文章目录
- 重要:本系列文章内容摘自
<Linux内核深度解析>基于ARM64架构的Linux4.x内核一书,作者余华兵。系列文章主要用于记录Linux内核的大部分机制及参数的总结说明
1 SMP调度
在SMP系统中,进程调度器必须支持以下特性:
- 需要使每个cpu的负载尽可能均衡。
- 可以设置进程的处理器亲和性(affinity),即允许进程在哪些处理器上执行。
- 可以把进程从一个cpu迁移到另一个cpu。
1.1 进程的cpu亲和性
设置进程的cpu亲和性,意思就是把进程绑定到某些cpu上,只允许进程在这个绑定的cpu上执行,默认情况是进程可以在所有cpu上执行。
进程描述符增加了以下两个成员:
include/linux/sched.h
struct task_struct {
...
int nr_cpus_allowed;
cpumask_t cpus_allowed;
...
};
成员cpus_allowed保存允许的cpu掩码,成员nr_cpus_allowed保存允许的cpu数量。
- 应用编程接口
内核提供了两个系统调用:- sched_setaffinity用来设置进程的cpu亲和性掩码:
int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask); - sched_getaffinity用来获取进程的cpu亲和性掩码:
int sched_getaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
- kthread_bind用来把一个刚刚创建的内核线程绑定到一个处理器:
void kthread_bind(struct task_struct *p, unsigned int cpu); - set_cpus_allowed_ptr用来设置内核线程的处理器亲和性掩码:
int set_cpus_allowed_ptr(struct task_struct *p, const struct cpumask *new_mask);
- sched_setaffinity用来设置进程的cpu亲和性掩码:
- 使用cpuset配置
管理员可以使用cpuset设置进程的处理器亲和性。cpuset用来控制进程在哪些处理器上执行,以及从哪些内存节点分配内存。cpuset可以单独使用,也可以作为cgroup的一个资源控制器使用(cpuset合并到内核的时间比cgroup早,2.6.12版本引入cpuset,2.6.24版本引入cgroup)。
1.2 对调度器的拓展
在SMP系统上,调度类增加了如下方法:
kernel/sched/sched.h
struct sched_class {
...
#ifdef CONFIG_SMP
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
void (*migrate_task_rq)(struct task_struct *p);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
#endif
...
};
(1)select_task_rq方法用来为进程选择运行队列,实际上就是选择处理器。
(2)migrate_task_rq方法用来在进程被迁移到新的处理器之前调用。
(3)task_woken方法用来在进程被唤醒以后调用。
(4)set_cpus_allowed方法用来在设置处理器亲和性的时候执行调度类的特殊处理。
以下两种情况下,进程在内存和缓存中的数据是最少的,是有价值的实现负载均衡的机会。
(1)调用fork或clone以创建新进程,如下所示:
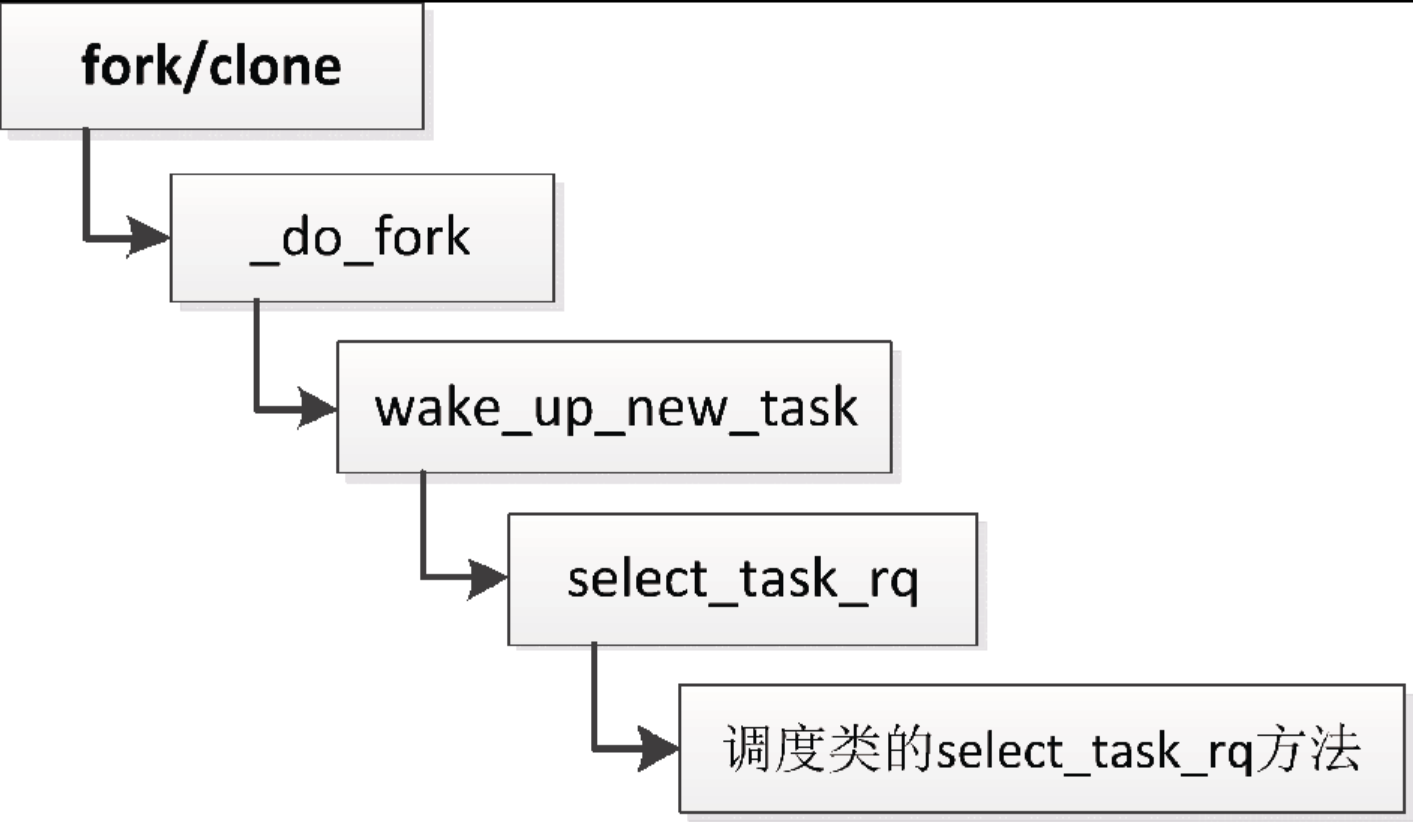
(2)调用execve装载程序,如下所示。
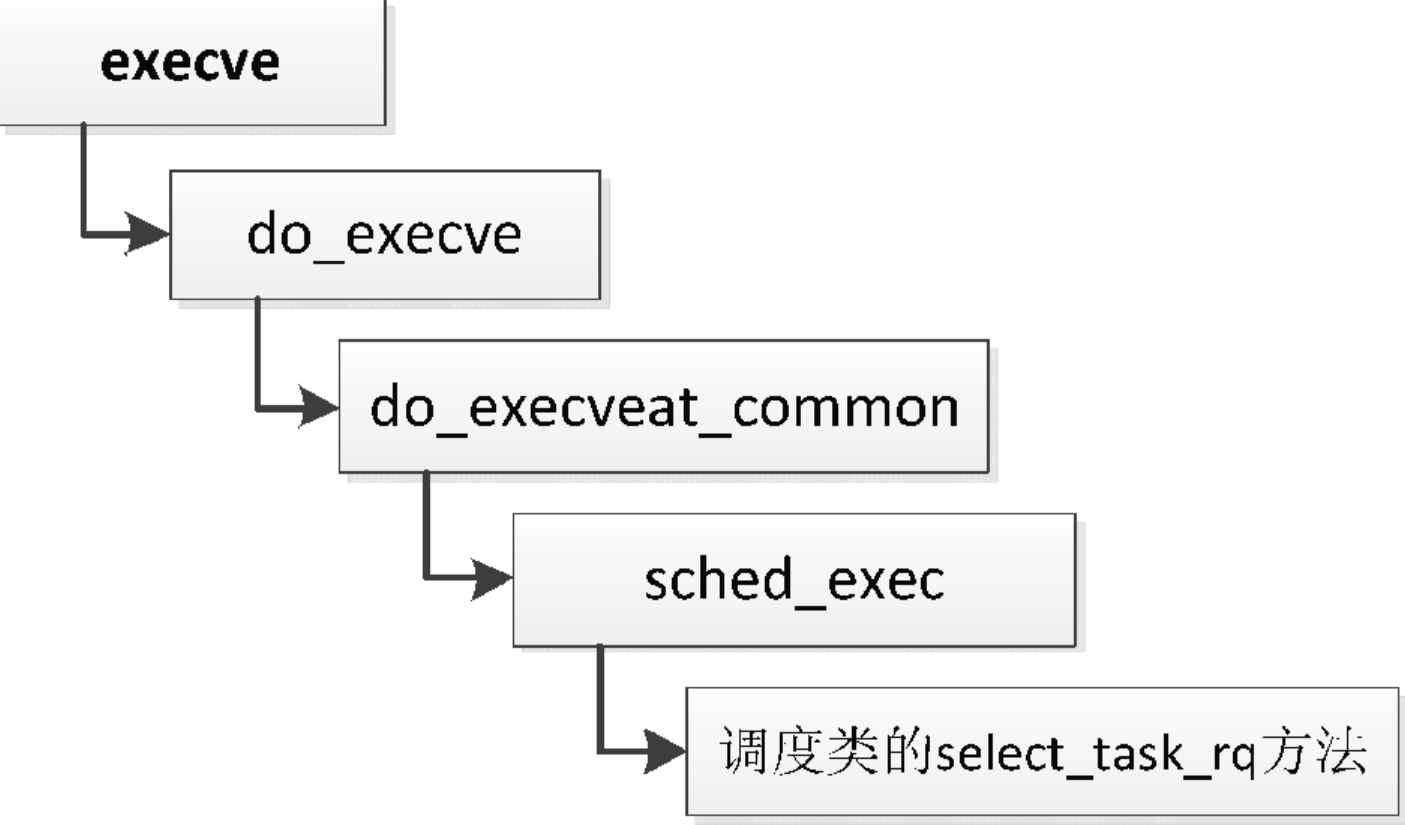
1.3 期限调度类的cpu负载均衡
限期调度类的处理器负载均衡比较简单,如下所示。调度器选择下一个限期进程的时候,如果当前正在执行的进程是限期进程,将会试图从限期进程超载的处理器把限期进程拉过来:
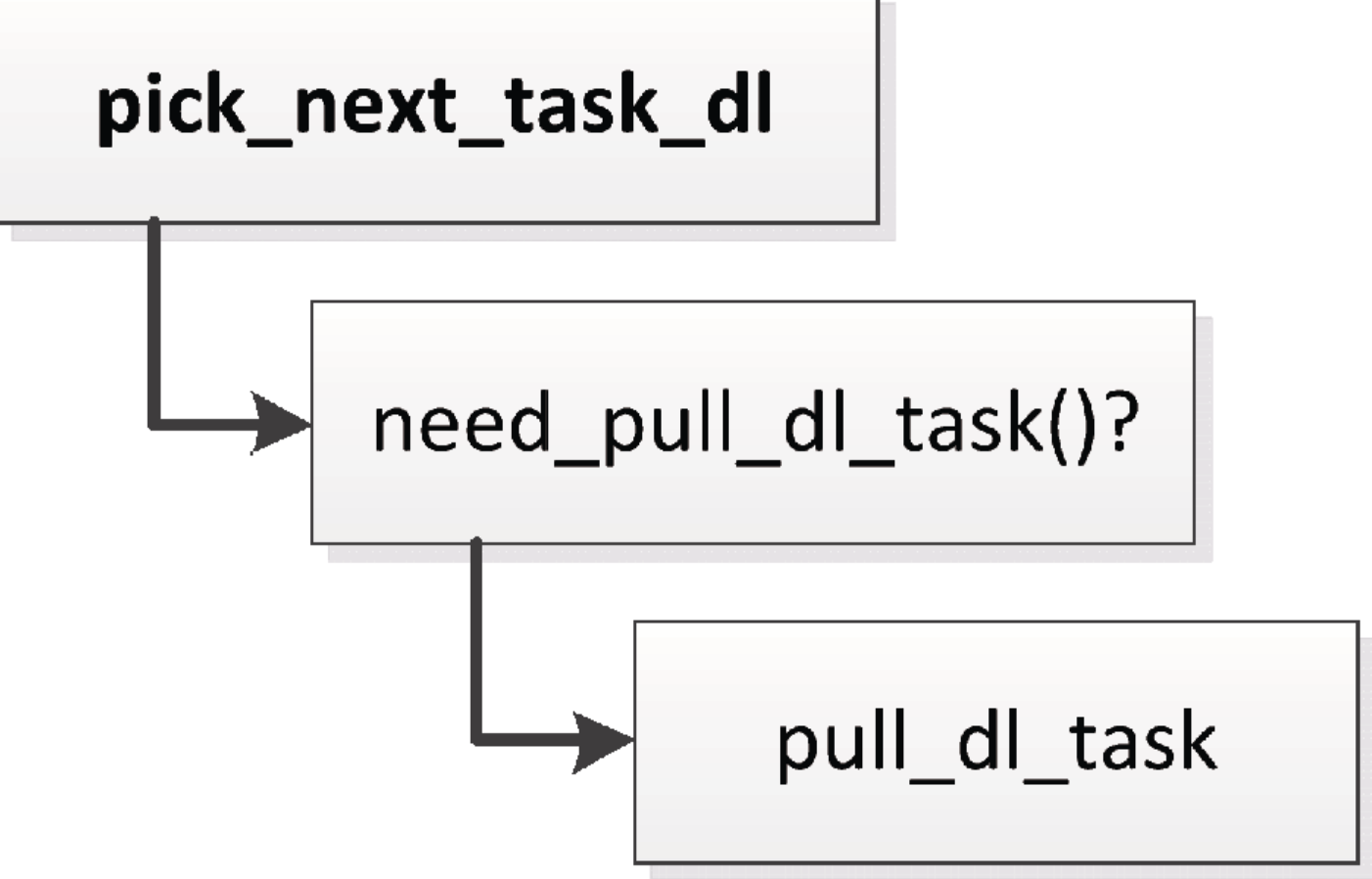
限期进程超载的定义如下:
(1)限期运行队列至少有两个限期进程。
(2)至少有一个限期进程绑定到多个处理器。
1.4 实时调度类的cpu负载均衡
实时调度类的处理器负载均衡和限期调度类相似,如下所示。调度器选择下一个实时进程时,如果当前处理器的实时运行队列中的进程的最高调度优先级比当前正在执行的进程的调度优先级低,将会试图从实时进程超载的处理器把可推送实时进程拉过来:
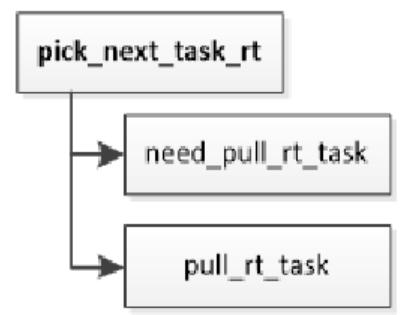
实时进程超载的定义如下。
(1)实时运行队列至少有两个实时进程。
(2)至少有一个可推送实时进程。
可推送实时进程是指绑定到多个处理器的实时进程,可以在处理器之间迁移。
1.5 公平调度类的cpu负载均衡
-
处理器拓扑
目前多处理器系统有两种体系结构。
(1)非一致内存访问(Non-Uniform Memory Access,NUMA):指内存被划分成多个内存节点的多处理器系统,访问一个内存节点花费的时间取决于处理器和内存节点的距离。每个处理器有一个本地内存节点,处理器访问本地内存节点的速度比访问其他内存节点的速度快。
(2)对称多处理器(Symmetric Multi-Processor,SMP):即一致内存访问(Uniform Memory Access,UMA),所有处理器访问内存花费的时间是相同的。每个处理器的地位是平等的,仅在内核初始化的时候不平等:“0号处理器作为引导处理器负责初始化内核,其他处理器等待内核初始化完成。”在实际应用中可以采用混合体系结构,在NUMA节点内部使用SMP体系结构。
处理器内部的拓扑如下。
(1)核(core):一个处理器包含多个核,每个核有独立的一级缓存,所有核共享二级缓存。
(2)硬件线程:也称为逻辑处理器或者虚拟处理器,一个处理器或者核包含多个硬件线程,硬件线程共享一级缓存和二级缓存。MIPS处理器的叫法是同步多线程(Simultaneous Multi-Threading,SMT),英特尔对它的叫法是超线程。当一个进程在不同的处理器拓扑层次上迁移的时候,付出的代价是不同的。
(1)如果从同一个核的一个硬件线程迁移到另一个硬件线程,进程在一级缓存和二级缓存中的数据可以继续使用。
(2)如果从同一个处理器的一个核迁移到另一个核,进程在源核的一级缓存中的数据失效,在二级缓存中的数据可以继续使用。
(3)如果从同一个NUMA节点的一个处理器迁移到另一个处理器,进程在源处理器的一级缓存和二级缓存中的数据失效。
(4)如果从一个NUMA节点迁移到另一个NUMA节点,进程在源处理器的一级缓存和二级缓存中的数据失效,并且访问内存可能变慢。可以看出,处理器拓扑层次越高,迁移进程付出的代价越大。
-
调度域和调度组
软件看到的处理器是最底层的处理器。
(1)如果处理器支持硬件线程,那么最底层的处理器是硬件线程。
(2)如果处理器不支持硬件线程,支持多核,那么最底层的处理器是核。
(3)如果处理器不支持多核和硬件线程,那么最底层的处理器是物理处理器。下面基于“处理器支持多核和硬件线程”这个假设。
内核按照处理器拓扑层次划分调度域层次,每个调度域包含多个调度组,调度组和调度域的关系如下。
(1)每个调度组的处理器集合是调度域的处理器集合的子集。
(2)所有调度组的处理器集合的并集是调度域的处理器集合。
(3)不同调度组的处理器集合没有交集。如果我们把硬件线程、核、物理处理器和NUMA节点都理解为对应层次的处理器,那么可以认为:调度域对应更高层次的一个处理器,调度组对应本层次的一个处理器。一个硬件线程调度域对应一个核,每个调度组对应核的一个硬件线程;一个核调度域对应一个物理处理器,每个调度组对应物理处理器的一个核;一个处理器调度域对应一个NUMA节点,每个调度组对应NUMA节点的一个处理器。
每个处理器有一个基本的调度域,它是硬件线程调度域,向上依次是核调度域、处理器调度域和NUMA节点调度域。
举例说明:假设系统只有一个处理器,处理器包含两个核,每个核包含两个硬件线程,软件看到的处理器是硬件线程,即处理器0~3,调度域层次树如下所示:
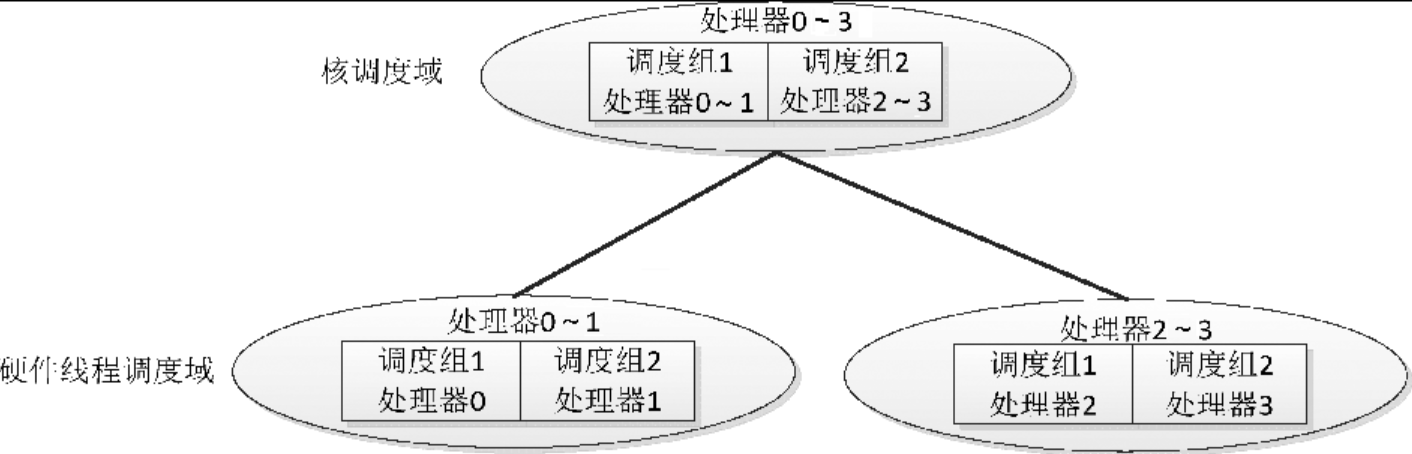
(1)两个硬件线程调度域:一个硬件线程调度域包含处理器0~1,分为两个调度组,调度组1包含处理器0,调度组2包含处理器1;另一个硬件线程调度域包含处理器2~3,分为两个调度组,调度组1包含处理器2,调度组2包含处理器3。
(2)一个核调度域包含处理器0~3,分为两个调度组,调度组1包含处理器0~1,调度组2包含处理器2~3。考虑到NUMA节点之间的距离不同,把NUMA节点调度域划分为多个层次,算法是:把节点0到其他节点之间的距离按从小到大排序,去掉重复的数值,如果有n个距离值,记为数组d[n],那么划分n个层次,层次i(0 <= i < n)的标准是节点之间的距离小于或等于d[i]。
算法假设:节点0到节点j的距离在任意节点i到节点j的距离之中是最大的。举例说明1:假设系统划分为3个NUMA节点,节点编号是0~2,节点0到节点1的距离是100,节点0到结节2的距离是200,那么划分2个NUMA节点调度域层次。
(1)层次0的标准是节点之间的距离小于或等于100。
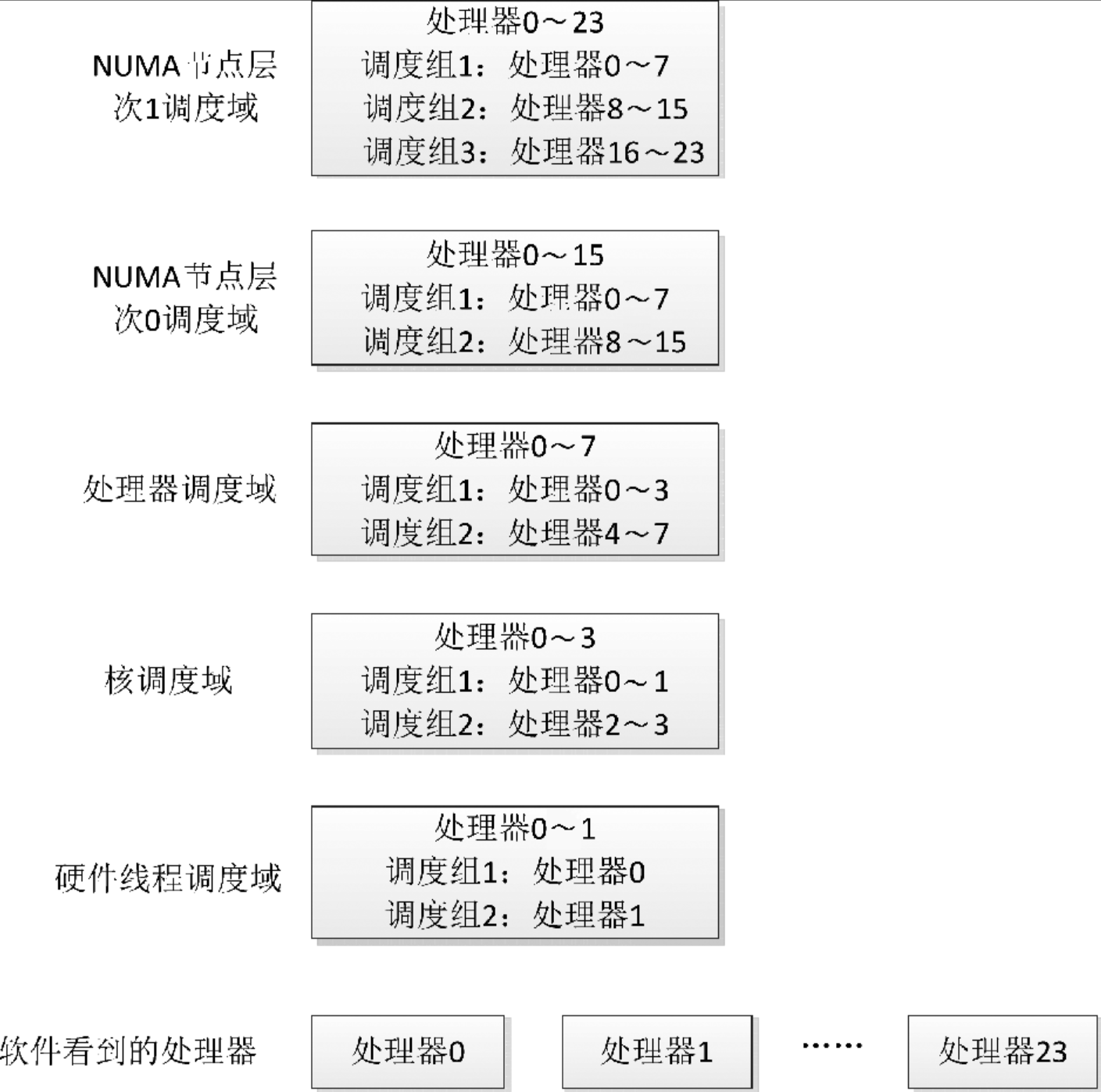
(2)层次1的标准是节点之间的距离小于或等于200。举例说明2:以举例说明1作为基础,每个NUMA节点包含2个处理器,每个处理器包含2个核,每个核包含2个硬件线程,总共24个硬件线程,软件看到的处理器是最底层的硬件线程,即24个处理器。硬件线程0和1看到的调度域层次树如下所示。
-
负载均衡算法
(1)计算公平运行队列的平均负载。
把运行历史划分成近似1毫秒的片段,每个片段称为一个周期,为了方便执行移位操作,把一个周期定义为1024微秒。一个周期的加权负载:load = 周期长度 × 处理器频率 × 公平运行队列的权重。
公平运行队列的加权负载总和:load_sum = load +(y × load_sum),其中y是衰减系数,y32 = 0.5。
把公式展开以后如下所示:

加权时间总和:time_sum = 周期长度 + (y × time_sum)。加权平均负载:load_avg = load_sum / time_sum。
(2)计算处理器负载。
基于上面的公平运行队列的加权平均负载,计算5种处理器负载,计算公式如下:
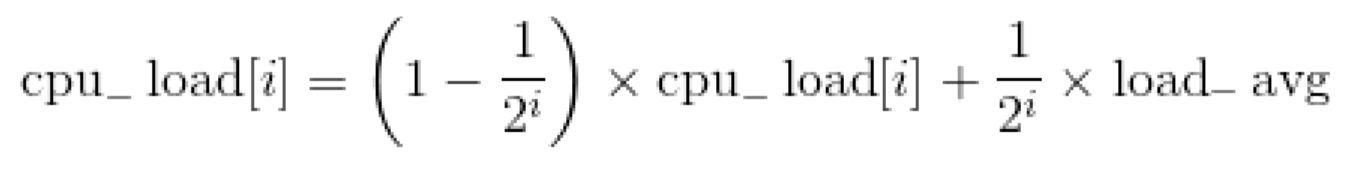
其中i的取值是0~4,load_avg是根任务组的公平运行队列的加权平均负载。5种负载的区别是,历史负载和当前负载的比例不同,i越大,历史负载占的比例越大,处理器负载曲线越平滑。在处理器不空闲、即将空闲和空闲等不同情况下实现负载均衡时,使用不同的处理器负载。
-
代码实现
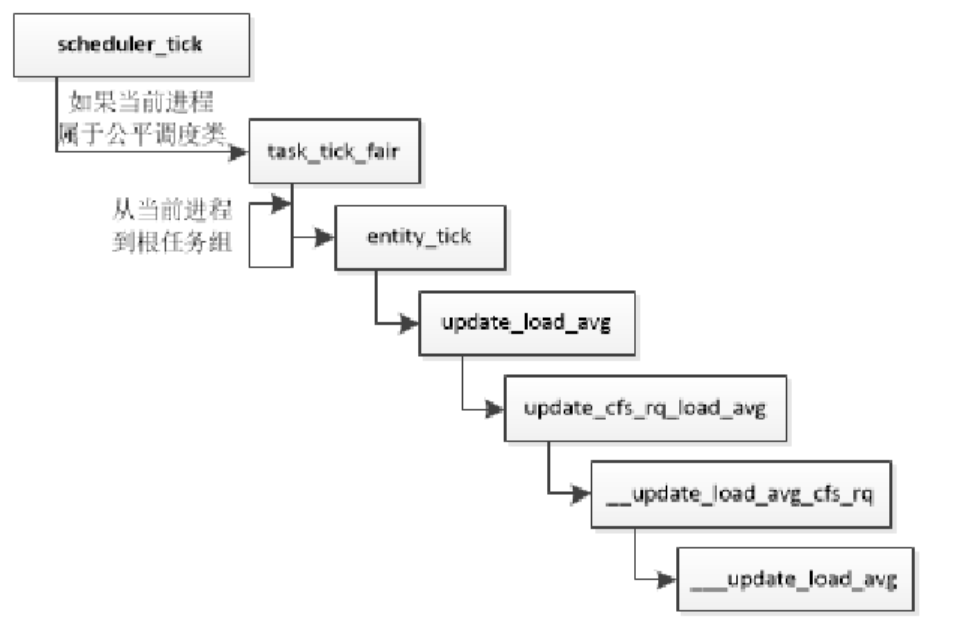
(1)计算公平运行队列的平均负载:在以下情况下,从进程到根任务组计算每层公平运行队列的平均负载。- 周期性地计算(函数task_tick_fair)。
- 进程加入公平运行队列(函数enqueue_task_fair)。
- 进程退出公平运行队列(函数dequeue_task_fair)。
公平运行队列中描述负载总和与平均负载的成员如下:
kernel/sched/sched.h struct cfs_rq { ... u64 runnable_load_sum; unsigned long runnable_load_avg; ... };如下所示,如果当前正在执行的进程属于公平调度类,那么周期调度函数scheduler_tick()将调用公平调度类的task_tick方法,从当前进程到根任务组,计算每层公平运行队列的平均负载。
(2)计算处理器负载。运行队列中描述处理器负载的成员如下:kernel/sched/sched.h struct rq { ... #define CPU_LOAD_IDX_MAX 5 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; ... };如下所示,周期调度函数scheduler_tick()调用函数cpu_load_update_active(),计算处理器负载。
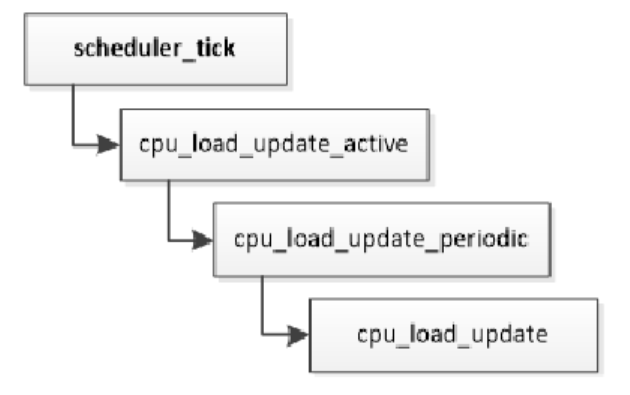
函数cpu_load_update负责以根任务组的公平运行队列的平均负载值为基础计算处理器负载,参数this_load是公平运行队列的平均负载值,其代码如下:kernel/sched/fair.c static void cpu_load_update(struct rq *this_rq, unsigned long this_load, unsigned long pending_updates) { ... this_rq->cpu_load[0] = this_load; for (i = 1, scale = 2; i < CPU_LOAD_IDX_MAX; i++, scale += scale) { unsigned long old_load, new_load; old_load = this_rq->cpu_load[i]; new_load = this_load; if (new_load > old_load) new_load += scale - 1; this_rq->cpu_load[i] = (old_load * (scale - 1) + new_load) >> i; } ... }(3)负载均衡。调度器在以下情况下会执行处理器负载均衡。
1)周期性地主动负载均衡,时间间隔是1分钟。
2)除空闲线程外没有其他可运行的进程,处理器即将空闲。
如下所示,周期调度函数scheduler_tick()判断有没有到达执行负载均衡的时间点,如果到达,触发调度软中断。调度软中断从处理器的基本调度域到顶层调度域执行负载均衡,在每层调度域,函数load_balance负责执行负载均衡。
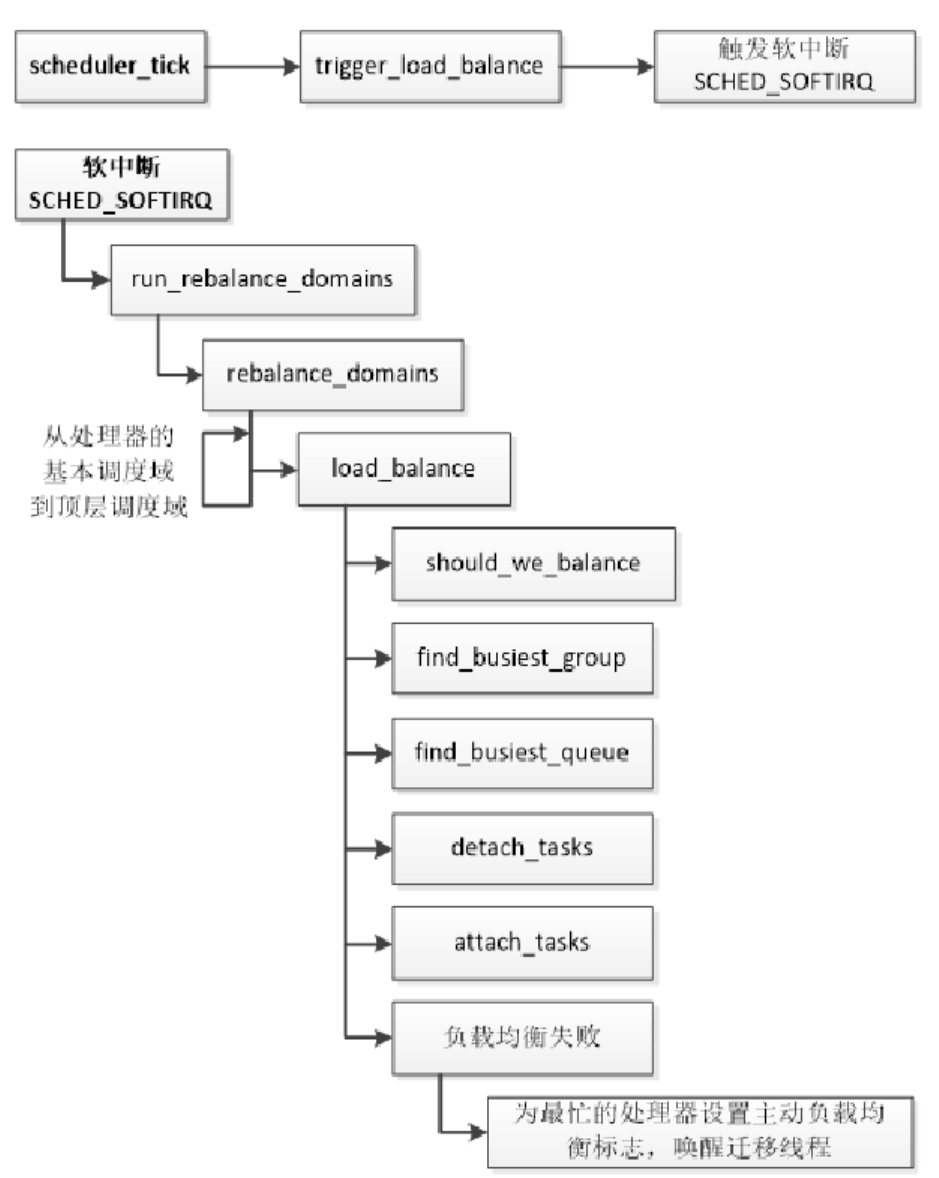
1)判断当前处理器是否应该执行负载均衡。这3种情况允许当前处理器执行负载均衡:当前处理器即将空闲,或是第一个调度组的第一个空闲处理器,或是第一个调度组的第一个处理器。
2)找出最忙的调度组。
3)从最忙的调度组中找出最忙的处理器。
4)从最忙的处理器中迁移若干个进程到当前处理器。
5)如果负载均衡失败,即没有迁移一个进程,那么为最忙处理器设置主动负载均衡标志,记录当前处理器作为迁移目标,向最忙处理器的停机工作队列添加一个工作,工作函数是active_load_balance_cpu_stop,唤醒最忙处理器的迁移线程。迁移线程将会从从停机工作队列取出工作,执行主动的负载均衡。找出最忙的调度组
当前处理器所属的调度组称为本地调度组,需要从除了本地调度组以外的调度组中找出最忙的调度组。计算每个调度组的负载和平均负载。调度组的负载是属于调度组的每个处理器的负载的总和,上面说了有5种处理器负载,根据当前处理器不空闲、即将空闲或空闲选择不同的处理器负载种类,并且采用保守策略:“对于本地调度组,取处理器负载和公平运行队列的加权平均负载的较大值;对于其他调度组,取两者的较小值”。调度组的平均负载 = 调度组的负载总和/调度组的所有处理器的能力总和。
从除了本地调度组以外的调度组找出负载最大的调度组,即最忙调度组。
当前处理器空闲的情况:如果最忙调度组没有超载,或者本地调度组的空闲处理器数量小于或等于“最忙调度组的空闲处理器数量+ 1”,那么不需要执行负载均衡。
当前处理器不空闲或即将空闲的情况:如果最忙调度组的平均负载小于或等于(本地调度组的平均负载×调度域的不均衡水线),那么不需要执行负载均衡。
最后计算一个不均衡值,用来控制从最忙调度组迁移多少个进程到本地调度组。不均衡值取以下三者的最小值:
1)(最忙调度组的平均负载−所有调度组的平均负载)×最忙调度组的能力值
2)最忙调度组超过处理能力的负载×最忙调度组的能力值
3)(所有调度组的平均负载−本地调度组的平均负载)×本地调度组的能力值
1.6 迁移线程
每个处理器有一个迁移线程,线程名称是“migration/<cpu_id>”,属于停机调度类,可以抢占所有其他进程,其他进程不可以抢占它。迁移线程有两个作用。
(1)调度器发出迁移请求,迁移线程处理迁移请求,把进程迁移到目标处理器。
(2)执行主动负载均衡。
如下所示,每个处理器有一个停机工作管理器,成员thread指向迁移线程的进程描述符,成员works是停机工作队列的头节点,每个节点是一个停机工作,数据类型是结构体cpu_stop_work。内核提供了两个添加停机工作的函数。
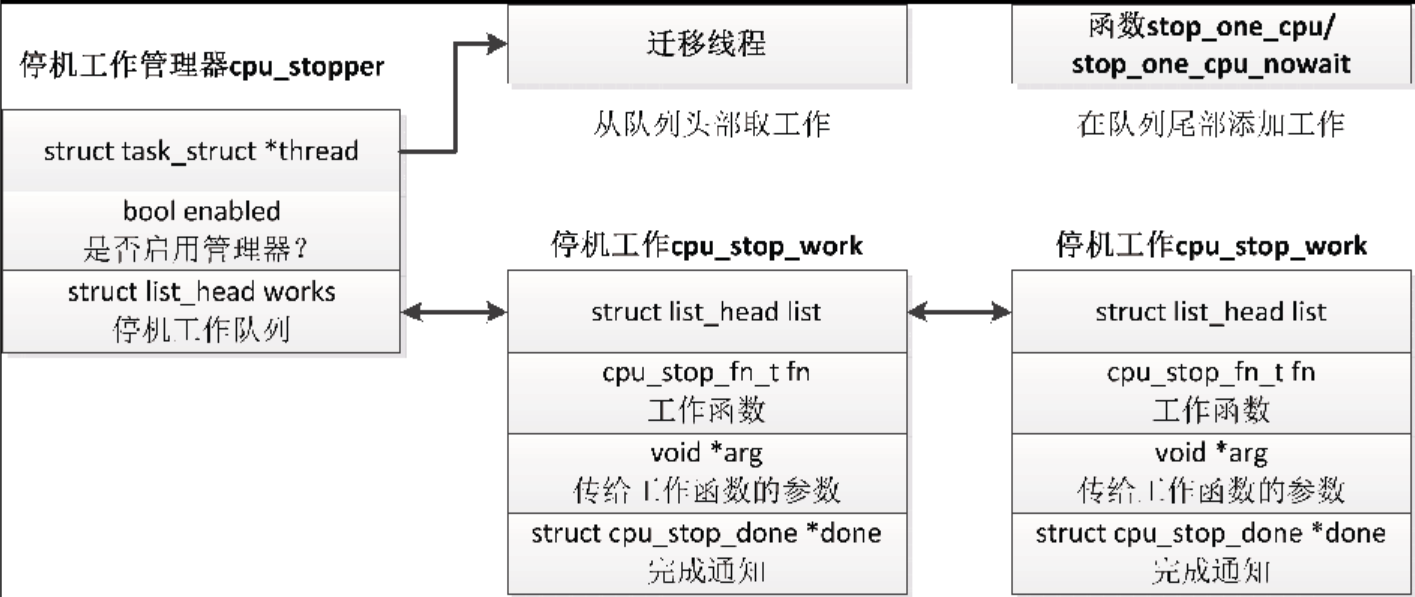
(1)stop_one_cpu用来向指定处理器添加停机工作,并且等待停机工作完成。int stop_one_cpu(unsigned int cpu, cpu_stop_fn_t fn, void *arg);
(2)stop_one_cpu_nowait用来向指定处理器添加停机工作,但是不等待停机工作完成。bool stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg, struct cpu_stop_work *work_buf);
如下所示,迁移线程的线程函数是smpboot_thread_fn,如果当前处理器的停机工作队列不是空的,重复执行下面的步骤。
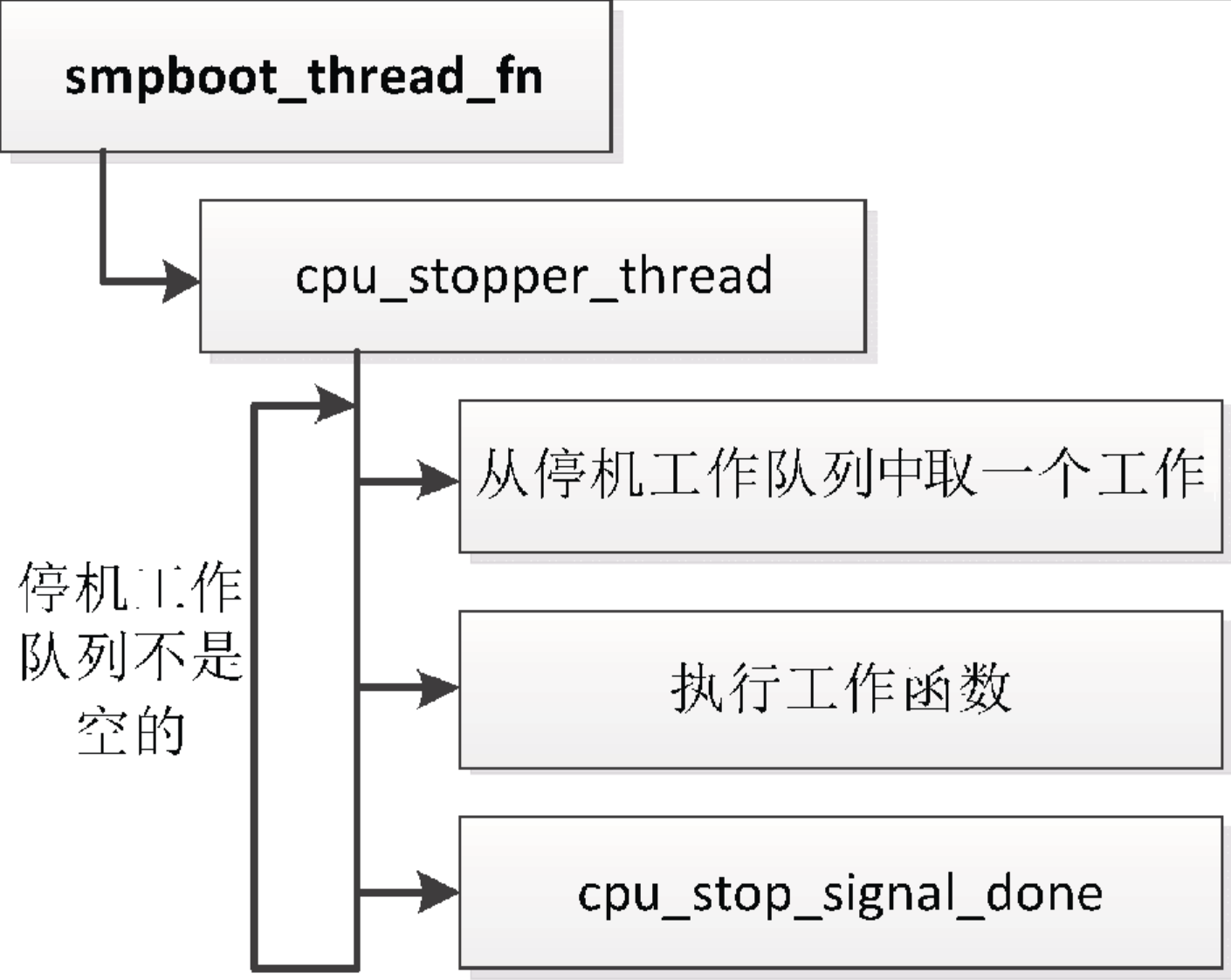
(1)从停机工作队列中取一个工作。
(2)执行工作函数。
(3)如果发起请求的进程正在等待,那么发送处理完成的通知。
如下所示,调用系统调用 sched_setaffinity以设置进程的处理器亲和性时,如果进程正在执行或者被唤醒,假设进程在处理器n上,调度器就会向处理器n的迁移线程发出迁移请求:“向处理器n的停机工作队列添加一个工作,工作函数是migration_cpu_stop”,然后唤醒处理器n的迁移线程,等待迁移线程处理完迁移请求。
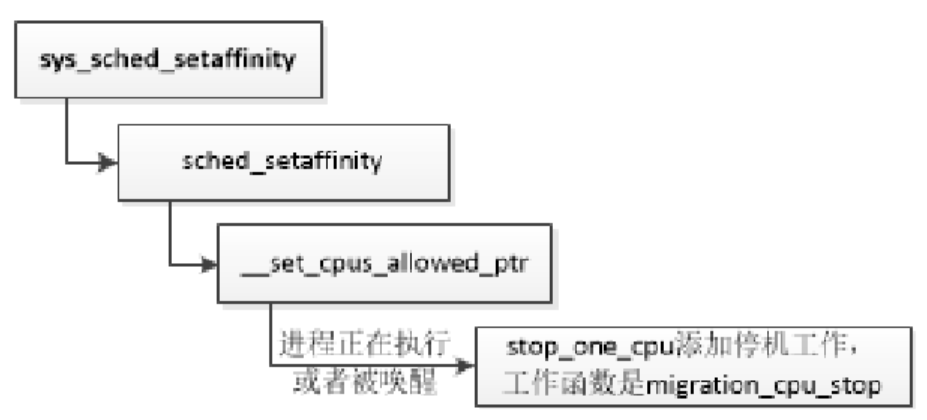
函数migration_cpu_stop负责把进程从当前处理器迁移到目标处理器,参数的类型是结构体migration_arg,成员task是需要迁移的进程,成员dest_cpu是目标处理器。
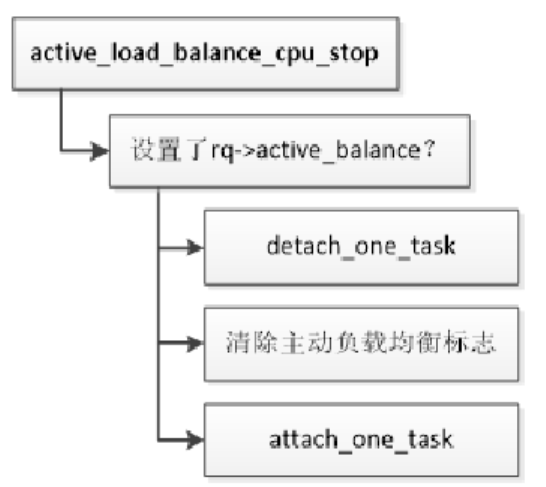
公平调度类执行处理器负载均衡失败的时候,为最忙处理器设置主动负载均衡标志,唤醒最忙处理器的迁移线程。函数active_load_balance_cpu_stop负责执行主动负载均衡,执行流程如下所示,先判断运行队列是否设置了主动负载均衡标志,如果设置了,那么从当前处理器的运行队列中选择一个公平调度类的进程,清除运行队列的主动负载均衡标志,把进程迁移到目标处理器。
1.7 隔离处理器
有时我们想把一部分处理器作为专用处理器,比如在网络设备上为了提高转发速度,让一部分处理器专门负责转发报文,实现方法是在引导内核时向内核传递参数“isolcpus=<CPU列表>”,隔离这些处理器,被隔离的处理器不会参与SMP负载均衡。如果没有把进程绑定到被隔离的处理器,那么不会有进程在被隔离的处理器上执行。
CPU列表有下面3种格式。
(1)<cpu number>,…,<cpu number>
(2)按升序排列的范围:<cpu number>-<cpu number>
(3)混合格式:<cpu number>,…,<cpu number>-<cpu number>
例如“isolcpus=1,2,10-20”表示隔离处理器1、2和10~20。










