一、Hadoop生态圈知识
一)Hadoop生态概况
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。具有可靠、高效、可伸缩的特点。
Hadoop的核心是YARN,HDFS和Mapreduce。
1、常用的模块架构
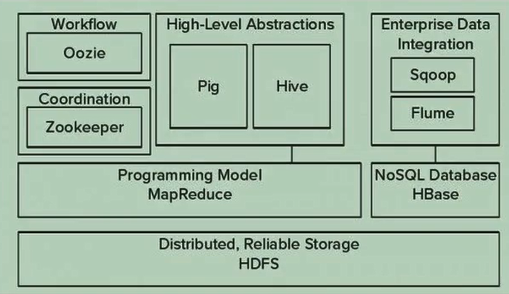
2、Hadoop社区版和发行版的区别
1、社区版的优缺点
优点:
- 完全免费
- 完全开源
- 社区活跃
缺点
- 版本管理较麻烦
- 缺乏部署、运维等工具
- 技术问题无人兜底(什么问题都会遇到)
2、发行版的优缺点
优点
- 版本管理清晰
- 兼容性、稳定性有提升
- 工具丰富
- 可购买技术服务
缺点
- 企业版需要付费
- 部分或全部不开源
- 部分产品无社区生态可言
3、Hadoop的应用场景
- 海量数据存储:各种云盘
- 日志处理:对网站日志做ETL,存入Hive或各种关系型数据库
- 数据分析:hive/impala等可用于离线数据分析、BI,spark和HBase等可用于实时的分析
- 机器学习:用于标签、推荐系统
4、Hadoop不适用的场景
- 少量结构化数据:不超过TB的结构化数据,继续使用单机版数据库,超过TB先考虑使用数据库集群
- 低延迟数据访问:可以考虑HBase,若是K/V型的则选择更多,例如Redis
- 大量小文件:HDFS的文件结构保存在namenode进程的内存中,因此总量是有限制的,一般100w个文件消化300M内存。若小文件超多,还是随机读写,HDFS就非常不合适的,一般有这种需求的公司会有自己研发。(默认的存储文件块是64M,其他存储文件块是几K)
- 实时计算:MapReduce的批处理机制决定了不能实时计算,根据实时性要求的不同,可使用Storm或SparkStreaming
5、为何大数据都要学Hadoop
- 非顶级公司,Hadoop几乎是分布式计算的必选方案
- 即使顶级公司,Hadoop的经验也非常有用
二)HDFS(Hadoop分布式文件系统)
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。
HDFS简化了文件的一致性模型,通过流式数据访问,提高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
它提供了一次写入多次读取的机制,数据以块的形式,同时分布式在集群不同物理机上。
1、HDFS架构示意图
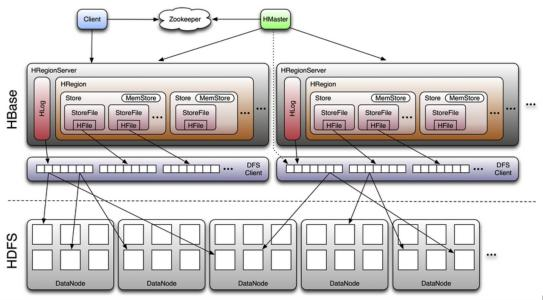
CS架构:分为两部分,NameNode(服务端)和DataNode(客户端)
Client是第三方程序。
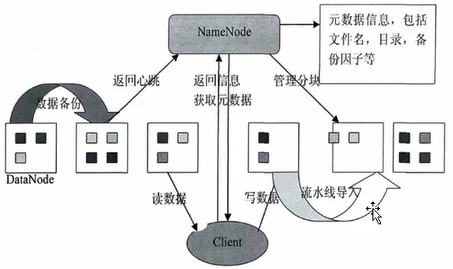
访问数据:Client请求访问NameNode,NameNode返回相应的元数据(告知client数据在哪个DataNode上),client找对应的DataNode读取数据。
NameNode负责数据存储到哪个节点上。
容错机制(数据备份): NameNode将数据存储到某个节点的同时,会根据配置创建对应副本到其他(物理)节点上(可以感知数据在哪个物理节点上)。
2、namenode和datanode角色职责
1、namenode职责
- 接收用户操作请求
- 维护文件系统的目录结构
- 管理文件与block之间关系,block与datanode之间关系
2、datanode职责
- 按照namenode的要求存储文件
- 文件被分成block存储在磁盘上
- 为保证数据安全,文件会有多个副本
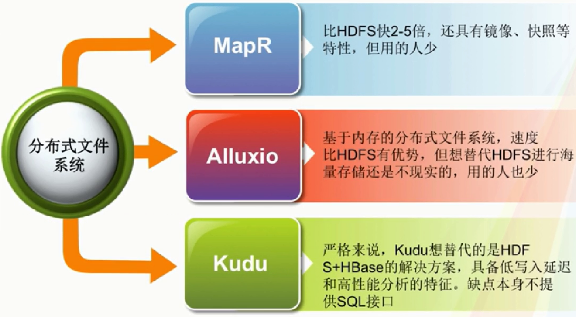
3、替代HDFS的产品
三)MapReduce(分布式计算框架)
1、MapReduce介绍
源自于Google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是Google MapReduce的克隆版。
map和reduce两部分。
map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
MapReduce非常适合大量计算机组成的分布式并行环境里进行数据处理。
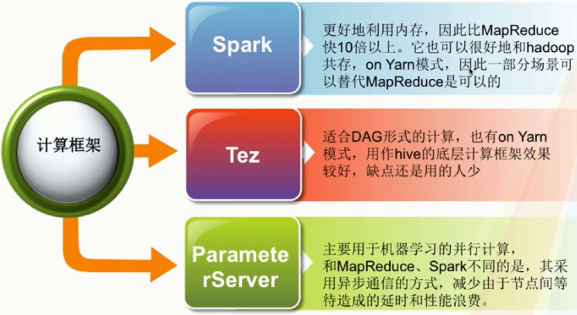
2、替代MapReduce的产品
四)HBASE(分布式列存储数据库)
1、HBase简述
源自于Google的bigtable论文,发表于2006年11月,HBase是Google bigtable的克隆版。
HBase是一个开源的非关系型分布式数据库(NoSQL)。
HBase是一个建立在HDFS之上, 面向列的稀疏排序映射表(Key/value),其中,键由行关键字、列关键字和时间戳构成。
在HBase中,列簇相当于关系型数据库的表。而key-value这样的键值对,相当于数据库里面的一行。
HBase提供了对大规模数据的随机、实时读写访问;同时,HBase中保存的数据可以使用MapReduce来处理,它将数据和并行计算完美结合在一起。
2、HBase的特点
HBase具有高可靠性、高性能、面向列、可伸缩的特点
3、HBase适用于哪些应用
- 海量数据(TB、PB)
- 需要在海量数据中高效的随机读取
- 能同时处理结构化和非结构化数据
- 不需要完全拥有RDBMS的ACID特性
4、HBase架构图
五)zookeeper(分布式协作服务)
1、zookeeper简述
源自于Google的chubby论文,发表于2006年11月,zookeeper是chubby的克隆版。
zookeeper是一个分布式应用程序协调服务。
它解决了分布式环境下数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于zookeeper,它运行在计算集群上面,用于管理Hadoop操作。
2、znode
zookeeper名字空间的每个节点都是以这样一个路径来标识的。这样的节点统一称为znode。
分为以下几类(以下可以组成)
- 持久的/临时的
- 无序的/有序的
3、三种成员
- leader:接收消息,并编号
- follower:同步消息,参与leader选举
- observer:同步消息,但不参与leader选举(提升节点选举效率,可添加observer)
六)HIVE(数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,Hive让部署MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
1、hive架构如下
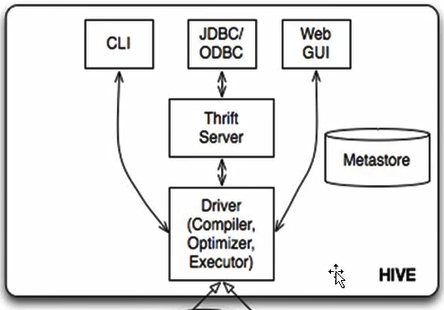
Hadoop和MapReduce是hive架构的根基。
2、hive架构包括的组件
分为两大类:服务端组件和客户端组件
- CLI:(command line interface)
- JDBC/ODBC
- Thtift Server
- WEB GUI
- metastore
- Driver(complier 、optimizer和executor)
七)Pig(ad-hoc脚本)
有Yahoo开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具。
pig定义了一种数据流语言——pig latin,它是MapReduce变成的复杂性的抽象,pig平台包括运行环境和用于Hadoop数据集的脚本语言(pig latin)。
现在几乎让hive去掉)
八)sqoop(数据ETL/同步工具)
sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。数据的导入和导出本质是MapReduce程序,充分利用MR的并行化和容错性。
用在关系数据库、数据仓库和Hadoop之间转移数据。
九)flume(日志收集工具)
flume是cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
产生、传输、处理并最终写入目标路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。(可以直接写到Hadoop中,传输到另外一台服务器中,或本地指定路径)
flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外flume还具有能够将日志写到各种数据目标(可定制)的能力。
总的来说,flume是一个可扩展、适合复杂环境的海量日志收集系统,也可以用于收集其他类型数据。
十)Oozie(工作流调度器)
Oozie是一个基于工作流引擎的服务器,可以在上面运行Hadoop的MapReduce和pig任务。它其实是一个运行在Java Servlet容器(比如tomcat)中的java web应用。
对于Oozie来说,工作流就是一系列的操作(比如Hadoop的MR,以及pig的任务),这些操作通过有向无环图的机制控制。这种控制依赖是,一个操作的输入依赖于前一个任务的输出,只有前一个操作全完完成后,才能开始第二个。
Oozie工作流通过hPDL(hPDL是一种xml的流程定义语言)。工作流操作通过远程系统启动任务,当任务完成后,远程系统会进行回调来通知任务已经结束,然后
再开始下一个操作。
1、Oozie工作流包含控制流节点以及操作节点
控制流节点定义了工作流的开始和借宿(start、end以及fail的节点),宁控制工作流执行路径(decision,fork,join节点)。操作节是工作流触发计算/处理任务的执行,Oozie支持不同的任务类型Hadoop MapReduce,hdfs,pig,ssh,email,Oozie子工作流等等。Oozie可以自动以扩展任务类型。
Oozie工作流可以参数化的方式执行(使用变量${inputDir}定义)。当提交工作流任务时,就需要同时提供参数。若参数合适的话(使用不同的目录)就可以定义并行的工作流任务。
十一)Yarn(分布式资源管理器)
YARN是一代MapReduce,即MRv2。是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性查,不支持多计算框架而提出的。
YARN是下一代Hadoop计算平台,是一个通用的运行框架,用户可以编写自己计算框架,在该运行环境中运行。
用于自己编写的框架作为客户端的一个lib,在运行提交作业时打包即可。
1、YARN包含的组件
- 资源管理:包括应用程序管理和机器资源管理
- 资源双层调度
- 容错性:各个组件均有考虑容错性
- 扩展性:可扩展到上万个节点
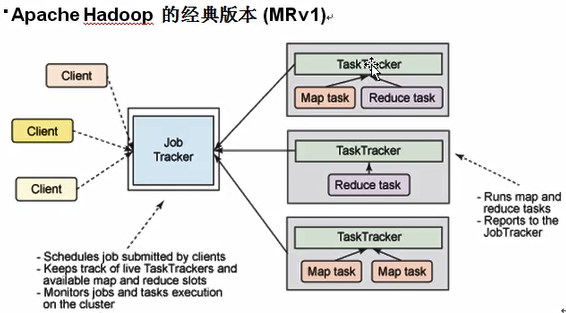
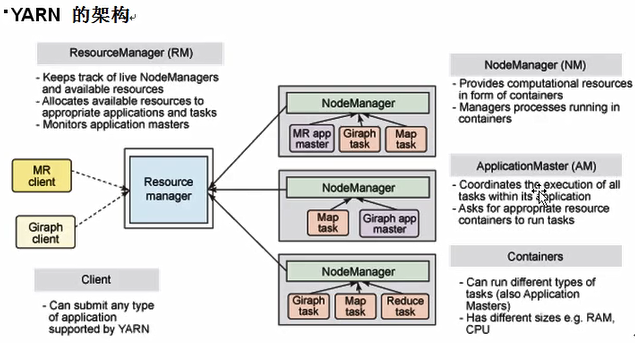
2、MRv1与MRv2架构
十二)spark(内存DAG计算模型)
1、spark简述
spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有了一个繁荣的开源社区,并且是目前最活跃的Apache项目。
spark是分布式批处理系统和分析挖掘引擎。
最早spark是UC berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。
2、spark的功能
- 数据处理:可以用来快速处理数据,兼具容错性和可扩展性
- 迭代计算:支持迭代计算,有效应对多步的数据处理逻辑
- 数据挖掘:在海量数据基础上进行复杂的分析,可支持各种数据挖掘和机器学习算法
3、spark的优势
快,内存计算;资源分配灵活,可基于Yarn或Mesos
spark提供了一个更快的、更通用的数据处理平台。和Hadoop相比,spark可以让你的程序在内训中运行时速度提升100倍,或者在磁盘时速度提高10倍。
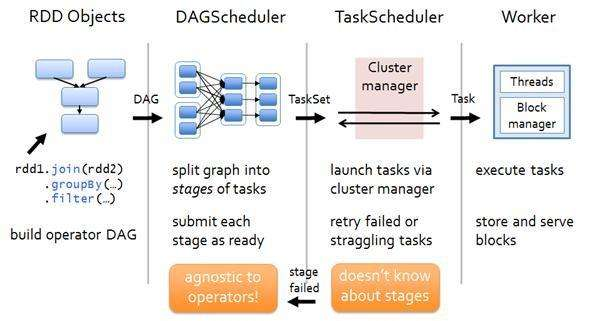
4、spark架构
十三)kafka(分布式消息队列)
kafka是LinkedIn与2010年12月开源的消息队列系统,他主要用于处理活跃的流式数据。
活跃的流式数据在web网站应用中非常常见,这些数据包括:网站的PV,用户访问了什么内容,搜索了什么内容等等。这些动作通常以日志的形式记录下来,然后每个一段时间进行一次统计处理。
十四)storm
1、storm简述
storm是一个开源、分布式、高容错的实时计算系统,弥补了Hadoop批处理所不能满足的实时要求,经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和EIL等领域。
2、storm的关键概念
javascript:void(0)
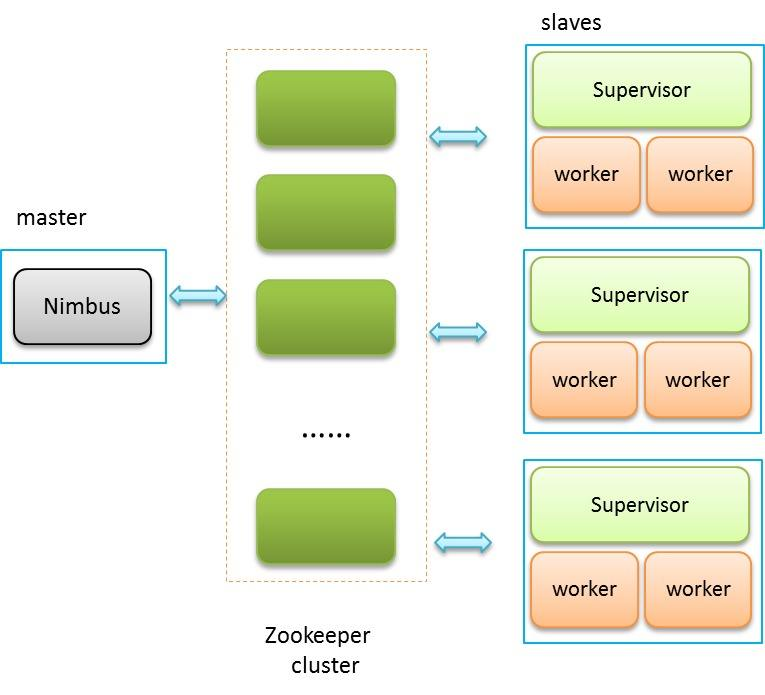
3、storm架构图
十五)Hue
1、Hue简述
Hue(Hadoop user experience)是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,它是基于Python Web框架Django实现的。
2、Hue的功能
- SQL编辑,支持Hive、impala、sparkSQL和各种关系型数据库
- 管理Hadoop和spark任务
- HBase数据的查询和修改
- Sqoop任务的开发和调试
- 管理Oozie的工作流
- 其他功能:浏览HDFS、浏览zookeeper
十六)StreamSets
在streamsets推出前,flume,scribe等少数开源工具是流式采集日志仅有的解决方案,flume的应用案例最多。streamsets是flume的良好替代品
streamsets的源和目标的支持特别丰富,还可以对数据进行不落地处理,因此还可以替代传统ETL软件的一部分功能
1、streamsets的优点
- 功能上,有管理界面,可以单个流启停,统计报表丰富,可以预览数据
- 源端支持,其多出HDFS、JDBC、Redis、ftp等几种重要的源
- 目标端支持,其多出JDBC、Redis、RabbitMQ、Flume等几种重要的目标
- 数据处理上,streamsets有多种字段处理组件,flume仅有过滤功能。有强大的格式处理能力,且支持源端压缩格式,还能使用JavaScript和Python等自定义处理逻辑
2、streamsets的缺点
资源占用率比flume略高,但是因为和flume一样可以分布式部署,问题不大










