ZoFS(SOSP'19)
1. 背景(Background)
NVM设备具有低延迟、字节级寻址能力,可以直接在用户态访问,这使得大量研究者开始研究基于NVM的用户态文件系统。但是现有的用户态NVM文件系统不能在用户态对元数据进行直接控制,从而不能够充分发挥DCPMM的性能,例如:
- Aerie:Aeire通过进程间通信(inter-process communications,IPCs)来保证元数据的更新,大概流程是:用户态库发送元数据更新请求至内核进程,由内核进行请求的检查与元数据的更新。这会带来较大的IPC开销。
- Strata:Strata将用户的元数据更新记录到一个NVM日志中,然后由内核进行日志项检测与处理(或称为消化,digestion),这会导致二次更新开销。
然而,用户态文件系统对元数据进行直接控制面临几大挑战:
-
挑战 1:如何确保各个文件的权限? 由于用户程序也位于用户态,因此用户程序可以轻松绕过权限检测,从而发动恶意攻击。
-
挑战 2:如何防止程序修改元数据? 如果在用户态可以直接对元数据发起修改,那么应用程序的各种BUG可以轻松地污染元数据,从而使得文件系统崩溃。
围绕这些挑战,作者提出解决思路:
- 思路 1: 作者希望用户态文件系统在使用NVM空间前先进行进程的权限检测。
- 思路 2: 作者利用Intel MPK(Memory Protection Key)对元数据修改进行保护。
2. 动机(Motivation)
2.1 观察1:低效的用户态NVMFS
现有的用户态文件系统不能在用户态对元数据做直接更新,因此存在较大的开销(见1. 背景)。因此,基于这个观察,本工作要提出一种用户态文件系统,它能够在用户态进行元数据的直接修改。
2.2 观察2:文件权限与隔离措施
文件系统通过有限的系统调用与应用程序隔离开,从而确保访问权限的正确性。但为了能够在用户态进行文件系统元数据修改从而充分发挥NVM的性能,作者调研了多个真实系统环境下应用程序涉及文件的权限。细节不再赘述。观察得出的结论为:应用程序的文件权限基本相同,且少有修改(applications tend to store files with similar permissions that are rarely changed)。
基于这个观察,作者试图将所有相同权限的文件分成一组(因为他们占大多数),然后让文件系统的用户态库对该组文件有完全的控制权。如此一来,就能达到思路 1的目标:在用户态程序使用这些文件前,用户态文件系统检测该组文件的权限即可。
至于为什么不是以单个文件为粒度进行NVM空间管理,而是以这种组的方式进行管理,文章并未做出解释,博主猜测可能原因如下:
- 以组为粒度进行权限检测的方式更为高效且更容易实现;
- 以文件为粒度可能造成有过多细小的组,由于MPK大小所限,这样会导致单个进程可操作的文件数量大大受限(因为ZoFS会用到MPK对这些文件进行保护,因此单个进程最多只能操作15个组,我们在后面会讲到);
3. ZoFS设计与实现(Design & Implementation)
3.1 Coffer
Coffer,金库,可以理解为前面提到的相同权限文件分组,不过这里有一点变化,Coffer是一系列权限相同的NVM页面的容器,这些页面被用于存放文件数据。
Coffer主要组成为:Root Page,用于承载Coffer的元数据(非文件系统元数据,例如:Inode等);Root File,一个根文件,也作为Coffer的入口。如果Root File 为常规文件,那么Coffer只存该文件相关的NVM页面,如果Root File 为目录文件,那么该目录下的所有子文件的NVM页面都可以存在相同的Coffer中。
如果子文件的权限与目录文件权限不同,那么子文件就不会与目录文件存在同一个Coffer中,此时,由目录文件的Dentry记录Cross-Coffer Reference将用于记录子文件所在的Coffer路径,见下图圈出来的部分)

Coffer是Treasury进行NVM空间管理的重要组成结构,Treasury可以理解为一个用户态文件系统架构,可以类比[FUSE文件系统](5分钟搞懂用户空间文件系统FUSE工作原理 - 知乎 (zhihu.com))架构。
3.2 Treasury
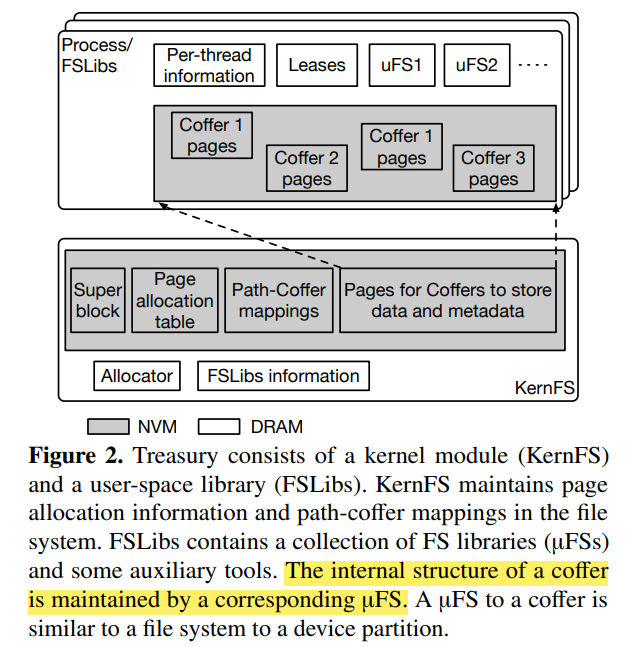
Treasury,财政部,用于管理Coffer,并且提供用户态接口。由两部分组成:内核模块KernFS、用户态库FSLibs。其中,KernFS用于管理NVM空间:记录哪个NVM页面属于哪个Coffer、维护Coffer的元数据(Coffer的路径、Coffer的类别)等。KernFS视Coffer为黑盒子,它并不知道Coffer内存了什么或者文件的数据到底是如何组织的。
FSLibs是一系列文件系统库的合集,这些文件系统库又被称为uFSs,每种uFS可以管理某种类别的Coffer。本文后续设计的uFS即为ZoFS。uFS对Coffer的关系就好比一个文件系统对设备分区的关系(磁盘逻辑分成4个区,每个区可以采用不同的文件系统管理;NVM介质被划分为多个Coffer,每个Coffer也可以由不同的uFS管理)。
3.2.1 KernFS
-
Coffer管理:Treasury给每个Coffer的
Root Page一个Coffer-ID,用以唯一标识Coffer,并利用持久化哈希表(Path-Coffer Mappings)来保存Coffers。其中,哈希表的Key为Coffer的路径、值是Coffer-ID。这样一来,当上层发起路径请求时,可以通过查表快速找到对应的Coffer; -
NVM空间管理:Treasury采用两级分配方式:首先分配一组NVM页面至Coffer,再由Coffer分配页面来保存数据和元数据。其页面分配情况由Page Allocation Table记录。具体Page Allocation Table结构如下图所示,在此不做赘述。
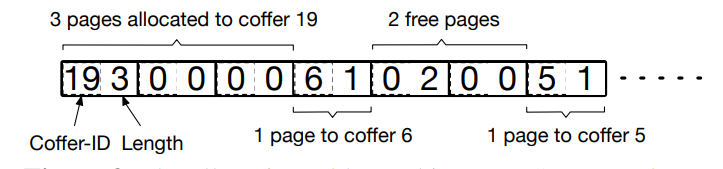
3.2.2 FSLibs
FSLibs是用户态文件系统库(uFSs)。通过预加载uFS库(.so),应用可以不用重新编译就能使用uFS。下图显示了FSLib在Treasury中的架构:
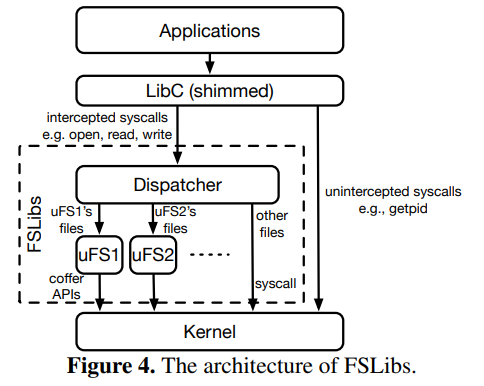
- 系统调用截胡:作者修改了glibc库,截胡了
write、open等系统调用。被截胡的系统调用通过Dispatcher分发给不同的uFSs。为了区分文件是内核文件系统还是用户态文件系统,需要将文件系统路径与挂载点对比,如果是相对路径,则把该路径展开为绝对路径再进行对比。如果传入的是句柄,就通过句柄映射表进行辨别。 - 句柄映射表(FD mapping table):为了区分用户态文件系统句柄与内核态文件系统句柄,Treasury在用户态维护了一个映射表,该映射表记录了被应用使用的句柄是属于用户态文件系统还是内核态文件系统。
- 软链接实现:把软链接文件指向的链接发给Dispatcher,递归该过程即可。但文章说到其他内核态文件系统的指向基于FSLibs文件的软链接存在问题,这里还不是很清楚存在什么问题。
3.3 保护与隔离
3.3.1 避免恶意写入
KernFS以Coffer为粒度将NVM页面映射到用户态,此时,KernFS将申请的Coffer中所有页面利用MPK区域进行标记(例如都标记为Region 0),示意图如下:
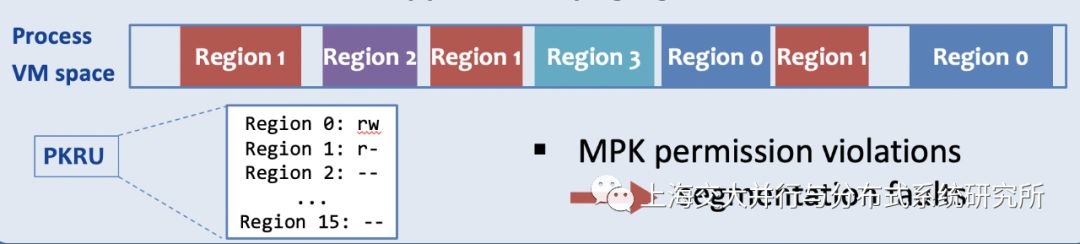
这些区域(Region)在PKRU中最初都标记为不可访问。当用户态文件系统库想要访问一个Coffer时,它先修改PKRU寄存器,打开对该Coffer的访问权限。在修改完毕之后,其又会马上修改PKRU,关闭对该Coffer的访问权限。通过这种方式,只有在用户态文件系统库执行的时候,Coffer才可以被修改。而当应用程序中的bug踩到Coffer内存时,会由于MPK的保护产生Segmentation fault,防止其破坏Coffer中的结构。(参考SOSP 2019—SJTU-IPADS的集体见闻(Day-3),博主由于知识能力有限,难以用自己的语言表达出来)
3.3.2 返回错误值和错误隔离
- 优雅地返回错误值:当FSLibs访问到无效内存时,程序会因为Segmentation fault崩掉,有一个方法是在关键路径上做地址检查,但这会降低系统性能,于是,Treasury利用
sigsetjump、siglongjump以及SIGSEGV信号处理机制来保证错误后能够返回错误值而不是使程序崩溃:在FSLibs的函数入口调用sigsetjump,然后再SIGSEGV的handler中调用siglongjump回到sigsetjump位置,然后返回相应的错误值。 - 错误隔离:uFS应该保证在任何时刻,每个线程最多只能访问一个Coffer,如此一来,对其他Coffer的恶意访问将会被MPK拒绝,从而避免错误传递。对于进程而言,可能有多个Coffer映射到该进程,对这些Coffer的访问可仅通过一条
WRPKRU指令完成。注意,这里最多只有15个Coffer能够被同时映射到进程中,因为只有15个MPK区域是有效的(上图展示了16个区域,和这里描述的不太一样,可能是实现不太相同)。
3.3.3 元数据安全性
简单来说就是下面三种情况:
-
情况 1:如果修改的metadata只在单一Coffer内,则不会引起问题,这与传统文件系统一致;
-
情况 2:如果修改的metadata涉及多个Coffer,那么,如果一个线程跟随错误的metadata访问到另一个Coffer,那么MPK会抛出错误(完成错误隔离),否则见情况 3;
-
情况 3:如果受害线程访问到目标Coffer,还需要检查待访问文件路径与Coffer路径的一致性;
3.4 ZoFS
ZoFS的设计中规中矩,主要贡献还是在于Coffer和Treasury,这里简单描述下:
3.4.1 数据及元数据管理
- 目录文件:两层哈希表结构
- 普通文件:类似Ext4的结构
- 特殊文件:一个4KB页面即可
3.4.2 分配器
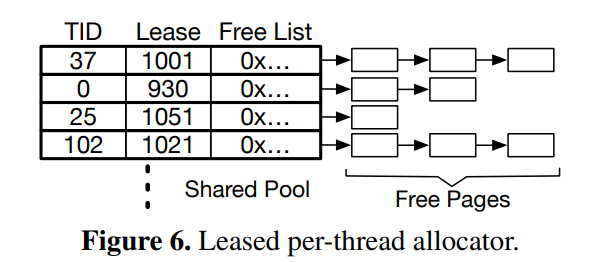
ZoFS用Lease Lock设计实现了基于Free List的NVM页面分配器,能够实现并发快速页面分配。个人觉得中规中矩。
3.4.3 一致性与恢复
ZoFS采用Lazy Consistency的方法进行错误恢复(类似fsck的方式),但是值得说明的是,ZoFS没有保证数据的原子更新。
4. 评估(Evaluation)
4.1 Microbenchmarks-FxMark
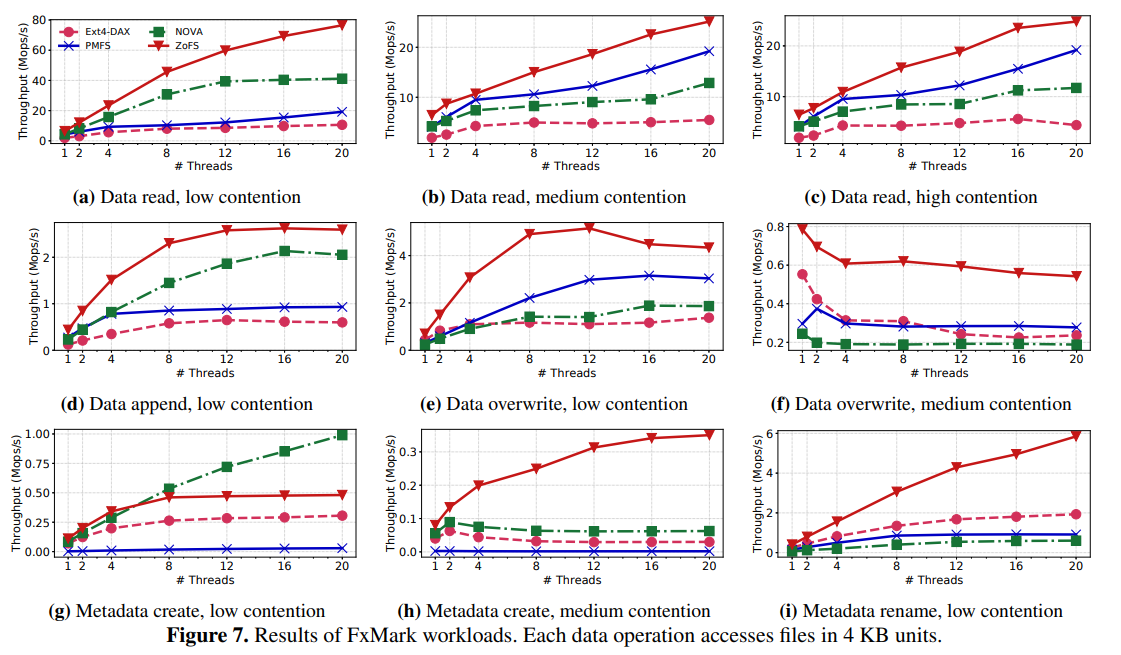
其中,最值得研究的是图 7(g),该Workload的工作模式为:不同的线程在不同的目录下创建文件。此时,ZoFS性能不及NOVA,文章说这是由于他们的Coffer的页面扩充函数竞争所致。
接着,利用图7(e)的Workload做了一个分解实验展示性能的提升:
各项目的含义如下:
-
ZoFS: ZoFS文件系统
-
ZoFS-sysempty: ZoFS的变体,在文件写入前发送空的系统调用
-
xx-noindex: 文件系统不更新索引(由于存在覆盖写,需要大批量调整树结构)
-
xx-nocache: 文件系统利用
ntstore绕过Cache写 -
ZoFS-kwrite: ZoFS的变体,在内核态写
-
PMFS: PMFS文件系统
-
NOVA: NOVA文件系统
-
NOVAi: NOVA变体,避免CoW更新(原地更新还慢一点吗?)
下图的结果充分说明了:用户态文件系统相较内核态在性能上的优越性

4.2 Macrobenchmarks-Filebench


不多说,ZoFS全是最牛的那一个。
4.3 Real-World应用
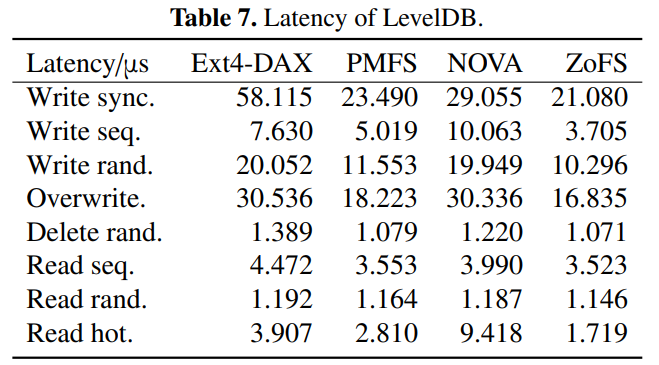
4.3.1 LevelDB
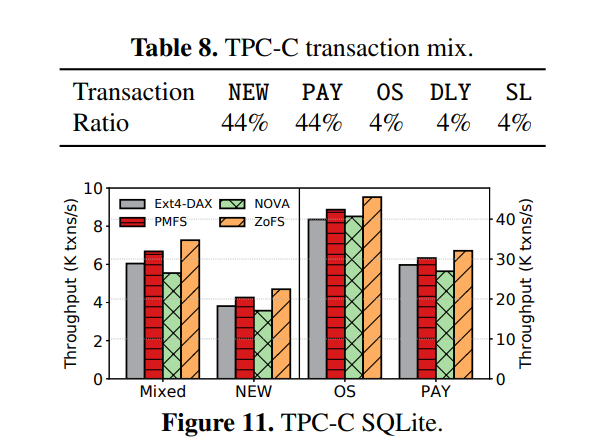
4.3.2 TPC-C SQLite
4.4 最差情况性能展示
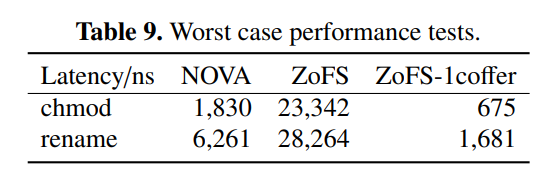
这里文章做了两组微基准测试:
- 不断更改文件的权限(
chmod) - 不断更改文件的名字(
rename)
ZoFS-1coffer代表不做Coffer的分裂(即,不同权限的页面也能保存在同一个Coffer中,只存在一个Coffer)。
结果表明,ZoFS的Cross-Coffer操作(Coffer分裂)会带来较大的开销,所以尽可能让文件的权限都不变吧。
4.5 恢复与一致性测试
- 一致性测试: 一致性测试也是Hand-Craft的,即作者给出一个场景,然后说明ZoFS能够成功防御这种场景。
- 恢复测试: 恢复1000个2MB文件要花20多s,用户态花5s,内核态花15s,这开销属实有点大……
总结
本工作着眼于NVM用户态文件系统的元数据更新问题,提出Coffer、Treasury用户态文件系统新架构:将具有相同权限的NVM页面聚集在一起形成Coffer,并通过Treasury进行管理。同时,本文利用MPK对在用户态直接修改元数据进行保护,有效缓解了Stray Write、避免了错误传播。
不过,该工作个人感觉并没有针对NVM硬件特性进行独到的设计,也许该设计能够适用于所有能够将页面直接映射到用户态的存储设备。有关更多NVM文件系统的设计与实现博主将在未来的时间慢慢解读。最近写博客的动力实在不太大,更新较慢请多多包涵。OK,开始起飞🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫🛫










