environment:
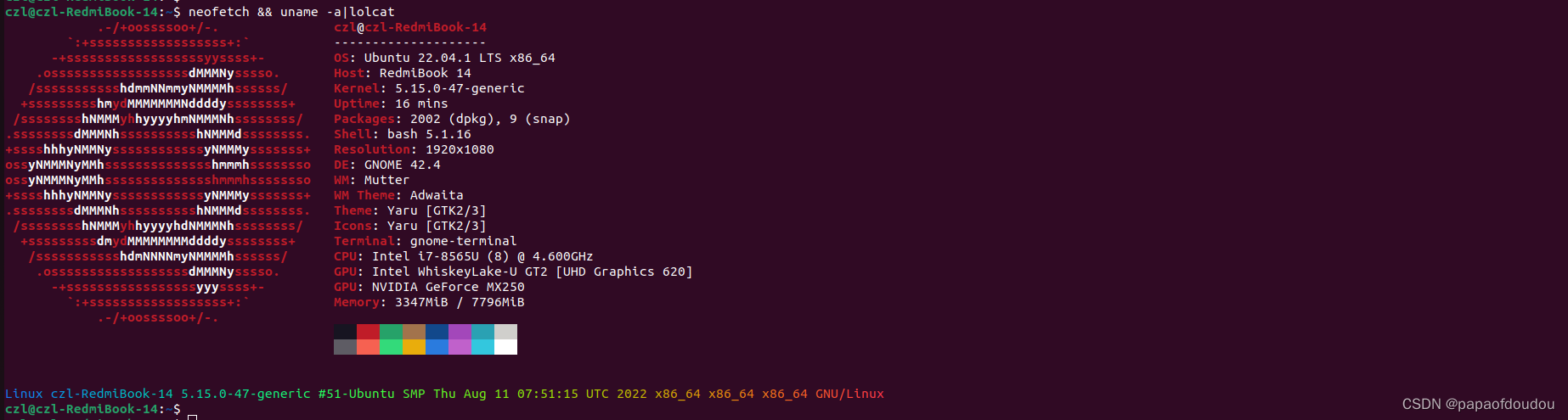
neofetch && uname -a|lolcat
install nvidia GPU driver:
sudo add-apt-repository ppa:graphics-drivers/ppa # 加入官方ppa源
sudo apt update # 检查软件包更新列表
apt list --upgradable # 查看可更新的软件包列表
sudo apt upgrade # 更新所有可更新的软件包
ubuntu-drivers devices # ubuntu检测n卡的可选驱动
sudo apt install nvidia-driver-510 # 根据自己的n卡可选驱动下载显卡驱动

ubuntu-drivers devices # ubuntu检测n卡的可选驱动
sudo apt install nvidia-driver-510 # 根据自己的n卡可选驱动下载显卡驱动
disable the nouveau
disable the nouveau by add the nouveau to the black list.
/etc/modprobe.d/blacklist.conf
最后一行加上: blacklist nouveau

and execute:
$ sudo update-initramfs -u
$ reboot
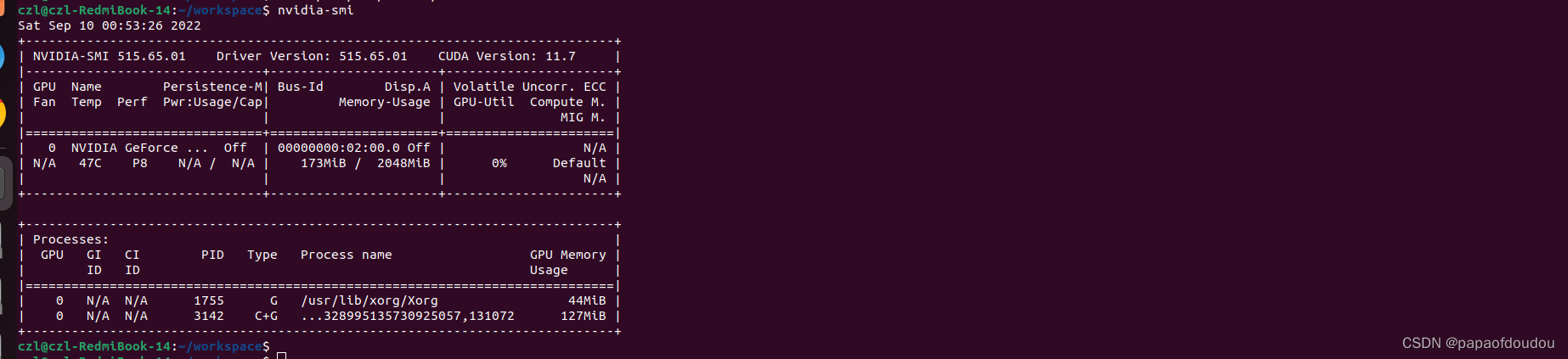
reboot the system and execute the nvidia-smi:
the output of cuda does not mean the cuda environment already been installed, it just meas the corrspoinding versions of cuda that this driver supports.
sudo nvidia-settings # 更改Nvidia驱动设置
nvidia-smi # 查看显卡基本信息
install cuda:
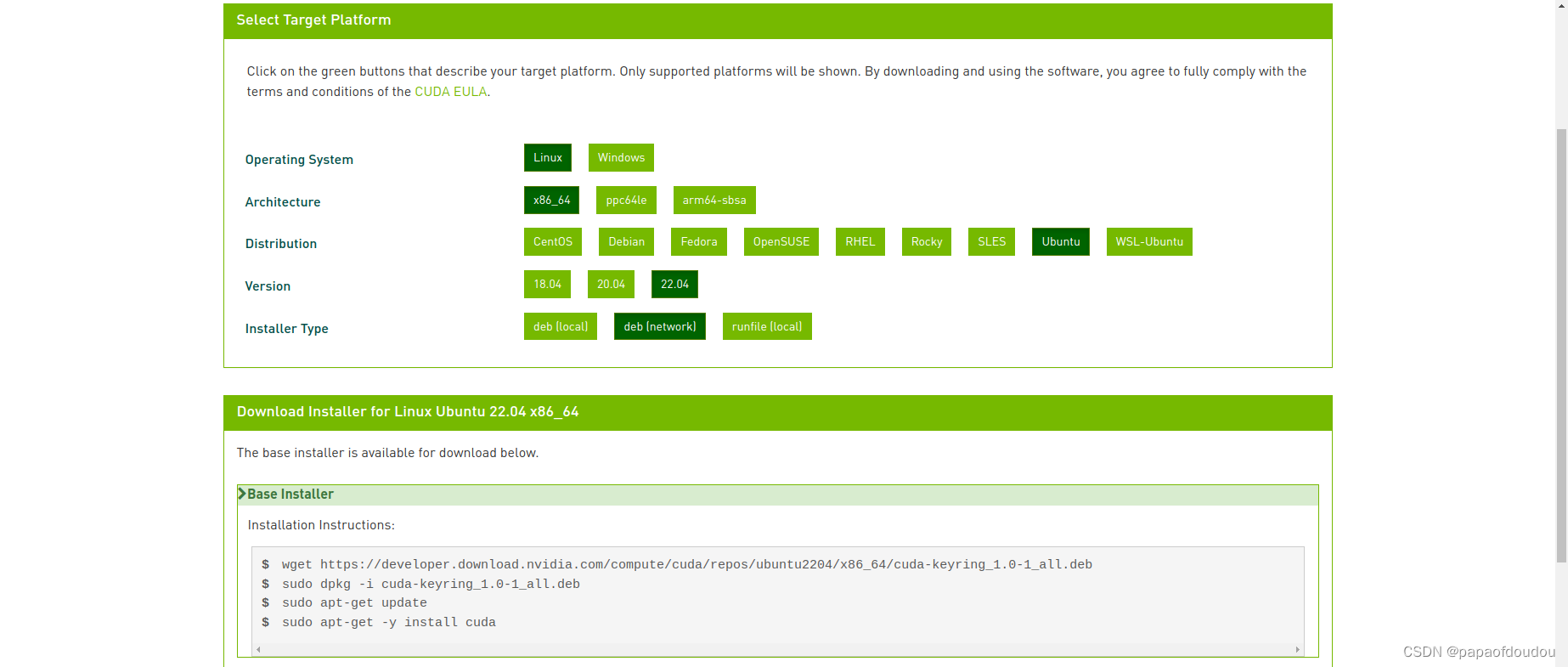
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda

nvcc:

add environment in bash shell
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.7/lib64
export PATH=$PATH:/usr/local/cuda-11.7/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.7
test,printf on device:
#include <cuda_runtime.h>
#include <stdio.h>
__device__ void add(void)
{
printf("kernel %s line %d, i am in kernel thread in block %d.\n", __func__, __LINE__,blockIdx.x);
}
__global__ void myfirstkernel(void)
{
printf("kernel %s line %d, i am in kernel thread in block %d.\n", __func__, __LINE__,blockIdx.x);
add();
}
int main(void)
{
myfirstkernel <<<16,1>>>();
cudaDeviceSynchronize();
printf("exit.\n");
return 0;
}

algo cuda sample:
#include <cuda_runtime.h>
#include <stdio.h>
__device__ void add(int a, int b, int *c)
{
*c = a + b;
printf("kernel %s line %d, i am in kernel thread in block %d. *c = %d.\n", __func__, __LINE__,blockIdx.x, *c);
}
__global__ void myfirstkernel(int a, int b, int *c)
{
printf("kernel %s line %d, i am in kernel thread in block %d.\n", __func__, __LINE__,blockIdx.x);
add(a, b, c);
}
int main(void)
{
int c;
int *gpu_c;
cudaMalloc((void **)&gpu_c, sizeof(int));
myfirstkernel <<<16,1>>>(3, 6, gpu_c);
cudaMemcpy(&c, gpu_c, sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(gpu_c);
cudaDeviceSynchronize();
printf("exit.c = %d.\n", c);
return 0;
}

change thread and block
#include <cuda_runtime.h>
#include <stdio.h>
__device__ void add(int a, int b, int *c)
{
*c = a + b;
printf("kernel %s line %d, i am in kernel thread %d in block %d. *c = %d.\n", __func__, __LINE__, threadIdx.x, blockIdx.x, *c);
}
__global__ void myfirstkernel(int a, int b, int *c)
{
printf("kernel %s line %d, i am in kernel thread %d in block %d.\n", __func__, __LINE__,threadIdx.x, blockIdx.x);
add(a, b, c);
}
int main(void)
{
int c;
int *gpu_c;
cudaMalloc((void **)&gpu_c, sizeof(int));
myfirstkernel <<<1,16>>>(3, 6, gpu_c);
cudaMemcpy(&c, gpu_c, sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(gpu_c);
cudaDeviceSynchronize();
printf("exit.c = %d.\n", c);
return 0;
}
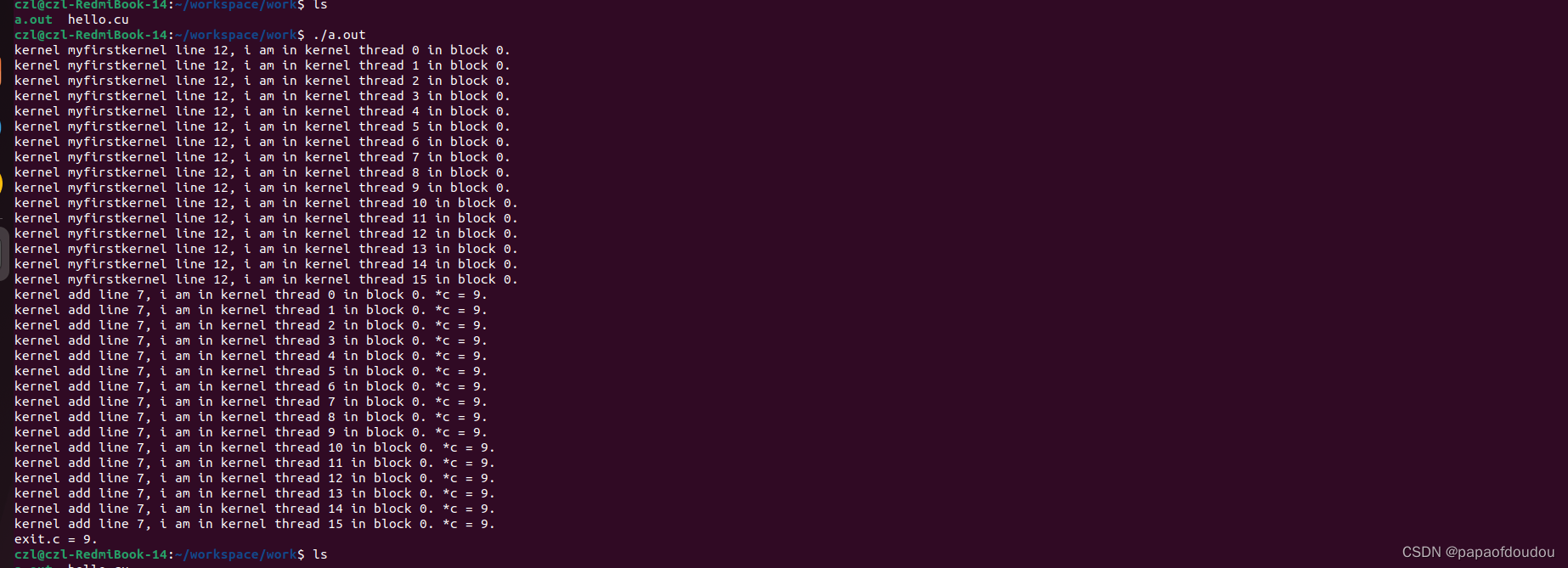
#include <cuda_runtime.h>
#include <stdio.h>
__device__ void add(int a, int b, int *c)
{
*c = a + b;
printf("kernel %s line %d, i am in kernel thread %d in block %d. *c = %d.\n", __func__, __LINE__, threadIdx.x, blockIdx.x, *c);
}
__global__ void myfirstkernel(int a, int b, int *c)
{
printf("kernel %s line %d, i am in kernel thread %d in block %d.\n", __func__, __LINE__,threadIdx.x, blockIdx.x);
printf("block.x = %d, block.y = %d,block.z = %d\n", blockDim.x, blockDim.y,blockDim.z);
printf("thread.x = %d, thread.y = %d,thread.z = %d\n", threadIdx.x, threadIdx.y,threadIdx.z);
add(a, b, c);
}
int main(void)
{
int c;
int *gpu_c;
cudaMalloc((void **)&gpu_c, sizeof(int));
myfirstkernel <<<3,16>>>(3, 6, gpu_c);
cudaMemcpy(&c, gpu_c, sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(gpu_c);
cudaDeviceSynchronize();
printf("exit.c = %d.\n", c);
return 0;
}
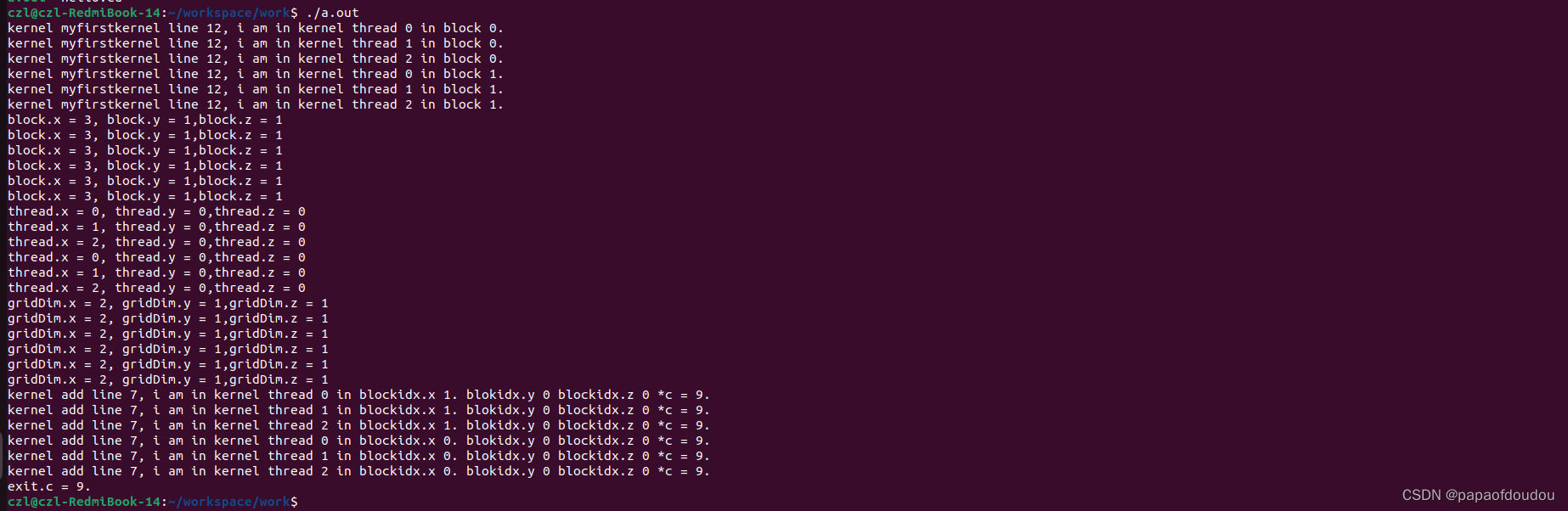
czl@czl-RedmiBook-14:~/workspace/work$ ./a.out
kernel myfirstkernel line 12, i am in kernel thread 0 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 1 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 2 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 3 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 4 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 5 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 6 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 7 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 8 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 9 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 10 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 11 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 12 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 13 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 14 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 15 in block 0.
kernel myfirstkernel line 12, i am in kernel thread 0 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 1 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 2 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 3 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 4 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 5 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 6 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 7 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 8 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 9 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 10 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 11 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 12 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 13 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 14 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 15 in block 1.
kernel myfirstkernel line 12, i am in kernel thread 0 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 1 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 2 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 3 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 4 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 5 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 6 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 7 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 8 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 9 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 10 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 11 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 12 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 13 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 14 in block 2.
kernel myfirstkernel line 12, i am in kernel thread 15 in block 2.
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
block.x = 16, block.y = 1,block.z = 1
thread.x = 0, thread.y = 0,thread.z = 0
thread.x = 1, thread.y = 0,thread.z = 0
thread.x = 2, thread.y = 0,thread.z = 0
thread.x = 3, thread.y = 0,thread.z = 0
thread.x = 4, thread.y = 0,thread.z = 0
thread.x = 5, thread.y = 0,thread.z = 0
thread.x = 6, thread.y = 0,thread.z = 0
thread.x = 7, thread.y = 0,thread.z = 0
thread.x = 8, thread.y = 0,thread.z = 0
thread.x = 9, thread.y = 0,thread.z = 0
thread.x = 10, thread.y = 0,thread.z = 0
thread.x = 11, thread.y = 0,thread.z = 0
thread.x = 12, thread.y = 0,thread.z = 0
thread.x = 13, thread.y = 0,thread.z = 0
thread.x = 14, thread.y = 0,thread.z = 0
thread.x = 15, thread.y = 0,thread.z = 0
thread.x = 0, thread.y = 0,thread.z = 0
thread.x = 1, thread.y = 0,thread.z = 0
thread.x = 2, thread.y = 0,thread.z = 0
thread.x = 3, thread.y = 0,thread.z = 0
thread.x = 4, thread.y = 0,thread.z = 0
thread.x = 5, thread.y = 0,thread.z = 0
thread.x = 6, thread.y = 0,thread.z = 0
thread.x = 7, thread.y = 0,thread.z = 0
thread.x = 8, thread.y = 0,thread.z = 0
thread.x = 9, thread.y = 0,thread.z = 0
thread.x = 10, thread.y = 0,thread.z = 0
thread.x = 11, thread.y = 0,thread.z = 0
thread.x = 12, thread.y = 0,thread.z = 0
thread.x = 13, thread.y = 0,thread.z = 0
thread.x = 14, thread.y = 0,thread.z = 0
thread.x = 15, thread.y = 0,thread.z = 0
thread.x = 0, thread.y = 0,thread.z = 0
thread.x = 1, thread.y = 0,thread.z = 0
thread.x = 2, thread.y = 0,thread.z = 0
thread.x = 3, thread.y = 0,thread.z = 0
thread.x = 4, thread.y = 0,thread.z = 0
thread.x = 5, thread.y = 0,thread.z = 0
thread.x = 6, thread.y = 0,thread.z = 0
thread.x = 7, thread.y = 0,thread.z = 0
thread.x = 8, thread.y = 0,thread.z = 0
thread.x = 9, thread.y = 0,thread.z = 0
thread.x = 10, thread.y = 0,thread.z = 0
thread.x = 11, thread.y = 0,thread.z = 0
thread.x = 12, thread.y = 0,thread.z = 0
thread.x = 13, thread.y = 0,thread.z = 0
thread.x = 14, thread.y = 0,thread.z = 0
thread.x = 15, thread.y = 0,thread.z = 0
kernel add line 7, i am in kernel thread 0 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 1 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 2 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 3 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 4 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 5 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 6 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 7 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 8 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 9 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 10 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 11 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 12 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 13 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 14 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 15 in block 0. *c = 9.
kernel add line 7, i am in kernel thread 0 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 1 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 2 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 3 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 4 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 5 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 6 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 7 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 8 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 9 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 10 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 11 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 12 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 13 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 14 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 15 in block 2. *c = 9.
kernel add line 7, i am in kernel thread 0 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 1 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 2 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 3 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 4 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 5 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 6 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 7 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 8 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 9 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 10 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 11 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 12 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 13 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 14 in block 1. *c = 9.
kernel add line 7, i am in kernel thread 15 in block 1. *c = 9.
exit.c = 9.
czl@czl-RedmiBook-14:~/workspace/work$
gridDim.x/gridDim.y/gridDim.z
#include <cuda_runtime.h>
#include <stdio.h>
__device__ void add(int a, int b, int *c)
{
*c = a + b;
printf("kernel %s line %d, i am in kernel thread %d in blockidx.x %d. blokidx.y %d blockidx.z %d *c = %d.\n", __func__, __LINE__, threadIdx.x, blockIdx.x, blockIdx.y,blockIdx.z,*c);
}
__global__ void myfirstkernel(int a, int b, int *c)
{
printf("kernel %s line %d, i am in kernel thread %d in block %d.\n", __func__, __LINE__,threadIdx.x, blockIdx.x);
printf("block.x = %d, block.y = %d,block.z = %d\n", blockDim.x, blockDim.y,blockDim.z);
printf("thread.x = %d, thread.y = %d,thread.z = %d\n", threadIdx.x, threadIdx.y,threadIdx.z);
printf("gridDim.x = %d, gridDim.y = %d,gridDim.z = %d\n", gridDim.x, gridDim.y,gridDim.z);
add(a, b, c);
}
int main(void)
{
int c;
int *gpu_c;
cudaMalloc((void **)&gpu_c, sizeof(int));
myfirstkernel <<<2,3>>>(3, 6, gpu_c);
cudaMemcpy(&c, gpu_c, sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(gpu_c);
cudaDeviceSynchronize();
printf("exit.c = %d.\n", c);
return 0;
}
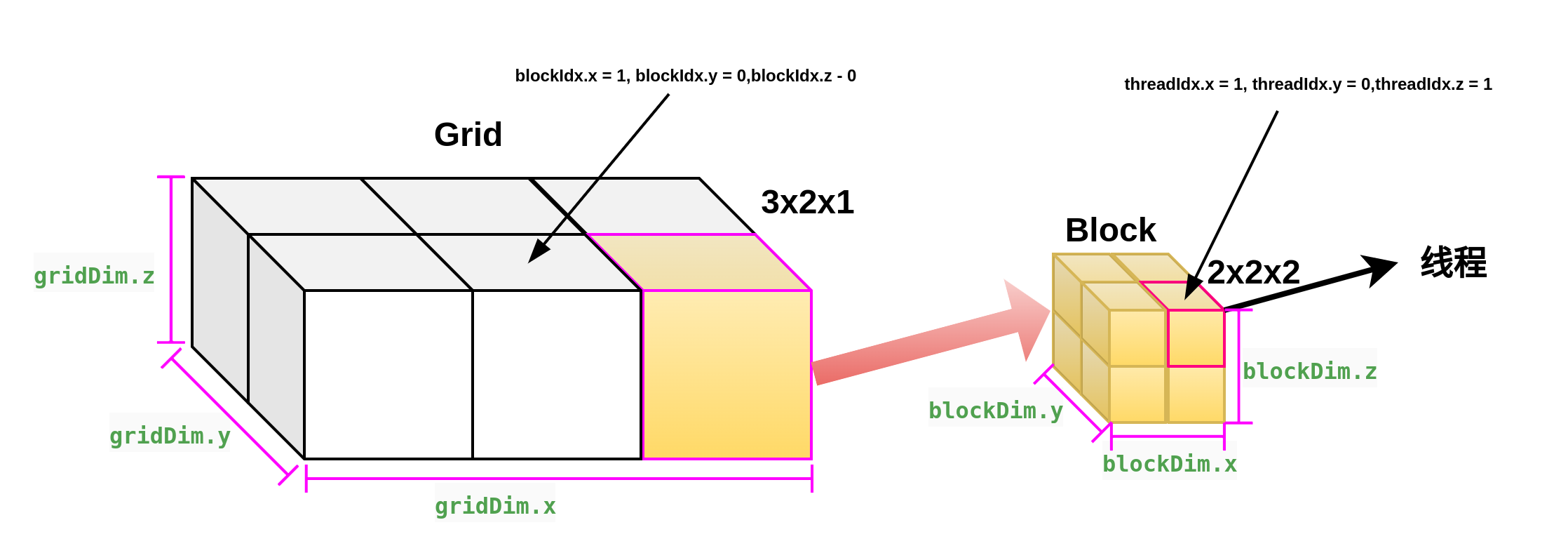
kernel call convontion:
kernel call invocation convotional is:
dim3 gridSize(3,2,1);
dim3 blockSize(2,2,2);
my_first_kernel<<<gridSize, blockSize>>>(para1,para2,...);
主机函数在声明的时候可以带有限定符__host__,全局函数在声明时必须带有限定符__global__.如果声明的函数没有限定符,则系统将认为其是主机函数,限定符写在返回类型之前。从上面的程序可以观察到,在调用全剧函数时除了函数名和形参表外,还有一个用三个小于号"<"和三个大于号">"包含的部分,这一部分用来指定在并行计算时使用的线程组数和每一个线程组包含的线程数。CUDA中将每一个线程组称为一个BLOCK,每个BLOCK由若干线程组成,而完成一次函数调用的所有BLOCK组成了一个grid.
在使用时,BLOCK和GRID的尺寸都可以用三元向量来表示,这表明BLOCK和GRID都是三维数组,BLOCK的元素是线程,而GRID的数组元素是BLOCK,在当前CUDA的计算能力下,BLOCK和GRID的维数和各维数的尺寸都有限制。
那么执行的线程是如何知道自己在在GRID,BLOCK,THREAD中的位置的呢?一种更简单的方案是让每个线程把自己的X索引(也就是threadIdx.x)记录下来,线程索引是线程在每个BLOCK里的索引,由于BLOCK的尺寸是三维的,因此线程索引也是一个三元常向量,threadIdx,访问方式为:threadIdx.x, threadIdx.y, threadIdx.z.对于一个BLOCK来说,它其中的每个线程的索引是唯一的,但是当一个GRID中有两个以上的BLOCK时,其中就会出现重复的线程索引,相应的,每个GRID里面的BLOCK也有唯一的BLOCK索引,用blockIdx表示,它同样是一个三维常向量,blockIdx.x, blockIdx.y, blockIdx.z。由于一次函数调用中只有一个GRID,因此不存在GRID索引。
对于BLOCK和GRID的尺寸,也用相应的三维常向量来表示,BLOCK的尺寸保存在常向量blockDim中,GRID的尺寸保存在gridDim中,他们都是CUDA C的内建变量,可以直接在设备代码中使用,在计算中,用户常常要给每个线程一个唯一的标识符,即线程号,以便给每个线程分配不同的任务。在多个BLOCK的情况下,线程号也不能重复。线程号在实际使用中很重要,它关系到被处理的数据在输入数组中的位置,也关系到线程的分配和存储器的使用问题。
当BLOCK或者GRID是多维的时候,该如何计算线程号呢?分别说明:
1D grid && 1d block.
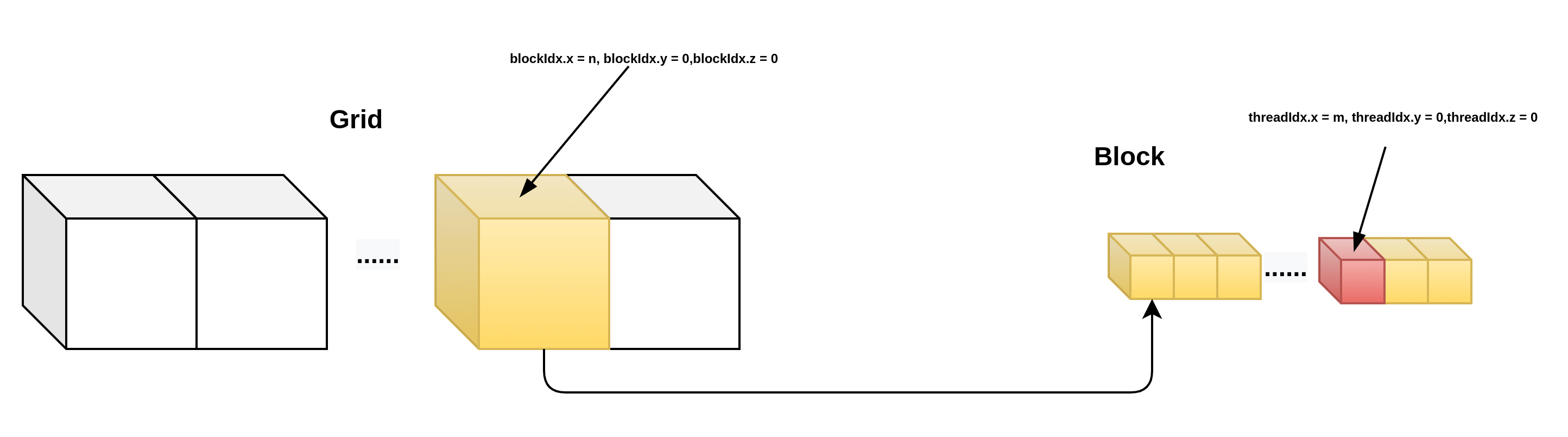
__device__ int get_globalidx_1d_1d(void)
{
return blockIdx.x * blockDim.x + threadIdx.x;
}
1D grid && 2d block.
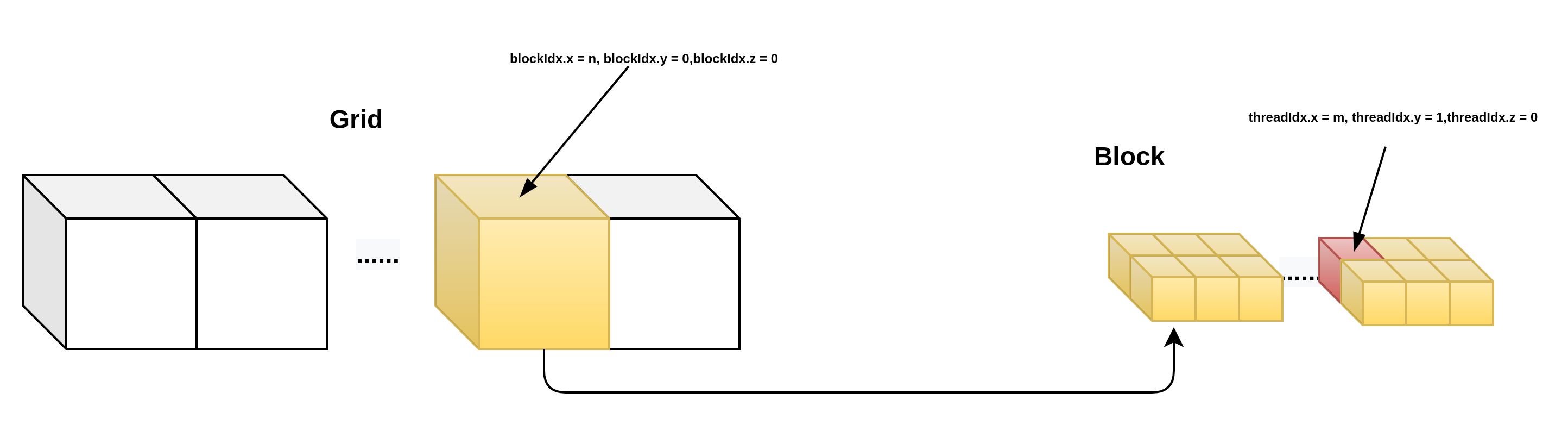
__device__ int get_globalidx_1d_2d(void)
{
return blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
}
1d grid && 3d block
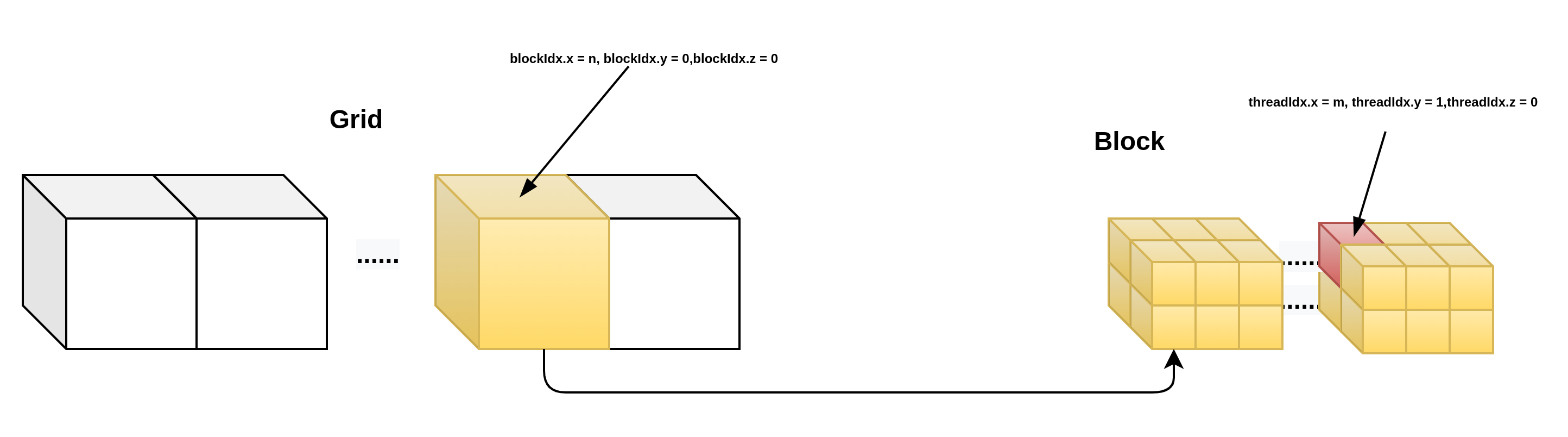
__device__ int get_globalidx_1d_3d(void)
{
return blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x;
}
2d grid && 1d block
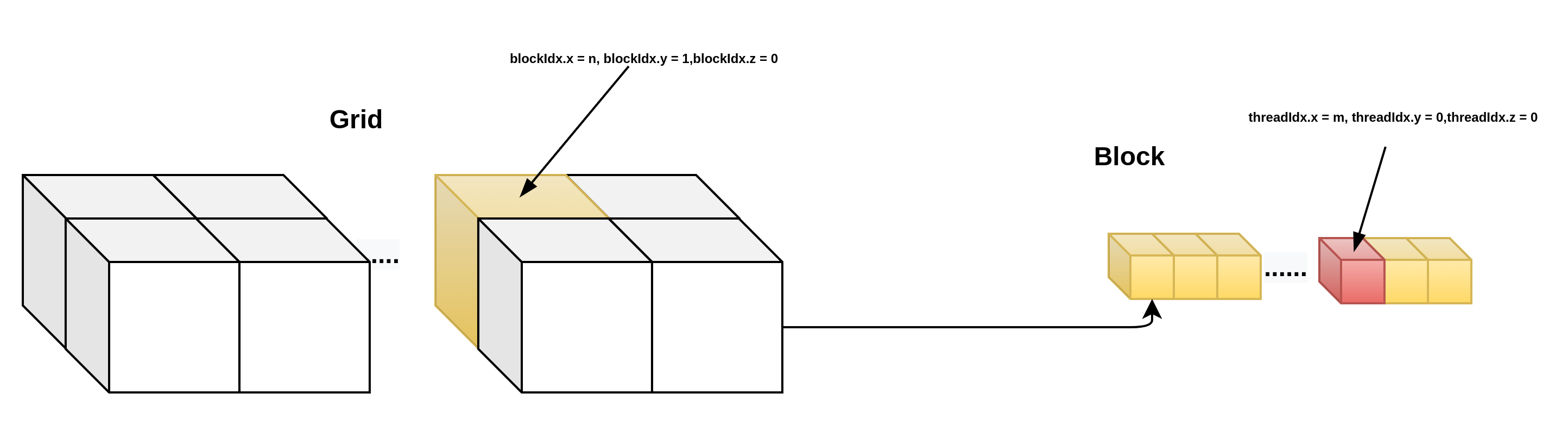
__device__ int get_globalidx_2d_1d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * blockDim.x + threadIdx.x;
return threadid;
}
2d grid && 2d block
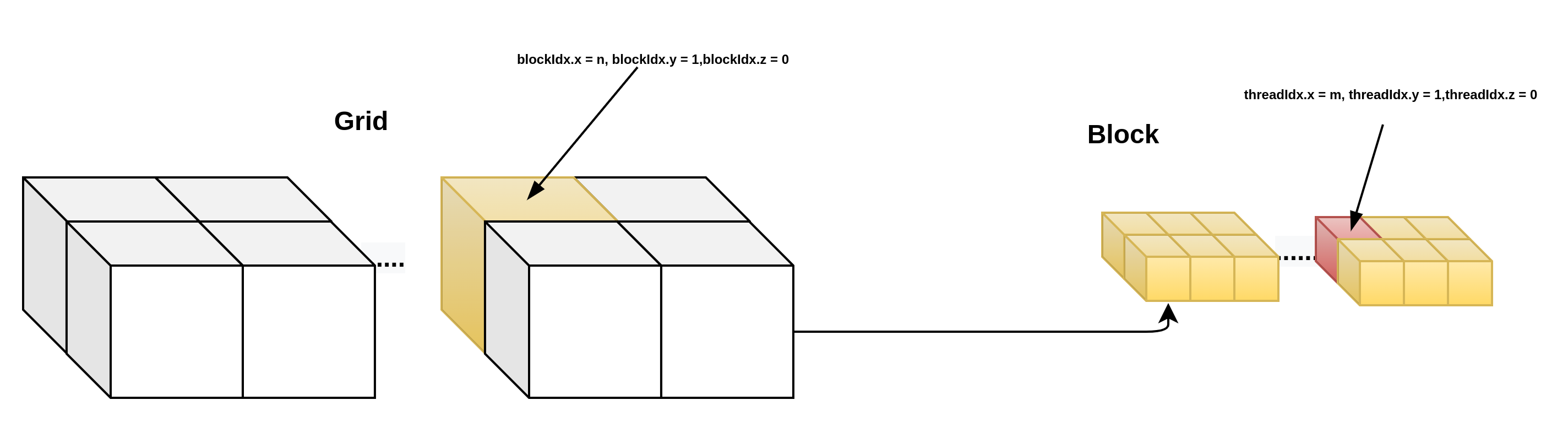
__device__ int get_globalidx_2d_2d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
2d grid && 3d block
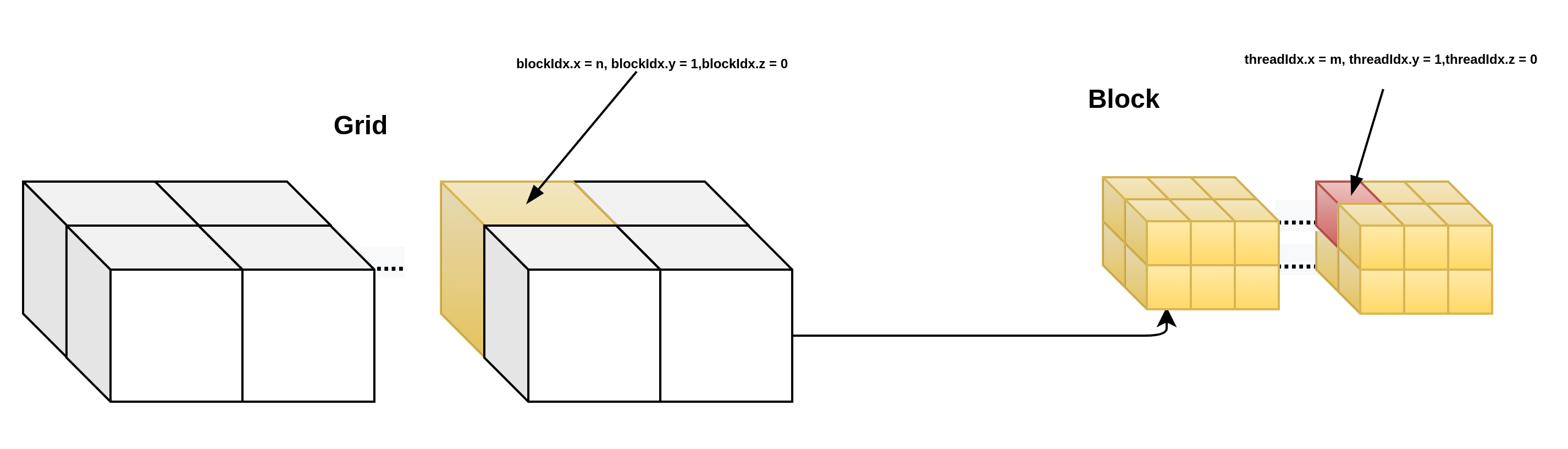
__device__ int get_globalidx_2d_3d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
3d grid && 1d block
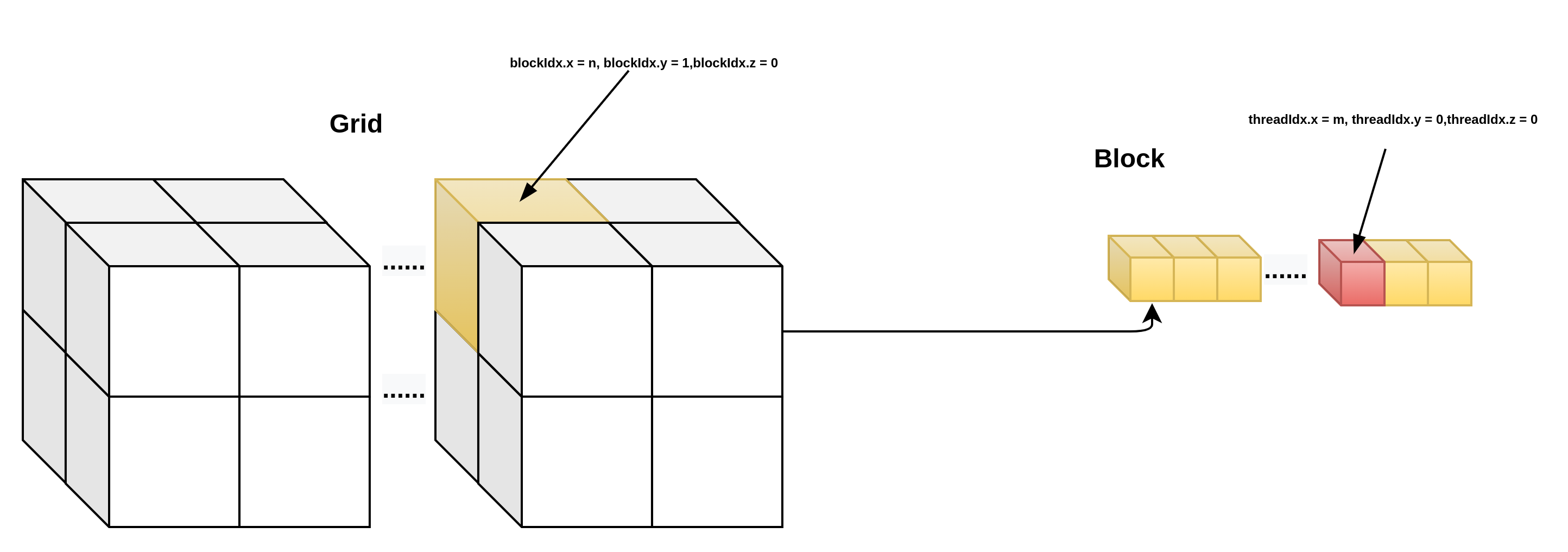
__device__ int get_globalidx_3d_1d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * blockDim.x + threadIdx.x;
return threadid;
}
3d grid && 2d block
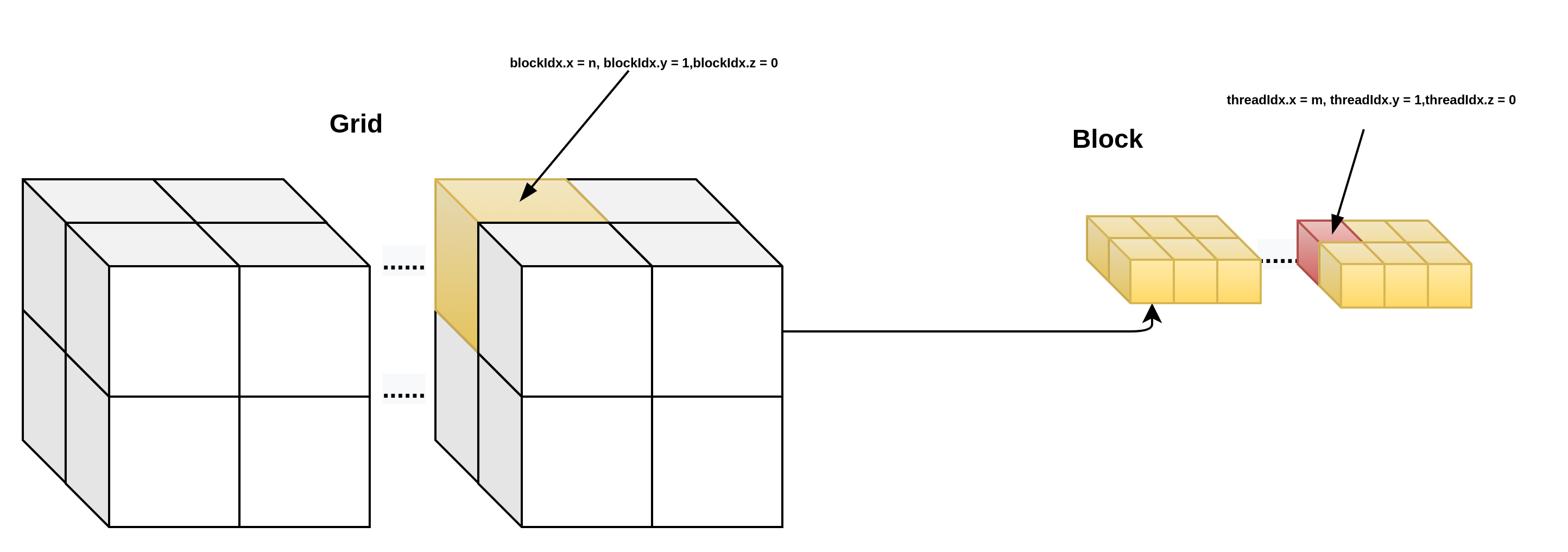
__device__ int get_globalidx_3d_2d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
3d grid && 3d block
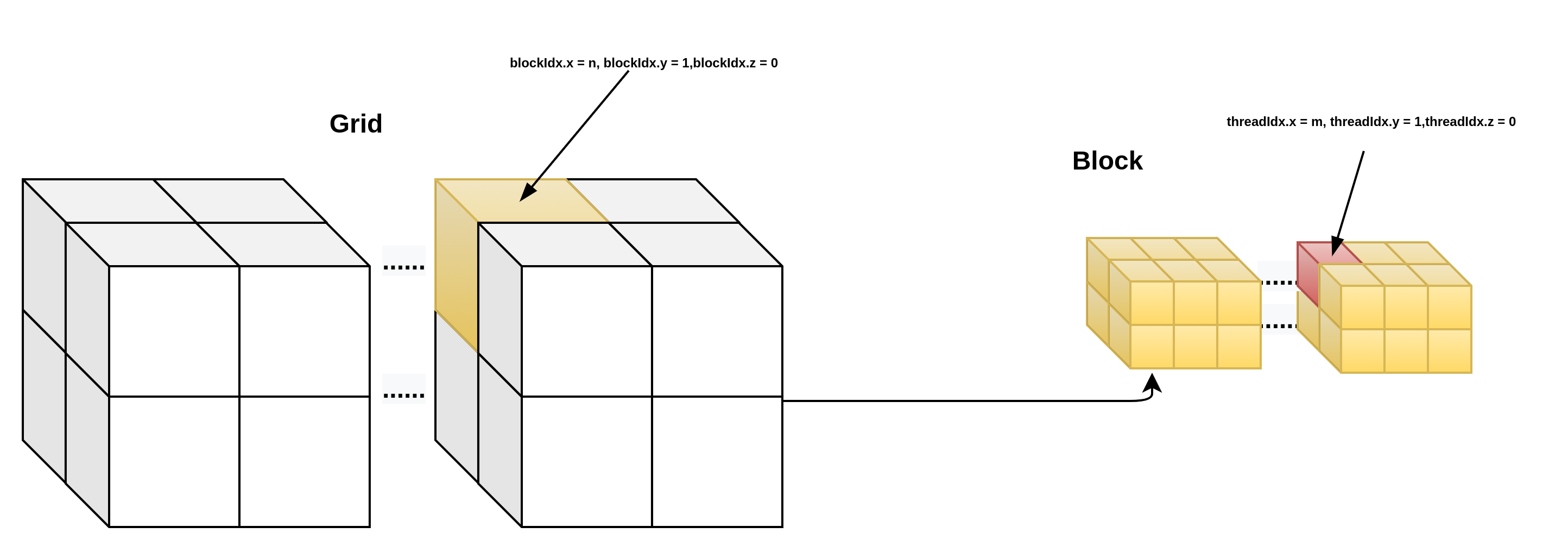
__device__ int get_globalidx_3d_3d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
code:
#include <cuda_runtime.h>
#include <stdio.h>
__device__ void add(int a, int b, int *c)
{
*c = a + b;
printf("kernel %s line %d, i am in kernel thread %d in blockidx.x %d. blokidx.y %d blockidx.z %d *c = %d.\n", __func__, __LINE__, threadIdx.x, blockIdx.x, blockIdx.y,blockIdx.z,*c);
}
__global__ void myfirstkernel(int a, int b, int *c)
{
printf("kernel %s line %d, i am in kernel thread %d in block %d.\n", __func__, __LINE__,threadIdx.x, blockIdx.x);
printf("block.x = %d, block.y = %d,block.z = %d\n", blockDim.x, blockDim.y,blockDim.z);
printf("thread.x = %d, thread.y = %d,thread.z = %d\n", threadIdx.x, threadIdx.y,threadIdx.z);
printf("gridDim.x = %d, gridDim.y = %d,gridDim.z = %d\n", gridDim.x, gridDim.y,gridDim.z);
add(a, b, c);
}
__device__ int get_globalidx_1d_1d(void)
{
return blockIdx.x * blockDim.x + threadIdx.x;
}
__device__ int get_globalidx_1d_2d(void)
{
return blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
}
__device__ int get_globalidx_1d_3d(void)
{
return blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x;
}
__device__ int get_globalidx_2d_1d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * blockDim.x + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_2d_2d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_2d_3d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_3d_1d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * blockDim.x + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_3d_2d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_3d_3d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
__host__ int main(void)
{
int c;
int *gpu_c;
cudaMalloc((void **)&gpu_c, sizeof(int));
myfirstkernel <<<2,3>>>(3, 6, gpu_c);
cudaMemcpy(&c, gpu_c, sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(gpu_c);
cudaDeviceSynchronize();
printf("exit.c = %d.\n", c);
return 0;
}
cuda debug with cuda-gdb
nvcc -g -G hello.cu
--debug (-g)
Generate debug information for host code.
--device-debug (-G)
Generate debug information for device code. If --dopt is not specified, then
turns off all optimizations. Don't use for profiling; use -lineinfo instead.
czl@czl-RedmiBook-14:~/workspace/work$ cuda-gdb a.out
NVIDIA (R) CUDA Debugger
11.7 release
Portions Copyright (C) 2007-2022 NVIDIA Corporation
GNU gdb (GDB) 10.2
Copyright (C) 2021 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-pc-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from a.out...
(cuda-gdb) b myfirstkernel(int, int, int*)
Breakpoint 1 at 0xa3e3: file /home/czl/workspace/work/hello.cu, line 11.
(cuda-gdb) r
Starting program: /home/czl/workspace/work/a.out
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[Detaching after fork from child process 38487]
[New Thread 0x7fffdffff000 (LWP 38492)]
[New Thread 0x7fffdf7fe000 (LWP 38493)]
[New Thread 0x7fffdeffd000 (LWP 38494)]
[Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (0,0,0), device 0, sm 0, warp 0, lane 0]
Thread 1 "a.out" hit Breakpoint 1, myfirstkernel<<<(2,1,1),(3,1,1)>>> (a=3, b=6, c=0x7fffcf000000) at hello.cu:12
12 printf("kernel %s line %d, i am in kernel thread %d in block %d.\n", __func__, __LINE__,threadIdx.x, blockIdx.x);
(cuda-gdb) info cuda threads
BlockIdx ThreadIdx To BlockIdx To ThreadIdx Count Virtual PC Filename Line
Kernel 0
* (0,0,0) (0,0,0) (1,0,0) (2,0,0) 6 0x0000555555a31628 hello.cu 12
(cuda-gdb)
BlockIdx ThreadIdx To BlockIdx To ThreadIdx Count Virtual PC Filename Line
Kernel 0
* (0,0,0) (0,0,0) (1,0,0) (2,0,0) 6 0x0000555555a31628 hello.cu 12
(cuda-gdb)
(cuda-gdb) info threads
Id Target Id Frame
1 Thread 0x7ffff7d7d000 (LWP 38482) "a.out" 0x00007ffff6ce679c in ?? () from /lib/x86_64-linux-gnu/libcuda.so.1
2 Thread 0x7fffdffff000 (LWP 38492) "cuda-EvtHandlr" 0x00007ffff7e98d7f in poll () from /lib/x86_64-linux-gnu/libc.so.6
3 Thread 0x7fffdf7fe000 (LWP 38493) "cuda-EvtHandlr" 0x00007ffff7e98d7f in poll () from /lib/x86_64-linux-gnu/libc.so.6
4 Thread 0x7fffdeffd000 (LWP 38494) "a.out" 0x00007ffff7e11197 in ?? () from /lib/x86_64-linux-gnu/libc.so.6
(cuda-gdb)
Id Target Id Frame
1 Thread 0x7ffff7d7d000 (LWP 38482) "a.out" 0x00007ffff6ce679c in ?? () from /lib/x86_64-linux-gnu/libcuda.so.1
2 Thread 0x7fffdffff000 (LWP 38492) "cuda-EvtHandlr" 0x00007ffff7e98d7f in poll () from /lib/x86_64-linux-gnu/libc.so.6
3 Thread 0x7fffdf7fe000 (LWP 38493) "cuda-EvtHandlr" 0x00007ffff7e98d7f in poll () from /lib/x86_64-linux-gnu/libc.so.6
4 Thread 0x7fffdeffd000 (LWP 38494) "a.out" 0x00007ffff7e11197 in ?? () from /lib/x86_64-linux-gnu/libc.so.6
(cuda-gdb)
(cuda-gdb) info cuda
blocks devices lanes launch trace managed threads
contexts kernels launch children line sms warps
(cuda-gdb) info cuda devices
Dev PCI Bus/Dev ID Name Description SM Type SMs Warps/SM Lanes/Warp Max Regs/Lane Active SMs Mask
* 0 02:00.0 NVIDIA GeForce MX250 GP108-A sm_61 3 64 32 256 0x00000000000000000000000000000003
(cuda-gdb) info cuda devices
Dev PCI Bus/Dev ID Name Description SM Type SMs Warps/SM Lanes/Warp Max Regs/Lane Active SMs Mask
* 0 02:00.0 NVIDIA GeForce MX250 GP108-A sm_61 3 64 32 256 0x00000000000000000000000000000003
(cuda-gdb) info cuda blocks
BlockIdx To BlockIdx Count State
Kernel 0
* (0,0,0) (1,0,0) 2 running
(cuda-gdb) info cuda lanes
Ln State Physical PC ThreadIdx Exception
Device 0 SM 0 Warp 0
* 0 active 0x0000000000000188 (0,0,0) None
1 active 0x0000000000000188 (1,0,0) None
2 active 0x0000000000000188 (2,0,0) None
(cuda-gdb) info cuda threads
BlockIdx ThreadIdx To BlockIdx To ThreadIdx Count Virtual PC Filename Line
Kernel 0
* (0,0,0) (0,0,0) (1,0,0) (2,0,0) 6 0x0000555555a31628 hello.cu 12
(cuda-gdb) info cuda sms
SM Active Warps Mask
Device 0
* 0 0x0000000000000001
1 0x0000000000000001
(cuda-gdb) info cuda kernels
Kernel Parent Dev Grid Status SMs Mask GridDim BlockDim Invocation
* 0 - 0 1 Active 0x00000003 (2,1,1) (3,1,1) myfirstkernel(a=3, b=6, c=0x7fffcf000000)
(cuda-gdb) info cuda contexts
Context Dev State
* 0x0000555555626930 0 active
(cuda-gdb) info cuda managed
Static managed variables on device 0 are:
(cuda-gdb)
analysis a.out with binutils
readelf -S a.out
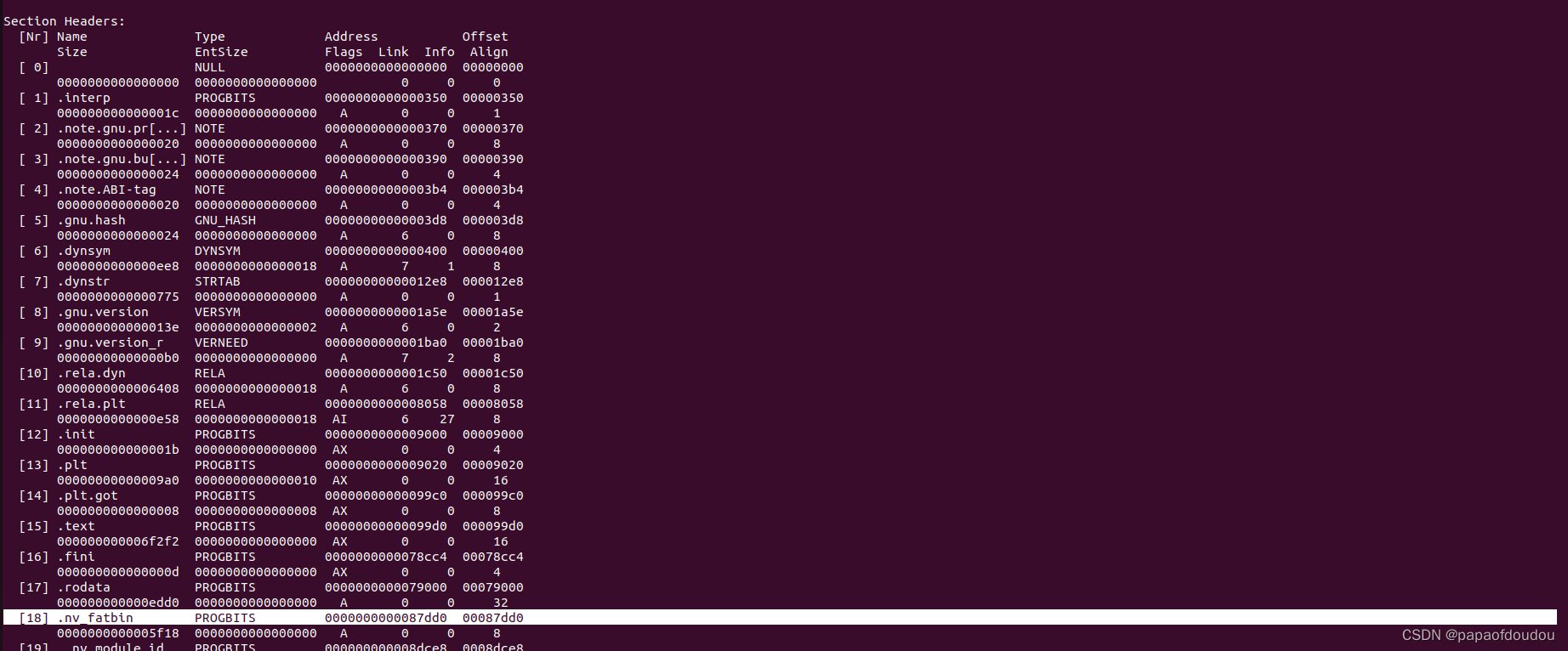
be notice the .nv_fatbin section, this section include all kinds of target device ISA binarys and bundle then together.so that is why it was called fat bin.
objdump -C -d -j .nv_fatbin a.out|more
so you can see it obviously include the HOST Like Device target enclude in the bundle fat bin.
CUDA架构下有许多不同计算能力的架构比如sm_20,sm_30…,使用cuda的nvcc生成的kernel程序二进制文件会有不同计算力的多个版本的.cubin文件,之后,CUDA会把这些.cubin文件打包成一个.fatbin文件,这样的好处是,若最开始设置的GPU架构为sm_60,但是在实际执行时,硬件架构达不到sm_60这个版本,如此,显卡驱动可以从fatbin中选取符合硬件版本的.cubin程序,而不需要再重新编译整个CUDA程序。
czl@czl-RedmiBook-14:~/workspace/work$ readelf -C -s a.out |grep get_globalidx_3d
2973: 000000000000a0fc 29 FUNC GLOBAL DEFAULT 15 get_globalidx_3d[...]
3101: 000000000000a0c2 29 FUNC GLOBAL DEFAULT 15 get_globalidx_3d[...]
3153: 000000000000a0df 29 FUNC GLOBAL DEFAULT 15 get_globalidx_3d[...]
czl@czl-RedmiBook-14:~/workspace/work$
从上图可以看出,即便是device端的代码,编译器也为其产生符号,binutils 工具中使用-C对 C++中的经过改编的名字进行反改编。
did cuda support recuisive function?
the answer is yes.
v#include <cuda_runtime.h>
#include <stdio.h>
__device__ void add(int a, int b, int *c)
{
*c = a + b;
printf("kernel %s line %d, i am in kernel thread %d in blockidx.x %d. blokidx.y %d blockidx.z %d *c = %d.\n", __func__, __LINE__, threadIdx.x, blockIdx.x, blockIdx.y,blockIdx.z,*c);
add(a,b+1,c);
}
__global__ void myfirstkernel(int a, int b, int *c)
{
//printf("kernel %s line %d, i am in kernel thread %d in block %d.\n", __func__, __LINE__,threadIdx.x, blockIdx.x);
//printf("block.x = %d, block.y = %d,block.z = %d\n", blockDim.x, blockDim.y,blockDim.z);
//printf("thread.x = %d, thread.y = %d,thread.z = %d\n", threadIdx.x, threadIdx.y,threadIdx.z);
//printf("gridDim.x = %d, gridDim.y = %d,gridDim.z = %d\n", gridDim.x, gridDim.y,gridDim.z);
add(a, b, c);
}
__device__ int get_globalidx_1d_1d(void)
{
return blockIdx.x * blockDim.x + threadIdx.x;
}
__device__ int get_globalidx_1d_2d(void)
{
return blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
}
__device__ int get_globalidx_1d_3d(void)
{
return blockIdx.x * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.y * blockDim.x + threadIdx.y * blockDim.x + threadIdx.x;
}
__device__ int get_globalidx_2d_1d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * blockDim.x + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_2d_2d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_2d_3d(void)
{
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int threadid = blockid * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_3d_1d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * blockDim.x + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_3d_2d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
__device__ int get_globalidx_3d_3d(void)
{
int blockid = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
int threadid = blockid * (blockDim.x * blockDim.y * blockDim.z) + (threadIdx.z * (blockDim.x * blockDim.y)) + (threadIdx.y * blockDim.x) + threadIdx.x;
return threadid;
}
__host__ int main(void)
{
int c;
int *gpu_c;
cudaMalloc((void **)&gpu_c, sizeof(int));
myfirstkernel <<<2,3>>>(3, 6, gpu_c);
cudaMemcpy(&c, gpu_c, sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(gpu_c);
cudaDeviceSynchronize();
printf("exit.c = %d.\n", c);
return 0;
}

czl@czl-RedmiBook-14:~/workspace/work$ ./a.out
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 9.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 9.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 9.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 9.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 9.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 9.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 10.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 10.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 10.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 10.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 10.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 10.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 11.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 11.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 11.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 11.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 11.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 11.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 12.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 12.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 12.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 12.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 12.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 12.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 13.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 13.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 13.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 13.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 13.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 13.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 14.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 14.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 14.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 14.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 14.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 14.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 15.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 15.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 15.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 15.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 15.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 15.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 16.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 16.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 16.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 16.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 16.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 16.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 17.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 17.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 17.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 17.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 17.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 17.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 18.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 18.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 18.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 18.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 18.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 18.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 19.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 19.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 19.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 19.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 19.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 19.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 20.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 20.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 20.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 20.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 20.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 20.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 21.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 21.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 21.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 21.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 21.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 21.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 22.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 22.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 22.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 22.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 22.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 22.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 23.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 23.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 23.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 23.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 23.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 23.
kernel add line 7, i am in kernel thread 0 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 24.
kernel add line 7, i am in kernel thread 1 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 24.
kernel add line 7, i am in kernel thread 2 in blockidx.x 0. blokidx.y 0 blockidx.z 0 *c = 24.
kernel add line 7, i am in kernel thread 0 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 24.
kernel add line 7, i am in kernel thread 1 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 24.
kernel add line 7, i am in kernel thread 2 in blockidx.x 1. blokidx.y 0 blockidx.z 0 *c = 24.
exit.c = 3.
czl@czl-RedmiBook-14:~/workspace/work$










