DFS之记忆化搜索
- 比如说一张图,有时候dfs不断递归的时候,发现不能达到目标状态(位置),需要回到原来状态,但是递归的时候中间结果是没有记录的,比如一个递归下去,当前的dfs有几个方向,但是发现这些方向都不能使用,于是返回上一层,由于没有中间态的记录,在上一层的另一个方向的递归下一层又是新的方向,就造了太多计算。
- 再说个极端点的例子,就类似于递归到目标态跟前了,但就是达不到,没办法只能一直往回走,同时在往回走的时候还会再试试当前点其他方向,再继续往下递归,然后下一个递归又有很多个方向,明知道已经完成不了目标但还是继续递归下去,这样就有大量的重复运算,一旦数据量大点时间就会爆炸,所以要引进记忆化搜索,记录递归过程的中间结果,方便以后判断哪个方向已经试过了,行不通!
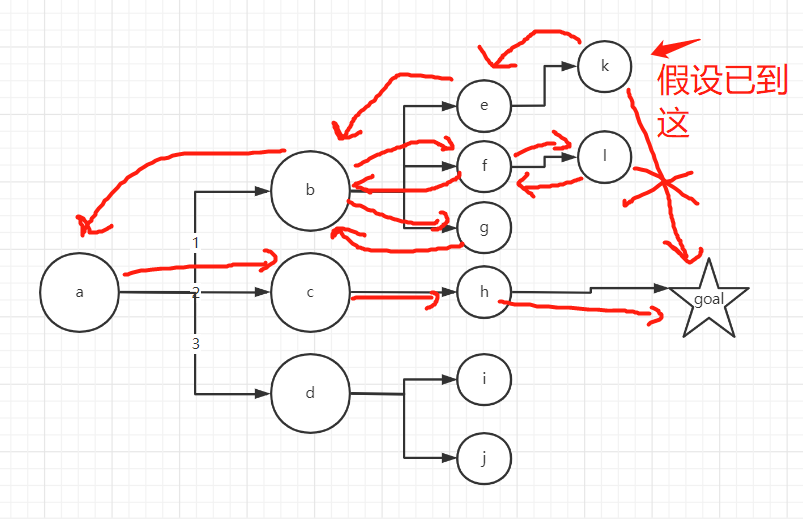
反正就差不多这个意思吧,可能不太精确,会有很多不必要的计算。
记忆化要点
- 加入记忆化的时候,就需要把DFS方法中的可变参数作为维度,把DFS返回的值作为存储值。一般使用数组来存,例如 int[x][y],自己设定0为为计算,-1为false,1为true。再看一下 Leetcode.403这题,这题的维度是石头列表的下标和已跳跃步数,这两都是可变参数,返回的值就是是否能走通。当然在这个数组空间不好判断的时候,我们可以直接用哈希表来存储,也可以降低爆空间风险,如果数据量小的话就用一般数组方便些,还有会遇到可变参数为负数的时候,就用哈希表来存。
看看代码:
未加入记忆化搜索的dfs:(时间会爆)
class Solution {
Map<Integer, Integer> map = new HashMap<>();
public boolean canCross(int[] ss) {
int n = ss.length;
// 将石子信息存入哈希表
// 为了快速判断是否存在某块石子,以及快速查找某块石子所在下标
for (int i = 0; i < n; i++) {
map.put(ss[i], i);
}
// check first step
// 根据题意,第一步是固定经过步长 1 到达第一块石子(下标为 1)
if (!map.containsKey(1)) return false;
return dfs(ss, ss.length, 1, 1);
}
/**
* 判定是否能够跳到最后一块石子
* @param ss 石子列表【不变】
* @param n 石子列表长度【不变】
* @param u 当前所在的石子的下标
* @param k 上一次是经过多少步跳到当前位置的
* @return 是否能跳到最后一块石子
*/
boolean dfs(int[] ss, int n, int u, int k) {
if (u == n - 1) return true;
for (int i = -1; i <= 1; i++) {
// 如果是原地踏步的话,直接跳过
if (k + i == 0) continue;
// 下一步的石子理论编号
int next = ss[u] + k + i;
// 如果存在下一步的石子,则跳转到下一步石子,并 DFS 下去
if (map.containsKey(next)) {
boolean cur = dfs(ss, n, map.get(next), k + i);
if (cur) return true;
}
}
return false;
}
}
加入记忆化搜索的dfs(正常):
class Solution {
Map<Integer, Integer> map = new HashMap<>();
// int[][] cache = new int[2009][2009];
Map<String, Boolean> cache = new HashMap<>();
public boolean canCross(int[] ss) {
int n = ss.length;
for (int i = 0; i < n; i++) {
map.put(ss[i], i);
}
// check first step
if (!map.containsKey(1)) return false;
return dfs(ss, ss.length, 1, 1);
}
boolean dfs(int[] ss, int n, int u, int k) {
String key = u + "_" + k;
// if (cache[u][k] != 0) return cache[u][k] == 1;
if (cache.containsKey(key)) return cache.get(key);
if (u == n - 1) return true;
for (int i = -1; i <= 1; i++) {
if (k + i == 0) continue;
int next = ss[u] + k + i;
if (map.containsKey(next)) {
boolean cur = dfs(ss, n, map.get(next), k + i);
// cache[u][k] = cur ? 1 : -1;
cache.put(key, cur);
if (cur) return true;
}
}
// cache[u][k] = -1;
cache.put(key, false);
return false;
}
}
- 再看一下 Leetcode.576 ,像这个用例
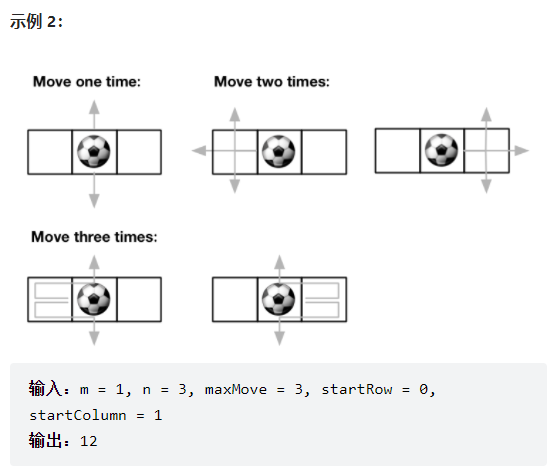
就会有重复往返的一条路,由于数据量并不大,就用数组来存,免得map的get和put方法一直调用,int[x][y][step] ,x和y就为坐标,step为走的步数,存储的值为0,说明还未计算,-1为不可达,1为可以出去。先看代码:
class Solution {
int[][] dirs = new int[][]{{1,0},{0,1},{-1,0},{0,-1}};//四个方向
int[][][] cache;
int MOD = (int) 1e9 + 7;
int m,n;
public int findPaths(int _m, int _n, int maxMove, int startRow, int startColumn) {
m = _m;n = _n;
cache = new int[m][n][maxMove+1];
for (int i = 0; i < m; i++) {
for (int j = 0; j <n; j++) {
for (int k = 0; k <= maxMove; k++) {
cache[i][j][k] = -1;//初始化全为不可达,为计算状态
}
}
}
return dfs(startRow,startColumn,maxMove);
}
int dfs(int x,int y,int step){
if(x < 0 || x>=m || y < 0 || y >= n) return 1;//判断是否出界
if(step == 0) return 0;//未出界并且步数为0则返回0,表示已经计算过但不能出界,否则继续走下去,往回走也行
if(cache[x][y][step] != -1) return cache[x][y][step];
int cnt = 0;//每次递归都重新定义一个计数,防止互相干扰
for(int[] dir:dirs){
int nx = x + dir[0],ny = y + dir[1];
cnt += dfs(nx, ny, step - 1); //累加有多少条路
cnt %= MOD;
}
cache[x][y][step] = cnt;//无路可走,记录一下。
return cnt;
}
}
当然这里的记忆数组同时还可以判重,防止走重复的路,有点跟BFS的visit类似。










