温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
注意:Fayson的github调整为:https://github.com/fayson/cdhproject,本文的代码在github中也能找到。
1.文档编写目的
在Kafka集群实际应用中,Kafka的消费者有很多种(如:应用程序、Flume、Spark Streaming、Storm等),本篇文章主要讲述如何在Kerberos环境使用Flume采集Kafka数据并写入HDFS。关于Flume更多sink方式实现敬请关注Fayson后续的文章。本文的数据流图如下:
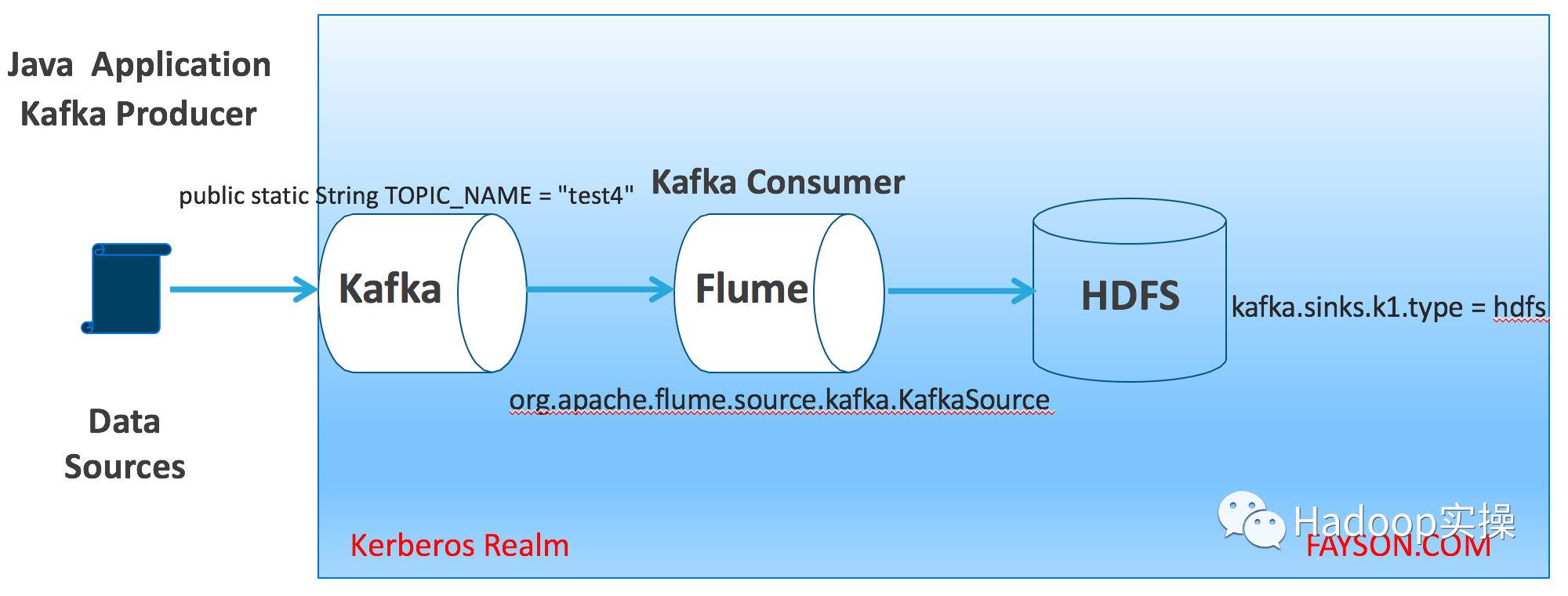
- 内容概述
1.Kafka集群启用Kerberos
2.环境准备及配置Flume Agent
3.java访问并测试
- 测试环境
1.CM和CDH版本为5.11.2
2.采用root用户操作
- 前置条件
1.集群已启用Kerberos
2.集群已安装Kafka
3.集群已安装Flume
2.Kafka集群启用Kerberos
登录Cloudera Manager进入Kafka服务,修改如下配置Kerberos.auth.enable和security.inter.broker.protocol配置为如下截图:
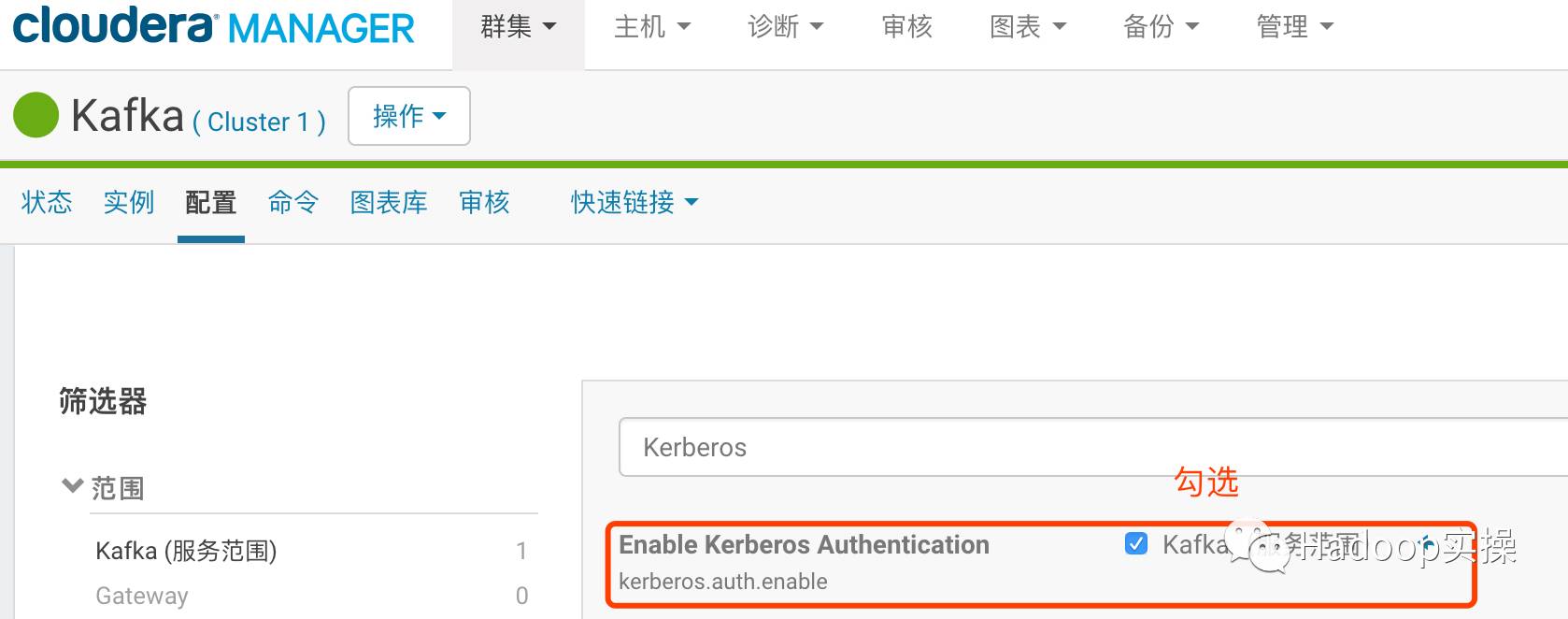
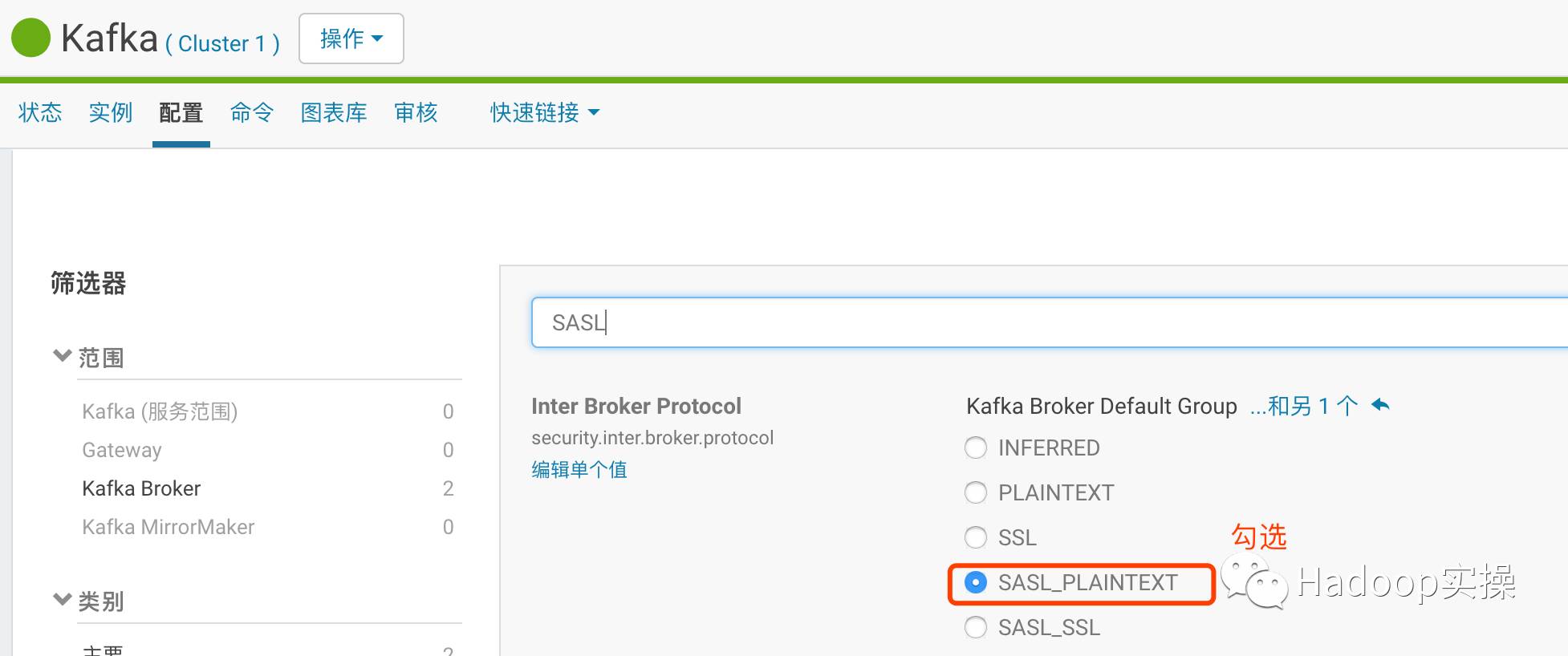
保存配置并重启Kafka服务。
3.环境准备
由于Kafka集群已启用Kerberos认证,这里需要准备访问Kafka集群的环境,如Keytab、jaas.conf配置等
1.生成访问Kafka集群的keytab文件,在Kerberos所在服务上执行如下命令
[root@ip-172-31-22-86 kafkatest]# pwd/home/ec2-user/kafkatest
[root@ip-172-31-22-86 kafkatest]# kadmin.localAuthenticating as principal hdfs/admin@CLOUDERA.COM with password.kadmin.local: xst -norandkey -k fayson.keytab fayson@CLOUDERA.COM
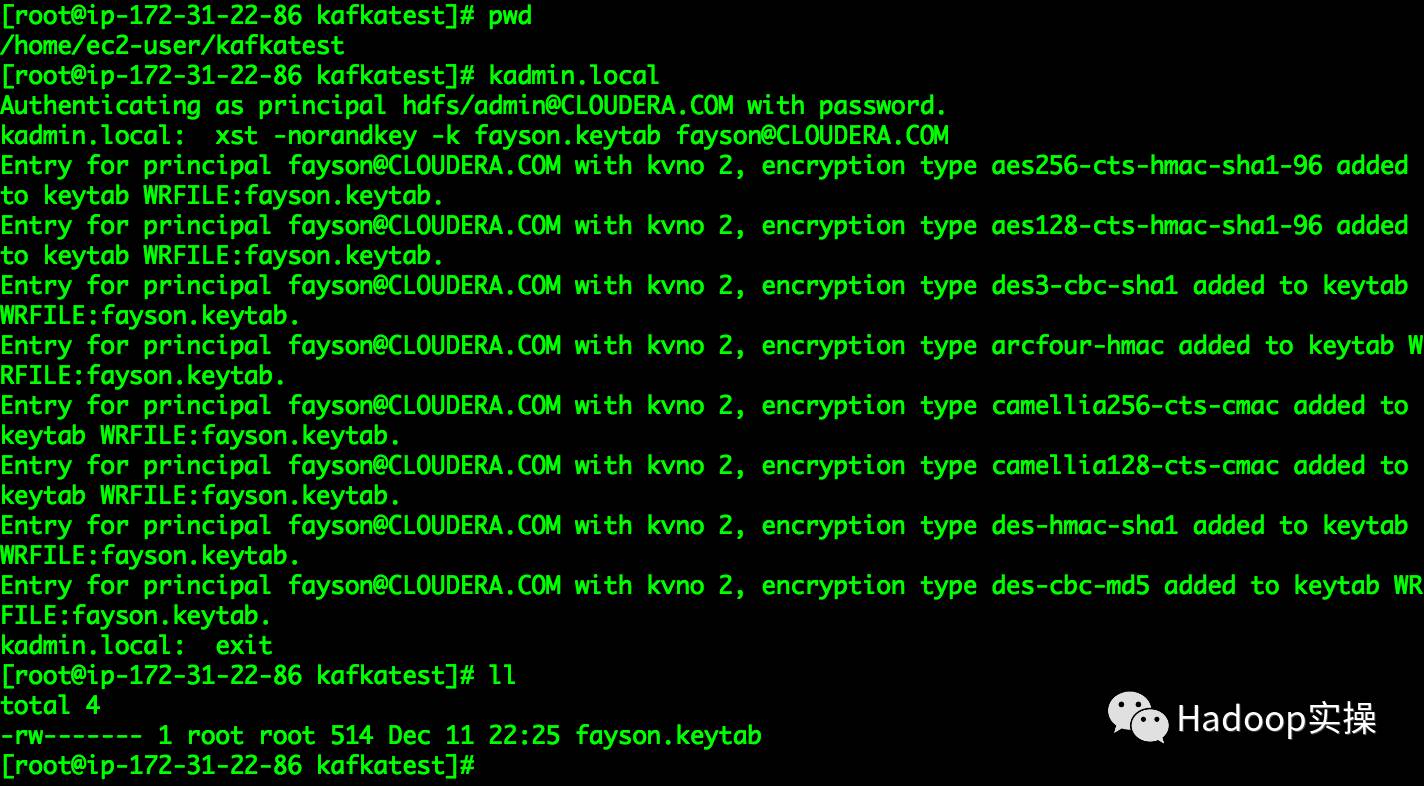
可以看到在当前目录下生成了fayson@CLOUDERA.COM账号的keytab文件。
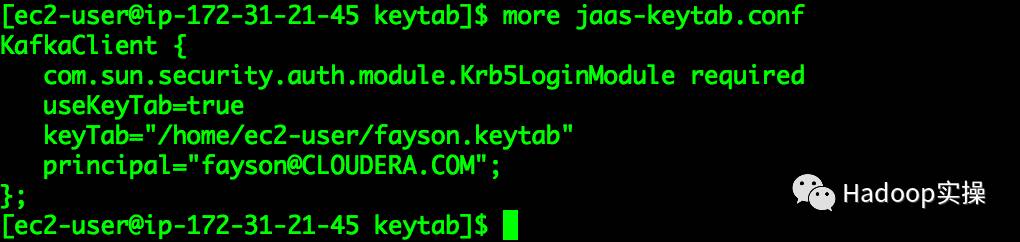
2.创建jaas.conf文件,文件内容如下
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/keytab/fayson.keytab"
principal="fayson@CLOUDERA.COM";
};
3.将keytab文件和jaas.conf文件拷贝至所有Flume Agent运行的节点
这里我们将上面的配置文件拷贝放在Flume Agent节点的/flume-keytab目录下

4.修改目录文件属主,确保flume用户有权限访问
[ec2-user@ip-172-31-21-45 flume-keytab]$ sudo chown -R flume. /flume-keytab/[ec2-user@ip-172-31-21-45 flume-keytab]$ sudo chmod -R 755 /flume-keytab/

4.配置Flume Agent
1.配置Flume Agent读取Kafka数据写入HDFS
kafka.channels = c1kafka.sources = s1kafka.sinks = k1kafka.sources.s1.type =org.apache.flume.source.kafka.KafkaSourcekafka.sources.s1.kafka.bootstrap.servers =ip-172-31-26-80.ap-southeast-1.compute.internal:9092,ip-172-31-21-45.ap-southeast-1.compute.internal:9092, ip-172-31-26-102.ap-southeast-1.compute.internal:9092kafka.sources.s1.kafka.topics = test4kafka.sources.s1.kafka.consumer.group.id =flume-consumerkafka.sources.s1.kafka.consumer.security.protocol= SASL_PLAINTEXTkafka.sources.s1.kafka.consumer.sasl.mechanism= GSSAPIkafka.sources.s1.kafka.consumer.sasl.kerberos.service.name= kafka
kafka.sources.s1.channels = c1kafka.channels.c1.type = memorykafka.sinks.k1.type = hdfskafka.sinks.k1.channel = c1kafka.sinks.k1.hdfs.kerberosKeytab= /flume-keytab/fayson.keytabkafka.sinks.k1.hdfs.kerberosPrincipal= fayson@CLOUDERA.COM
kafka.sinks.k1.hdfs.path =/tmp/kafka-testkafka.sinks.k1.hdfs.filePrefix = events-kafka.sinks.k1.hdfs.writeFormat = Text
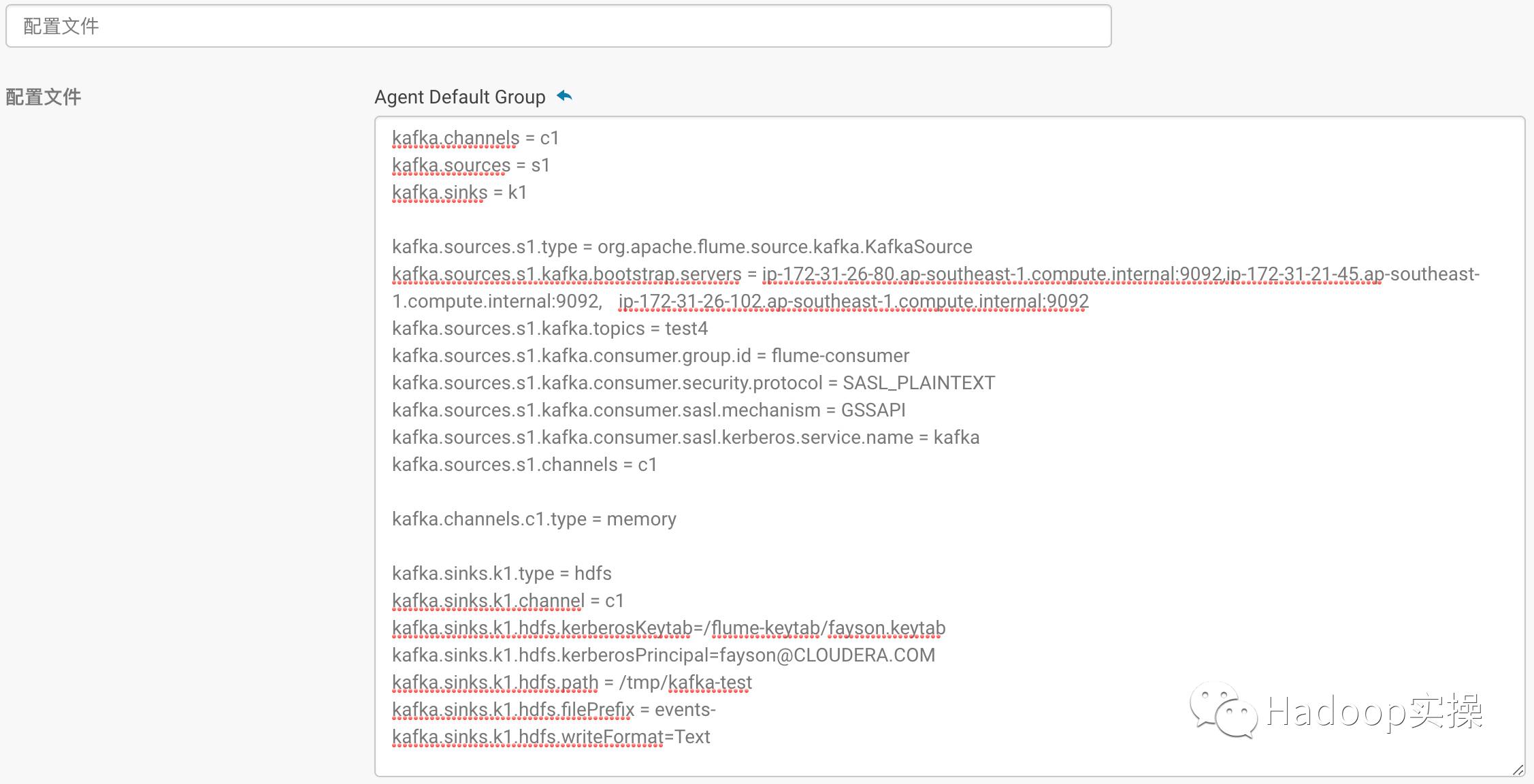
关于HDFS Sink的更多配置可以参考:http://flume.apache.org/FlumeUserGuide.html#hdfs-sink
2.增加Flume Agent启动参数
-Djava.security.auth.login.config=/flume-keytab/jaas.conf
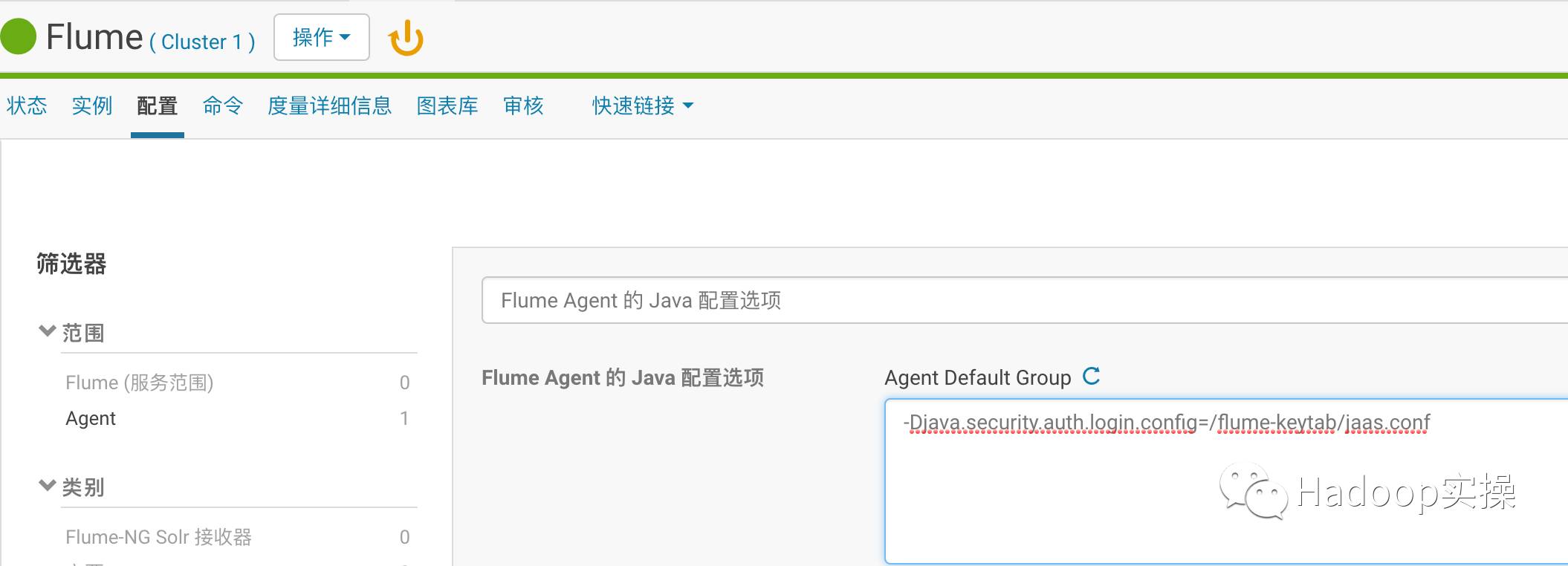
配置完成后保存更改并重启FlumeAgent服务。
5.Java生产消息
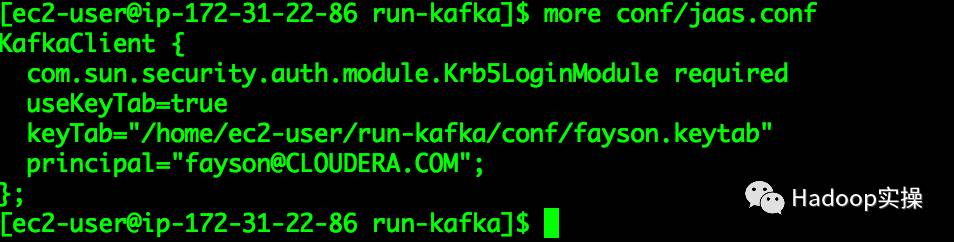
1.编写jaas.conf文件
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/ec2-user/run-kafka/conf/fayson.keytab"
principal="fayson@CLOUDERA.COM";
};
2.使用Java编写消息生产代码
package com.cloudera;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.Producer;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.clients.producer.ProducerRecord;import java.io.File;import java.util.Properties;/**
* package: com.cloudera
* describe: TODO
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2017/12/12
* creat_time: 下午3:35
* 公众号:Hadoop实操 */public class ProducerTest {
public static String TOPIC_NAME = "test4";
public static String confPath = System.getProperty("user.dir") + File.separator + "conf";
public static void main(String[] args) {
try {
String krb5conf = confPath + File.separator + "krb5.conf";
String jaasconf = confPath + File.separator + "jaas.conf";
System.setProperty("java.security.krb5.conf", krb5conf);
System.setProperty("java.security.auth.login.config", jaasconf);
System.setProperty("javax.security.auth.useSubjectCredsOnly", "false");// System.setProperty("sun.security.krb5.debug", "true"); //Kerberos Debug模式 Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip-172-31-21-45.ap-southeast-1.compute.internal:9092,ip-172-31-26-102.ap-southeast-1.compute.internal:9020,ip-172-31-26-80.ap-southeast-1.compute.internal:9020");
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put("security.protocol", "SASL_PLAINTEXT");
props.put("sasl.kerberos.service.name", "kafka");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 10; i++) {
String message = i + "\t" + "fayson" + i + "\t" + 22+i;
ProducerRecord record = new ProducerRecord<String, String>(TOPIC_NAME, message);
producer.send(record);
System.out.println(message);
}
producer.flush();
producer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.将工程编译打包kafka-demo-1.0-SNAPSHOT.jar
mvn clean package
4.使用mvn命令将工程依赖库导出
mvn dependency:copy-dependencies -DoutputDirectory=/Users/fayson/Desktop/lib
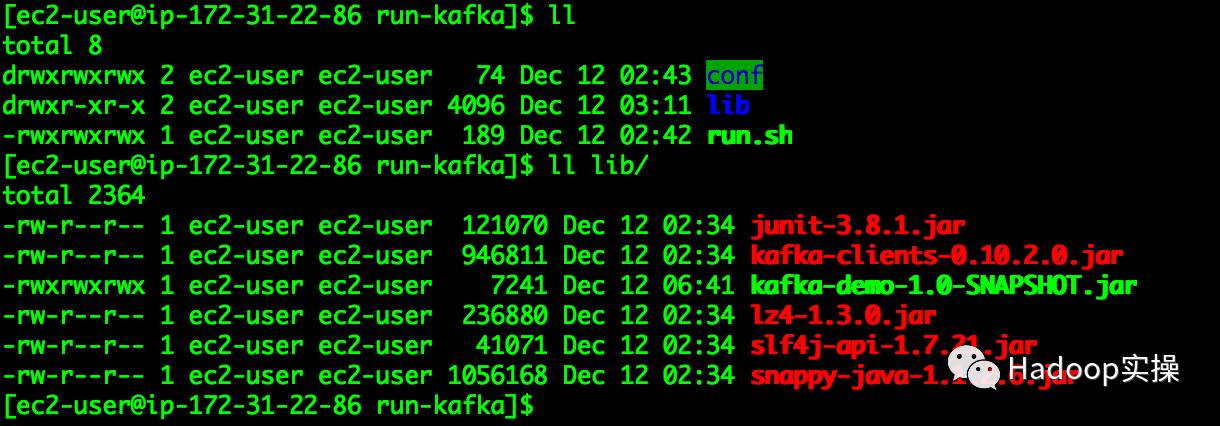
将导出的jar包放在run-kafka/lib目录下。
5.编写run.sh脚本,运行测试jar包
#!/bin/bash
JAVA_HOME=/usr/java/jdk1.8.0_131-clouderafor file in `ls lib/*jar`do
CLASSPATH=$CLASSPATH:$filedoneexport CLASSPATH${JAVA_HOME}/bin/java com.cloudera.ProducerTest
6.conf目录文件

fayson.keytab:fayson的keytab文件
jaas.conf:java访问Kerberos环境下的配置
krb5.conf:集群的krb5配置文件
6.Kafka->Flume->HDFS流程测试
1.将第5章开发好的示例放在集群的服务器上
2.执行run.sh
[ec2-user@ip-172-31-22-86 run-kafka]$ sh run.sh
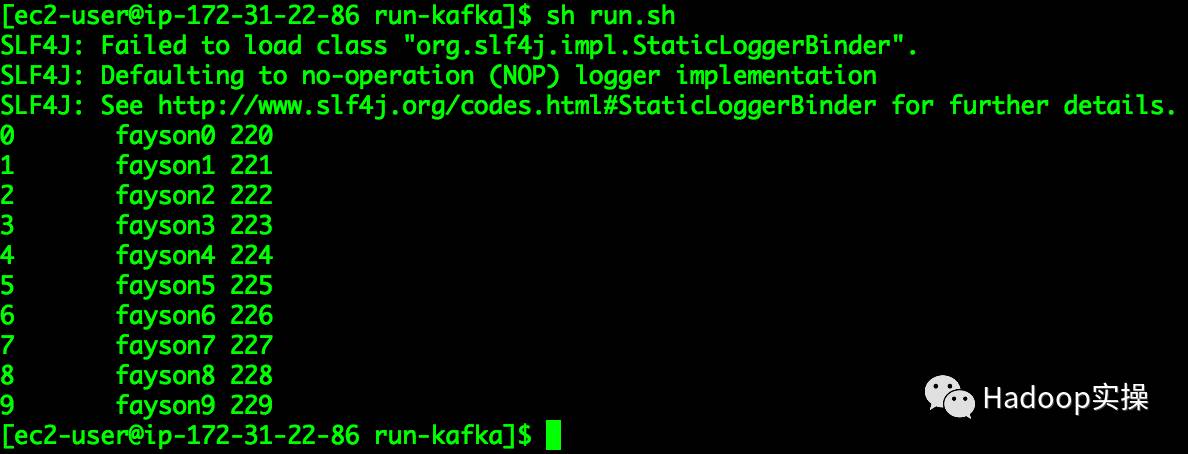
3.查看HDFS的/extwarehouse/student目录下数据
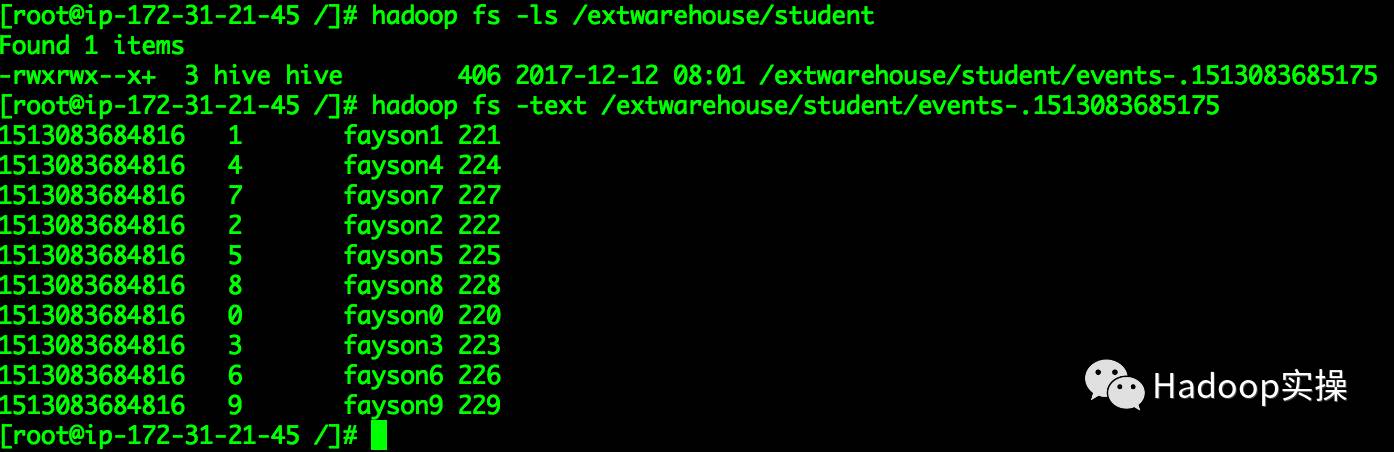
这里可以看到数据已写入HDFS指定的目录。
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。

原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操









