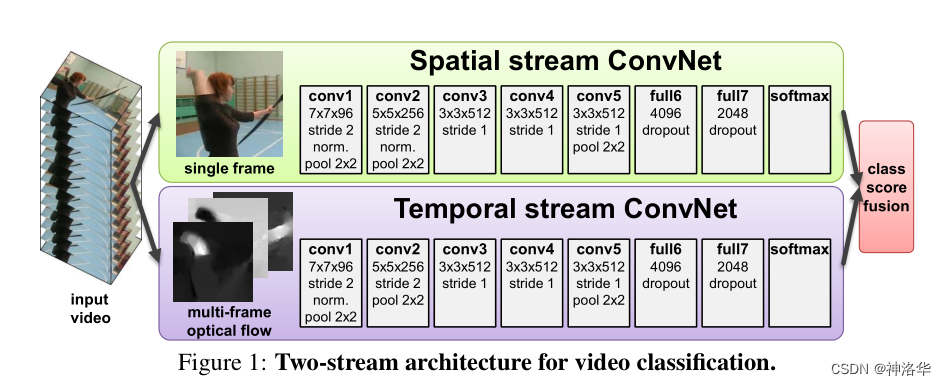

3.1.2 改进工作
从上面双流网络的结构图,可以看到会有几个明显可以改进的地方:
Slow Fusion:理论上来说,在中间的特征层面做融合,肯定比最后在网络输出上简单的进行加权平均的效果要更好- 优化backbone:双流网络使用的backbone是Alexnet,所以自然想到可以使用更优的backbone
- 融入LSTM:考虑在网络抽取特征后加入LSTM模型,进一步处理时序信息,得到更强的视频特征
- 长时间视频理解:双流网络输入的光流只有10帧,算下来不到0.5秒,非常的短。一般一个动作或者事件可能会更长。如果要做长时间视频理解,还需要改进
下面针对每个方向,分别介绍一个代表性工作。
3.2 Two stream +LSTM(CVPR 2015 )
3.2.1 模型结构
原始的双流网络,空间流输入是一帧或几帧视频帧,时间流输入是10帧光流,只能处理很短的视频。如果是长视频,有特别多的视频帧,首先想到的还是用CNN去抽取视频特征,但关键是抽取的特征如何去做pooling。本文探索了6种pooling方法,最后结果差不多,conv pooling稍微好一点。另外还作者还试了使用LSTM做特征融合,最后提升有限。作者做的pooling和LSTM操作,如下图所示:
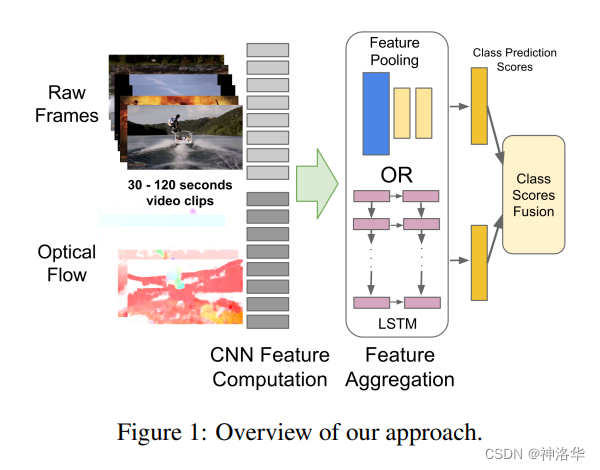
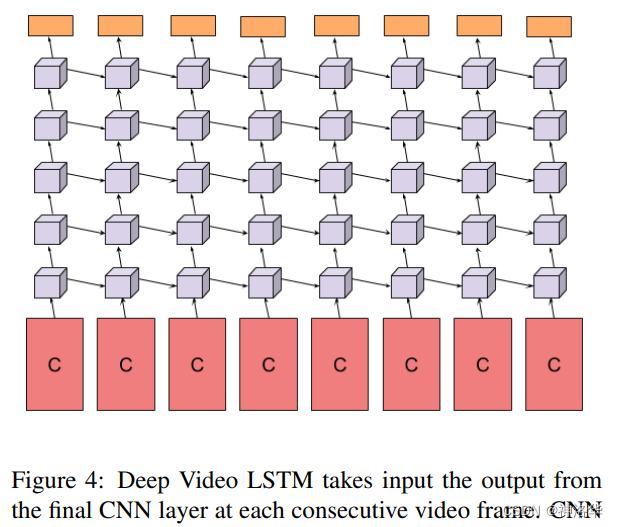
具体的LSTM操作如下图所示,C表示最后一层CNN输出的特征,每个视频帧都对应了一个特征。这些特征是有时序的,所以将其用5层的LSTM处理抽取的视频特征,最后的橘黄色这一层代表直接做softmax分类了。
简单说,就是从双流网络抽取特征之后直接做softmax分类,改为抽取特征后进行LSTM融合,再做softmax分类。
3.2.2实验结果
- conv pooling效果最好
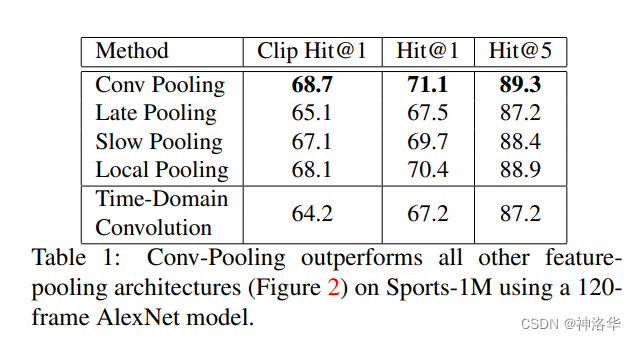

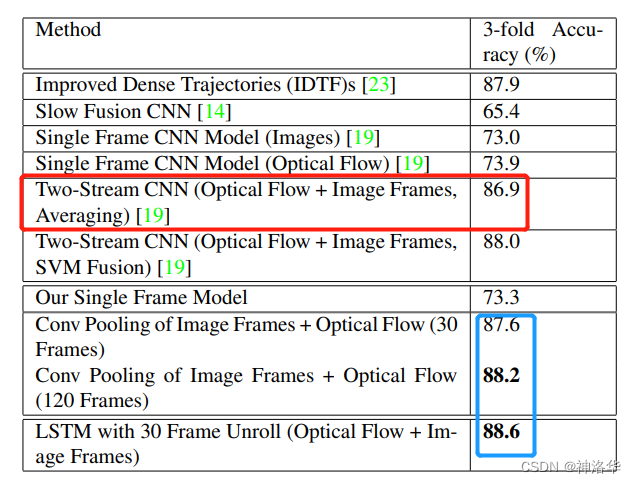
- Slow Fusion就是DeepVideo的结果,Single Frame就是DeepVideo论文中的baseline。
- conv pooling和LSTM:都能处理非常多的视频帧,模型效果相比光流网络,稍有提升。
也就是说,在UCF-101这种只有六七秒的短视频上,LSTM带来的提升非常有限。这也是可以理解的,因为LSTM操作,应该是一个更high level,有更高语义信息的一种操作,其输入必须有一定的变化,才能起到应有的作用,才能学到时序上的改变。如果视频太短,可能其语义信息基本没有改变,对LSTM来说,各个时序上的输入基本都是一样的,所以它也学不到什么东西。如果是在长视频或者变化比较剧烈的视频上,LSTM可能更有用武之地。
3.3 Two-Stream+Early Fusion(CVPR 2016 )
双流网络叫Two-Stream Convolutional Network,这篇论文题目是将其颠倒了一下,但关键词是Fusion。本文非常细致的讨论了如何去做双流网络特征的合并,主要是三个方向:
- spatial fusion(空间融合):下图展示了如何在空间上做Early Fusion,即如何将两个特征图上相同位置的点做合并
- temporal fusion(时间融合)
- 特征融合位置
作者通过解决这三个问题,得到了一个非常好的Early Fusion网络结构,比之前直接做Late Fusion的双流网络,效果好不少。
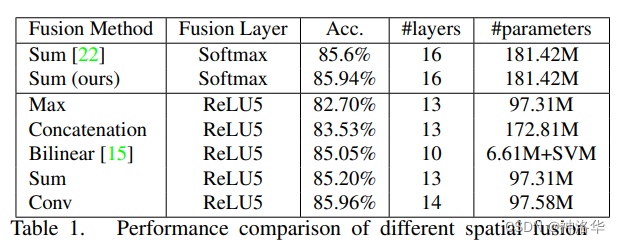
3.3.1 spatial fusion
在有了时间流和空间流两个网络之后,如何保证这两个网络的特征图在同样的位置上的channel responses是能联系起来的(To be clear, our intention here is to fuse the two networks (at a particular convolutional layer) such that channel responses at the same pixel position are put in correspondence.),也就是在特征图的层面去做融合。作者对此作了几种尝试:(融合层有两个输入 x t a + x t b x_t^a + x_t^b xta+xtb,输出为 y y y)
- Sum Fusion : y s u m = x t a + x t b y^{sum} = x_t^a + x_t^b ysum=xta+xtb,两个特征图直接相加
- Max Fusion : y m a x = m a x ( x t a , x t b ) y^{max} = max(x_t^a, x_t^b) ymax=max(xta,xtb),即特征图a和b在同一位置只取最大值
- Concatenation Fusion : y c a t = c a t ( x t a , x t b ) y^{cat} = cat(x_t^a, x_t^b) ycat=cat(xta,xtb),将两个特征图在通道维度做合并
- Conv Fusion : y c o n v = y c a t ∗ f + b y^{conv} = y^{cat} * f + b yconv=ycat∗f+b,将两个特征图堆叠之后再做一个卷积操作
- Biliner Fusion : y b i l = ∑ j = 1 H ∑ i = 1 M x i , j a ⊗ x i , j b y^{bil} = \sum_{j=1}^H\sum_{i=1}^M x_{i,j}^a \otimes x_{i,j}^b ybil=∑j=1H∑i=1Mxi,ja⊗xi,jb。在两个特征图上做一个外积,然后再做一次加权平均。
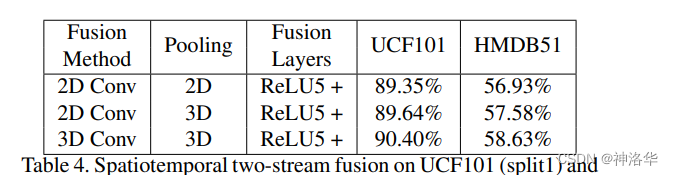
不同融合方式的效果如下,表现最好的是Conv fusion:
3.3.2 特征融合位置
关于在哪一层做融合效果最好,作者作了大量的消融实验,效果最好的两种方式如下:
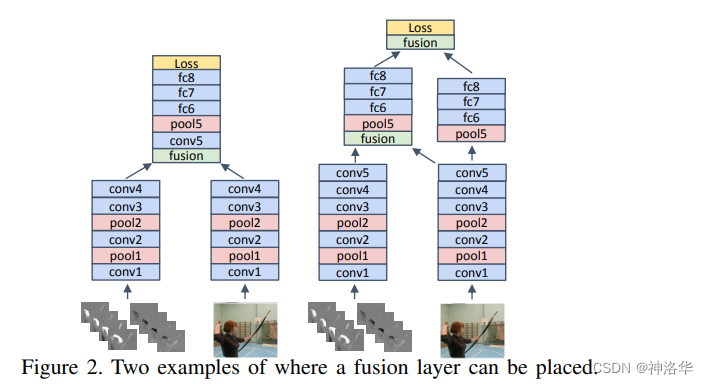
- 两个网络在Conv4之后,就做一次融合,然后就变为一个卷积神经网络了
- 在conv5和fc8两个层都分别做一次融合
- 将空间流的conv5特征拿过来和时间流的conv5特征合并,最后时间流得到一个 spatial temporal feature(时空特征)。同时空间流继续做完剩下层,得到一个完整的空间流特征。在最后的fc8层,再做一次合并。
- 相当于还没有学到特别high level的语义信息时,先做一次融合,用空间流特征取帮助时间流去学习。然后在fc8层high level级别上再做一次合并。
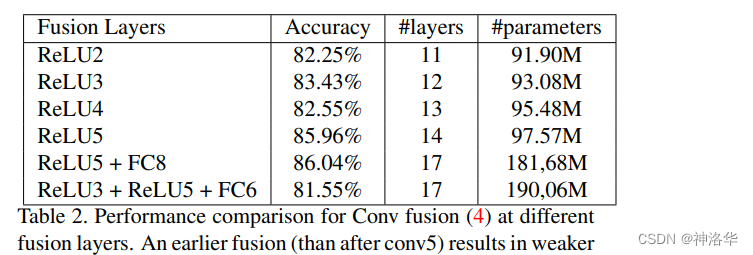
下面是试验结果,晚融合(relu5)和多融合(relu5+fc8)效果最好,但是多融合训练参数多一倍。
3.3.3 temporal fusion
temporal fusion就是抽取多个视频帧的特征之后,如何在时间轴位置将这些特征融合。作者3尝试了两种方式:3D Pooling和3D Conv+3D Pooling,后一种方式性能最好。
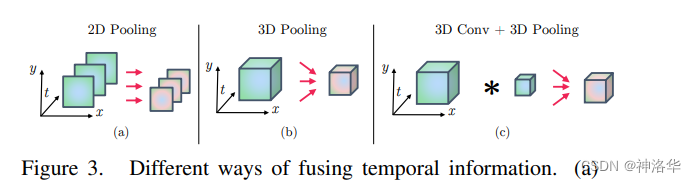
- a:2D Pooling完全忽略了时序信息
- b:3D Pooling:先在时间维度堆叠各个特征图,再做Pooling
- c:3D Pooling之前先做一次3D卷积
3.3.4 模型结构和最终效果
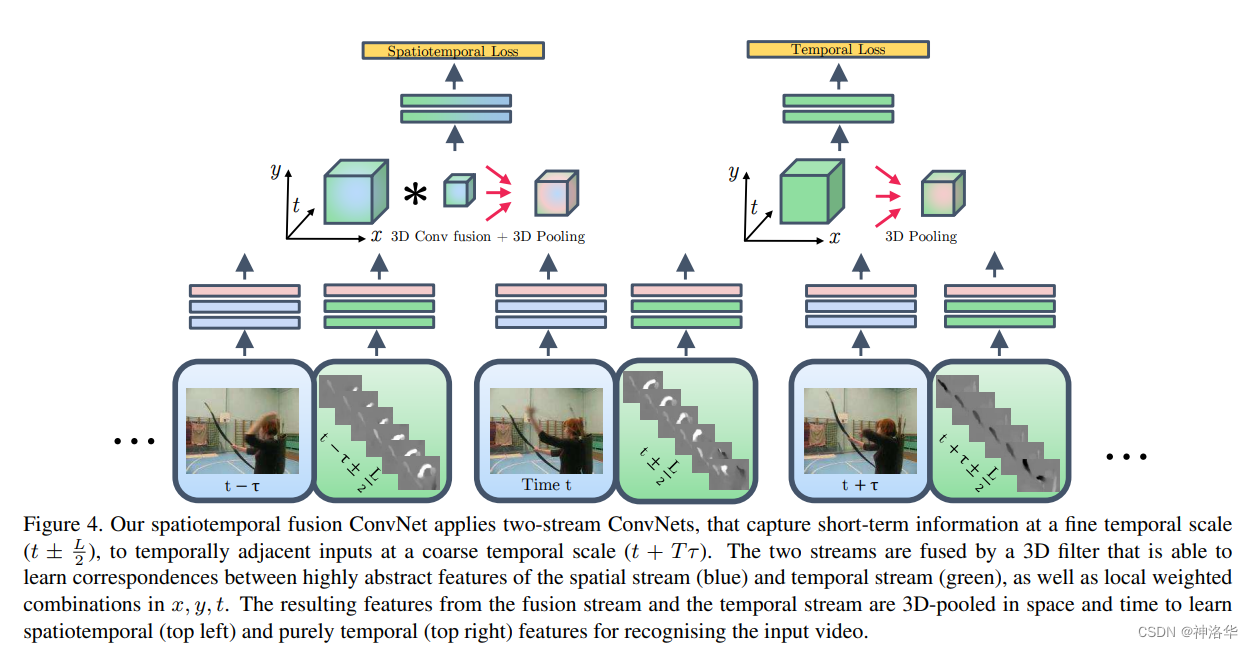
- 网络输入是
[t-τ,t+τ]时刻的RGB图像输入和对应的光流输入,蓝色代表空间流网络,绿色代表时间流网络。 - 时空融合:先分别从两个网络抽取特征,然后在Conv5这一层先做一次Early Fusion(3D Conv+3D Pooling),融合后用FC层得到最后的融合特征,这个特征就包含了时空信息
- 时间流融合:因为时间流特征非常重要,所以将时间流特征单独拿出来也做一次3D pooling,再接FC层,并专门设计一个时间上的损失函数Temporal Loss。
也就是这个模型有两个分支:时空学习和时序学习,对应的也有两个损失函数Spatiotemporal Loss 和Temporal Loss。推理时,两个分支的输出做一次加权平均。最后结果如下:
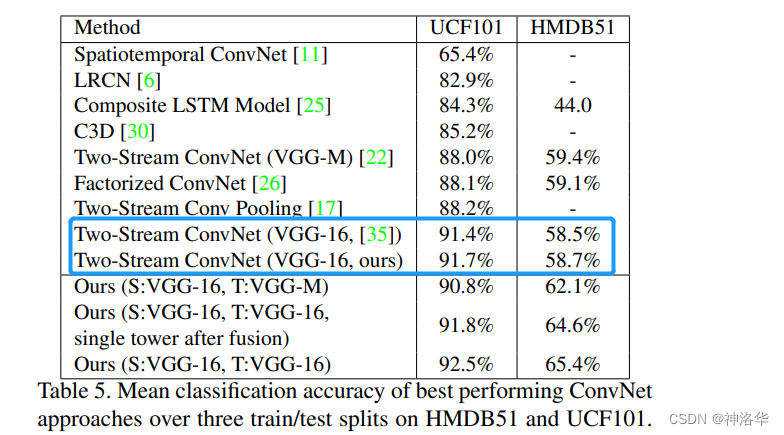
- 标蓝色的两个是作者用VGG复现了双流网络,因为使用了更深的backbone,在
UCF101上的效果更好,但是在HMDB51上的精度还略有下降。这是因为当训练集特别小(HMDB51只有约7000个视频)时,用一个很深的网络,就特别容易过拟合。 - 使用本文作者提出的fusion方法之后,
UCF101精度略有提升,HMDB51精度大幅提升。early fusion可能算是一种变相的对网络的约束,使网络在早期的学习中,就可以融合时空信息,一定程度上弥补了数据不足的问题,所以使early fusion效果比late fusion效果要好很多。
3.3.5 结论
本文做了大量消融实验,从三个方面彻底研究了一下网络结构,给后续工作提供了很大的启示。另外作者尝试了3D Conv和3D Pooling,增加了后续研究者对3D CNN的信心,变相推动了3D CNN 的发展,所以不到一年,I3D就出来了,从此开始了3D CNN 霸占视频理解领域的局面。
3.4 TSN(长视频理解,ECCV 2016)
3.4.1 网络结构
之前的双流网络,输入是单帧或几帧视频帧和10帧光流图像(大概只有半秒),只能处理很短的视频段,那该如何去处理一个更长的视频呢?
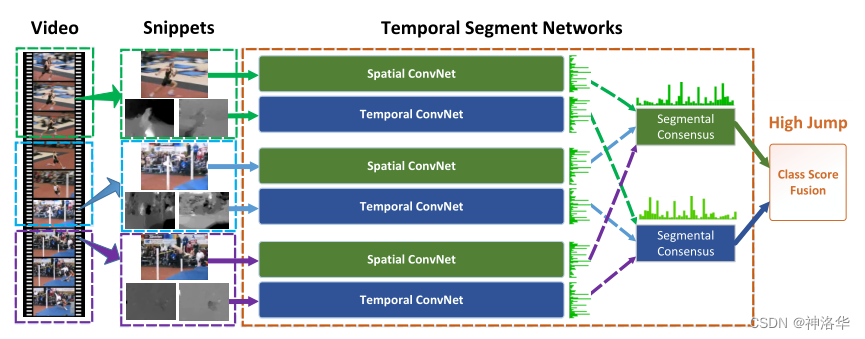
如上图所示,TSN的想法非常简单,就是把长视频分成K段来进行处理:
- 将长视频分成K段,在每一段里随机抽取一帧当做RGB图像输入,后续连续的10帧计算光流图像作为光流输入。
- 分别通过K个双流网络得到2K组logits(一组有时空两个logits,这些双流网络共享参数)。
- 将K个空间流网络输出特征做一次融合(
Segmental Consensus,达成共识),时间流输出特征也如此操作。融合方式有很多种,取平均、 - 最后将两个融合特征做一次late fusion(加权平均)得到最终结果。
3.4.2 训练技巧及效果
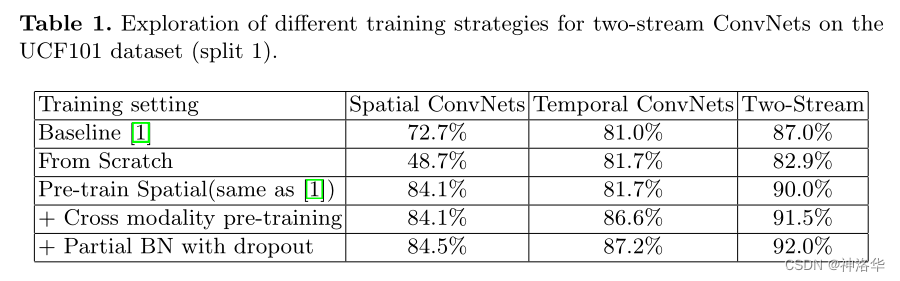
在论文3.2 节中的Network Training部分,作者尝试了很多的训练技巧。
Cross Modality Pre-training:作者提出了使用ImageNet预训练模型做光流网络预训练初始化的技巧- 在这之前并没有好的光流预训练模型,只是从头训练,光流效果并不够好,因为很多视频数据集都很小
- ImageNet预训练模型的网络输入channel=3,而光流网络输入channel=20,无法直接使用。作者先将ImageNet预训练模型第一层网络输入的RGB三个channel的权重做一个平均,得到一个channel的权重( average the weights across the RGB channels ),然后将其复制20次就行。
- 这种初始化技巧使得光流网络也能使用预训练模型,最终模型精度提高了5个点。这种技巧后来被广泛使用,I3D中使用预训练的2D模型来初始化3D模型,也是这么做的。
Regularization Techniques:- BN层用得好,模型会工作的很好,而一旦用的不好,模型也会出各种问题。在视频领域初期,很多视频数据集都很小,使用BN虽然可以加速训练,但也带来了严重的过拟合问题(数据集小,一微调就容易过拟合)。作者由此提出了
partial BN。 partial BN:简单说就是只微调第一层的BN,其它的BN 层全部冻住( freeze the mean and variance parameters of all Batch Normalization layers except the first one)。
这是因为一方面存在过拟合,所以考虑冻结BN层;但是全部冻住,迁移学习的效果就不好了。Imagenet数据集和视频分类数据集还是差的很远的,之前BN层估计出来的统计量不一定适用于视频分类,所以第一层BN必须进行学习,但后面再动就有过拟合的风险了。partial BN这种技巧在后续很多迁移学习中也经常用到。
- BN层用得好,模型会工作的很好,而一旦用的不好,模型也会出各种问题。在视频领域初期,很多视频数据集都很小,使用BN虽然可以加速训练,但也带来了严重的过拟合问题(数据集小,一微调就容易过拟合)。作者由此提出了
Data Augmentation:在传统的 two-stream 中,采用随机裁剪和水平翻转方法增加训练样本。作者采用两个新方法:角裁剪(corner cropping)和尺度抖动(scale-jittering)。- corner cropping:作者发现random crop经常是crop图片中间部分,很难crop到边角。作者强制使用角裁剪,仅从图片的边角或中心进行crop。
- scale jittering:通过改变输入图像的长宽比,增加输入图片的多样性。具体来说,先将视频帧都resize到
[256,340],然后进行各种裁剪,裁剪的图片长和宽都是从列表 [256,224,192,168]里随机选取(比如168×256,224×224等等)。这样丰富了图片尺寸,减少过拟合。
下面是在UCF101数据集上,这些训练技巧的提点效果。可以看出,从零开始训练网络比双流网络的baseline方法要差很多,证明需要重新设计训练策略来降低过拟合的风险,特别是针对空间网络。对时空网络都进行预训练,再加上partial BN,效果最好。
这些技巧都非常有用,所以作者将Good Practices作为论文题目之一。
3.4.3 实验部分
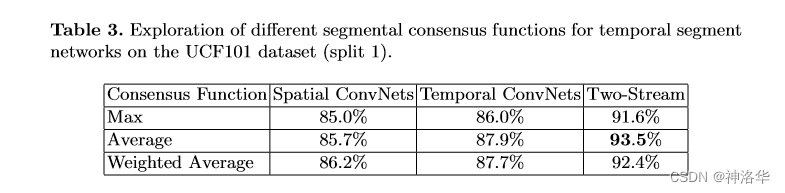
- 比较了BN-Inception、GoogLeNet和VGGNet-16作为backbone,最终BN-Inception效果最好;
- 对比了三种
Segmental Consensus方式,取平均效果最好
- 模型性能对比
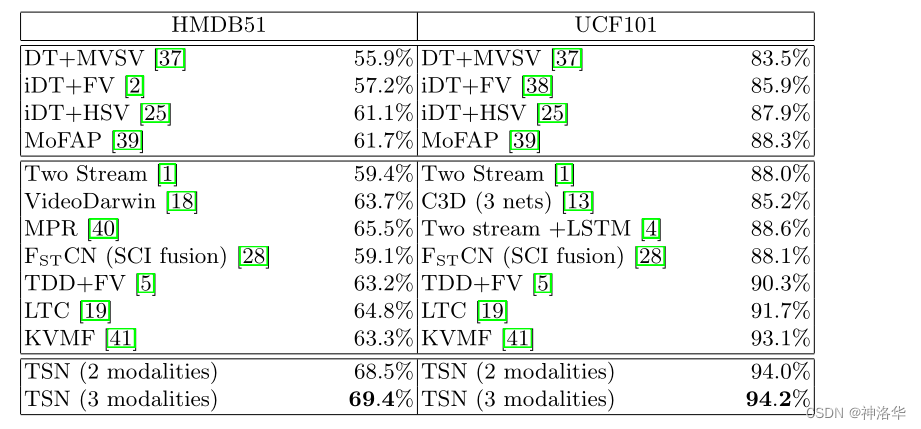
- 第一块是传统手工特征
- 第二块是使用深度学习做视频理解
C3D是早期使用3D CNN做视频理解,即使使用三个网络,结果也比不上最好的手工特征。在下一章 3D CNN部分会简单介绍这个模型- Two stream +LSTM:就是3.2 节中的方法(Beyond Short Snippets),提升0.6%。
- TDD+FV:就是王利明老师改进光流堆叠方式的论文(直接叠加光流改为按轨迹叠加光流,在此文1.3.2中有讲过)
- TSN (3 modalities) 就是还使用了另外一种光流形式作为输入,本文就不做介绍了。
3.4.4 总结
本文不仅提出了一种特别简单效果又很好的方式处理长视频,而且还确定了很多很有效的技巧( Good Practices),其贡献不亚于双流网络或者I3D。
-
处理更长的原始视频
这种将视频分K段再做Segmental Consensus的方法,除了裁剪好的Vedio clip(视频段)外,还可以应用于完全没有裁剪过的长视频。如果长时间包括更多的事件,分成的K段包含不同的事件和动作,那么后续融合时不使用平均或者max这些方式融合,改为LSTM就行了。2017年的UntrimmedNet就是处理完全没有裁剪过的长视频进行视频分类的,工作的也很好。 -
Segmental Consensus用于对比学习
本文用长视频分段后Segmental Consensus来做有监督训练,UntrimmedNet做的是弱监督训练(Weakly Supervised),但Segmental Consensus也可以用来做对比学习。
简单来说,之前的工作都是把视频里任意两帧当做正样本,其它视频帧都当做负样本。这样如果视频比较长,任意抽取的两帧不一定互为正样本。如果借鉴Segmental Consensus的思想,将长视频分为K段后,从K段视频段(K个Segment)中各抽取任意抽取一帧,这K帧当做第一个样本;再在这K个视频段中任意抽取剩下的一帧,当做第二个样本;这两个样本互为正样本就更为合理了。因为两个样本都是从K个视频段中抽出的,它们在视频段中的顺序和走势都是一样的(两个样本都是从Segment1→Segment2…→SegmentK),互为正样本的可能性更大。 -
后续进展:
- DOVF:在TSN基础上融入了全局编码(Fisher Vectors encoding),从而获取了更加全局的特征,UCF101精度推到95%以上。
- TLE (CVPR 2017 ):融入了temporal linear encoding (TLE)全局编码,并且把模型做到端到端。
- Action VLAD:融入了VLAD encoding全局编码
- DVOF:在TSN基础上融入了全局编码(Fisher Vectors encoding或VLAD encoding),从而获取了更加全局的特征,
UCF101精度推到95%以上。
也就是在2017年,I3D发表了,至此,双流网络慢慢淡出了舞台。另外I3D刷爆了UCF101数据集,且发布了Kinetics数据集,HMDB51 和UCF101也基本淡出舞台了。
3.5 总结

四、3D CNN
4.1 前言
上一章讲了双流网络及其改进,双流网络这种一个网络学习场景信息,一个网络引入光流学习运动信息的方式非常合理,效果也很好,那为什么大家还一直想将其替换为3D 卷积神经网络呢?主要就是在光流抽取这一块。
- 光流抽取非常耗时
- 计算光流的常用算法tvl one来自《 High accuracy optical flow estimation based on a theory for warping》这篇论文,使用的是其GPU实现,计算一帧光流需要约0.06秒,所以抽取光流是非常耗时的。
- 比如对于
UCF-101数据集,有约1万视频,每个视频约10秒,每秒30fps(30帧),一共约300万帧。每两帧抽一张光流图,总共耗时约50h。如果是Sports-1M这种更大的数据集(100万视频,视频时长长达几分钟),不做任何优化的话,抽取光流就要成千上万个小时了,这样即使是8卡GPU也要抽取一个多月。 - 这意味着每当你想尝试一个新的数据集,都需要先抽取光流,再去做模型的开发。
- 光流即使存为JPEG图像,也还是非常占空间。
在双流网络这篇论文中,作者巧妙的将光流的密集表示改为JPEG图像存储,大大减少了存储空间,并在后续工作中一直沿用。但即使如此,UCF-101数据集存储所有抽取的光流也要27GB,如果是Kinetics 400数据集,大概需要500G存储空间。这么大的数据量,训练时是非常卡IO读取速度的。 - 推理时无法做到实时处理
- 推理时也需要先抽取光流。tvl one算法是一帧0.06秒,换算下来就是约15fps,低于实时要求的25fps,而且这还只是抽光流,其它还什么都没做。如果加上模型,就更不是实时了。
- 视频处理的很多工作,都有实时性要求。
综合以上几点因素,所以才有那么多人想要避开光流,避开双流网络的架构。如果能直接从视频里学习视频特征该多好,这也是2017年到现在,3D CNN火热的原因。因为3D CNN是直接学习视频里的时空信息,就不需要再额外用一个时间流网络去对时序信息单独建模了,也就不需要使用光流。
但其实现在回过头来看,3D CNN 越做越大,vedio transformer也越做越大,大部分的视频模型依旧不是实时的。而如果在3D CNN或vedio transformer里加入光流,其实还是可以继续提高性能,所以光流依旧是一个很好的特征。
4.2 C3D(ICCV 2015)
4.2.1 前言
论文题目意为使用3D CNN学习时空特征,而摘要的第一句话,就说到:本文的目的,就是使用一种简单的3D CNN结构来学习视频中的时空特征。主要贡献,就是使用的3D CNN还比较深,而且是在一个特别大的数据集上进行训练的(Sports-1M数据集)。
4.2.2 模型结构和效果
1. 模型结构
如下图所示,简单来说就是有8个conv层和5个pooling层,两个FC层和最后的softmax分类层。整个3D CNN的构造,就是把所有的2d 卷积核(3×3)都变成3d的卷积核(3×3×3),2d pooling层(2×2)换成3d pooling层(除第一个是1×2×2之外,其它pooling层都是2×2×2)。
整体构造,就是将VGG-16的每个block都减去一个conv层,然后2d卷积、池化核变为3d 卷积核池化,所以C3D相当于是一个3D版的VGG(共11层)。所以作者才说,这种改动的方法非常简单。没有inception net那种多路径的结构,也没有残差连接(当时还没有ResNet)。
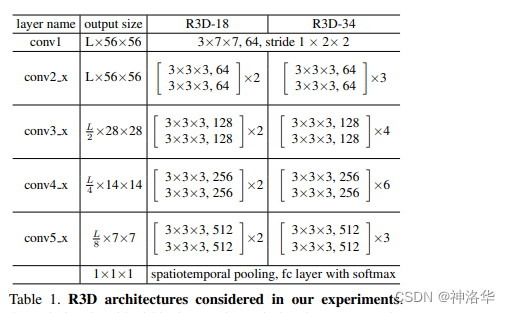
模型输入维度是[16,112,112](也就是输入16个视频帧,每帧尺寸是112×112),其余各个block尺寸如下:

2. 模型结果
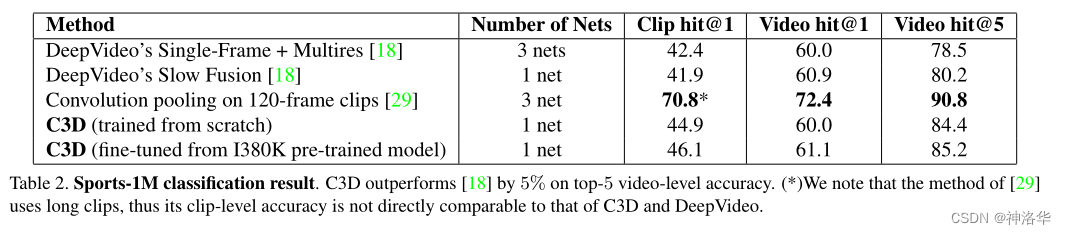
如上图所示,前两行都是Deep Video在Sports-1M数据集上的训练结果。如果改为C3D,则效果略有提升。如果C3D换成是在更大的数据集I380K(Facebook内部数据集,未开源)上预训练,效果进一步提升。所以这也是作者反复强调的,3D CNN比2D CNN做更适合做视频理解(Deep Video还是使用一个2D CNN,只不过后面做了一些Fusion )。
下面是在 UCF101数据集上的精度对比。
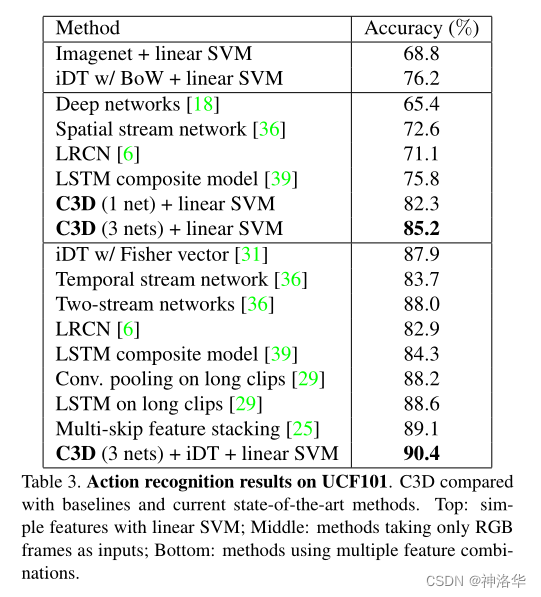
- 只使用一个C3D网络,精度只有82.3%,如果集成三个网络,精度为85.2%,也低于同期双流网络和手工特征的结果。
- 结果最好的是C3D+iDT+SVM分类器,精度90.4%。
4.2.3 总结
C3D的结果并不是最好,但依旧很吸引人,因为其卖点是在特征抽取上。
作者当时给出了python和matlab的接口。不管是使用python还是matlab,如果用opencv读进来,就可以返回一个1×4096的特征,直接用这个特征去做下游任务就行,中间细节通透不用管。所以当时很多视频理解任务,比如vedio detection、vedio captioning都纷纷使用C3D特征去做。
除了抽取特征这种方式,让大量的研究者可以用于下游任务,作者还系统的研究了如何将3D CNN用于视频理解任务上来,为后续的一系列3D CNN 工作做了铺垫。
4.3 I3D(CVPR 2017)
4.3.1 研究动机
C3D在Sports-1M这么大的数据集熵进行预训练之后,效果还是不太行。作者坚信,如果使用一个类似ImageNet这样的预训练模型,让网络进行更好的初始化,降低训练难度,模型性能一定会提高很多。
所以作者提出了Inflated 3D ConvNet,这也是I3D里面的I的来源。具体来说,就是将一个2D的网络扩张成一个3D网络(2D卷积池化改为3D的卷积池化,类似C3D),而保持整体网络架构不变。同时这样可以后续采样用Bootstrapping技术,将2D网络的预训练参数,可以用于扩张后的3D 网络的初始化。
4.3.2 简介
本文从两个方面降低了训练3D网络的难度。
Inflated 3D ConvNet:如果没有好的训练数据,可以使用ImageNet上预训练的2D模型,按I3D的方式扩张到3D网络。这样不用设计3D网络结构,而且使用了预训练模型的参数进行初始化,效果一般都很好(Inflating+Bootstrapping);Kinetics 400:如果你想从头设计一个3D网络,那么可以使用本文提出的Kinetics 400数据集进行预训练,是一个不错的选择(不再依赖于ImageNet预训练的模型参数)
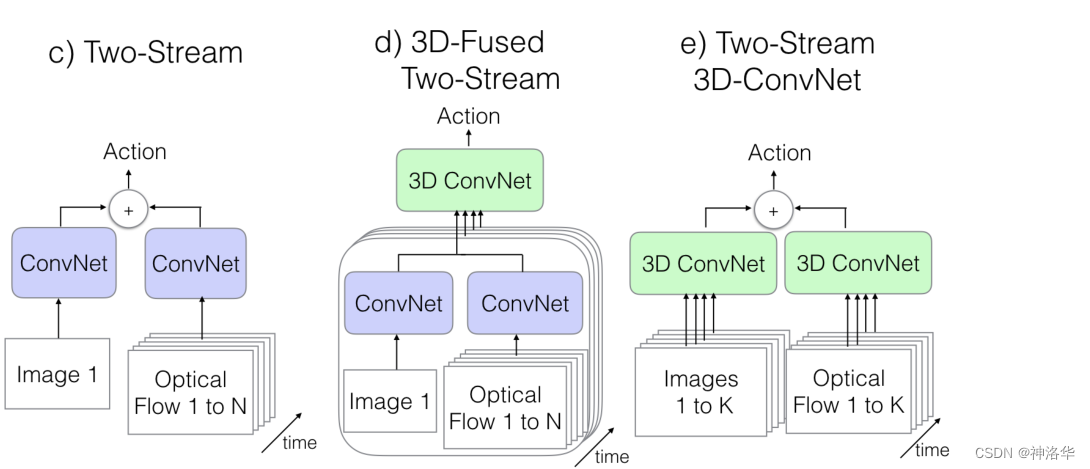
具体的I3D网络结构,就是Two-Stream+3D ConvNet(backbone为Inception-V1):
4.3.3 总结
I3D最大的亮点就是Inflating操作,不仅不用再从头设计一个3D网络,直接使用成熟的2D网络进行扩充就行,而且看还可以使用2D网络的预训练参数,简化了训练过程,使用更少的训练时间达到了更好的训练效果。
I3D的最终结果,也超过了之前的2D CNN或者双流网络(UCF101精度刷到98%,远高于C3D的85.2%和Two-Stream的88%)。所以自从I3D 在2017年提出之后,到2020年,3D CNN基本霸占了整个视频理解领域,双流网络瞬间就不香了,直到vision transformer的出现。
I3D的影响:
I3D虽然使用了3D CNN,但依旧使用了光流。也就是说光流不是没有,只是计算代价太高。I3D以一己之力,将视频理解领域 从双流网络推动到3D CNN时代,将做视频测试的数据集,从UCF-101和HMDB-51变成了Kinetics 400(前两个已经被刷爆了)- 证明了从2D 网络迁移到3D网络的有效性,后续有很多工作跟进(比如backbone换成ResNet,融入ResNext或者SENet的思想等等。)
4.4 Non-local Neural Networks(CVPR 2018)
4.4.1 前言
1. 研究动机
I3D奠定了3D CNN的视频处理架构之后,后续的就是各种改进了。其中一点,就是如何处理更长的视频,也就是该如何进行更好的时序建模。
恰好这一时期,NLP领域发生了一个巨大的变革,transformer、GPT和BERT相继被提出来了,并被广泛证明其有效性。而其中的attention操作,本来就是可以学习远距离信息的,与LSTM的作用不谋而合。所以本文的作者,就考虑将self-attention融入I3D当中。
结果也证明这样做确实有效,后续视频检查分割等等任务,都融入了non-local算子。尤其是2019年,简直都卷疯了,不知道有多少论文,尝试用各种方式将attention操作加到不同的视频分割网络结构里来。
2. 摘要
卷积(convolutional)和递归(recurrent)都是对局部区域进行的操作,所以它们是典型的local operations。那如果能看到更长距离的上下文,肯定是对各种任务都有帮助的。
受计算机视觉中经典的非局部均值(non-local means)的启发,本文提出一种non-local 算子用于捕获长距离依赖,可用于建模图像上两个有一定距离的像素之间的联系,建模视频里两帧的联系,建模一段话中不同词的联系等。
non-local operations在计算某个位置的响应时,是考虑所有位置features的加权——所有位置可以是空间的,时间的,时空的。所以non-local 算子是一个即插即用的 building blocks(模块),所以可以用于各种任务,泛化性好。在视频分类、物体检测、物体分割、姿态估计等任务也都取得了不错的效果。
4.4.2 Non-local Block结构
下图是一个时空Non-local Block,也就是专门用于视频理解的Non-local 模块。输入X经过变换得到
θ
,
ϕ
,
g
\theta ,\phi ,g
θ,ϕ,g,也就相当于self-attention里的q、k、v。然后前两者做点积注意力操作得到注意力分数,再和g做加权求和,得到最终的自注意力结果。这个结果和模块的输入做一个残差连接,得到整个模块的最终输出Z:
Z
=
W
Z
⋅
A
t
t
e
n
t
i
o
n
(
θ
,
ϕ
,
g
)
+
X
=
W
Z
⋅
s
o
f
t
m
a
x
(
θ
ϕ
T
d
ϕ
)
g
+
X
Z= W_{Z}\cdot\mathrm{Attention}(\theta ,\phi,g)+X =W_{Z}\cdot \mathrm{softmax}(\frac{\theta \phi ^T}{\sqrt{d_\phi}})g +X
Z=WZ⋅Attention(θ,ϕ,g)+X=WZ⋅softmax(dϕθϕT)g+X
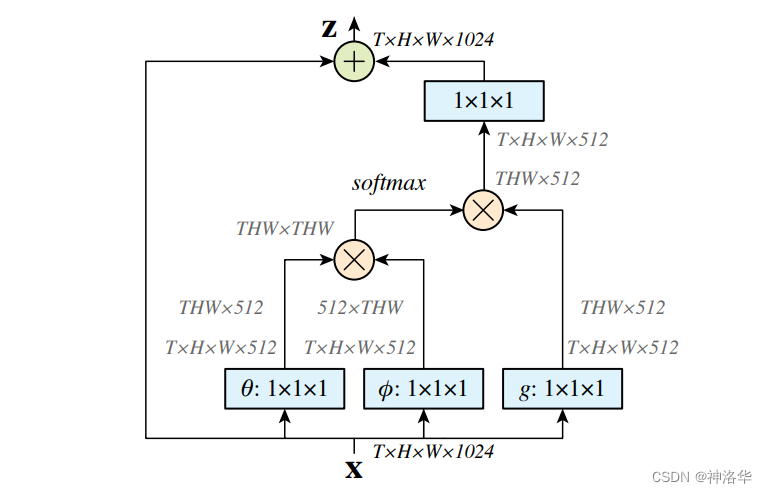
- 上图T应该是输入的视频帧的数量,H和W是视频帧的高宽尺寸。
- 计算过程中, θ , ϕ , g \theta ,\phi ,g θ,ϕ,g的维度是输入X的一半,减少计算量。最后乘以 W Z W_Z WZ时,恢复原来的通道数(也就是图中1×1×1的卷积操作),这样就可以做残差连接了( ⨂ , ⨁ \bigotimes,\bigoplus ⨂,⨁分别表示矩阵乘法和矩阵加法)
- 这种残差结构,可以让我们在任意的模型中插入一个新的non-local block,而不改变其原有的结构。
4.4.3 实验
4.4.3.1 baseline
ResNet-50 C2D baseline:2D 卷积核,3D pooling,结构如下图:
作者先构造了一个没有使用non local的ResNet-50 C2D baseline。输入的video clip是32帧,大小为224*224。所有卷积都是2D的,即逐帧对输入视频进行计算。唯一和时序有关的计算就是pooling,即简单的在时间维度上做了一个聚合操作。

I3D:上面的C2D可以通过I3D论文中Inflating的方式扩张成3D CNN,即卷积核也变成3D的。但采用两种扩张方式:一种是将residual block中的卷积核由3*3扩张为3*3*3,另一种是将residual block中卷积核由1*1扩张为3*1*1。扩张后的模型分别表示为 I 3 D 3 ∗ 3 ∗ 3 I3D_{3\ast 3\ast 3} I3D3∗3∗3和 I 3 D 3 ∗ 1 ∗ 1 I3D_{3\ast 1\ast 1} I3D3∗1∗1 。
4.4.3.2 消融实验
下面的试验,都是在Kinetics数据集上,进行视频分类的结果:
- a:试验自注意力计算的方式:点积计算效果最好,这也是transformer默认的计算方式
- b:试验单个non-local block插入位置:在
r
e
s
2
res_2
res2和
r
e
s
3
res_3
res3上插入
non-local block。- 在ResNet的第2、3、4这三个block上插入non-local的效果都不错。加在 r e s 5 res_5 res5上效果不好,作者认为这是因为第五个block的特征图太小了,没有多少远距离的信息可以学习
- 加在 r e s 2 res_2 res2上计算代价比较高,因为这个模块的特征图尺寸还是很大的
- c:试验插入
non local block的数量。- ResNet50的4个Conv Block的卷积层层数分别是3、4、6、3,所以下表中加入10个non-local就等于是,在ResNet50的第二、三这两个模块的每个卷积层上,都加入
non local block。5-block就是每隔一层来一个 - 下图可以看到,加入更多的block效果就更好,这也说明,自注意力操作真的有用,特别是在视频理解里面,长距离时序建模更为有用。
- ResNet50的4个Conv Block的卷积层层数分别是3、4、6、3,所以下表中加入10个non-local就等于是,在ResNet50的第二、三这两个模块的每个卷积层上,都加入
- d:试验时空自注意力的有效性
- 表d分别试验了只在时间维度和只在空间维度计算self -attention,以及在时空维度计算self attention的结果,最终显示,时间维度做self attention效果优于空间维度,两个维度都做,效果最好。这也证明作者提出的
spacetime self attention才是最有效的。
- 表d分别试验了只在时间维度和只在空间维度计算self -attention,以及在时空维度计算self attention的结果,最终显示,时间维度做self attention效果优于空间维度,两个维度都做,效果最好。这也证明作者提出的
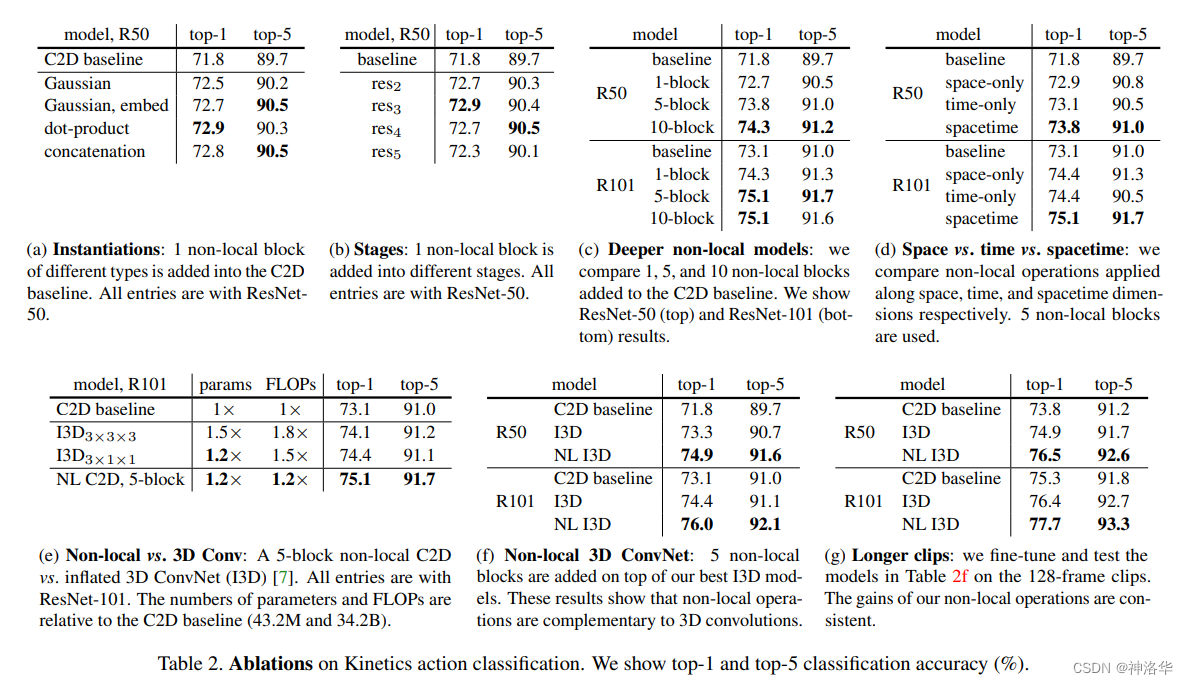
- e:对比
C2D+5 non local blocks和两种I3D模型的效果,前者精度更高,FLOPs更小,说明单独使用non-local比3D conv更高效 - f:
I3D+ 5 non-local blocks,效果进一步提升。 - g:使用更长的视频段(32帧→128帧,大概4秒),加入
non-local block依然可以提高模型的精度,也说明其对长距离时序建模的有效性。
4.4.3.3 对比其它模型
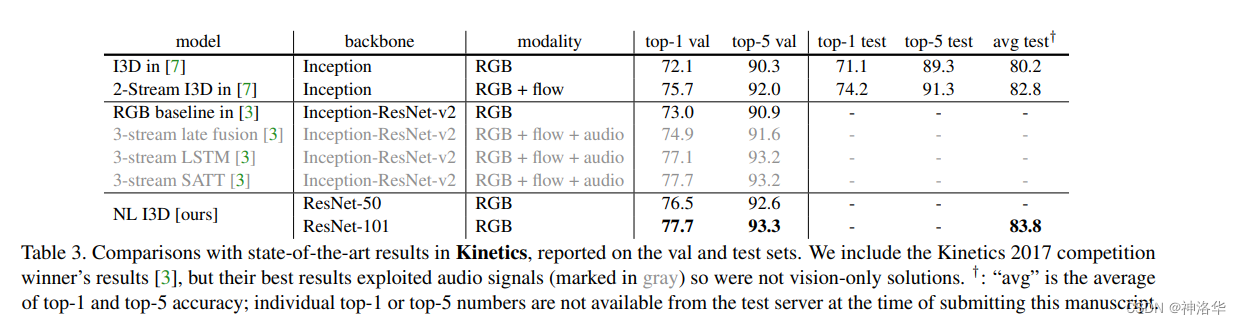
下面是本文的方法和I3D等几种模型在 Kinetics 400上的效果对比。NL I3D是将I3D的backb替换为ResNet,精度提升了一个点左右,加入non local之后,又提升了三个点,所以总共提升了约4个点,而且比双流I3D的效果还要好,更是给了做3D CNN研究者以信心。
4.4.4 总结
作者将self attention引入到了视觉领域,而且针对视频理解,提出了spacetime self attention,通过一系列实验,证明了其有效性。从此在CV 领域,大家基本都使用non local算子,而不使用LSTM了。
4.5 R(2+1)D(CVPR 2018 )
4.5.1 前言
- 主要内容:本文详细讨论了,在动作识别任务上做时空卷积的几种网络结构,是一篇实验性质的论文。
- 研究动机:作者发现,只使用2D CNN网络对一帧帧的单个视频帧抽取特征,最后动作识别的效果和3D网络差不多。而2D CNN是比3D CNN便宜很多的,所以作者考虑,在3D CNN网络结构中,部分加入2DCNN网络,并试验了各种网络结构。
- 结论:通过
Sports-1M、Kinetics等多个数据集上的测试,证明了将3D 卷积拆分成空间上的2D+时间上的1D的网络结构,效果最好,也易于训练。
4.5.2 网络结构
1. 几种网络结构对比:
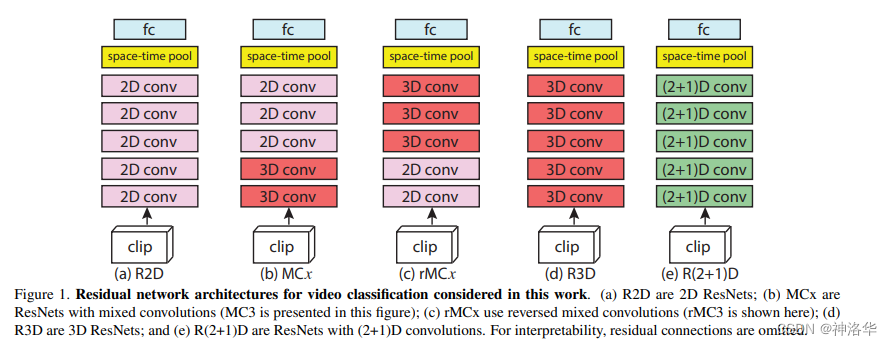
R2D:将时间维度合并到channel维度中。比如将输入维度[C,T,H,W ]→[CT,H,W],然后直接输入到2D卷积网络中,得到最后的分类结果。MCx:前x层为3D卷积网络,而其余顶层为2D卷积网络,也就是先在底层抽取时空特征,然后上层用2D CNN降低复杂度rMCx:将一帧帧视频帧先输入x层2D Conv抽取特征,再用3D Conv去做一些融合,输出最后的结果R3D:ResNet版本的I3D,即backbone换成3D ResNet,整体结构如下:
R(2+1)D:本文的网络结构,先做2D的Spatial Conv,再做1D的Temporal Conv,效果最好。
2. 对比结果
下面对比了几种网络结构在Kinetics验证集上的动作识别精度,并且都是使用ResNet-18从头训练的模型:
- 单纯使用2D卷积神经网络效果最差,只使用3D效果稍微高一点
- 不管是
MCx还是rMCx,加入部分2D网络,效果都有提高 - 本文提出的
R(2+1)D网络结构的效果最好
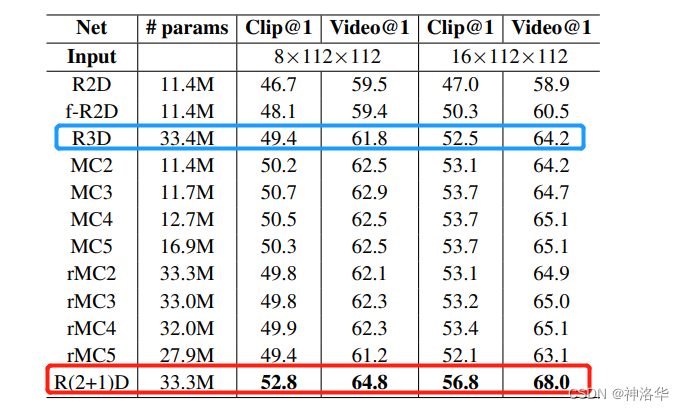
对比了输入分别为8帧和16帧的两种情况
4.5.3 R(2+1)D结构
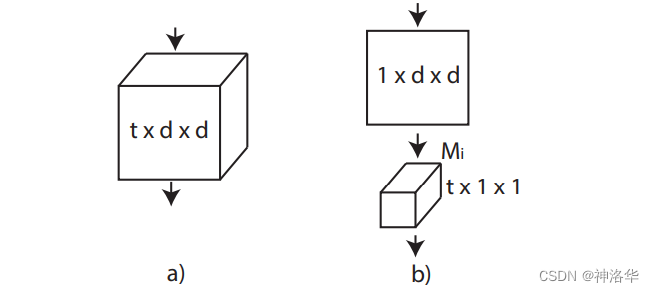
如上图所示, R(2+1)D 就是将一个 t×d×d的卷积核,替换为一个 1×d×d的卷积核和一个t×1×1的卷积核。也就是先只在空间维度(宽高尺度)上做卷积,时间维度卷积尺寸保持为1不变;然后再保持空间维度不变,只做时间维度的卷积。
-
为了使分解后的 R(2+1)D 网络参数量 和原3D网络参数量大体相同(和3D网络公平对比),中间使用Mi个2D CNN进行一次维度变换(输出维度为Mi)
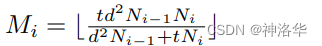
-
R(2+1)D增强了模型的非线性表达能力:相比原来,多使用了一次卷积操作,也就多用了一次RELU函数,所以模型的学习能力更强了; -
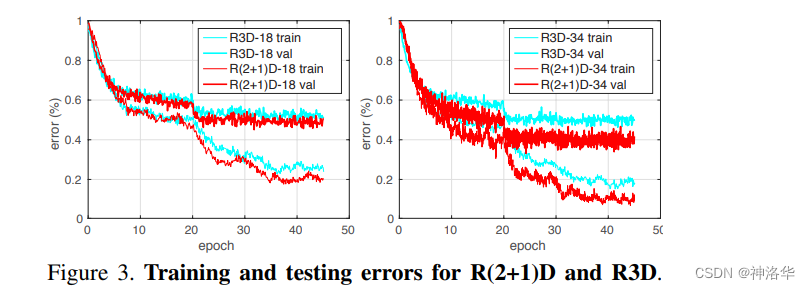
R(2+1)D结构使网络更加容易优化:直接使用3D卷积,模型是不容易学习的,拆分成两次卷积之后,降低了模型学习的难度。在参数量相同的情况下,R(2+1)D获得的训练损失和测试损失更低。网络层数越深,效果差距越明显。
下面是两种结构的训练和测试误差对比图,R(2+1)D网络误差都更小,这既不是过拟合也不是欠拟合,而确实是网络更容易训练。
4.5.4 实验和总结
下图对比其它模型在 Kinetics上的结果。R(2+1)D单个网络(RGB/Flow)比I3D单个网络的效果更好,但是双流R(2+1)D比双流I3D效果略低,也就是Fusion操作对I3D提升更大。在UCF101和HMDB51两个数据集上,也观察到同样的现象。
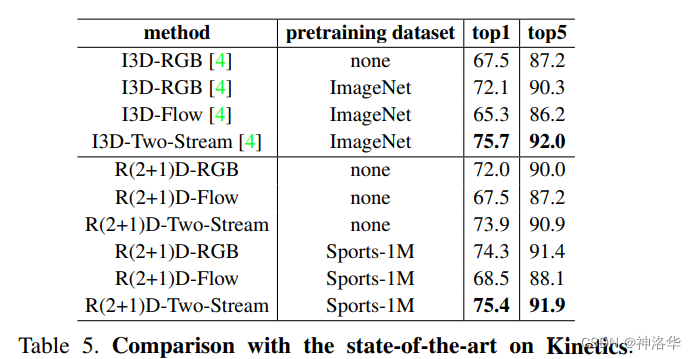
这也是可以理解的,因为R(2+1)D输入尺寸是112×112,I3D输入尺寸是224×224,所以稍微低一点没关系。R(2+1)D这种拆分方式,确实有助于降低过拟合,降低训练难度。而且可以从头训练,不需要像I3D一样借助2D模型的ImageNet预训练参数,所以是一个很值得借鉴的网络结构。
在前两年视频领域对比学习很火的时候,很多工作的backbone都是R(2+1)D,就是因为其容易训练和优化,而且输入尺寸是112×112,对GPU内存比较友好。
后面会讲到TimeSformer这篇论文,其中一些作者就是本文作者,想法也类似,即将一个时空自注意力,拆分成时间上和空间上分别作自注意力。这样拆分,大大减少了对显存的要求,从而能训练起一个vedio transformer。

4.6 SlowFast(ICCV 2019 )
4.6.1 前言
- 研究动机:人的视觉系统有两种细胞:p细胞和m细胞。前者数量占比约80%,主要处理静态图像;后者占比约20%,主要处理运动信息。这种方式就类似双流网络,受此启发,作者设计了
SlowFast网络。 - 摘要:本文提出了一种快慢结合的网络来用于视频分类。其中一路为Slow网络,输入为低帧率,用来捕获空间语义信息。另一路为Fast网络,输入为高帧率,用来捕获运动信息,且Fast网络是一个轻量级的网络,其channel数比较小。
SlowFast网络在Kinetics数据集上视频分类的精度为79.0%,在AVA动作检测达到了28.3mAP,都是当前的SOTA效果。
4.6.2 模型结构
1. 整体结构
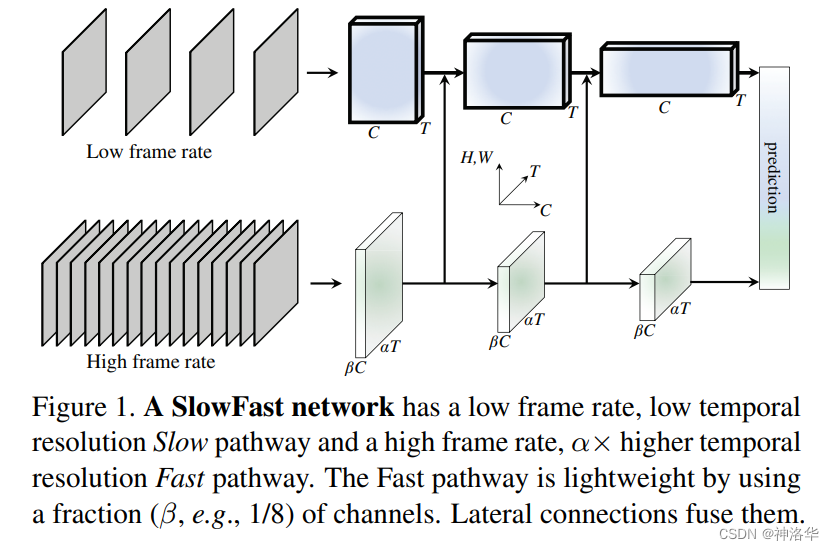
如上图所示,SlowFast网络有两条分支。
-
Slow pathway:类似p细胞,主要学习静态图像
- 慢分支每隔
τ帧取一帧,假设输入是T帧时,原视频是τ×T帧的vedio clip。 - 默认
T=4,τ=16(以帧率30fps来说,刷新速度大约是每秒采样2帧)。 - 慢分支的网络就类似一个I3D,网络是比较大的。但因为输入只有4帧,所以相对而言,计算复杂度也不高。
- 慢分支每隔
-
Fast pathway:快分支用于处理动态信息,所以需要更多的输入帧。
- 高帧率:每隔
τ/α帧取一帧,所以输入是αT帧,默认α=8,快分支输入就是32帧。 α是两个分支的帧速比,是SlowFast的关键概念,它表示这两条pathways的时间速度不同,促使两个分支分别学习不同的特征。- 低通道容量:相比于Slow分支, Fast分支的channel数是其
β倍(默认β=1/8),所以是一个轻量级的分支。一般计算复杂度(FLOPs)是channel的平方关系,最后Fast分支约占整个网络计算量的20%。(上面也提到了,m细胞约占总数的15%-20%) - 高时间分辨率:整个Fast分支中均不使用时间下采样层(既不使用时间池化,也不使用时间步长的卷积操作),这样一来,特征张量在时间维度上总是
αT帧,尽可能地保持时间保真度。
- 高帧率:每隔
-
. Lateral connections(侧连接):将快分支的特征融合到慢分支上
- 两条分支的每个 stage 上都使用一个侧连接,将快分支的特征融合到慢分支上。作者也尝试了双向融合,提升不大。
- 对于 ResNets而言,这些连接就位于 p o o l 1 , r e s 2 , r e s 3 , r e s 4 pool_1,res_2,res_3,res_4 pool1,res2,res3,res4之后。
- 这两条分支的时间维度不同,通过变换来将它们匹配在一起。
SlowFast使用小输入大网络的Slow pathway,和大输入小网络的Fast pathway,两个分支还使用侧连接进行信息融合,来学习更好的时空特征。通过这种设计,SlowFast达到了一种较好的时间和精度的平衡。
2. 前向过程
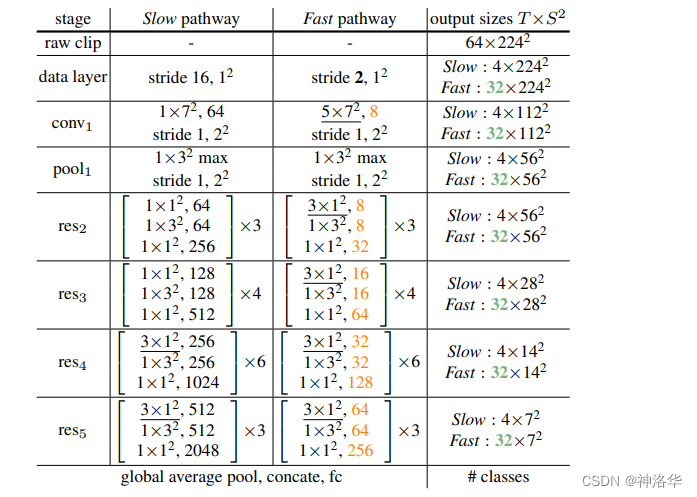
- Slow pathway:就是一个ResNet-50 I3D,所以有四个res block,卷积层个数分别是3、4、6、3。
- Fast pathway:channel数是上图黄色数字,远远少于慢分支的channel数。
- forword:
-
输入:慢分支和快分支输入维度分别是 [ T , S 2 , C ] [T,S^{2},C] [T,S2,C]和 [ α T , S 2 , β C ] [\alpha T,S^{2},\beta C] [αT,S2,βC]。假设样本是64帧224×224的视频帧,则慢分支和快分支的输入分别是4帧和32帧;
-
下采样:在时间维度上,两个分支始终没有在时间维度上进行下采样,也就是始终保持32帧和4帧,使网络可以更好地学习时序信息;空间维度和原来一样,每个block都进行2倍的下采样
-
侧连接:文中讨论了三种将快分支特征变换到慢分支同维度特征的方法,最后采用3D Time-strided卷积: k e r n e l s i z e = 5 × 1 2 , o u t p u t − c h a n n e l = 2 β C , s t r i d e = α kernel size=5\times 1^2,output -channel=2\beta C,stride=\alpha kernelsize=5×12,output−channel=2βC,stride=α。
-
两个分支各接一个全局平均池化层,然后进行特征融合(concate)。最后接一个FC层(包含softmax),得到最终结果。
-
4.6.3 实验结果
-
对比Kinetics上的视频分类结果(表2)
- 表2灰色部分表示都使用了ImageNet预训练的模型
- 下=表还对比了不同的计算复杂度,最小的SlowFast计算复杂度是很小的。
- 随着输入帧数的提高,更换更深的backbone,以及最后加入了non-local算子,模型的精度一直在提升。最优模型在
Kinetics-400上的精度达到了79.8%,基本是3D CNN中的最好结果。 - 表3使用
Kinetics-600数据集进行训练,精度更高
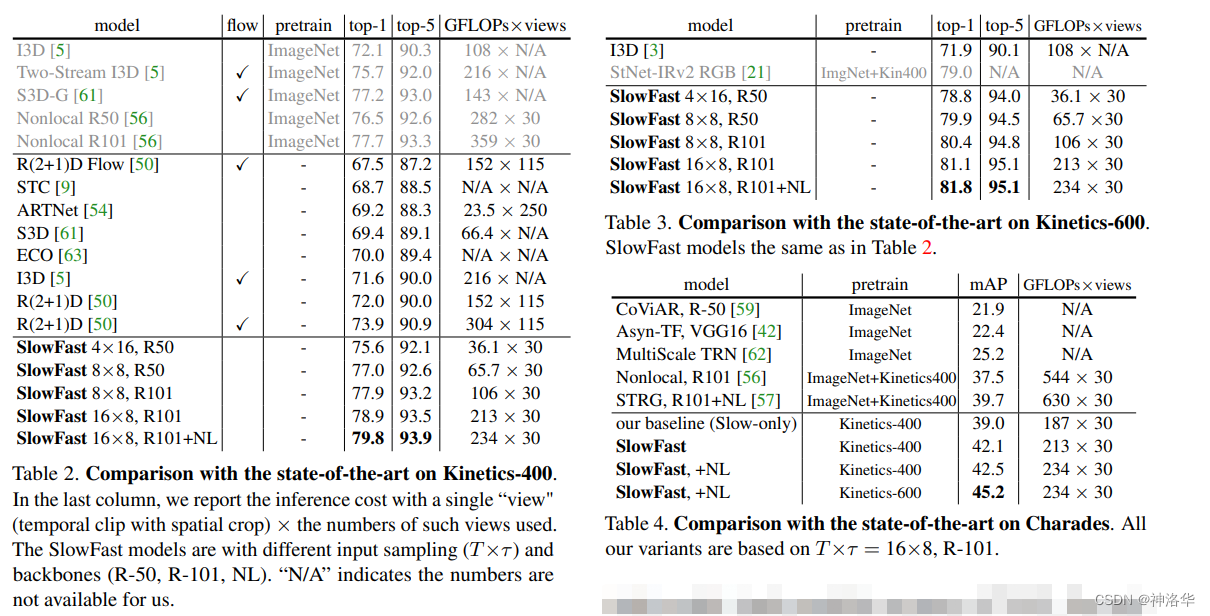
-
对比AVA上视频分割效果
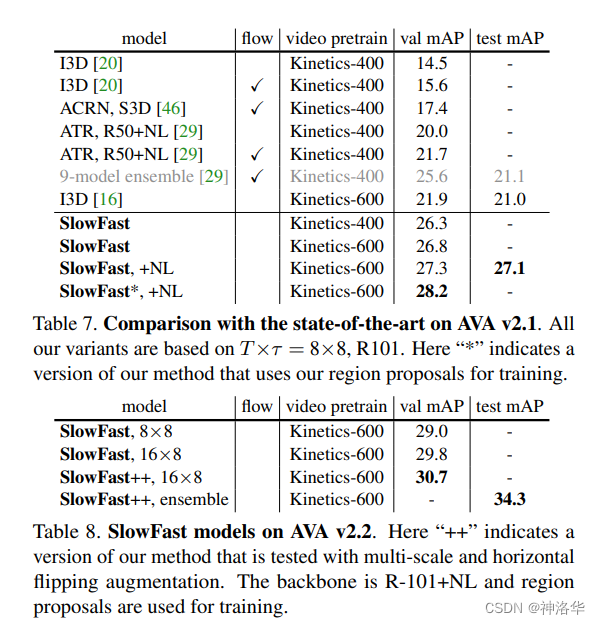
另外还做了很多消融实验,比如α,β,T改如何取值等等,就不一一列举了。
4.7 3D CNN总结
除了上面列举的这些,还有很多优秀的论文。比如:
- Hidden Two-Stream:朱老师组2017年的论文,使用一种新的CNN架构,在网络中隐式地捕获相邻帧之间的运动信息,相当于隐式的光流。这样在训练和推理时都不需要抽取光流,这种端到端的算法比two-stage baseline快10倍。
- TSM(Temporal Shift Module ,ICCV2019):提出了一种通用且有效的时间移位模块(TSM)。TSM shifts part of the channels along the temporal dimension,从而在相邻帧之间交换信息。引入shift操作之后,能让一个2D CNN 媲美3D CNN的效果,且2D CNN计算量小,更高效,更易部署。作者还提供了一个首饰检测的demo。
五、Vedio Transformer
5.1 TimeSformer(2021.2.9)
5.1.1 前言
在CV领域,卷积和 Transformer 相比,有以下的缺陷:
- 卷积有很强的归纳偏置(例如局部连接性和平移不变性)。对于一些比较小的训练集来说,这毫无疑问是有效的,但数据集够大时,这些会限制模型的表达能力。相比之下,Transformer 的归纳偏置更少,能够表达的范围更广,也更适用于非常大的数据集。
- 卷积核是专门设计用来捕捉局部的时空信息,并不能够对感受野之外的依赖进行建模。虽然将卷积进行堆叠,会扩大感受野,但是这种策略,仍然会限制长期依赖的建模。与之相反,自注意力机制通过直接比较在所有时空位置上的特征,可以被用来捕捉局部和全局的长范围内的依赖。
- 当应用于高清的长视频时,训练深度 CNN 网络非常耗费计算资源。而在静止图像的领域中,Transformer 训练和推导要比 CNN 更快。使用相同的计算资源可以训练更强的网络。
本文讨论了如何将Vision Transformer从图像领域迁移到视频领域,即如何将自注意力机制从图像的空间维度(2D)扩展到视频的时空维度(3D)。TimeSformer算是这方面工作最早的一篇。
TimeSformer 在多个有挑战的行为识别数据集上达到了 SOTA 的结果,相比于 3D CNN网络,TimeSformer训练要快3倍,推理时间仅为其十分之一。此外,TimeSformer 的可扩展性,使得它可以在更长的视频片段上训练更大的模型(当前的 3D CNN 最多只能够处理几秒钟的片段,而TimeSformer 甚至可以在数分钟的片段上进行训练。),为将来的 AI 系统理解更复杂的人类行为做下了铺垫。
5.1.2 网络结构
具体来说,文中讨论了五种融入自注意力的结构:
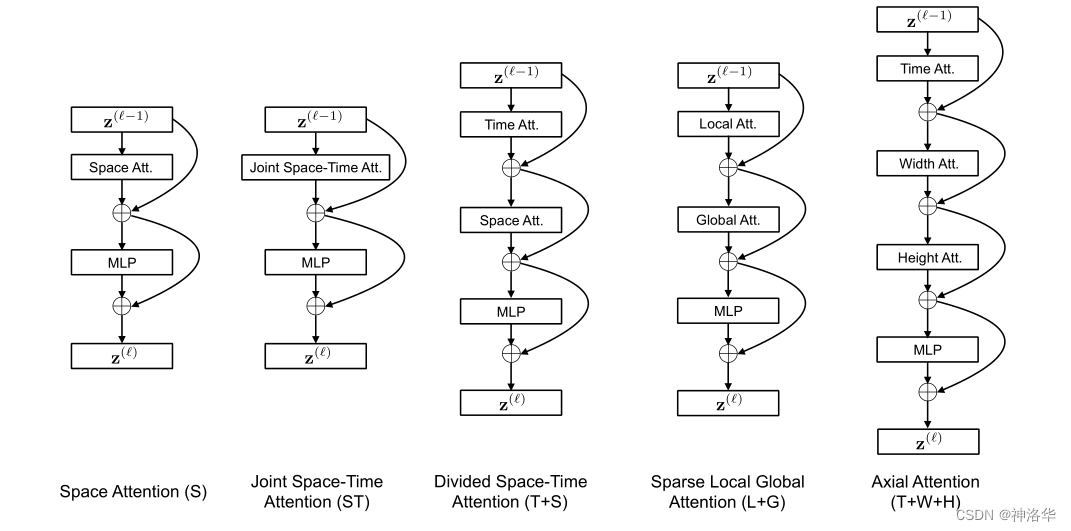
- 空间注意力机制(
S):只在单帧图像上计算空间自注意力(+残差连接),然后接一个MLP(+残差连接)得到最后的结果,就类似ViT本身的做法,相当于是一个baseline了 - (共同)时空注意力(
ST):在视频的三个维度上都使用自注意力- 暴力的计算所有视频帧中的所有图像块的自注意力,剩下的操作和上面一样。
- 这种方式基本显存都塞不下(本来
ViT就快塞不下了,视频使用更多的视频帧,更是塞不下)
- 拆分的时空自注意力(
T+S):直接计算3D的时空自注意力显存不够,借鉴R(2+1)D的方法,将其拆分为Temporal Self Attention+Spatial Self Attention。- 先计算不同帧中同一位置图像块的自注意力,再计算同一帧中的所有图像块的自注意力
- 这种方式大大降低了计算复杂度
- 局部-全局注意力机制(
L+G) :直接计算序列太长,所以考虑先计算局部的自注意力,再在全局计算自注意力,类似Swin-Transformer。
具体来说,先利用所有帧中,相邻的 H/2 和 W/2 的图像块计算局部的注意力。然后在空间上,使用2个图像块的步长,在整个序列中计算自注意力机制,这个可以看做全局的时空注意力更快的近似 - 轴向自注意力(
T+W+H):分别沿着时间维度、width维度和height维度计算自注意力。
下面作者对这五种自注意力方式进行了可视化,更加的形象:

- 空间注意力机制(
S):上图以第t帧blue patch为基准点时,Space Attention只计算这一帧内其他patches和基准点的self attention,而完全看不到其它帧的信息; - 时空注意力(
ST):基准点和所有帧的所有patches都计算自注意力; - 拆分时空注意力(
T+S):先做时间上的自注意力,也就是计算不同帧中同一位置的self attention。然后计算同一帧上所有patches的self attention; - 局部-全局注意力机制(
L+G):先计算图中蓝色快和黄色/红色块的局部自注意力,再计算全局自注意力(此时是进行稀疏的计算,所以只计算蓝色块和紫色块的自注意力)。 - 轴向自注意力(
T+W+H):先做时间轴(绿色块)的自注意力,再分别作横轴(黄色块)和纵轴(紫色块)上的自注意力。
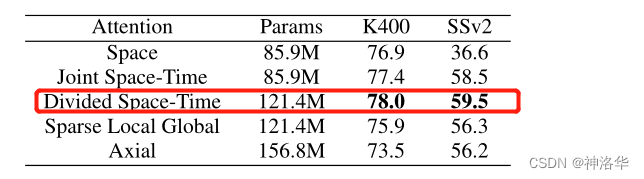
最终作者在Kinetics-400和Something-Something-V2数据集上,试验了这几种结构的精度。拆分时空注意力( divided space-time attention)效果最好;
5.1.3 实验
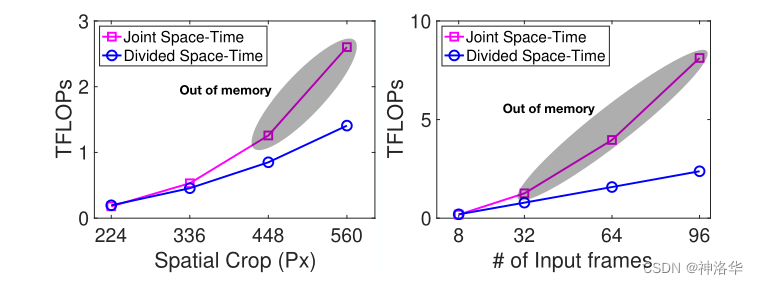
- 显存对比
下图表示随着输入图像尺度的增长和输入帧数的增长,Divided Space-Time的方式计算复杂度基本还是线性增长,而Joint Space-Time的方式,计算复杂度增长非常快。下图灰色部分表示从448×448 crop和32帧起,就爆显存了,无法训练。
- 模型效果对比

- 左图对比了
TimeSformer、I3D、SlowFast三种模型在K400数据集上的精度。其实 SlowFast使用Resnet101效果更好(精度78.9)。但是TimeSformer确实训练(微调)时间和推理速度都更短。 - 右图是作者使用了更大的
TimeSformer-L模型,并在ImageNet-21K上进行训练,终于把K400刷到80.7了。作为第一篇把ViT用到视频理解上的论文,这效果已经不错了。 - 下图是在K600数据集上,
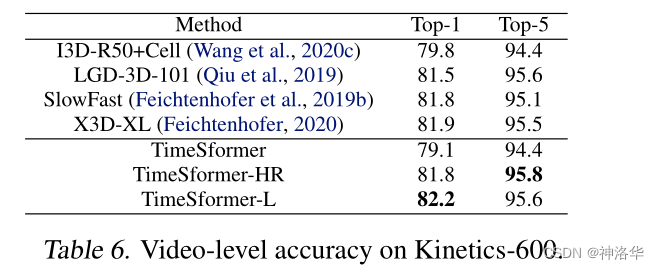
TimeSformer达到了 SOTA。
- 长视频处理
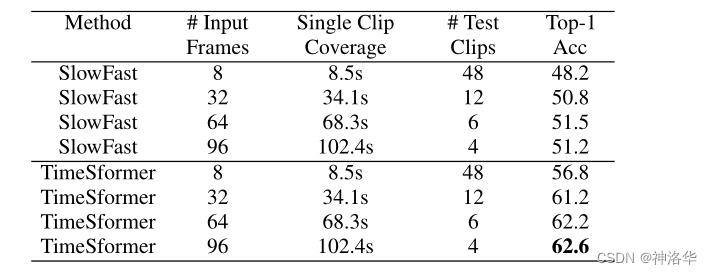
作者还验证了TimeSformer在长视频处理上相比于 CNN 更有优势,这一步使用了 HowTo100M 数据集。可以看到,当TimeSformer输入96帧时,能够有效利用视频中长期依赖的信息,达到了最好的效果。# Input Frames:代表输入模型的帧数Single Clip Coverage:代表输入的一段视频覆盖了多久的视频# Test Clips: 代表预测阶段,需要将输入视频裁剪几段才能输入进网络。
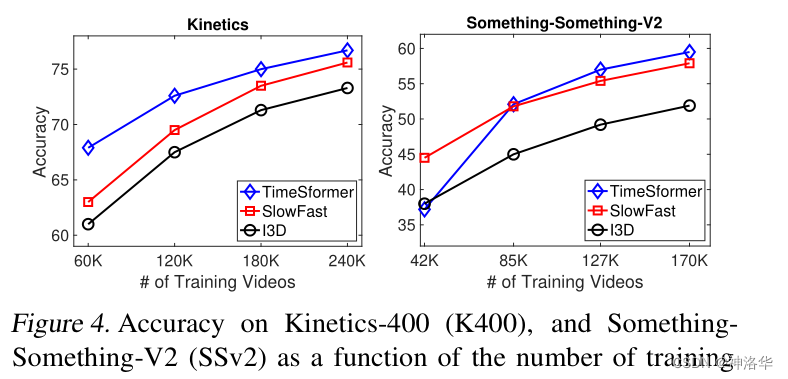
4. 预训练和数据集规模的重要性
- 因为这个模型需要非常大的数据才能够训练,作者有尝试自己从头训练,但是都失败了,因此在论文中报告的所有结果,都使用了 ImageNet 进行预训练。
- 为了研究数据集的规模的影响,使用了两个数据集,实验中,分四组,分别使用25%,50%,75%和100%的数据。结果是 TimeSformer 当数据比较少的时候表现不太好,数据多的时候表现好(这个结论和ViT中是一样的,即训练transformer需要更大的数据量才能达到媲美CNN的效果)。
5.1.4 总结
TimeSformer有以下几个优点:
- 想法简单
- 效果好,在很多动作识别数据集上都取得了SOTA效果
- 训练和推理都和高效
- 可以处理超过一分钟的长视频,也就是可以做长视频理解了。
另外还有一些其它的Vedio Transformer论文,也都是研究如何拆分时空自注意力,只是方式不一样,比如:
- VidTr(ICCV 2021):朱老师组的另一篇工作,提出了separable-attention用于视频分类。VidTr能够通过叠加注意力来聚集时空信息,效率更高性能更好。
- MViT(Multi-Scale Vision Longformer,ICCV 2021 ):Facebook的工作,使用了多尺度和Longformer,效果更好。
- ViViT(ICCV 2021 ):Google 的工作
六 总结
本文讲了这么多模型,下面就再把这些都简单的串讲一下。
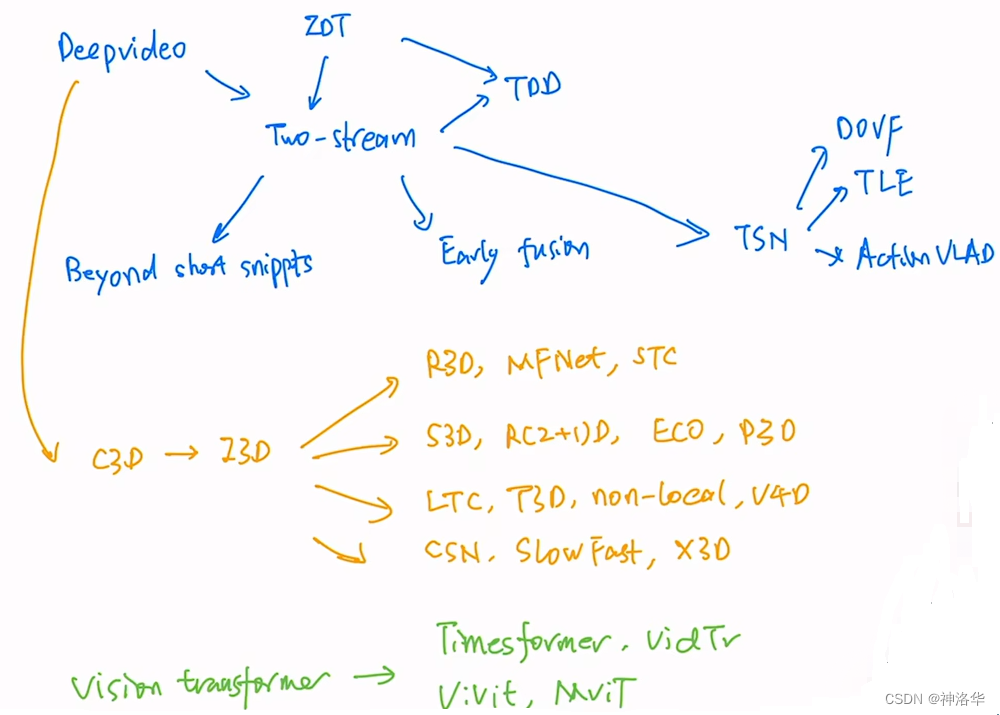
- 阶段一:
- DeepVedio(CVPR2014:最早将CNN网络用于视频理解
- 自从2012年
Alexnet出来之后,大家就想把CNN也用到视频理解领域,所以就有了DeepVedio这个工作。 - 提出了
Sports-1M数据集(100万视频) DeepVedio没有很好地利用运动信息,所以即使在Sports-1M这么大的数据集上预训练,效果也不好(UCF101精度65.4%),比最好的手工特征IDT差了近20个点。
- 自从2012年
- DeepVedio(CVPR2014:最早将CNN网络用于视频理解
- 阶段二:Two-Stream
- Two-Stream(NeurIPS 2014 :开启了用深度学习做视频理解的新时代(
UCF101精度87%)。- 作者受IDT的启发,考虑将运动特征也加入到网络中来。最后是选择了引入光流的形式,用一个额外的时间流网络学习物体的运动特征,大大提高了模型的精度,使其可以媲美最好的手工特征,由此开启了用深度学习来做视频理解的时代。
- 因为Two-Stream证明了其有效性,所以后续涌现了很多改进工作。
- Two-Stream+LSTM(CVPR 2015:融入LSTM,使模型拥有更长的时序建模(理解)能力
- Two-Stream+Early Fusion(CVPR 2016 ):改进了双流网络简单加权平均的Late Fusion方式。简单就是在Conv5这一层两个分支做3D Conv+3D Pooling,融合时空特征;同时时间流单独拿出来也做一次3D pooling,最后进行特征融合(加权平均)。相应的模型有Spatiotemporal Loss 和Temporal Loss两个损失函数。(
UCF101精度91.5%左右) TDD(CVPR 2015):将光流按轨迹叠加特征,效果更好TSN(ECCV 2016):为了处理长视频理解,TSN将长视频分成K段,每段都输入一个双流网络。然后将K个时间流特征进行融合得到一个时间流特征,空间流特征也这样操作。最后将两个融合后的特征再次合并,得到最终的视频特征。(UCF101精度94%左右)- TSN得想法非常简单,所以后面也有很多改进,也就是加入传统手工特征里面的全局建模。到这个阶段,就把UCF-101和HDB51刷的非常高了,也没有什么太多可以做的了。
- DOVF:在TSN基础上融入了全局编码(Fisher Vectors encoding),从而获取了更加全局的特征,UCF101精度推到95%以上。
- TLE (CVPR 2017 ):融入了temporal linear encoding (TLE)全局编码,并且把模型做到端到端。
- Action VLAD:融入了VLAD encoding全局编码
- Two-Stream(NeurIPS 2014 :开启了用深度学习做视频理解的新时代(
- 阶段三:3D CNN
-
C3D(ICCV 2015):将3D CNN用于视频理解是一个很自然的想法,所以有了C3D这篇工作。因为有了
Sports-1M这么大的数据集,作者觉得还是可以训练一个很好的网络的。结果C3D抽取特征还可以(作者提供了抽取特征的接口),但是直接用于刷分效果还是差的比较远(C3D (1 net)+linear SVM在UCF101精度为82.3)。 -
I3D(CVPR 2017):
Two-Stream+3D ConvNet,开启3D CNN 做视频理解的时代- C3D的效果不好,可能是网络的初始化不够好。I3D的作者使用将2D网络Inflating成3D网络,保持整体网络架构不变。这样既不用从头设计3D网络,还可以使用Bootstrapping技术,将2D网络的预训练参数,用于扩张后的3D 网络的初始化,使模型得到更好的效果。
- 依旧使用了光流,提高模型性能。
- 提出了
K400数据集 UCF-101和HDB51两个数据集基本被刷爆了,此后,大家都使用K400数据集或者SSv2数据集汇报结果。
-
改进backbone:R3D(ResNet)、MFNet(ResNext)、STC(SENet)
-
将纯3D CNN改为2D+3D的形式:降低模型复杂度,大幅提高模型性能。
- S3D、ECO、P3D等等。
- R(2+1)D(CVPR 2018 ):将3D CNN拆成2D的空间卷积+1D的时间卷积,降低过拟合和训练难度。
-
长视频理解:
- LTC(输入是120帧)、T3D、V4D
- non-local(CVPR 2018):融入自注意力,使模型精度更高,且可以建模更长的时间序列。
-
高效处理:
- CSN( Channel-Separate Network)、X3D(使用anto ml方式搜索网络,最终网络效果好,且参数量很少,基本刷到顶了)
- SlowFast(ICCV 2019 ):使用快慢结合的网络来用于视频分类,两个网络分别学习静态信息和运动信息,得到了SOTA效果。
-
- 阶段四:Vedio Transformer:3D 基本刷不动了,正好ICLR 2021发布了ViT模型,从此步入了Vedio Transformer时代
- TimeSformer(2021.2.9):Joint Space-Time Attention太贵了,容易爆显存,所以考虑将其拆分。借鉴
R(2+1)D的方法,将其拆分为Temporal Self Attention+Spatial Self Attention。 - 还有一些其它的拆分自注意力工作,比如VidTr、MViT、ViViT等等。
- TimeSformer(2021.2.9):Joint Space-Time Attention太贵了,容易爆显存,所以考虑将其拆分。借鉴
vison transformer在视频理解领域的应用还是比较初级的,在长视频、多模态、自监督等方向还可以进一步挖掘。而且视频领域发展这么多年,其实也还是处于一个比较初级的阶段,还有很多工作可以做。
最后借用Andrej Karpathy大神在Twitter的一句话:如果想训练一个强大的视觉模型,处理好视频才是正确的做法。










