情景一:
将程序提交到集群,即执行spark-submit命令时时,出现Compression codec com.hadoop.compression.lzo.LzoCodec not found. 或 Class com.hadoop.compression.lzo.LzoCodec not found
[root@myhadoop spark-yarn]$
bin/spark-submit \
--class com.spark.WordCount \
--master yarn \
WordCount.jar \
/input \
/output
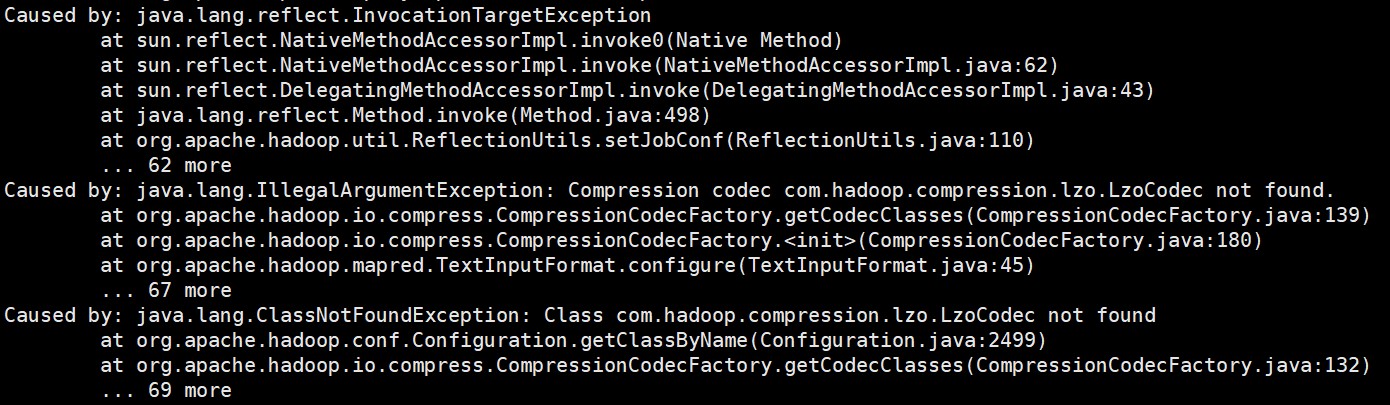
原因:Spark on Yarn会默认使用Hadoop集群配置文件设置编码方式,但是Spark在自己的spark-yarn/jars包里面没有找到支持lzo压缩的jar包,所以报错。
解决方案一:拷贝lzo的包到/opt/module/spark-yarn/jars目录
[root@myhadoop common]$
cp /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar /opt/module/spark-yarn/jars
再执行spark-submit命令
(3)解决方案二:在执行命令的时候指定lzo的包位置
[root@myhadoop spark-yarn]$
bin/spark-submit \
--class com.spark.WordCount \
--master yarn \
--driver-class-path /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar \
WordCount.jar \
/input \
/output
情景二:
在本地,即在idea中连接集群中hive时,出现Compression codec com.hadoop.compression.lzo.LzoCodec not found. 或 Class com.hadoop.compression.lzo.LzoCodec not found
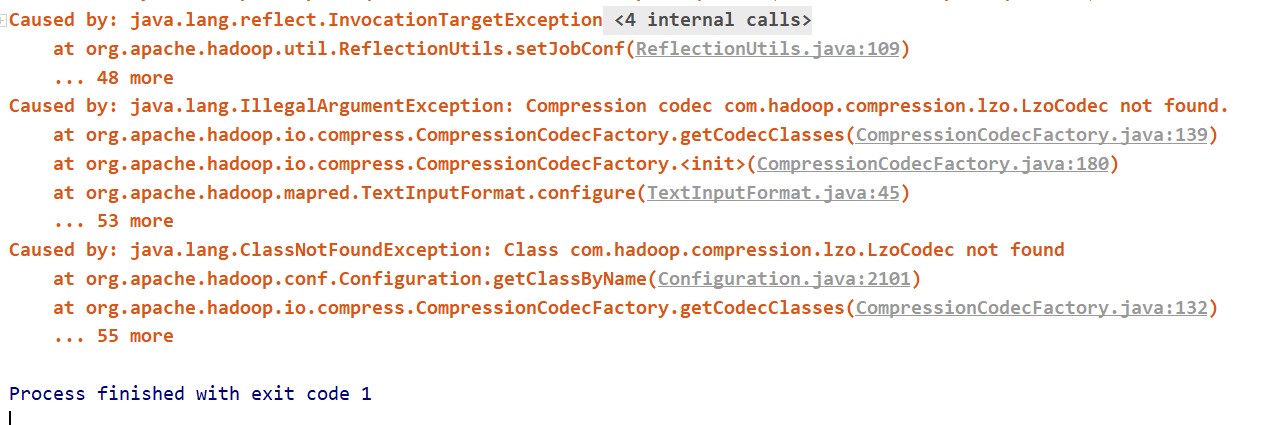
原因:在idea中连接hive时,要将集群中hive和hadoop相关的配置文件(hive-site.xml、hdfs-site.xml、yarn-site.xml和core-site.xml)拷贝到项目的resours文件夹中。而core-site.xml中指定了压缩相关的配置,但在projec中找不到相关的类,所以报错。
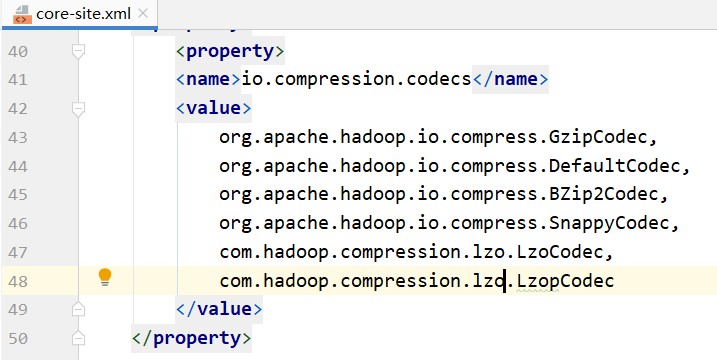
解决方案:不使用相关配置,即注释掉相关配置即可。