Linux VFS Extended Attribute And Access Control Table
catalog
0. 简介
1. 扩展属性
2. 访问控制表
3. 小结
0. 简介
许多文件系统都提供了一些特性,扩展了VFS层提供的标准功能,虚拟文件系统不可能为所有特性都提供具体的数据结构。超出标准的UNIX文件模型的附加特性,通常需要将一个组扩展属性关联到每个文件系统对象
Linux内核能够提供的是一个框架,容许增加特定于文件系统的扩展,扩展属性(extended attribute xattrs)是能够关联到文件的任意属性,由于每个文件通常都只关联了所有可能扩展属性的一个子集,扩展属性存储在常规的inode数据结构之外,以避免增加该结构在内存中的长度和浪费磁盘空间,这实际上容许使用一个通用的属性集合,而不会对文件系统性能或磁盘空间需求有任何显著影响0x1: 扩展用途
1. 实现访问控制表(access control list)
对UNIX风格的权限模型进行扩展,它们允许实现细粒度的访问控制,不仅仅使用用户、组、其他用户的概念,而是将各个用户及其允许的操作组成一个明确的列表,关联到文件
这种列表很自然地融合到扩展属性模型中
2. 为SELINUX提供标记信息
Relevant Link:
1. 扩展属性
从文件系统用户的角度来看,一个扩展属性就是与文件系统对象关联的一个"名称/值"对
1. 名称: 一个普通字符串
2. 值: 内核对值的内容不作限制,可以是文本,也可以是包含任意二进制数据
属性名称会按命名空间细分,这意味着,访问属性也需要给出命名空间,按照符号约定,用一个点来分隔命名空间和属性名(例如user.mime_type)
内核使用宏定义了有效的顶层命名空间的列表(例如XATTR_*_PREFIX),在从用户空间传递来一个名字串,需要与命名空间前缀比较时,一组辅助性的宏XATTR_*_PREFIX_LEN是很有用的
\linux-2.6.32.63\include\linux\xattr.h
/* Namespaces */
#define XATTR_OS2_PREFIX "os2."
#define XATTR_OS2_PREFIX_LEN (sizeof (XATTR_OS2_PREFIX) - 1)
#define XATTR_SECURITY_PREFIX "security."
#define XATTR_SECURITY_PREFIX_LEN (sizeof (XATTR_SECURITY_PREFIX) - 1)
#define XATTR_SYSTEM_PREFIX "system."
#define XATTR_SYSTEM_PREFIX_LEN (sizeof (XATTR_SYSTEM_PREFIX) - 1)
#define XATTR_TRUSTED_PREFIX "trusted."
#define XATTR_TRUSTED_PREFIX_LEN (sizeof (XATTR_TRUSTED_PREFIX) - 1)
#define XATTR_USER_PREFIX "user."
#define XATTR_USER_PREFIX_LEN (sizeof (XATTR_USER_PREFIX) - 1)
内核提供了几个系统调用来读取和操作扩展属性
1. setxattr: 用于设置或替换某个扩展属性的值,或创建一个新的扩展属性
2. getxattr: 获取某个扩展属性的值
3. removexattr: 删除一个扩展属性
4. listxattr: 列出与给定的文件系统对象相关的所有扩展属性
0x1: 到虚拟文件系统的接口
虚拟文件系统向用户空间提供了一个抽象层,使得所有应用程序都可以使用扩展属性,而无需考虑底层文件系统实现如何在磁盘上存储该信息,要注意的是,尽管VFS作为扩展属性提供了一个抽象层,这并不意味着每个文件系统都必须实现该特性,实际上,内核中的大多数文件系统都不支持扩展属性,但是Linux上的所有主流硬盘型的文件系统(如Ext3、reiscrfs、xfs等)都支持扩展属性
1. 数据结构
由于扩展属性的结构非常简单,内核并没有提供一个特定的结构来封装这样的名称/值对,相反,内核使用了一个简单的字符串来表示名称,而用一个void指针来表示值在内存中的存储位置
但是仍然需要一些方法来设置、检索、删除、列出扩展属性,由于这些操作是特定于inode的,因此它们归入struct inode_operations
事实上,文件系统可以为这些操作提供定制实现,但内核也提供了一组通用的处理程序(例如Ext3文件系统即使用了内核的通用实现),在理解其实现之前,我们需要先了解基本的数据结构,对每一对扩展属性,都需要函数与块设备之间来回传输信息,这些函数封装在下列结构中
\linux-2.6.32.63\include\linux\xattr.h
struct xattr_handler
{
//表示命名空间,该操作即应用到这个命名空间的属性上,它可以是XATTR_*_PREFIX中的任何值
char *prefix;
//list方法列出一个与文件相关的所有扩展属性
size_t (*list)(struct inode *inode, char *list, size_t list_size, const char *name, size_t name_len);
//get方法从底层块设备读取扩展属性
int (*get)(struct inode *inode, const char *name, void *buffer, size_t size);
//set方法向底层块设备写入扩展属性
int (*set)(struct inode *inode, const char *name, const void *buffer, size_t size, int flags);
};
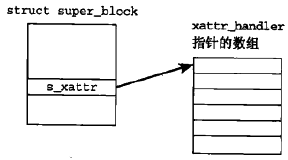
超级块提供了到一个数组的关联,该数组给出了相应文件系统的所有支持的处理程序
//搜索:0x10: struct super_block
处理程序在数组中出现的次序不是固定的,内核通过比较处理程序的前缀与所述扩展属性的命名空间的前缀,可以找到一个适当的次序
2. 系统调用
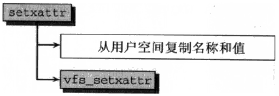
我们知道,每个扩展属性操作(get、set、list)都对应了3个系统调用,三者的区别在于指定目标的方法,为避免代码复制,这些系统调用在结构上分为两部分
1. 查找与目标对象相关联的dentry实例
查找dentry实例时,可使用user_path_walk、或user_path_walk_link、或直接读取包含在file实例中的指针,具体的做法取决于使用了哪个系统调用,在找到dentry实例后,就为3个系统调用建立了一个公共的基础
2. 其他工作委托给一个函数,该函数对3个系统调用是通用的
我们以setxattr系统调用为例,相关代码流程图如下
/source/fs/xattr.c
/*
* Extended attribute SET operations
*/
static long setxattr(struct dentry *d, const char __user *name, const void __user *value, size_t size, int flags)
{
int error;
void *kvalue = NULL;
char kname[XATTR_NAME_MAX + 1];
if (flags & ~(XATTR_CREATE|XATTR_REPLACE))
return -EINVAL;
//将属性的名称/值从用户空间复制到内核空间
error = strncpy_from_user(kname, name, sizeof(kname));
if (error == 0 || error == sizeof(kname))
error = -ERANGE;
if (error < 0)
return error;
if (size) {
if (size > XATTR_SIZE_MAX)
return -E2BIG;
kvalue = memdup_user(value, size);
if (IS_ERR(kvalue))
return PTR_ERR(kvalue);
}
//进一步的处理委托给vfs_setxattr
error = vfs_setxattr(d, kname, kvalue, size, flags);
kfree(kvalue);
return error;
}
/source/fs/xattr.c
int vfs_setxattr(struct dentry *dentry, const char *name, const void *value, size_t size, int flags)
{
struct inode *inode = dentry->d_inode;
int error;
//内核需要确认用户是否有执行目标操作的权限,对于只读或不可修改的inode,操作会立即失败
error = xattr_permission(inode, name, MAY_WRITE);
if (error)
//VFS层并不关注security、system命名空间中的属性,如果xattr_permission返回0,则允许请求,内核忽略这些命名空间,并将选择权委派给安全模块
return error;
mutex_lock(&inode->i_mutex);
//LSM Hook
error = security_inode_setxattr(dentry, name, value, size, flags);
if (error)
goto out;
error = __vfs_setxattr_noperm(dentry, name, value, size, flags);
out:
mutex_unlock(&inode->i_mutex);
return error;
}
EXPORT_SYMBOL_GPL(vfs_setxattr);
error = xattr_permission(inode, name, MAY_WRITE);
static int xattr_permission(struct inode *inode, const char *name, int mask)
{
/*
* We can never set or remove an extended attribute on a read-only
* filesystem or on an immutable / append-only inode.
*/
if (mask & MAY_WRITE)
{
if (IS_IMMUTABLE(inode) || IS_APPEND(inode))
return -EPERM;
}
/*
* No restriction for security.* and system.* from the VFS. Decision
* on these is left to the underlying filesystem / security module.
VFS不限制security.*和system.*,对此类属性的判断留给底层文件系统/安全模块
*/
if (!strncmp(name, XATTR_SECURITY_PREFIX, XATTR_SECURITY_PREFIX_LEN) ||
!strncmp(name, XATTR_SYSTEM_PREFIX, XATTR_SYSTEM_PREFIX_LEN))
return 0;
/*
* The trusted.* namespace can only be accessed by a privileged user.
trusted.*命名空间只能由特权用户访问
*/
if (!strncmp(name, XATTR_TRUSTED_PREFIX, XATTR_TRUSTED_PREFIX_LEN))
return (capable(CAP_SYS_ADMIN) ? 0 : -EPERM);
/* In user.* namespace, only regular files and directories can have
* extended attributes. For sticky directories, only the owner and
* privileged user can write attributes.
在user.*命名空间中,只有普通文件和目录可以有扩展属性
对于"粘着位"置位的目录来说,只有所有者和特权用户能够写入属性值
*/
if (!strncmp(name, XATTR_USER_PREFIX, XATTR_USER_PREFIX_LEN)) {
if (!S_ISREG(inode->i_mode) && !S_ISDIR(inode->i_mode))
return -EPERM;
if (S_ISDIR(inode->i_mode) && (inode->i_mode & S_ISVTX) &&
(mask & MAY_WRITE) && !is_owner_or_cap(inode))
return -EPERM;
}
return inode_permission(inode, mask);
}
如果inode通过了权限检查,则vfs_setattr继续进行以下步骤
1. 如果inode_operations中提供了特定于文件系统的setattr方法,则调用该方法与文件系统进行底层交互,接下来,fsnotify_xattr使用inotify机制将扩展属性的改变通知用户层
2. 如果没提供setattr方法(即底层文件系统不支持扩展属性),但所述的扩展属性属于security命名空间,那么内核会试图使用由安全框架(例如SEINUX)提供的一个函数,如果没有注册此类框架,则拒绝该操作
//在不支持扩展属性的文件系统中,这种做法能够在文件上加上安全标记。同时以一种合理的方法来存储该信息,则是安全子系统的任务
3. 通用处理程序函数
安全是一项重要的工作,如果做出错误的决策,那么即使最佳的安全机制也毫无价值,由于代码的复制增加了细节出错的可能性,所以内核对处理扩展属性的inode_operations方法提供了通用实现(实际上,内核对VFS的很多函数都封装了通用的实现),文件系统开发者可以直接使用这些实现
/source/fs/xattr.c
/*
* Find the handler for the prefix and dispatch its set() operation.
*/
int generic_setxattr(struct dentry *dentry, const char *name, const void *value, size_t size, int flags)
{
struct xattr_handler *handler;
struct inode *inode = dentry->d_inode;
if (size == 0)
value = ""; /* empty EA, do not remove */
//首先,xattr_resolve_name查找适用于所述扩展属性的命名空间的xattr_handler实例
handler = xattr_resolve_name(inode->i_sb->s_xattr, &name);
if (!handler)
return -EOPNOTSUPP;
//如果存在一个处理程序,则调用其set方法来执行设置属性值的操作,handler->set是一个特定于文件系统的方法
return handler->set(inode, name, value, size, flags);
}
0x2: ext3中的实现
在所有文件系统中,Ext3是最杰出的成员之一,因为它提供了对扩展属性的良好支持,我们继续讨论在文件系统层面上对扩展属性的实现,以及扩展属性如何在磁盘上持久存储
1. 数据结构
Ext3采纳了一些提高编码效率的良好建议,并采用了VFS通用实现,它提供了若干处理程序函数,并使用标识号来访问处理程序函数,而不是按照字符串标识,这简化了许多操作,并能够更高效地利用磁盘空间
\linux-2.6.32.63\fs\ext3\xattr.c
static struct xattr_handler *ext3_xattr_handler_map[] =
{
[EXT3_XATTR_INDEX_USER] = &ext3_xattr_user_handler,
#ifdef CONFIG_EXT3_FS_POSIX_ACL
[EXT3_XATTR_INDEX_POSIX_ACL_ACCESS] = &ext3_xattr_acl_access_handler,
[EXT3_XATTR_INDEX_POSIX_ACL_DEFAULT] = &ext3_xattr_acl_default_handler,
#endif
[EXT3_XATTR_INDEX_TRUSTED] = &ext3_xattr_trusted_handler,
#ifdef CONFIG_EXT3_FS_SECURITY
[EXT3_XATTR_INDEX_SECURITY] = &ext3_xattr_security_handler,
#endif
};
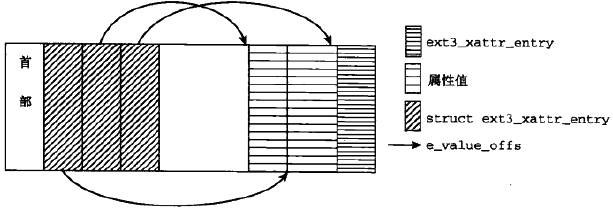
结构描述如下
1. 扩展属性所占的空间,由一个短的标识头开始,即首部
\linux-2.6.32.63\fs\ext3\xattr.h
struct ext3_xattr_header
{
/* magic number for identification 用于标识的魔数 */
__le32 h_magic;
/* reference count 引用计数 */
__le32 h_refcount;
/* number of disk blocks used 使用磁盘块的数目,必须总是设置为1,其他任何值都是错的 */
__le32 h_blocks;
/* hash value of all attributes 所有属性的散列值 */
__le32 h_hash;
__u32 h_reserved[4]; /* zero right now */
};
2. 接下来是一系列数据项的列表(struct ext3_xattr_entry),每个数据项都包含了属性名称和指向属性值存储区域的一个指针,在向文件添加新的扩展属性时,列表向下增长
struct ext3_xattr_entry
{
/* length of name 名称长度 */
__u8 e_name_len;
/* attribute name index 属性名索引,用于索引ext3_xattr_handler_map */
__u8 e_name_index;
/* offset in disk block of value 属性值在所处磁盘块中的偏移量 */
__le16 e_value_offs;
/* disk block attribute is stored on (n/i) 存储属性的磁盘块 */
__le32 e_value_block;
/* size of attribute value 属性值长度 */
__le32 e_value_size;
/* hash value of name and value 属性名和值的散列值 */
__le32 e_hash;
/*
attribute name 属性名
各个数据项的长度不一定是相同的,因为属性名的长度是可变的,因此将属性名存储在结构末尾
*/
char e_name[0];
};
3. 属性值存储在扩展属性数据空间的尾部,值表与属性名称表相对增长,属性值可以按任意次序存储,通常与属性名称排序不同
Ext3扩展属性的结构可以放置在两个地方
1. inode末尾的未使用空间: 只有使用了允许动态inode长度的新文件系统格式(EXT3_DYNAMIC_REV)才可能出现
2. 磁盘上一个独立的数据块
//如果两个文件的扩展属性集合是相同的,那么二者可以共享同一个磁盘表示,这有助于节省一些磁盘空间
2. 实现
对不同的属性命名空间,处理程序的实现十分类似,我们以user命名空间的实现为例进行讨论,ext3_xattr_user_hanler的定义如下
\linux-2.6.32.63\fs\ext3\xattr_user.c
struct xattr_handler ext3_xattr_user_handler =
{
.prefix = XATTR_USER_PREFIX,
.list = ext3_xattr_user_list,
.get = ext3_xattr_user_get,
.set = ext3_xattr_user_set,
};
0x3: ext2中的实现
Ext2中的扩展属性的实现和Ext3的实现非常类似,但是由于Ext3中的一些特性在Ext2中是不可用的,这也是二者扩展属性的实现有所差别的原因
1. 由于Ext2并不支持动态的inode长度,所以磁盘上的inode中没有足够空间存储扩展属性的数据,因此,扩展属性总是存储在一个独立的数据块中,这简化了一些函数,因为无须区分扩展属性的不同存储位置
2. Ext2并不使用日志,因此所有日志相关函数的调用都是不必要的,这也使得一些只处理句柄操作的包装器变得不必要
//此外,二者的实现几乎相同,大部分函数,将前缀ext3_换成ext2_之后,都是可用的
2. 访问控制表
POSIX访问控制表(ACL)是POSIX标准定义的一种扩展,用于细化Linx的自主访问控制(DAC)模型。ACL借助扩展属性实现,修改ACL所用的方法与其他扩展属性是相同的,内核对扩展属性的内容并不感兴趣,但ACL扩展属性将集成到inode权限检查中,尽管文件系统可以自由选择用于表示扩展属性的物理格式,但内核仍然定义了用于表示访问控制表的交换结构,对于承载访问控制表的扩展属性,必须使用下列命名空间
\linux-2.6.32.63\include\linux\posix_acl_xattr.h
/* Extended attribute names */
#define POSIX_ACL_XATTR_ACCESS "system.posix_acl_access"
#define POSIX_ACL_XATTR_DEFAULT "system.posix_acl_default"
用户层getfacl、setfacl、chacl用于获取、设置和修改ACL的内容,它们使用可以操作扩展属性的标准系统调用,并不需要与内核进行非标准交互,许多其他实用程序(例如ls)也内建了对访问控制表的支持0x1: 通用实现
用于实现ACL的通用代码包含在两个文件中
1. \linux-2.6.32.63\fs\posix_acl.c
包含了分配新ACL、复制ACL、进行扩展权限检查等功能代码
2. \linux-2.6.32.63\fs\xattr_acl.c
包含的函数用于在扩展属性、ACL的通用表示之间进行转换,并且转换是双向的
/*
所有通用的数据结构都定义在
\linux-2.6.32.63\include\linux\posix_acl_xattr.h
\linux-2.6.32.63\include\linux\posix_acl.h
*/
1. 数据结构
用于存储与ACL相关的所有数据的内存表示的主要数据结构定义如下
\linux-2.6.32.63\include\linux\posix_acl.h
/*
每个ACL项都包含了
1. 一个标记
2. 一个权限
3. 一个(用户/组)ID
该ACL项即定义了该ID对某文件的权限
*/
struct posix_acl_entry
{
short e_tag;
unsigned short e_perm;
unsigned int e_id;
};
//属于给定inode的所有ACL,都收集到struct posix_acl 中
struct posix_acl
{
atomic_t a_refcount;
unsigned int a_count;
//由于包含所有ACL项的数组位于结构末尾,所以ACL项的最大数据除了受到扩展属性最大长度的限制之外,并无其他限制
struct posix_acl_entry a_entries[0];
};
用于ACL类型、标记、权限的符号常数,由以下预处理器定义给出
\linux-2.6.32.63\include\linux\posix_acl.h
/* a_type field in acl_user_posix_entry_t */
#define ACL_TYPE_ACCESS (0x8000)
#define ACL_TYPE_DEFAULT (0x4000)
/* e_tag entry in struct posix_acl_entry */
#define ACL_USER_OBJ (0x01)
#define ACL_USER (0x02)
#define ACL_GROUP_OBJ (0x04)
#define ACL_GROUP (0x08)
#define ACL_MASK (0x10)
#define ACL_OTHER (0x20)
/* permissions in the e_perm field */
#define ACL_READ (0x04)
#define ACL_WRITE (0x02)
#define ACL_EXECUTE (0x01)
内核定义了另一组数据结构,用于和用户层的外部交互中ACL的扩展属性表示
\linux-2.6.32.63\include\linux\posix_acl_xattr.h
typedef struct
{
__le16 e_tag;
__le16 e_perm;
__le32 e_id;
} posix_acl_xattr_entry;
typedef struct
{
__le32 a_version;
posix_acl_xattr_entry a_entries[0];
} posix_acl_xattr_header;
posix_acl_from_xattr、posix_acl_to_xattr用于在两种表示之间来回转换,函数的工作是独立于底层文件系统的
2. 权限检查
对涉及访问控制表的权限检查,内核通常需要底层文件系统的支持
1. 文件系统自行实现所有的权限检查,通过struct inode_operations->permission函数
2. 文件系统提供一个回调函数供generic_permission使用(内核中大多数文件系统默认使用的方法)
generic_permission中使用的回调函数如下
\linux-2.6.32.63\fs\namei.c
//搜索:0x3: 权限检查
即使文件系统提供了进行ACL权限检查的专用函数,但各个例程通常会归结到一些技术性的工作,例如获得ACL数据,而真正的权限检查仍然会委托给内核提供的标准函数: posix_acl_permission
\linux-2.6.32.63\fs\posix_acl.c
int posix_acl_permission(struct inode *inode, const struct posix_acl *acl, int want)
{
const struct posix_acl_entry *pa, *pe, *mask_obj;
int found = 0;
//使用FOREACH_ACL_ENTRY宏来遍历所有的ACL项
FOREACH_ACL_ENTRY(pa, acl, pe)
{
switch(pa->e_tag)
{
case ACL_USER_OBJ:
/*
(May have been checked already)
对每个ACL项,都需要比较文件系统UID(FSUID),和当前进程凭据的相应部分
1. 对_OBJ类型的ACL项,需要比较inode的UID/GID
2/ 对其他类型的项,需要比较ACL项中指定的ID
*/
if (inode->i_uid == current_fsuid())
goto check_perm;
break;
case ACL_USER:
if (pa->e_id == current_fsuid())
goto mask;
break;
case ACL_GROUP_OBJ:
if (in_group_p(inode->i_gid)) {
found = 1;
if ((pa->e_perm & want) == want)
goto mask;
}
break;
case ACL_GROUP:
if (in_group_p(pa->e_id)) {
found = 1;
if ((pa->e_perm & want) == want)
goto mask;
}
break;
case ACL_MASK:
break;
case ACL_OTHER:
if (found)
return -EACCES;
else
goto check_perm;
default:
return -EIO;
}
}
return -EIO;
//从根本上来说,授权访问权限,代码的控制流在mask标号结束,在这种情况下,仍然需要确认在授权ACL项之后没有声明ACL_MASK项,所以导致拒绝授权
mask:
for (mask_obj = pa+1; mask_obj != pe; mask_obj++)
{
if (mask_obj->e_tag == ACL_MASK)
{
if ((pa->e_perm & mask_obj->e_perm & want) == want)
return 0;
return -EACCES;
}
}
//下面代码确保,权限不仅仅因为适当的UID/GID而有效,而且授权ACL项也允许了所要进行的访问(读、写、执行),即是否满足主体-客体的授权关系
check_perm:
if ((pa->e_perm & want) == want)
return 0;
return -EACCES;
}
0x2: ext3中的实现
我们知道,ACL基于扩展属性实现,并借助了许多通用的辅助例程,所以Ext3对ACL的实现相当简洁
1. 数据结构
Ext3的ACL的磁盘表示的格式与通用的POSIX辅助函数所需的内存非常类似
\linux-2.6.32.63\fs\ext3\acl.h
typedef struct
{
__le16 e_tag;
__le16 e_perm;
__le32 e_id;
} ext3_acl_entry;
//为了节省磁盘空间,还定义了一个e_id字段的版本,该版本用于ACL列表的前四项,因为这几项不需要具体的UID/GID
typedef struct
{
__le16 e_tag;
__le16 e_perm;
} ext3_acl_entry_short;
ACL项的列表总是有一个表头
typedef struct
{
//a_version字段使得能够区分ACL实现的不同版本
__le32 a_version;
} ext3_acl_header;
Ext3 inode的内存表示增加了两个与ACL实现相关的字段
\linux-2.6.32.63\include\linux\ext3_fs_i.h2. 磁盘和内存表示之间的转换
有两个转换函数可用于磁盘和内存表示之间的转换
1. ext3_acl_to_disk: 遍历给定的posix_acl实例中的所有ACL项,将其中包含的数据从特定于CPU的格式转换为小端序格式,并指定适当的位长
2. ext3_acl_from_disk: 从inode中包含的信息获取裸数据,剥去头信息,将ACL列表中每个ACL项的数据从小端序格式转换为适用于系统本机CPU的格式
//fs/ext3/acl.c
3. inode初始化
在用ext3_new_inode创建新inode时,ACL的初始化委托给ext3_init_acl
\linux-2.6.32.63\fs\ext3\acl.c
/*
* Initialize the ACLs of a new inode. Called from ext3_new_inode.
*
* dir->i_mutex: down
* inode->i_mutex: up (access to inode is still exclusive)
1. inode参数指向新的inode
2. dir表示包含inode对应文件的目录的inode,之所以需要目录信息,是因为如果目录包含了默认ACL,则其内容需要应用到新的文件,这是权限继承原则
*/
int ext3_init_acl(handle_t *handle, struct inode *inode, struct inode *dir)
{
struct posix_acl *acl = NULL;
int error = 0;
if (!S_ISLNK(inode->i_mode))
{
if (test_opt(dir->i_sb, POSIX_ACL)) {
acl = ext3_get_acl(dir, ACL_TYPE_DEFAULT);
if (IS_ERR(acl))
return PTR_ERR(acl);
}
if (!acl)
inode->i_mode &= ~current_umask();
}
//inode所在的文件系统支持ACL,而且父目录有与之关联的默认ACL
if (test_opt(inode->i_sb, POSIX_ACL) && acl)
{
struct posix_acl *clone;
mode_t mode;
if (S_ISDIR(inode->i_mode))
{
//ext3_set_acl用来设置特定inode的ACL内容
error = ext3_set_acl(handle, inode, ACL_TYPE_DEFAULT, acl);
if (error)
goto cleanup;
}
//调用posix_acl_clone对默认ACL的内存表示创建一个可工作的副本
clone = posix_acl_clone(acl, GFP_NOFS);
error = -ENOMEM;
if (!clone)
goto cleanup;
mode = inode->i_mode;
/*
调用posix_acl_create_masq,从inode创建进程指定的访问权限中,删除默认ACL不能授予的所有权限,这可能导致下面两种情形
1. 为符合ACL的要求,访问权限可能不变,也可能需要删除某些权限位,这种情况下,新的inode的i_mode字段,需要设置为posix_acl_create_masq计算出来的mode值
2. 除了对原来指定的访问权限进行必要的调整之外,默认ACL可能包含了一些ACL项,不能用通常的用户/组/其他方案来表示,在这种情况下,需要为新的inode创建一个ACL,包含相关的扩展权限信息
*/
error = posix_acl_create_masq(clone, &mode);
if (error >= 0)
{
inode->i_mode = mode;
if (error > 0)
{
/* This is an extended ACL */
error = ext3_set_acl(handle, inode, ACL_TYPE_ACCESS, clone);
}
}
posix_acl_release(clone);
}
cleanup:
posix_acl_release(acl);
return error;
}
4. 获取ACL
给出struct inode的一个实例,ext3_get_acl可用于获取ACL的内存表示
\linux-2.6.32.63\fs\ext3\acl.c
/*
* Inode operation get_posix_acl().
*
* inode->i_mutex: don't care
1. type指定了获取ACL类型
1) ACL_TYPE_DEFAULT: 默认ACL
2) ACL_TYPE_ACCESS: 获取由于控制inode访问权限的ACL
*/
static struct posix_acl *ext3_get_acl(struct inode *inode, int type)
{
int name_index;
char *value = NULL;
struct posix_acl *acl;
int retval;
if (!test_opt(inode->i_sb, POSIX_ACL))
return NULL;
//调用get_cached_acl检查ACL的内存表示是否已经缓存到了ext3_inode_info->i_acl,如果已经缓存,则直接创建并返回一个副本
acl = get_cached_acl(inode, type);
if (acl != ACL_NOT_CACHED)
return acl;
switch (type) {
case ACL_TYPE_ACCESS:
name_index = EXT3_XATTR_INDEX_POSIX_ACL_ACCESS;
break;
case ACL_TYPE_DEFAULT:
name_index = EXT3_XATTR_INDEX_POSIX_ACL_DEFAULT;
break;
default:
BUG();
}
//如果ACL无缓存,那么首先调用ext3_xattr_get从扩展属性子系统获取裸数据
retval = ext3_xattr_get(inode, name_index, "", NULL, 0);
if (retval > 0) {
value = kmalloc(retval, GFP_NOFS);
if (!value)
return ERR_PTR(-ENOMEM);
retval = ext3_xattr_get(inode, name_index, "", value, retval);
}
if (retval > 0)
acl = ext3_acl_from_disk(value, retval);
else if (retval == -ENODATA || retval == -ENOSYS)
acl = NULL;
else
acl = ERR_PTR(retval);
kfree(value);
if (!IS_ERR(acl))
set_cached_acl(inode, type, acl);
return acl;
}
5. 修改ACL
在通过ext3_setattr改变文件的(通用)属性时,ext3_acl_chmod函数负责保持ACL为最新数据并维护其一致性。一般来说,用户空间通过系统调用来调用VFS层,VFS层又通过ext3_setattr来修改属性
\linux-2.6.32.63\fs\ext3\inode.c
int ext3_setattr(struct dentry *dentry, struct iattr *attr)
{
struct inode *inode = dentry->d_inode;
int error, rc = 0;
const unsigned int ia_valid = attr->ia_valid;
error = inode_change_ok(inode, attr);
if (error)
return error;
if ((ia_valid & ATTR_UID && attr->ia_uid != inode->i_uid) ||
(ia_valid & ATTR_GID && attr->ia_gid != inode->i_gid)) {
handle_t *handle;
/* (user+group)*(old+new) structure, inode write (sb,
* inode block, ? - but truncate inode update has it) */
handle = ext3_journal_start(inode, 2*(EXT3_QUOTA_INIT_BLOCKS(inode->i_sb)+
EXT3_QUOTA_DEL_BLOCKS(inode->i_sb))+3);
if (IS_ERR(handle)) {
error = PTR_ERR(handle);
goto err_out;
}
error = vfs_dq_transfer(inode, attr) ? -EDQUOT : 0;
if (error) {
ext3_journal_stop(handle);
return error;
}
/* Update corresponding info in inode so that everything is in
* one transaction */
if (attr->ia_valid & ATTR_UID)
inode->i_uid = attr->ia_uid;
if (attr->ia_valid & ATTR_GID)
inode->i_gid = attr->ia_gid;
error = ext3_mark_inode_dirty(handle, inode);
ext3_journal_stop(handle);
}
if (S_ISREG(inode->i_mode) &&
attr->ia_valid & ATTR_SIZE && attr->ia_size < inode->i_size) {
handle_t *handle;
handle = ext3_journal_start(inode, 3);
if (IS_ERR(handle)) {
error = PTR_ERR(handle);
goto err_out;
}
error = ext3_orphan_add(handle, inode);
EXT3_I(inode)->i_disksize = attr->ia_size;
rc = ext3_mark_inode_dirty(handle, inode);
if (!error)
error = rc;
ext3_journal_stop(handle);
}
rc = inode_setattr(inode, attr);
if (!rc && (ia_valid & ATTR_MODE))
//由于在最后才调用ext3_acl_chmod,因而新的权限已经设置到inode中的访问控制部分,因而需要将指向所述struct inode实例的指针作为参数输入
rc = ext3_acl_chmod(inode);
err_out:
ext3_std_error(inode->i_sb, error);
if (!error)
error = rc;
return error;
}
ext3_acl_chmod的运作逻辑如下
\linux-2.6.32.63\fs\ext3\acl.c
int ext3_acl_chmod(struct inode *inode)
{
struct posix_acl *acl, *clone;
int error;
if (S_ISLNK(inode->i_mode))
return -EOPNOTSUPP;
if (!test_opt(inode->i_sb, POSIX_ACL))
return 0;
//获得指向ACL数据内存表示的指针之后
acl = ext3_get_acl(inode, ACL_TYPE_ACCESS);
if (IS_ERR(acl) || !acl)
return PTR_ERR(acl);
//调用posix_acl_clone创建一个可工作的副本
clone = posix_acl_clone(acl, GFP_KERNEL);
posix_acl_release(acl);
if (!clone)
return -ENOMEM;
//主要工作委托给posix_acl_chmod_masq
error = posix_acl_chmod_masq(clone, inode->i_mode);
if (!error) {
handle_t *handle;
int retries = 0;
retry:
//启动事务处理
handle = ext3_journal_start(inode,
EXT3_DATA_TRANS_BLOCKS(inode->i_sb));
if (IS_ERR(handle)) {
error = PTR_ERR(handle);
ext3_std_error(inode->i_sb, error);
goto out;
}
//在获得事务句柄后,ext3_set_acl用来将修改后的ACL数据写回
error = ext3_set_acl(handle, inode, ACL_TYPE_ACCESS, clone);
//通知日志相关操作结束
ext3_journal_stop(handle);
if (error == -ENOSPC &&
ext3_should_retry_alloc(inode->i_sb, &retries))
goto retry;
}
out:
//释放ACL副本
posix_acl_release(clone);
return error;
}

更新ACL数据的一般性工作在posix_acl_chmod_masq中进行
\linux-2.6.32.63\fs\posix_acl.c
/*
* Modify the ACL for the chmod syscall.
*/
int posix_acl_chmod_masq(struct posix_acl *acl, mode_t mode)
{
struct posix_acl_entry *group_obj = NULL, *mask_obj = NULL;
struct posix_acl_entry *pa, *pe;
/* assert(atomic_read(acl->a_refcount) == 1); */
//其中将遍历所有的ACL项
FOREACH_ACL_ENTRY(pa, acl, pe)
{
/*
属主、所在组、其他、ACL_MASK类型的ACL项都会相应更新,以反应最新的ACL数据
*/
switch(pa->e_tag)
{
case ACL_USER_OBJ:
pa->e_perm = (mode & S_IRWXU) >> 6;
break;
case ACL_USER:
case ACL_GROUP:
break;
case ACL_GROUP_OBJ:
group_obj = pa;
break;
case ACL_MASK:
mask_obj = pa;
break;
case ACL_OTHER:
pa->e_perm = (mode & S_IRWXO);
break;
default:
return -EIO;
}
}
if (mask_obj) {
mask_obj->e_perm = (mode & S_IRWXG) >> 3;
} else {
if (!group_obj)
return -EIO;
group_obj->e_perm = (mode & S_IRWXG) >> 3;
}
return 0;
}
6. 权限检查
我们知道,内核提供了通用的权限检查函数generic_permission,其中可以集成一个特定于文件系统的处理程序,用于ACL检查,Ext3中,ext3_permission函数(在进行权限检查时,由VFS层调用)指示generic_permission将ext3_check_acl作为处理ACL相关工作的回调函数
/source/fs/ext3/acl.c
int ext3_permission(struct inode *inode, int mask, struct nameidata *nd)
{
return generic_permission(inode, mask, ext3_check_acl);
}

0x3: ext2中的实现
Ext2对ACL的实现,几乎与Ext3完全相同
3. 小结
传统上,UNIX和Linux使用自主访问控制模型来判断哪些用户可以访问给定的资源,资源一般表示为文件系统中的文件,它是一种非常粗粒度的安全手段
ACL可以向文件系统对象提供更细粒度的访问控制手段,即向每个对象附加一个显式列出访问控制规则的列表(主体-客体关系)
Linux基于扩展属性实现ACL,与从UNIX继承而来的传统模型相比,扩展属性方法能够向文件系统对象增加额外的、更复杂的属性
Copyright (c) 2015 LittleHann All rights reserved










