系统整体CPU使用率是多少? 每个CPU呢?
CPU负载并发程度? 单线程 多线程? 多进程?
那些应用程序/用户在使用CPU 使用了多少?
那个内核线程在使用CPU 使用了多少?
中断CPU 是多少
CPU 互联使用率是多少
用户 内核级别在CPU 上的调用路径
什么类型的停滞周期
谁测量 为什么测量 测量什么 如何测量
有多少CPU 可用 是核 还是硬件线程
CPU架构是单处理器还是多处理器
CPU缓存是多少 是共享缓存吗
CPU时钟是多少 是动态 可以加速吗 intel的超频加速 动态特性是在bios启用了吗?
bios 里面禁用了其他CPU 特性吗
CPU有什么性能bug吗
软件限制了CPU 使用资源吗?
CPU 绑定----
进程绑定: 进程只在某个cpu上跑
独占CPU:分出一组cpu 运行指定的进程; 提高cpu cache 效率
uptime :平均负载
vmstat:系统范围的CPU平均负载
mpstat:单个CPU统计信息
ps: 进程状态
top:进程、线程cpu使用
pidstat:每个进程的CPU用量
time:给一个命令计时,带CPU使用
perf:CPU 分析统计
linux 平均负载:不可中断的磁盘I/O 也计入平均负载---
---> 平均负载不能表示 CPU余量 以及饱和度
负载可能在CPU和磁盘间不断变化
最好使用vmstat mpstat 了解CPU负载
sar -P ALL 和mpstat -P ALL 一样
sar -u 和mpstat 1 一样
sar -q 包括运行队列长度和(vmstat 的r 列相同 ) 也包好平均负载
pidstat 按进程 线程打印CPU用量
#time md5sum 6.0.7.1.48319/update.v6.0.7.1.48319.bin
7c09d09ca9d24b7980f7049a1704ba32 6.0.7.1.48319/update.v6.0.7.1.48319.bin
real 0m0.334s 实际话费时间
user 0m0.298s user态时间
sys 0m0.026s 系统调用
剩余的 0.334-0.298-0.026 = 0.01 应该就是磁盘I/O等待了
time md5sum 6.0.7.1.48319/update.v6.0.7.1.48319.bin
7c09d09ca9d24b7980f7049a1704ba32 6.0.7.1.48319/update.v6.0.7.1.48319.bin
real 0m0.321s
user 0m0.299s
sys 0m0.021s
这次: 0.321-0.299-0.021=
perf 用来分析CPU 调用路径
perf stat 比如:perf stat -p xx ;
perf stat ls-l
perf stat -e instructions ls -l
perf stat
perf stat用于运行指令,并分析其统计结果。虽然perf top也可以指定pid,但是必须先启动应用才能查看信息。perf stat能完整统计应用整个生命周期的信息。
其使用如下:


perf stat [-e <EVENT> | --event=EVENT] [-a] <command>
perf stat [-e <EVENT> | --event=EVENT] [-a] — <command> [<options>]
-a, --all-cpus 显示所有CPU上的统计信息
-C, --cpu <cpu> 显示指定CPU的统计信息
-c, --scale scale/normalize counters
-D, --delay <n> ms to wait before starting measurement after program start
-d, --detailed detailed run - start a lot of events
-e, --event <event> event selector. use 'perf list' to list available events
-G, --cgroup <name> monitor event in cgroup name only
-g, --group put the counters into a counter group
-I, --interval-print <n>
print counts at regular interval in ms (>= 10)
-i, --no-inherit child tasks do not inherit counters
-n, --null null run - dont start any counters
-o, --output <file> 输出统计信息到文件
-p, --pid <pid> stat events on existing process id
-r, --repeat <n> repeat command and print average + stddev (max: 100, forever: 0)
-S, --sync call sync() before starting a run
-t, --tid <tid> stat events on existing thread idView Code
perf -a -g -F 998 sleep 10
perf top
perf record -f -g -a -e xxxx sleep 10 跟踪事件
perf top常用选项有:
-e <event>:指明要分析的性能事件。
-p <pid>:Profile events on existing Process ID (comma sperated list). 仅分析目标进程及其创建的线程。
-k <path>:Path to vmlinux. Required for annotation functionality. 带符号表的内核映像所在的路径。
-K:不显示属于内核或模块的符号。
-U:不显示属于用户态程序的符号。
-d <n>:界面的刷新周期,默认为2s,因为perf top默认每2s从mmap的内存区域读取一次性能数据。
-g:得到函数的调用关系图。
perf 参考:perllog
进程绑定: 可以绑定在一个或者多个CPU 上
独占CPU组: 不允许其他进程使用, 只能此进程使用CPU
选择I/O尺寸:
I/O的开销有:初始化缓冲区 系统调用 上下文切换 内核数据分配 进程权限 限制
映射地址到设备 内核代码 驱动代码I/O
并发:并行
并发执行不同的应用程序、应用程序内的函数也可以并发执行
多进程 多线程实现 函数并发
基于事件的并发,也是一种方案
哈希表:用一张锁的hash表对大量的数据结构的锁做数目优化
1、所有的数据只设定一个mutex, 并发的访问会有锁的竞争, 等待也会超时。需要该锁的线程也会串行执行而不是并发执行
2、每个数据都有一个mutex, 减小锁的竞争互斥范围,但是锁会有存储开销 创建销毁也有开销
哈希表是一种折中方案!!
散列表+一个链表 解决
对于频繁的短时I/O 频繁切换上下文会消耗CPU 增加应用程序的延时
perf sched 可以观察 运行线程 等待线程所花费的时间指标
系统调用:
系统调用: I/O 、锁 、 以及xx syscall
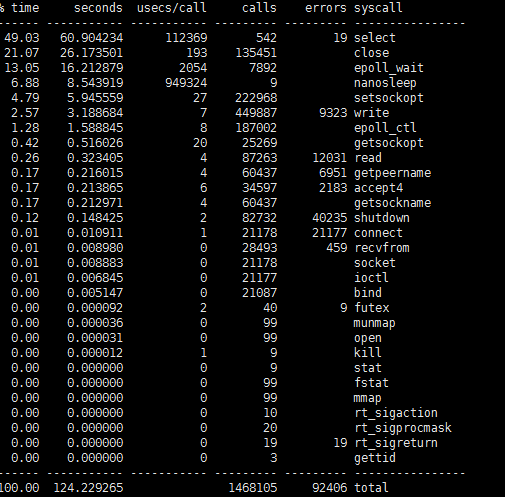
strace -ttt -T -p pid
strace -c -p pid
cpu的使用率 饱和度
错误等erron
网络:
延时:同一主机: 延时0.05ms
局域网有线: 10g:0.2ms 1g网口:0.6ms
wifi局域网:3ms
RSS: 接收端缩放,NIC网卡支持多队列
RPS:接收数据包分发
netstat -s 查找高流量的重传以及乱序包
netstat -i 检测接口错误计数
ifconfig 接口报文总数 丢弃报文数 错误数等
netstat -i -s -r
sar -n DEV 接口统计信息
-n EDEV 网络接口错误信息
-n IP ip 数据包统计
-n EIP
-n TCP
-n ETCP
-n SOCK
观察工具:
系统级别
vmstat mpstat tcpdump snoop stap
iostat sar perf
计数器 跟踪
ps top 进程级别 strace gdb
数据来源:
进程级别计数: /proc
系统级别计数: /proc, /sys
设备驱动和调试信息: /sys
进程级跟踪: ptrace
性能计数器: perf_event
网络跟踪:tcpdump
系统级别跟踪: ftrace kprobes tracepoints
ls /proc/89958/
attr auxv clear_refs comm cpuset environ fd io maps mountinfo mountstats numa_maps oom_score pagemap
root smaps statm syscall wchan
autogroup cgroup cmdline coredump_filter cwd exe fdinfo limits mem mounts net
oom_adj oom_score_adj personality sched stat status task
limits: 实际的资源限制
maps:内存映射
sched: CPU调度统计
stat: 进程状态和统计 包含总的CPU 内存使用情况
statm:以页为单位的内存使用统计总结
status: stat statm的信息
task: 任务统计目录 多线程---
/proc # ls -Fd [a-z]*
acpi/ cmdline crypto dri/ filesystems ioports kcore kpagecount mdstat mounts@ pagetypeinfo self@ swaps timer_list vmallocinfo
buddyinfo config.gz devices driver/ fs/ ipmi/ key-users kpageflags meminfo mpt/ partitions slabinfo sys/ tty/ vmstat
bus/ consoles diskstats execdomains interrupts irq/ keys loadavg misc mtrr sched_debug softirqs sysrq-trigger uptime zoneinfo
cgroups cpuinfo dma fb iomem kallsyms kmsg locks modules net@ scsi/ stat sysvipc/ version
cpuinfo:
diskstats:
interrupts:
loadavg:
meminfo:
net/dev:
net/tcp:
schedstat:
self:
slabinfo:
stat:
zoneinfo:
http代理服务器(3-4-7层代理)-网络事件库公共组件、内核kernel驱动 摄像头驱动 tcpip网络协议栈、netfilter、bridge 好像看过!!!!
但行好事 莫问前程
--身高体重180的胖子










