监督学习
项目: 为CharityML寻找捐献者
前言
在这个项目中,笔者将使用1994年美国人口普查收集的数据,选用几个监督学习算法以准确地建模被调查者的收入。然后,根据初步结果从中选择出最佳的候选算法,并进一步优化该算法以最好地建模这些数据。目标是建立一个能够准确地预测被调查者年收入是否超过50000美元的模型。这种类型的任务会出现在那些依赖于捐款而存在的非营利性组织。了解人群的收入情况可以帮助一个非营利性的机构更好地了解他们要多大的捐赠,或是否他们应该接触这些人。虽然很难直接从公开的资源中推断出一个人的一般收入阶层,但是可以(也正是我们将要做的)从其他的一些公开的可获得的资源中获得一些特征从而推断出该值。
这个项目的数据集来自UCI机器学习知识库。这个数据集是由Ron Kohavi和Barry Becker在发表文章_“Scaling Up the Accuracy of Naive-Bayes Classifiers: A Decision-Tree Hybrid”_之后捐赠的,你可以在Ron Kohavi提供的在线版本中找到这个文章。我们在这里探索的数据集相比于原有的数据集有一些小小的改变,比如说移除了特征'fnlwgt' 以及一些遗失的或者是格式不正确的记录。
探索数据
载入需要的Python库并导入人口普查数据。注意数据集的最后一列'income'将是我们需要预测的列(表示被调查者的年收入会大于或者是最多50,000美元),人口普查数据中的每一列都将是关于被调查者的特征。
# 为这个项目导入需要的库
import numpy as np
import pandas as pd
from time import time
from IPython.display import display # 允许为DataFrame使用display()
# 导入附加的可视化代码visuals.py
import visuals as vs
# 为notebook提供更加漂亮的可视化
%matplotlib inline
# 导入人口普查数据
data = pd.read_csv("census.csv")
# 成功 - 显示第一条记录
display(data.head(n=1))

练习:数据探索
首先对数据集进行一个粗略的探索,看看每一个类别里会有多少被调查者?这些里面多大比例是年收入大于50,000美元的。在下面的代码单元中,我将计算以下数据:
- 总的记录数量,
'n_records' - 年收入大于50,000美元的人数,
'n_greater_50k'. - 年收入最多为50,000美元的人数
'n_at_most_50k'. - 年收入大于50,000美元的人所占的比例,
'greater_percent'.
# TODO:总的记录数
n_records = len(data)
# TODO:被调查者的收入大于$50,000的人数
n_greater_50k = data['income'].isin(['>50K']).sum()
# TODO:被调查者的收入最多为$50,000的人数
n_at_most_50k = data['income'].isin(['<=50K']).sum()
# TODO:被调查者收入大于$50,000所占的比例
greater_percent = n_greater_50k / n_records *100
# 打印结果
print ("Total number of records: {}".format(n_records))
print ("Individuals making more than $50,000: {}".format(n_greater_50k))
print ("Individuals making at most $50,000: {}".format(n_at_most_50k))
print ("Percentage of individuals making more than $50,000: {:.2f}%".format(greater_percent))
Total number of records: 45222
Individuals making more than $50,000: 11208
Individuals making at most $50,000: 34014
Percentage of individuals making more than $50,000: 24.78%
准备数据
在数据能够被作为输入提供给机器学习算法之前,它经常需要被清洗,格式化,和重新组织 - 这通常被叫做预处理。幸运的是,对于这个数据集,没有我们必须处理的无效或丢失的条目,然而,由于某一些特征存在的特性我们必须进行一定的调整。这个预处理都可以极大地帮助我们提升几乎所有的学习算法的结果和预测能力。
获得特征和标签
income 列是我们需要的标签,记录一个人的年收入是否高于50K。 因此我们应该把他从数据中剥离出来,单独存放。
# 将数据切分成特征和对应的标签
income_raw = data['income']
features_raw = data.drop('income', axis = 1)
转换倾斜的连续特征
一个数据集有时可能包含至少一个靠近某个数字的特征,但有时也会有一些相对来说存在极大值或者极小值的不平凡分布的的特征。算法对这种分布的数据会十分敏感,并且如果这种数据没有能够很好地规一化处理会使得算法表现不佳。在人口普查数据集的两个特征符合这个描述:'capital-gain'和'capital-loss'。
运行下面的代码单元以创建一个关于这两个特征的条形图。请注意当前的值的范围和它们是如何分布的。
# 可视化 'capital-gain'和'capital-loss' 两个特征
vs.distribution(features_raw)
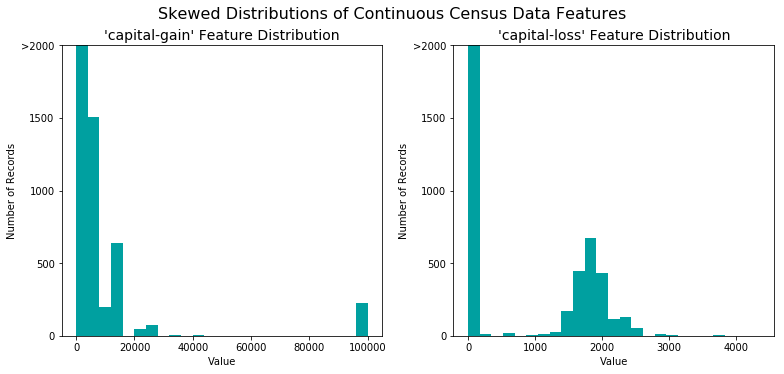
对于高度倾斜分布的特征如’capital-gain’和’capital-loss’,常见的做法是对数据施加一个对数转换,将数据转换成对数,这样非常大和非常小的值不会对学习算法产生负面的影响。并且使用对数变换显著降低了由于异常值所造成的数据范围异常。但是在应用这个变换时必须小心:因为0的对数是没有定义的,所以我们必须先将数据处理成一个比0稍微大一点的数以成功完成对数转换。
运行下面的代码单元来执行数据的转换和可视化结果。再次,注意值的范围和它们是如何分布的。
# 对于倾斜的数据使用Log转换
skewed = ['capital-gain', 'capital-loss']
features_raw[skewed] = data[skewed].apply(lambda x: np.log(x + 1))
# 可视化对数转换后 'capital-gain'和'capital-loss' 两个特征
vs.distribution(features_raw, transformed = True)
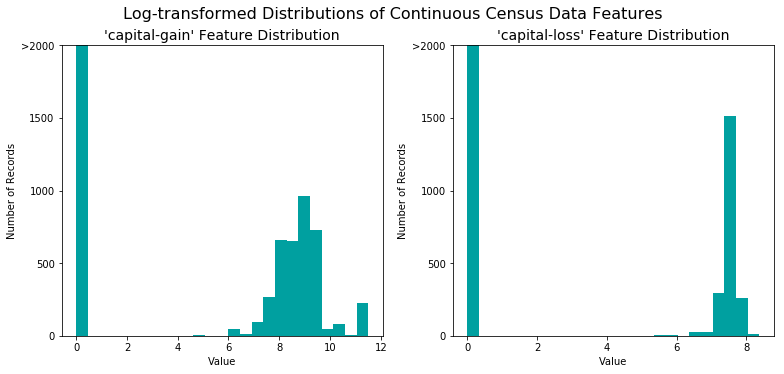
规一化数字特征
除了对于高度倾斜的特征施加转换,对数值特征施加一些形式的缩放通常会是一个好的习惯。在数据上面施加一个缩放并不会改变数据分布的形式(比如上面说的’capital-gain’ or ‘capital-loss’);但是,规一化保证了每一个特征在使用监督学习器的时候能够被平等的对待。注意一旦使用了缩放,观察数据的原始形式不再具有它本来的意义了,就像下面的例子展示的。
运行下面的代码单元来规一化每一个数字特征。将使用sklearn.preprocessing.MinMaxScaler来完成这个任务。
from sklearn.preprocessing import MinMaxScaler
# 初始化一个 scaler,并将它施加到特征上
scaler = MinMaxScaler()
numerical = ['age', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week']
features_raw[numerical] = scaler.fit_transform(data[numerical])
# 显示一个经过缩放的样例记录
display(features_raw.head(n = 1))

数据预处理
从上面的数据探索中的表中,可以看到有几个属性的每一条记录都是非数字的。通常情况下,学习算法期望输入是数字的,这要求非数字的特征(称为类别变量)被转换。转换类别变量的一种流行的方法是使用独热编码方案。独热编码为每一个非数字特征的每一个可能的类别创建一个_“虚拟”_变量。例如,假设someFeature有三个可能的取值A,B或者C,。我们将把这个特征编码成someFeature_A, someFeature_B和someFeature_C.
此外,对于非数字的特征,我们需要将非数字的标签'income'转换成数值以保证学习算法能够正常工作。因为这个标签只有两种可能的类别(“<=50K"和”>50K"),我们不必要使用独热编码,可以直接将他们编码分别成两个类0和1,在下面的代码单元中你将实现以下功能:
- 使用
pandas.get_dummies()对'features_raw'数据来施加一个独热编码。 - 将目标标签
'income_raw'转换成数字项。- 将"<=50K"转换成
0;将">50K"转换成1。
- 将"<=50K"转换成
# TODO:使用pandas.get_dummies()对'features_raw'数据进行独热编码
features = pd.get_dummies(features_raw)
# TODO:将'income_raw'编码成数字值
income = income_raw.replace(['<=50K', '>50K'], [0, 1])
# 打印经过独热编码之后的特征数量
encoded = list(features.columns)
print ("{} total features after one-hot encoding.".format(len(encoded)))
# 移除下面一行的注释以观察编码的特征名字
print(encoded)
103 total features after one-hot encoding.
[‘age’, ‘education-num’, ‘capital-gain’, ‘capital-loss’, ‘hours-per-week’, ‘workclass_ Federal-gov’, ‘workclass_ Local-gov’, ‘workclass_ Private’, ‘workclass_ Self-emp-inc’, ‘workclass_ Self-emp-not-inc’, ‘workclass_ State-gov’, ‘workclass_ Without-pay’, ‘education_level_ 10th’, ‘education_level_ 11th’, ‘education_level_ 12th’, ‘education_level_ 1st-4th’, ‘education_level_ 5th-6th’, ‘education_level_ 7th-8th’, ‘education_level_ 9th’, ‘education_level_ Assoc-acdm’, ‘education_level_ Assoc-voc’, ‘education_level_ Bachelors’, ‘education_level_ Doctorate’, ‘education_level_ HS-grad’, ‘education_level_ Masters’, ‘education_level_ Preschool’, ‘education_level_ Prof-school’, ‘education_level_ Some-college’, ‘marital-status_ Divorced’, ‘marital-status_ Married-AF-spouse’, ‘marital-status_ Married-civ-spouse’, ‘marital-status_ Married-spouse-absent’, ‘marital-status_ Never-married’, ‘marital-status_ Separated’, ‘marital-status_ Widowed’, ‘occupation_ Adm-clerical’, ‘occupation_ Armed-Forces’, ‘occupation_ Craft-repair’, ‘occupation_ Exec-managerial’, ‘occupation_ Farming-fishing’, ‘occupation_ Handlers-cleaners’, ‘occupation_ Machine-op-inspct’, ‘occupation_ Other-service’, ‘occupation_ Priv-house-serv’, ‘occupation_ Prof-specialty’, ‘occupation_ Protective-serv’, ‘occupation_ Sales’, ‘occupation_ Tech-support’, ‘occupation_ Transport-moving’, ‘relationship_ Husband’, ‘relationship_ Not-in-family’, ‘relationship_ Other-relative’, ‘relationship_ Own-child’, ‘relationship_ Unmarried’, ‘relationship_ Wife’, ‘race_ Amer-Indian-Eskimo’, ‘race_ Asian-Pac-Islander’, ‘race_ Black’, ‘race_ Other’, ‘race_ White’, ‘sex_ Female’, ‘sex_ Male’, ‘native-country_ Cambodia’, ‘native-country_ Canada’, ‘native-country_ China’, ‘native-country_ Columbia’, ‘native-country_ Cuba’, ‘native-country_ Dominican-Republic’, ‘native-country_ Ecuador’, ‘native-country_ El-Salvador’, ‘native-country_ England’, ‘native-country_ France’, ‘native-country_ Germany’, ‘native-country_ Greece’, ‘native-country_ Guatemala’, ‘native-country_ Haiti’, ‘native-country_ Holand-Netherlands’, ‘native-country_ Honduras’, ‘native-country_ Hong’, ‘native-country_ Hungary’, ‘native-country_ India’, ‘native-country_ Iran’, ‘native-country_ Ireland’, ‘native-country_ Italy’, ‘native-country_ Jamaica’, ‘native-country_ Japan’, ‘native-country_ Laos’, ‘native-country_ Mexico’, ‘native-country_ Nicaragua’, ‘native-country_ Outlying-US(Guam-USVI-etc)’, ‘native-country_ Peru’, ‘native-country_ Philippines’, ‘native-country_ Poland’, ‘native-country_ Portugal’, ‘native-country_ Puerto-Rico’, ‘native-country_ Scotland’, ‘native-country_ South’, ‘native-country_ Taiwan’, ‘native-country_ Thailand’, ‘native-country_ Trinadad&Tobago’, ‘native-country_ United-States’, ‘native-country_ Vietnam’, ‘native-country_ Yugoslavia’]
混洗和切分数据
现在所有的 类别变量 已被转换成数值特征,而且所有的数值特征已被规一化。和我们一般情况下做的一样,我们现在将数据(包括特征和它们的标签)切分成训练和测试集。其中80%的数据将用于训练和20%的数据用于测试。然后再进一步把训练数据分为训练集和验证集,用来选择和优化模型。
运行下面的代码单元来完成切分。
# 导入 train_test_split
from sklearn.model_selection import train_test_split
# 将'features'和'income'数据切分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, income, test_size = 0.2, random_state = 0,
stratify = income)
# 将'X_train'和'y_train'进一步切分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=0,
stratify = y_train)
# 显示切分的结果
print ("Training set has {} samples.".format(X_train.shape[0]))
print ("Validation set has {} samples.".format(X_val.shape[0]))
print ("Testing set has {} samples.".format(X_test.shape[0]))
Training set has 28941 samples.
Validation set has 7236 samples.
Testing set has 9045 samples.
评价模型性能
在这一部分中,我们将尝试四种不同的算法,并确定哪一个能够最好地建模数据。四种算法包含一个天真的预测器 和三个你选择的监督学习器。
评价方法和朴素的预测器
CharityML通过他们的研究人员知道被调查者的年收入大于$50,000最有可能向他们捐款。因为这个原因CharityML对于准确预测谁能够获得$50,000以上收入尤其有兴趣。这样看起来使用准确率作为评价模型的标准是合适的。另外,把没有收入大于$50,000的人识别成年收入大于$50,000对于CharityML来说是有害的,因为他想要找到的是有意愿捐款的用户。这样,我们期望的模型具有准确预测那些能够年收入大于$50,000的能力比模型去查全这些被调查者更重要。我们能够使用F-beta score作为评价指标,这样能够同时考虑查准率和查全率:
F β = ( 1 + β 2 ) ⋅ p r e c i s i o n ⋅ r e c a l l ( β 2 ⋅ p r e c i s i o n ) + r e c a l l F_{\beta} = (1 + \beta^2) \cdot \frac{precision \cdot recall}{\left( \beta^2 \cdot precision \right) + recall} Fβ=(1+β2)⋅(β2⋅precision)+recallprecision⋅recall
尤其是,当 β = 0.5 \beta = 0.5 β=0.5 的时候更多的强调查准率,这叫做F 0.5 _{0.5} 0.5 score (或者为了简单叫做F-score)。
问题 1 - 天真的预测器的性能
通过查看收入超过和不超过 $50,000 的人数,发现多数被调查者年收入没有超过 $50,000。如果简单地预测说*“这个人的收入没有超过 $50,000”,就可以得到一个 准确率超过 50% 的预测。这样甚至不用看数据就能做到一个准确率超过 50%。这样一个预测被称作是天真的。通常对数据使用一个天真的预测器*是十分重要的,这样能够帮助建立一个模型表现是否好的基准。 使用下面的代码单元计算天真的预测器的相关性能。将你的计算结果赋值给'accuracy', ‘precision’, ‘recall’ 和 'fscore',这些值会在后面被使用,请注意这里不能使用scikit-learn,你需要根据公式自己实现相关计算。
如果选择一个无论什么情况都预测被调查者年收入大于 $50,000 的模型,那么这个模型在验证集上的准确率,查准率,查全率和 F-score是多少?
#不能使用scikit-learn,需要根据公式自己实现相关计算。
# 假设不管三七二十一,预测结果为1(“这个人的收入没有超过 $50,000”)
beta = 0.5
ac = (y_val==1).sum()
#TODO: 计算准确率
accuracy = ac / len(y_val)
# TODO: 计算查准率 Precision
precision = ac / len(y_val)
# TODO: 计算查全率 Recall
recall = ac / ac
# TODO: 使用上面的公式,设置beta=0.5,计算F-score
fscore = (1 + beta**2)*(precision * recall)/(beta ** 2 * precision + recall)
# 打印结果
print ("Naive Predictor on validation data: \n \
Accuracy score: {:.4f} \n \
Precision: {:.4f} \n \
Recall: {:.4f} \n \
F-score: {:.4f}".format(accuracy, precision, recall, fscore))
Naive Predictor on validation data:
Accuracy score: 0.2478
Precision: 0.2478
Recall: 1.0000
F-score: 0.2917
监督学习模型
问题 2 - 模型应用
你能够在 scikit-learn 中选择以下监督学习模型
- 高斯朴素贝叶斯 (GaussianNB)
- 决策树 (DecisionTree)
- 集成方法 (Bagging, AdaBoost, Random Forest, Gradient Boosting)
- K近邻 (K Nearest Neighbors)
- 随机梯度下降分类器 (SGDC)
- 支撑向量机 (SVM)
- Logistic回归(LogisticRegression)
从上面的监督学习模型中选择三个适合我们这个问题的模型,并回答相应问题。
模型1
模型名称
回答:决策树
描述一个该模型在真实世界的一个应用场景。(你需要为此做点研究,并给出你的引用出处)
回答:决策树在经济决策中的应用 https://www.ixueshu.com/document/4a0ebc8fedbed93f.html
这个模型的优势是什么?他什么情况下表现最好?
回答:优势:
①在相对短的时间内能够对大型数据源做出可行且效果良好的结果
②数据的预处理较少.其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性
情况:
③对非线性数据适应力强
这个模型的缺点是什么?什么条件下它表现很差?
回答:缺点:
①容易过拟合,记住数据而不是学习数据特征
情况:
②对于那些各类别样本数量不一致时,数据增益可能会偏向于样品数量多的一方
③数据缺失时,模型很难处理
根据我们当前数据集的特点,为什么这个模型适合这个问题。
回答:
①易于理解,我们现在是想要从人群中找出收入大于 $50,000 ,而当我们判断一个人是否收入大于 $50,000,就是看他的各种特征,比如:阶级、家庭情况、职业等,这符合我们人类的思维方法,而决策树也是通过这样的方法,判断一个人是否收入大于 $50,000
②高效,学习时间相对较短,方便后续调参,能快速投入使用
模型2
模型名称
回答:支撑向量机 (SVM)
描述一个该模型在真实世界的一个应用场景。(你需要为此做点研究,并给出你的引用出处)
回答:航空发电机故障判断https://www.ixueshu.com/document/8887643afa3103bf318947a18e7f9386.html
这个模型的优势是什么?他什么情况下表现最好?
回答:①持向量机能对非线性决策边界建模,又有许多可选的核函数。在面对过拟合时,支持向量机有着极强的稳健性,尤其是在高维空间中
这个模型的缺点是什么?什么条件下它表现很差?
回答:①对缺失数据敏感
②对非线性问题没有通用解决方案
根据我们当前数据集的特点,为什么这个模型适合这个问题。
回答:这个问题是不是线性决策,而且数据不大,总训练时间不会很长
模型3
模型名称
回答:集成算法中的(AdaBoost)
描述一个该模型在真实世界的一个应用场景。(你需要为此做点研究,并给出你的引用出处)
回答:AdaBoost算法在网络入侵检测中的研究 http://www.doc88.com/p-0418323006831.html
这个模型的优势是什么?他什么情况下表现最好?
回答:①当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单。
②不用担心过拟合
③简单,不用做特征筛选
这个模型的缺点是什么?什么条件下它表现很差?
回答:在Adaboost训练过程中,Adaboost会使得难于分类样本的权值呈指数增长,训练将会过于偏向这类困难的样本,导致Adaboost算法易受噪声干扰。此外,Adaboost依赖于弱分类器,而弱分类器的训练时间往往很长。
根据我们当前数据集的特点,为什么这个模型适合这个问题。
回答:①数据特征较多,有8个,而使用adaboost能不做特征筛选。
练习 - 创建一个训练和预测的流水线
为了正确评估选择的每一个模型的性能,创建一个能够帮助你快速有效地使用不同大小的训练集并在验证集上做预测的训练和验证的流水线是十分重要的。
你在这里实现的功能将会在接下来的部分中被用到。在下面的代码单元中,你将实现以下功能:
- 从
sklearn.metrics中导入fbeta_score和accuracy_score。 - 用训练集拟合学习器,并记录训练时间。
- 对训练集的前300个数据点和验证集进行预测并记录预测时间。
- 计算预测训练集的前300个数据点的准确率和F-score。
- 计算预测验证集的准确率和F-score。
# TODO:从sklearn中导入两个评价指标 - fbeta_score和accuracy_score
```python
from sklearn.metrics import fbeta_score, accuracy_score
def train_predict(learner, sample_size, X_train, y_train, X_val, y_val):
'''
inputs:
- learner: the learning algorithm to be trained and predicted on
- sample_size: the size of samples (number) to be drawn from training set
- X_train: features training set
- y_train: income training set
- X_val: features validation set
- y_val: income validation set
'''
results = {}
# TODO:使用sample_size大小的训练数据来拟合学习器
# TODO: Fit the learner to the training data using slicing with 'sample_size'
start = time() # 获得程序开始时间
learner = learner
learner.fit(X_train[:sample_size], y_train[:sample_size])
end = time() # 获得程序结束时间
# TODO:计算训练时间
results['train_time'] = end - start
# TODO: 得到在验证集上的预测值
# 然后得到对前300个训练数据的预测结果
start = time() # 获得程序开始时间
predictions_val = learner.predict(X_val)
predictions_train = learner.predict(X_train)
end = time() # 获得程序结束时间
# TODO:计算预测用时
results['pred_time'] = end - start
# TODO:计算在最前面的300个训练数据的准确率
results['acc_train'] = accuracy_score(y_train[:300], predictions_train[:300])
# TODO:计算在验证上的准确率
results['acc_val'] = accuracy_score(y_val[:300], predictions_val[:300])
# TODO:计算在最前面300个训练数据上的F-score
results['f_train'] = fbeta_score(y_train[:300], predictions_train[:300], beta = 0.5)
# TODO:计算验证集上的F-score
results['f_val'] = fbeta_score(y_val[:300], predictions_val[:300], beta = 0.5)
# 成功
print ("{} trained on {} samples.".format(learner.__class__.__name__, sample_size))
# 返回结果
return results
练习:初始模型的评估
在下面的代码单元中,您将需要实现以下功能:
- 导入你在前面讨论的三个监督学习模型。
- 初始化三个模型并存储在
'clf_A','clf_B'和'clf_C'中。- 使用模型的默认参数值,在接下来的部分中你将需要对某一个模型的参数进行调整。
- 设置
random_state(如果有这个参数)。
- 计算1%, 10%, 100%的训练数据分别对应多少个数据点,并将这些值存储在
'samples_1','samples_10','samples_100'中
注意:取决于你选择的算法,下面实现的代码可能需要一些时间来运行!
# TODO:从sklearn中导入三个监督学习模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import AdaBoostClassifier
# TODO:初始化三个模型
clf_A = DecisionTreeClassifier(random_state = 0)
clf_B = SVC(random_state = 0)
clf_C = AdaBoostClassifier(random_state = 0)
# TODO:计算1%, 10%, 100%的训练数据分别对应多少点
samples_1 = int(X_train.size*0.01)
samples_10 = int(X_train.size*0.1)
samples_100 = int(X_train.size*1)
# 收集学习器的结果
results = {}
for clf in [clf_A, clf_B, clf_C]:
clf_name = clf.__class__.__name__
results[clf_name] = {}
for i, samples in enumerate([samples_1, samples_10, samples_100]):
results[clf_name][i] = train_predict(clf, samples, X_train, y_train, X_val, y_val)
# 对选择的三个模型得到的评价结果进行可视化
vs.evaluate(results, accuracy, fscore)
DecisionTreeClassifier trained on 29809 samples.
DecisionTreeClassifier trained on 298092 samples.
DecisionTreeClassifier trained on 2980923 samples.
SVC trained on 29809 samples.
SVC trained on 298092 samples.
SVC trained on 2980923 samples.
AdaBoostClassifier trained on 29809 samples.
AdaBoostClassifier trained on 298092 samples.
AdaBoostClassifier trained on 2980923 samples.

提高效果
在这最后一节中,您将从三个有监督的学习模型中选择 最好的 模型来使用学生数据。你将在整个训练集(X_train和y_train)上使用网格搜索优化至少调节一个参数以获得一个比没有调节之前更好的 F-score。
问题 3 - 选择最佳的模型
基于你前面做的评价,用一到两段话向 CharityML 解释这三个模型中哪一个对于判断被调查者的年收入大于 $50,000 是最合适的。
回答:选择AdaBoost模型
①在评价指标上,虽然训练集中准确率和f_score不如决策树模型,但是我们最终选择的是泛化能力好的模型,而在测试集中,AdaBoost的准确率和f_score是最高的。
② AdaBoost训练时间稍微比决策树高一点(多0.87s),并远低于SVM模型,训练时间可以接
受
③ 最后一点, AdaBoost自带了特征选择(feature selection),只使用在数据集中发现有效的特征(feature)。这样就降低了分类时需要计算的特征数量,也在一定程度上解决了高维数据难以理解的问题,更好的预测出收入大于10,000人群的数量
问题 4 - 用通俗的话解释模型
用一到两段话,向 CharityML 用外行也听得懂的话来解释最终模型是如何工作的。你需要解释所选模型的主要特点。例如,这个模型是怎样被训练的,它又是如何做出预测的。避免使用高级的数学或技术术语,不要使用公式或特定的算法名词。
回答: adaboost算法的工作原理,打个比方,就是假设这里有一张试卷,你不知道不怎么做,然后你就找同学来帮你做,第一个同学做完后对答案,就走出考场,对下一个同学说自己哪里做错了,要小心一点,这样下一个同学做的时候,就会特别注意之前同学犯过错误的地方,然后以此循环,直到最后一个人做完。最后把大家集中起来,根据大家最后的结果,来模拟一个最好拟合训练集的模型。这个模型的优点是准确率高,不用担心模型没有学习到学习集的特征,完全记住数据。
练习:模型调优
调节选择的模型的参数。使用网格搜索(GridSearchCV)来至少调整模型的重要参数(至少调整一个),这个参数至少需尝试3个不同的值。你要使用整个训练集来完成这个过程。在接下来的代码单元中,你需要实现以下功能:
- 导入
sklearn.model_selection.GridSearchCV和sklearn.metrics.make_scorer. - 初始化你选择的分类器,并将其存储在
clf中。 - 设置
random_state(如果有这个参数)。 - 创建一个对于这个模型你希望调整参数的字典。
- 例如: parameters = {‘parameter’ : [list of values]}。
- 注意: 如果你的学习器有
max_features参数,请不要调节它! - 使用
make_scorer来创建一个fbeta_score评分对象(设置 β = 0.5 \beta = 0.5 β=0.5)。 - 在分类器clf上用’scorer’作为评价函数运行网格搜索,并将结果存储在grid_obj中。
- 用训练集(X_train, y_train)训练grid search object,并将结果存储在
grid_fit中。
注意: 取决于你选择的参数列表,下面实现的代码可能需要花一些时间运行!
# TODO:导入'GridSearchCV', 'make_scorer'和其他一些需要的库
from sklearn.model_selection import KFold, GridSearchCV
from sklearn.metrics import make_scorer
def fbeta_score_1(y_true, y_pred):
score = fbeta_score(y_true, y_pred, beta = 0.5)
return score
# TODO:初始化分类器
clf = AdaBoostClassifier()
# TODO:创建你希望调节的参数列表
parameters = {'base_estimator':[DecisionTreeClassifier(max_depth=2, min_samples_leaf=10, random_state = 0, min_samples_split = 5)],
'n_estimators': [i for i in range(60,90,10)], 'learning_rate':[i/10 for i in range(1,11)],
'algorithm':['SAMME', 'SAMME.R'], 'random_state': [0]}
# TODO:创建一个fbeta_score打分对象
cross_validator = KFold(n_splits = 3)
scorer = make_scorer(fbeta_score_1)
# TODO:在分类器上使用网格搜索,使用'scorer'作为评价函数
start = time()
grid_obj = GridSearchCV(clf, parameters, scoring = scorer, cv = cross_validator)
grid = grid_obj.fit(X_train, y_train)
# TODO:用训练数据拟合网格搜索对象并找到最佳参数
end = time()
# 得到estimator
best_clf = grid_obj.best_estimator_
best_clf_time = end - start
# 使用没有调优的模型做预测
predictions = (clf.fit(X_train, y_train)).predict(X_val)
best_predictions = best_clf.predict(X_val)
# 汇报调优后的模型
print ("best_clf\n------")
print (best_clf)
# 汇报调参前和调参后的分数
print ("\nUnoptimized model\n------")
print ("Accuracy score on validation data: {:.4f}".format(accuracy_score(y_val, predictions)))
print ("F-score on validation data: {:.4f}".format(fbeta_score(y_val, predictions, beta = 0.5)))
print ("\nOptimized Model\n------")
print ("Final accuracy score on the validation data: {:.4f}".format(accuracy_score(y_val, best_predictions)))
print ("Final F-score on the validation data: {:.4f}".format(fbeta_score(y_val, best_predictions, beta = 0.5)))
best_clf
——————
AdaBoostClassifier(algorithm=‘SAMME.R’,
base_estimator=DecisionTreeClassifier(class_weight=None, criterion=‘gini’, max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=10, min_samples_split=5,
min_weight_fraction_leaf=0.0, presort=False, random_state=0,
splitter=‘best’),
learning_rate=0.4, n_estimators=80, random_state=0)
Unoptimized model
——————
Accuracy score on validation data: 0.8648
F-score on validation data: 0.7443
Optimized Model
——————
Final accuracy score on the validation data: 0.8752
Final F-score on the validation data: 0.7669
问题 5 - 最终模型评估
你的最优模型在测试数据上的准确率和 F-score 是多少?这些分数比没有优化的模型好还是差?
注意:请在下面的表格中填写你的结果,然后在答案框中提供讨论。
结果:
| 评价指标 | 未优化的模型 | 优化的模型 |
|---|---|---|
| 准确率 | 0.8648 | 0.8752 |
| F-score | 0.7443 | 0.7669 |
回答: 优化后的模型比没有优化的模型高出了大约1.1%的准确率,f-score得分高出0.0226,优化后的模型比优化前的稍微好一点
特征的重要性
在数据上(比如这里使用的人口普查的数据)使用监督学习算法的一个重要的任务是决定哪些特征能够提供最强的预测能力。专注于少量的有效特征和标签之间的关系,能够更加简单地理解这些现象,这在很多情况下都是十分有用的。在这个项目的情境下这表示我们希望选择一小部分特征,这些特征能够在预测被调查者是否年收入大于$50,000这个问题上有很强的预测能力。
选择一个有 'feature_importance_' 属性的scikit学习分类器(例如 AdaBoost,随机森林)。'feature_importance_' 属性是对特征的重要性排序的函数。在下一个代码单元中用这个分类器拟合训练集数据并使用这个属性来决定人口普查数据中最重要的5个特征。
问题 6 - 观察特征相关性
当探索数据的时候,它显示在这个人口普查数据集中每一条记录我们有十三个可用的特征。
在这十三个记录中,你认为哪五个特征对于预测是最重要的,选择每个特征的理由是什么?你会怎样对他们排序?
回答: 顺序为特征1>特征2>特征3>特征4>特征5, 特征1,2,3与工作收入的相关程度比较大,所以排在前面
- 特征1:workclass, 企业家的收入会特别多
- 特征2:education_level,教育程度越高,平均薪资也会越高
- 特征3:occupation,职业领域不同,收入不同,比如高科技领域的人收入会比较高
- 特征4:age,一般来说有钱人都是成年人,特别是收入大于$50,000的
- 特征5:sex,福布斯2019全球富豪榜前10,只有1个是女的,推测与财富有关
练习 - 提取特征重要性
选择一个scikit-learn中有feature_importance_属性的监督学习分类器,这个属性是一个在做预测的时候根据所选择的算法来对特征重要性进行排序的功能。
在下面的代码单元中,你将要实现以下功能:
- 如果这个模型和你前面使用的三个模型不一样的话从sklearn中导入一个监督学习模型。
- 在整个训练集上训练一个监督学习模型。
- 使用模型中的
'feature_importances_'提取特征的重要性。
# TODO:导入一个有'feature_importances_'的监督学习模型
# TODO:在训练集上训练一个监督学习模型
model = AdaBoostClassifier(random_state = 0)
# TODO: 提取特征重要性
importances = best_clf.feature_importances_
# 绘图
vs.feature_plot(importances, X_train, y_train)
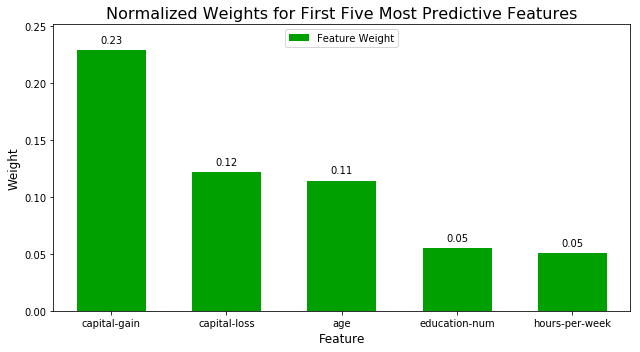
问题 7 - 提取特征重要性
观察上面创建的展示五个用于预测被调查者年收入是否大于$50,000最相关的特征的可视化图像。
这五个特征的权重加起来是否超过了0.5?
这五个特征和你在问题 6中讨论的特征比较怎么样?
如果说你的答案和这里的相近,那么这个可视化怎样佐证了你的想法?
如果你的选择不相近,那么为什么你觉得这些特征更加相关?
回答:权重加起来为0.63, 大于0.5, 与我回答的相比,我只有一个年龄是沾边的,captain-gain和captain-loss指风险资本投资 (包括买卖证券) 或出售资本财产所实现的利润或蒙受的损失,可以说是比较直观地说明了一个人是否收入大于50,000 , 如 果 一 个 人 的 c a p t a i n − g a i n 和 c a p t a i n − l o s s 都 没 有 50 , 000 ,如果一个人的captain-gain和captain-loss都没有50,000 ,如果一个人的captain−gain和captain−loss都没有50,000,那它的收入一般不超过50,000$的人(权重0.35),剩下的是工作时长和家庭情况,工作时长也是比较直观,假设每个人每小时赚的钱是一样的,那么工作越久,赚的钱也越多。而我的选择就有些比较虚,与工作不直接挂钩的,比如教育情况,年龄。
特征选择
如果只是用可用特征的一个子集的话模型表现会怎么样?通过使用更少的特征来训练,在评价指标的角度来看我们的期望是训练和预测的时间会更少。从上面的可视化来看,我们可以看到前五个最重要的特征贡献了数据中所有特征中超过一半的重要性。这提示我们可以尝试去减小特征空间,简化模型需要学习的信息。下面代码单元将使用你前面发现的优化模型,并只使用五个最重要的特征在相同的训练集上训练模型。
# 导入克隆模型的功能
from sklearn.base import clone
# 减小特征空间
X_train_reduced = X_train[X_train.columns.values[(np.argsort(importances)[::-1])[:5]]]
X_val_reduced = X_val[X_val.columns.values[(np.argsort(importances)[::-1])[:5]]]
# 在前面的网格搜索的基础上训练一个“最好的”模型
start = time()
clf_on_reduced = (clone(best_clf)).fit(X_train_reduced, y_train)
end = time()
reduced_time = end - start
# 做一个新的预测
reduced_predictions = clf_on_reduced.predict(X_val_reduced)
# 对于每一个版本的数据汇报最终模型的分数
print("Final Model trained on full data\n------")
print("Accuracy on validation data: {:.4f}".format(accuracy_score(y_val, best_predictions)))
print("F-score on validation data: {:.4f}".format(fbeta_score(y_val, best_predictions, beta = 0.5)))
print("spend time: {:.4f}".format(best_clf_time))
print("\nFinal Model trained on reduced data\n------")
print("Accuracy on validation data: {:.4f}".format(accuracy_score(y_val, reduced_predictions)))
print("F-score on validation data: {:.4f}".format(fbeta_score(y_val, reduced_predictions, beta = 0.5)))
print("spend time: {:.4f}".format(reduced_time))
Final Model trained on full data
————
Accuracy on validation data: 0.8752
F-score on validation data: 0.7669
spend time: 345.0182
Final Model trained on reduced data
————
Accuracy on validation data: 0.8495
F-score on validation data: 0.7238
spend time: 0.7035
问题 8 - 特征选择的影响
最终模型在只是用五个特征的数据上和使用所有的特征数据上的 F-score 和准确率相比怎么样?
如果训练时间是一个要考虑的因素,你会考虑使用部分特征的数据作为你的训练集吗?
回答: 减少了数据的模型与没有减少的相比,准确度少了4.06%,f-score少了0.0765,耗费时间上,网格搜索的模型耗时336.8117s,约为减少数据模型的608倍,如果把时间也考虑进去, 我会选用减少了数据的模型,毕竟这只是一个推送收入大于$50,000的人的广告的问题,我觉得准确率稍微低一点没有什么关系。
问题 9 - 在测试集上测试你的模型
终于到了测试的时候,记住,测试集只能用一次。
使用你最有信心的模型,在测试集上测试,计算出准确率和 F-score。
简述你选择这个模型的原因,并分析测试结果
#TODO test your model on testing data and report accuracy and F score
best_predictions = best_clf.predict(X_test)
print ("\nFinal Model\n------")
print ("Final accuracy score on the validation data: {:.4f}".format(accuracy_score(y_test, best_predictions)))
print ("Final F-score on the validation data: {:.4f}".format(fbeta_score(y_test, best_predictions, beta = 0.5)))
Final Model
————
Final accuracy score on the validation data: 0.8688
Final F-score on the validation data: 0.7548









