Logstash 是一个功能强大的工具,可与各种部署集成。 它提供了大量插件,可帮助你解析,丰富,转换和缓冲来自各种来源的数据;本文主要介绍 Logstash 的基本概念。
1、Logstash 是一个数据流引擎
- 它是用于数据物流的开源流式 ETL(Extract-Transform-Load)引擎
- 在几分钟内建立数据流管道
- 具有水平可扩展及韧性且具有自适应缓冲
- 不可知的数据源
- 具有 200 多个集成和处理器的插件生态系统
- 使用 Elastic Stack 监视和管理部署
2、Logstash 几乎可以摄入各种类别的数据
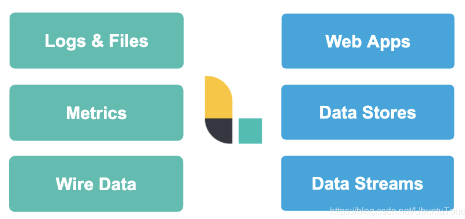
它可以摄入日志,文件,指标或者网路真实数据。经过 Logstash 的处理,变为可以使用的 Web Apps 可以消耗的数据,也可以存储于数据中心,或变为其它的流式数据。
3、Logstash 可接入各种流行的数据源
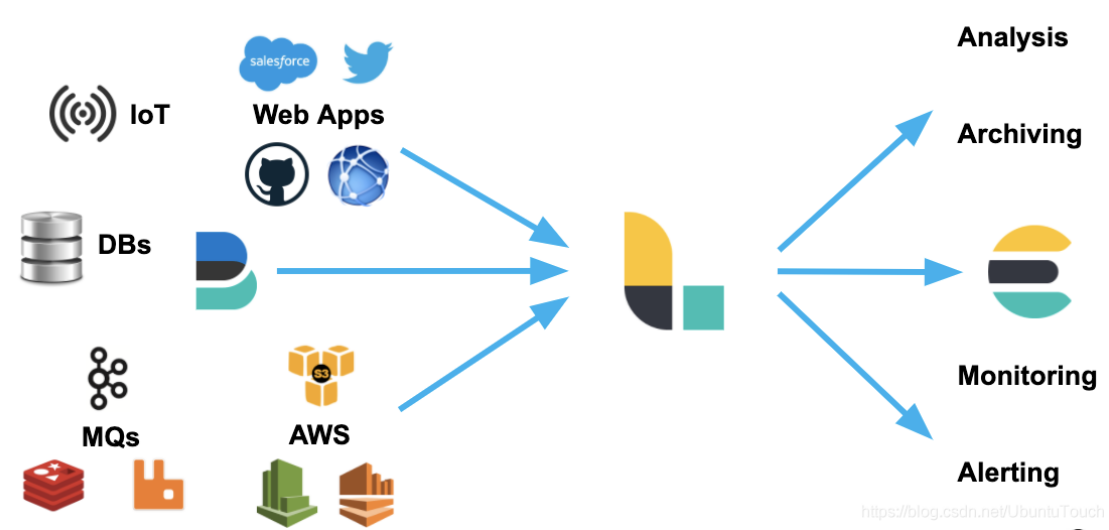
- Logstash 可以很方便地和 Beats一起合作,这也是被推荐的方法
- Logstash 也可以和那些著名的云厂商的服务一起合作处理它们的数据
- 它也可以和最为同样的信息消息队列,比如 redis 或 kafka 一起协作
- Logstash 也可以使用 JDBC 来访问 RDMS 数据
- 它也可以和 IoT 设备一起处理它们的数据
- Logstash 不仅仅可以把数据传送到 Elasticsearch,而且它还可以把数据发送至很多其它的目的地,并作为它们的输入源做进一步的处理
4、Logstash 在 Elastic Stack 中是如何融入的
有如下的 3 种方式能够把数据导入到 Elasticsearch 中:

- Beats:我们可以通过 Beats 把数据导入到 Elasticsearch 中
- Logstash:我们可以 Logstash 把数据导入。Logstash 的数据来源也可以是 Beats
- REST API:我们可以通过 Elastic 所提供的丰富的 API 来把数据导入到 Elasticsearch 中。我们可以通过 Java, Python, Go, Nodejs 等各种 Elasticsearch API 来完成我们的数据导入。
那么针对 Beats 来说,Logstash 是如何和其它的 Elastic Stack 一起工作的?可以看如下的框图:
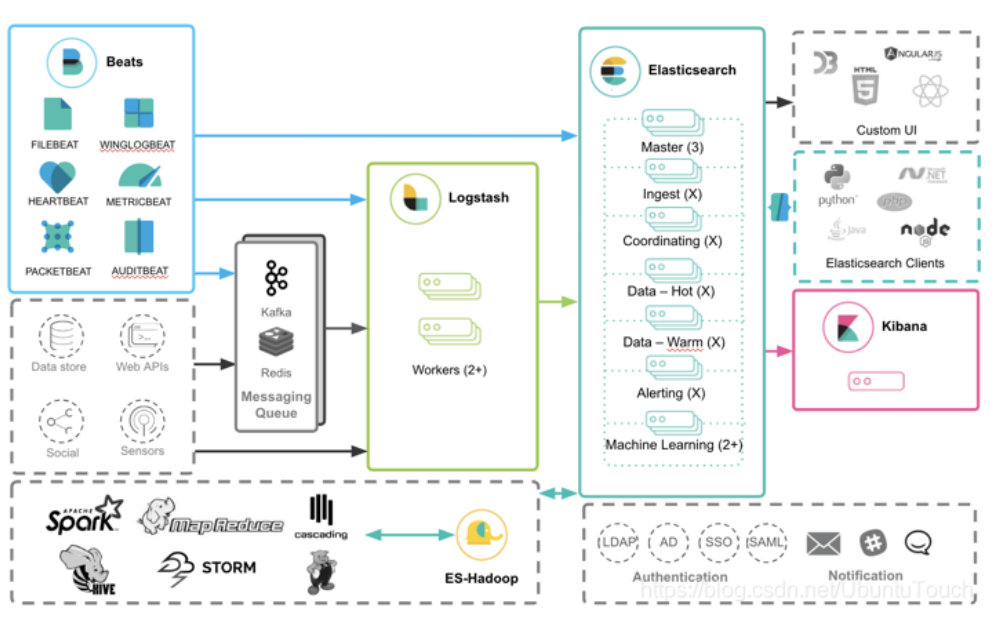
从上面我们可以看出来,Beats 的数据可以有如下的三种方式导入到 Elasticsearch 中:
- Beats ==> Elasticsearch
- Beats ==> Logstash ==> Elasticsearch
- Beats ==> Kafka ==> Logstash ==> Elasticsearch
正如上面所显示的那样:
- 我们可以直接把 Beats 的数据传入到 Elasticsearch 中,甚至在现在的很多情况中,这也是一种比较受欢迎的一种方案。它甚至可以结合 Elasticsearch 所提供的 pipeline 一起完成更为强大的组合。
- 我们可以利用 Logstash 所提供的强大的 filter 组合对数据流进行处理:解析,丰富,转换,删除,添加等等。
- 针对有些情况,如果我们的数据流具有不确定性,比如可能在某个时刻生产大量的数据,从而导致 Logstash 不能及时处理,我们可以通过 Kafka 来做一个缓存。
5、Logstash 是如何工作的
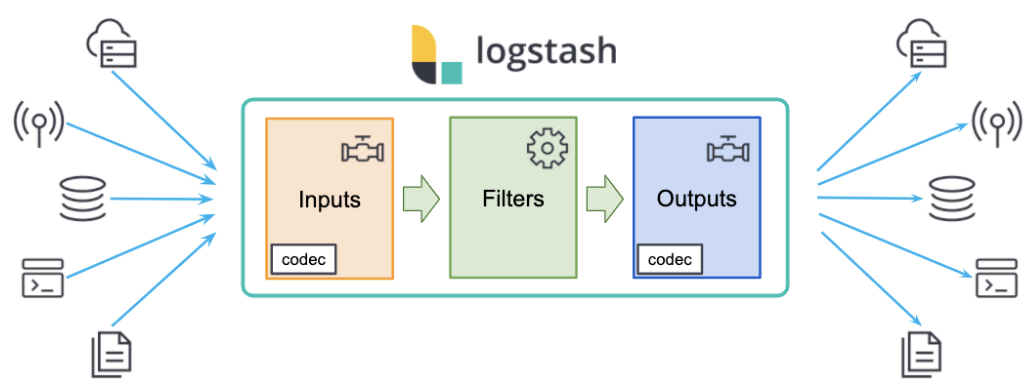
Logstash 旨在作为独立组件运行,以将数据加载到 Elasticsearch(以及其他目标系统)。 Logstash 是一个基于插件的组件,这意味着它可以高度扩展它支持的源/目标系统类型以及它可以进行的转换。Logstash 不是集群组件,无法感知其他 Logstash 实例。 通过跨实例负载平衡数据,可以使用多个 Logstash 实例来满足高可用性和扩展需求。
与 Logstash 相关的概念如下:
- Logstash 实例是一个正在运行的 Logstash 进程。建议在单独主机上运行 Logstash,以确保有足够的计算资源可用。
- 管道(pipeline)是配置为处理给定工作负载的插件集合。一个 Logstash 实例可以运行多个管道(彼此独立)
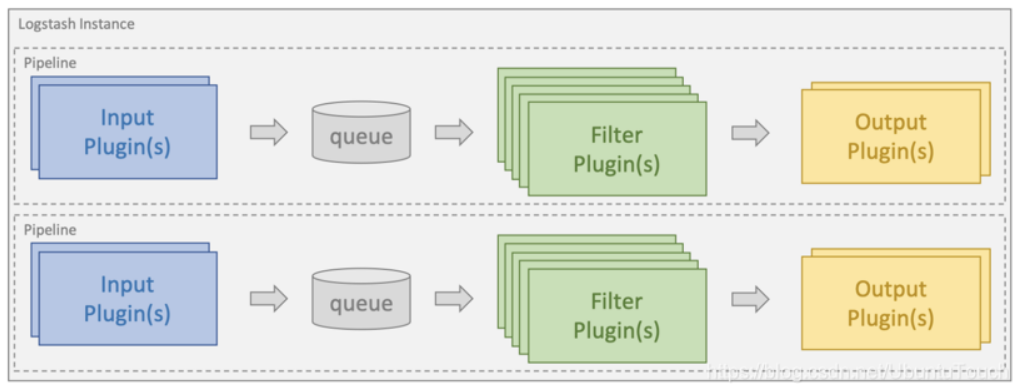
- 输入插件(input plugins)用于从给定的源系统中提取或接收数据。 Logstash 参考指南中提供了支持的输入插件列表:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
- 过滤器插件(filter plugin)用于对传入的数据进行转换和处理。 Logstash 参考指南中提供了支持的过滤器插件列表:https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
- 输出插件(output plugin)用于将数据加载或发送到给定的目标系统。 Logstash 参考指南中提供了支持的输出插件列表:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
Logstash 通过运行一个或多个 Logstash 管道作为 Logstash 实例的一部分来处理 ETL 工作负载。

Logstash 包含3个主要部分: 输入(inputs),过滤器(filters)和输出(outputs)。 你必须定义这些过程的配置才能使用 Logstash,尽管不是每一个都必须的。在有些情况下,我们可以甚至没有过滤器。在过滤器的部分,它可以对数据源的数据进行分析,丰富,处理等等。
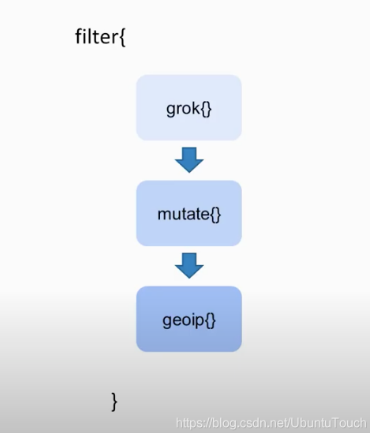
在输出的部分,可以有多于一个以上的输出。
在下面的图中,我们可以看到一些常见的 inputs, filters 及 outputs:
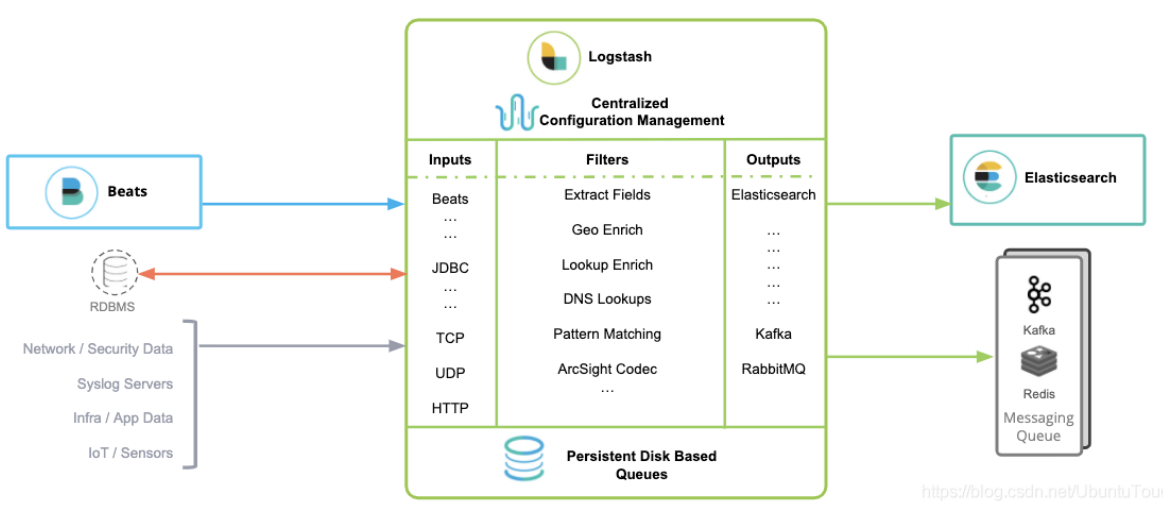
更多关于 Logstash 的 Inputs, Filters 及 Outputs,请访问 Elastic 的官方网站:https://www.elastic.co/guide/en/logstash/current/index.html。
