
目录
1.贡献
这项工作的目标是建立一个可扩展的pipeline,使用零手动注释将目标检测器扩展到新的类别。为了实现这一点,做出了以下四个贡献:
- 为了实现泛化,我们提出了一个两阶段的开放词汇表对象检测器,其中类不可知的对象proposal区域通过预先训练的视觉-语言模型中的文本编码器进行分类;
- 为了将视觉潜在空间(RPN box proposal)与预先训练的文本编码器的视觉潜在空间配对,我们提出了区域提示学习(regional prompt)的思想,以使文本嵌入空间与regional visual object特征对齐;
- 为了扩大学习过程,以检测更广泛的对象,我们通过一个新的自训练框架来利用可用的在线资源,该框架允许在大量未经处理的网络图像上训练我们提出的检测器。
- 最后,为了评估我们提出的检测器PromptDet,我们对具有挑战性的LVIS和MS-COCO数据集进行了广泛的实验。
PromptDet的性能优于现有方法,并且只需较少的额外训练图像和零手动注释。

- 图1:提出的PromptDet是一个框架,用于扩展目标检测器中的词汇表,并且无需人工注释。该图描述了模型在LVIS验证集上生成的检测示例,蓝色和绿色框分别表示基本类别和新类别的目标对象。尽管没有为新类别提供GroundTruth,PromptDet仍然能够以高精度可靠地定位和识别这些目标。
相关工作:Zero-shot learning
Zero-shot learning旨在将已经学到的知识从看得见的目标类别迁移到新的类别。在目标检测领域,早期的工作利用视觉属性:比如类别的层次结构,类别的相似度,目标对象的局部part,从而将看得见的类别泛化到看不见的类别;其他研究方向学习将视觉样本和语义描述符映射到联合嵌入空间,并计算嵌入空间中图像和文本之间的相似性。
个人对zero-shot learning的理解
我认为分类任务的尽头其实是:类别的名称只是一个描述,我们要学会区分新类别和过去见过的类别,同时要能区分新类别中的各个不同的类别。zero-shot learning应当属于分类任务的最终目的。
设想第一个发现秃鹰(Bald eagle)的研究者,他可以简单地给这个物种命名Bald eagle,这群秃鹰的特征是相似的:翼展6-7英尺,深褐色或白色的尾巴,白色的头,明亮的黄色眼睛。尽管研究者事先并不知道什么是“秃鹰”,但是他能确定这是与以前发现的物种不同的动物。
一般来说,目前zero-shot learning 方法会遵循三种学习范式之一:
- 从属性中学习。一个类别可以伴随一个结构化的描述,例如,“白色的头“和“黄色的嘴“描述一个秃鹰。这允许算法将输入分解为描述类的元素,即使它没有看到该类的任何显式示例;
- 从文字描述中学习。一个类别可以附带一个文本的自然语言描述,就像一本词典或者一个百科全书的单词入口。这允许模型在仅给定类别描述的情况下解释输入并将其映射到类别。
- 独立学习。类别被嵌入到一个连续的空间中,zero-shot 分类器可以区分embedding的位置以确定输出。由于不需要每个类别显式的属性或文本描述,这种方法更符合 zero-shot learning 的目标,但是可能表现得比较差。
2.方法
在本文中,我们的目标是扩展标准的 2 stage 目标检测器的词汇表,以最少的手动操作定位和识别新类别对象。本节的组织方式如下,我们首先介绍构建开放词汇表检测器的基本模块,该检测器可以检测封闭集合之外的任意类别的对象;在第2.2节中,我们通过继承CLIP的文本编码器作为分类器生成器,描述了将视觉主干与冻结语言模型配对的基本思想;在第2.3节中,为了鼓励以目标对象为中心的视觉表示和文本表示之间的一致性,我们引入了区域提示学习(RPL,regional prompt learning);在第2.4节中,我们介绍了一种迭代学习方案,它可以有效地利用未经处理的web图像,寻找新类别的高质量候选图像。因此,我们提出的开放词汇检测器,称为PromptDet,可以用可扩展的方式对这些候选图像进行自训练。
2.1.Open Vocabulary Object Detector
假设我们有一个目标检测数据集 D t r a i n D_{train} Dtrain,包含一组基本类别的注释 C t r a i n = C b a s e C_{train}=C_{base} Ctrain=Cbase,比如 D t r a i n = { ( I 1 , y 1 ) , . . . , ( I n , y n ) } D_{train}=\left\{(I_{1},y_{1}),...,(I_{n},y_{n})\right\} Dtrain={(I1,y1),...,(In,yn)},其中 I i ∈ R H × W × 3 I_{i}\in R^{H\times W\times 3} Ii∈RH×W×3指第 i i i张图像, y i = { ( b i , c i ) } m y_{i}=\left\{(b_{i},c_{i})\right\}^{m} yi={(bi,ci)}m表示坐标 b i k ∈ R 4 b_{i}^{k}\in R^{4} bik∈R4和类别 c i k ∈ R C b a s e c_{i}^{k}\in R^{C_{base}} cik∈RCbase(该图像中一共 m m m个对象)。我们要训练能够在测试集 D t e s t D_{test} Dtest上成功运行的目标检测器,测试集上的对象类别超出了 C b a s e C_{base} Cbase,测试集的对象类别为 C t e s t = C b a s e ∪ C n o v e l C_{test}=C_{base}\cup C_{novel} Ctest=Cbase∪Cnovel,因此被称为开放词汇检测器。特别是,我们在LIVS数据集上进行了实验,并将常见类作为基本类别,将罕见类作为新类别。
一般来说,流行的 2 stage 目标检测器,例如MaskRCNN,由视觉主干编码器、区域建议网络(RPN)和分类模块组成: { y ^ 1 , . . . , y ^ n } = Φ C L S ∘ Φ R P N ∘ Φ E N C ( I ) \left\{\widehat{y}_{1},...,\widehat{y}_{n}\right\}=\Phi_{CLS}\circ\Phi_{RPN}\circ\Phi_{ENC}(I) {y 1,...,y n}=ΦCLS∘ΦRPN∘ΦENC(I)因此,构建开放词汇表检测器需要解决以下两个后续问题:
- 有效生成类别无关的 regional proposal;
- 在视觉类别的闭集之外,准确对proposal的区域进行分类;
类别无关的RPN Φ R P N \Phi_{RPN} ΦRPN:指的是proposal出可能有对象的所有区域的能力,不管其类别是什么。在这里,我们将anchor分类,bounding box回归,mask预测用类别无关的方式参数化,比如对所有类别都共享参数。
开放词汇表分类
Φ
C
L
S
\Phi_{CLS}
ΦCLS:目的是对视觉对象进行分类,使其超出固定大小的词汇表。我们假设,视觉和自然语言之间存在一个共同的潜在空间,因此可以通过寻找视觉对象在语言潜在空间中的最接近嵌入来对其进行分类,例如,将一个区域划分为“杏仁almond”或“狗dog”,可以计算出“杏仁almond“的分类概率:
c
a
l
m
o
n
d
=
ϕ
t
e
x
t
(
g
(
"
t
h
i
s
−
i
s
−
a
−
p
h
o
t
o
−
o
f
−
[
a
l
m
o
n
d
]
"
)
)
c_{almond}=\phi_{text}(g("this-is-a-photo-of-[almond]"))
calmond=ϕtext(g("this−is−a−photo−of−[almond]"))
c
d
o
g
=
ϕ
t
e
x
t
(
g
(
"
t
h
i
s
−
i
s
−
a
−
p
h
o
t
o
−
o
f
−
[
d
o
g
]
"
)
)
c_{dog}=\phi_{text}(g("this-is-a-photo-of-[dog]"))
cdog=ϕtext(g("this−is−a−photo−of−[dog]"))
p
a
l
m
o
n
d
=
e
x
p
(
<
v
,
c
a
l
m
o
n
d
>
/
t
)
e
x
p
(
<
v
,
c
a
l
m
o
n
d
>
/
t
)
+
e
x
p
(
<
v
,
c
d
o
g
>
/
t
)
p_{almond}=\frac{exp(<v,c_{almond}>/t)}{exp(<v,c_{almond}>/t)+exp(<v,c_{dog}>/t)}
palmond=exp(<v,calmond>/t)+exp(<v,cdog>/t)exp(<v,calmond>/t)其中,
v
∈
R
D
v\in R^{D}
v∈RD表示region proposal的ROI pooled features,
g
(
⋅
)
g(\cdot)
g(⋅)表示tokenisation程序,没有可学习参数,
ϕ
t
e
x
t
(
⋅
)
\phi_{text}(\cdot)
ϕtext(⋅)表示将自然语言映射到embedding的网络,输入文本通常需要带有手动提示的模板,比如"this is a photo of [category]",prompt范式将分类任务转换为与训练前使用的格式相同的格式。
t
t
t是温度参数,
<
a
,
b
>
<a,b>
<a,b>表示计算向量相似度。通过优化分类损失来训练视觉主干,将相应类别的region视觉嵌入和文本嵌入配对。
讨论:定义开放词汇检测器很简单,但由于缺乏针对大规模数据集的详尽注释,训练此类模型将面临巨大挑战。 直到最近,大规模的视觉语言模型,如 CLIP 和 ALIGN,已经被训练来对齐视觉和语言之间的潜在空间。这些视觉语言模型受益于文本描述中的丰富信息,例如动作、物体、人与物体的交互和物体与物体之间的关系,在各种图像分类任务中表现出显著的“zero-shot”泛化,这为扩大物体检测器的词汇量提供了机会。
2.2.通过Detector Training实现对齐
在本节中,我们旨在用
D
t
r
a
i
n
D_{train}
Dtrain(仅包括base categories)训练一个开放词汇目标检测器(基于Mask-RCNN),仅使用基本类别优化视觉主干和类别无关的RPN,与继承自CLIP的预训练文本编码器的分类器对齐。见图2左侧。
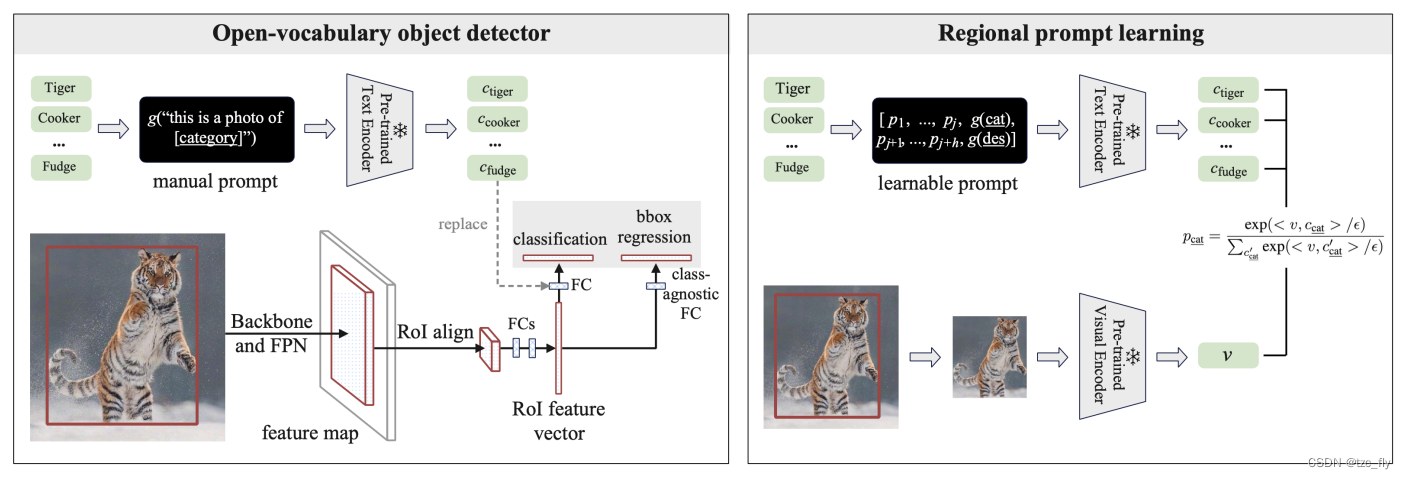
- 图2:Left是提出的开放词汇检测器,将开放类别嵌入作为开放词汇表分类器的输出,训练视觉主干和CLIP的分类器对齐。Right是离线区域提示学习的程序。为所有基本类别提取crop,并使用其视觉嵌入优化可学习的prompt(2.3节有详细描述)
然而,正如实验所表明的那样,将视觉潜在空间与文本空间自然对齐只会产生非常有限的开放词汇检测性能。我们推测泛化能力差主要来自三个方面:
- 仅用类名(
"This is a photo of [category]")计算类别嵌入是次优的,因为它们可能不够精确,无法描述视觉概念,从而导致词汇歧义。例如,“杏仁almond”既指带硬壳的可食用椭圆形坚果,也指它生长的树; - 用于训练CLIP的web图像是以场景为中心的,对象仅占图像的一小部分,而RPN的proposal要求将对象紧密地框起来,导致视觉表现上存在明显的领域差距;
- 用于检测器训练的基本类别与用于训练CLIP的基本类别相比差异显著较小,因此,可能不足以保证对新类别的泛化。
在下面的章节中,我们提出了一些简单的步骤来缓解上述问题。
2.3.通过Regional Prompt Learning对齐
与用于训练CLIP的以场景为中心的图像相比,RPN的输出特征是局部的和以对象为中心的。因此,如果将区域视觉表示与冻结的CLIP文本编码器对齐,将鼓励每个proposal捕获更多的上下文。为此,我们提出了一个简单的区域提示学习(RPL)概念,控制文本潜在空间以更好地适应以对象为中心的图像。
具体来说,在计算类别分类器或嵌入时,我们在文本输入之前添加一系列可学习向量,称为“连续提示向量”(continuous prompt vectors)。这些提示向量与任何实际单词都不对应,并且将在后续层中处理,它们就像是一系列“虚拟标记virtual tokens”一样。此外,我们还将更详细的描述包含在提示模板中,以减轻词汇歧义,例如:{category: "almond", description: "oval-shaped edible seed of the almond tree"}。请注意,描述通常可以很容易地从维基百科或数据集中的元数据中获取。因此,每个单独类别的嵌入可以生成为:
c
a
l
m
o
n
d
=
ϕ
t
e
x
t
(
[
p
1
,
.
.
.
,
p
j
,
g
(
c
a
t
e
g
o
r
y
)
,
p
j
+
1
,
.
.
.
,
p
j
+
h
,
g
(
d
e
s
c
r
i
p
t
i
o
n
)
]
)
c_{almond}=\phi_{text}([p_{1},...,p_{j},g(category),p_{j+1},...,p_{j+h},g(description)])
calmond=ϕtext([p1,...,pj,g(category),pj+1,...,pj+h,g(description)])其中,
p
i
p_{i}
pi表示可学习的提示向量,其维度和word embedding的维度相同。由于可学习提示向量是类别无关的,并且为所有类别共享,因此在训练后,它们有望转移到新类别。
优化提示向量
为了节省计算,我们考虑离线学习提示向量,具体来说,我们从LVIS获取基本类别的对象crop,相应地调整它们的大小,并通过冻结的CLIP视觉编码器生成图像嵌入。为了优化提示向量,我们将视觉编码器和文本编码器都冻结,只更新可学习的提示向量,并使用标准交叉熵损失对这些图像crop进行分类。RPL的过程如图2(Right)所示。
2.4.PromptDet:通过自训练对齐
到目前为止,通过将视觉主干与提示文本编码器对齐,我们已经获得了一个开放词汇表目标检测器。然而,RPL仅利用了有限的视觉多样性,即仅使用基本类别。在本节中,我们放宽了这种限制,并利用大规模、未经处理、嘈杂的web图像来进一步改进对齐。具体来说,如图3所示,我们描述了一个学习框架,该框架迭代RPL和候选图像,然后生成伪GT框,并对开放词汇检测器进行自训练。
寻找候选图像
我们将LAION-400M数据集作为初始图像-语料库,使用CLIP的视觉编码器预先计算视觉嵌入。为了获取每个类别的候选图像,我们计算视觉嵌入和类别嵌入之间的相似性分数,这是通过学习的区域提示计算的。我们保留了具有最高相似性的图像。因此,使用基本类别和新类别构建了一组额外的图像,并且没有可用的GT框,
D
e
x
t
=
{
(
I
e
x
t
)
i
}
i
=
1
∣
D
e
x
t
∣
D_{ext}=\left\{(I_{ext})_{i}\right\}_{i=1}^{|D_{ext}|}
Dext={(Iext)i}i=1∣Dext∣。
迭代式提示学习
我们交替使用"区域提示学习"(图3 stage1)和"用学习到的提示寻找候选图像"(图3 stage2)。实验表明,这种迭代过程有利于高精度挖掘以对象为中心的图像。它能够生成更精确的伪GT框,因此,在自训练后,大大提高了对新类别的检测性能。
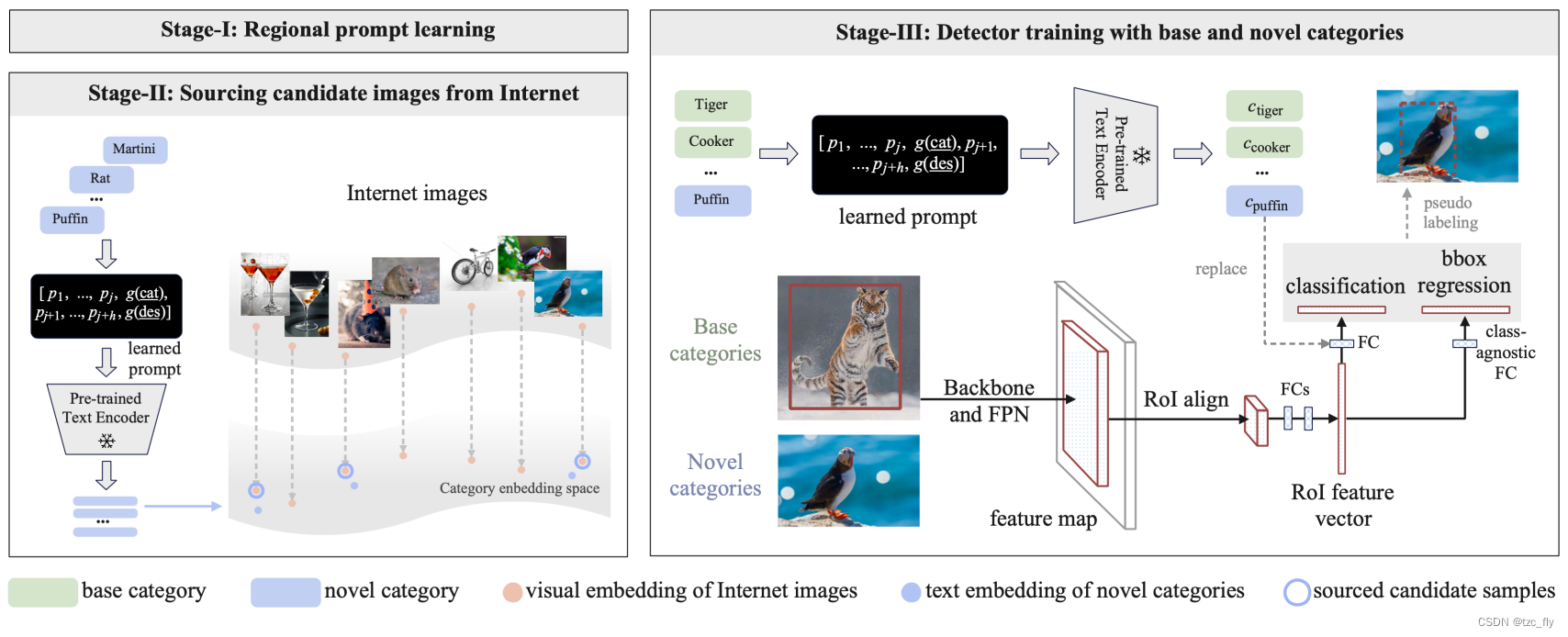
- 图3:自训练框架。
- stage 1:使用基本类别来学习区域提示,如图2(Right)所示。
- stage 2:通过学习的提示来获取来自Web的候选图像。
- stage 3:我们使用基本类别的LVIS图像和新类别的源图像对检测器进行自训练。请注意,可以反复执行提示学习和候选图像的获取,以更好地检索相关图像。
Bounding box生成
对于
D
e
x
t
D_{ext}
Dext中的每一张图像,我们使用开放词汇表进行推理。由于这些候选图像通常是以对象为中心的,因此不受类别限制的RPN的输出对象proposal通常可以保证适当的精度和召回率。我们保留具有最大对象性分数的top-K proposal,然后保留具有最大分类分数的框作为每个图像的伪Ground Truth。请注意,尽管图像可能包含多个感兴趣的对象,但我们只选择一个框作为伪GT。总的来说,这种程序将成功地挖掘出大量以前未标记的伪GT实例,这些实例随后用于在Mask RCNN中重新训练视觉中枢和RPN(包括回归头)。
3.实验

- 图4:候选图像上生成的伪GT。

- 表1:手动设计提示和学习提示的比较。这里,我们在PRL中只使用两个可学习的提示向量,即[1+1]表示使用一个向量作为前缀,一个向量用作后缀。










