一、实验目的:
- 利用 LeNet-5 实现手写数字识别
二、实验环境:
-
Win 10 + Visual Studio Code + Python 3.6.6
-
CUDA 11.3 + cuDNN 8.2.1
-
Pytorch 1.10.0
-
torchvision 0.11.1
-
numpy 1.14.3 + mkl
-
matplotlib 2.2.2
三、实验理论知识——LeNet-5
1. 背景
1998年计算机科学家Yann LeCun等提出的LeNet5采用了基于梯度的反向传播算法对网络进行有监督的训练,Yann LeCun在机器学习、计算机视觉等都有杰出贡献,被誉为卷积神经网络之父。LeNet5网络通过交替连接的卷积层和下采样层,将原始图像逐渐转换为一系列的特征图,并且将这些特征传递给全连接的神经网络,以根据图像的特征对图像进行分类。感受野是卷积神经网络的核心,卷积神经网络的卷积核则是感受野概念的结构表现。学术界对于卷积神经网络的关注,也正是开始于LeNet5网络的提出,并成功应用于手写体识别。同时,卷积神经网络在语音识别、物体检测、人脸识别等应用领域的研究也逐渐开展起来。
2. 网络架构
LeNet-5共有7层(不包括输入层),每层包含不同数量的可训练参数和连接数,整体网络架构如下图所示:
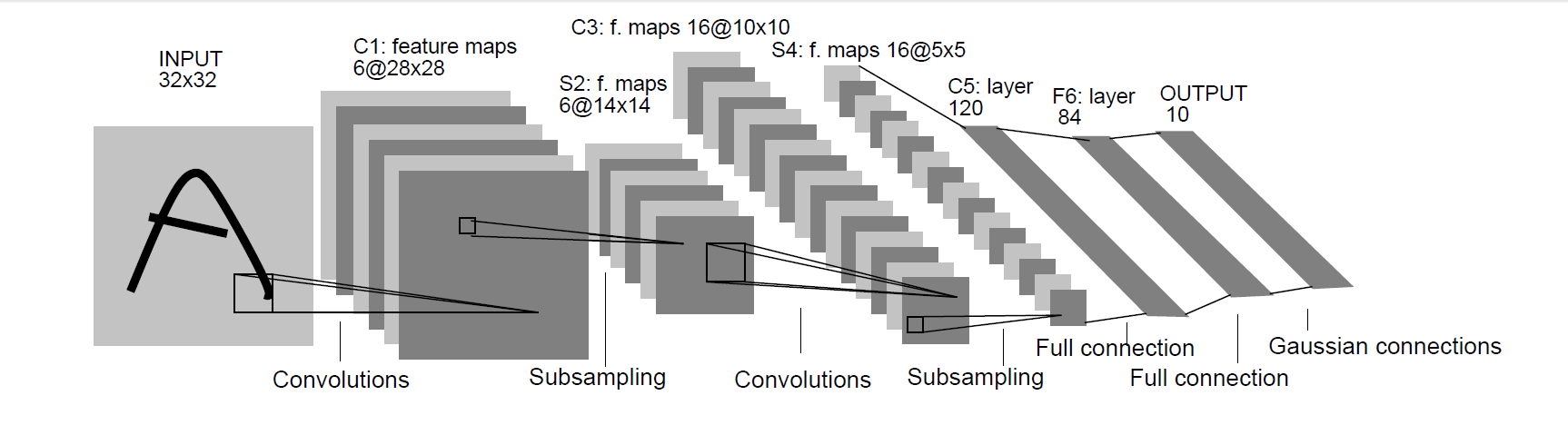
2.1 C1卷积层
输入图像尺寸:1 × 32 × 32
卷积核大小:5 × 5
卷积核种类:6
输出图像尺寸:6 × 28 × 28
可训练参数:(5 × 5 + 1) × 6 = 156(共6个卷积核,每个卷积核包含5 × 5 = 25个一般参数加一个可训练的偏置参数)
连接数:(5 × 5 + 1) × 6 × 28 × 28 = 122304(6个Feature Map分别与其对应的输入图像中的5 × 5像素加一个偏置之间存在连接)
说明:输入图像为单通道的灰度图,大小为32 × 32,经过6个卷积核卷积后生成6张Feature Map,分别包含了经过C1层提取出来的不同特征,输出图像大小为28 × 28。
C1层的连接结构如下所示:
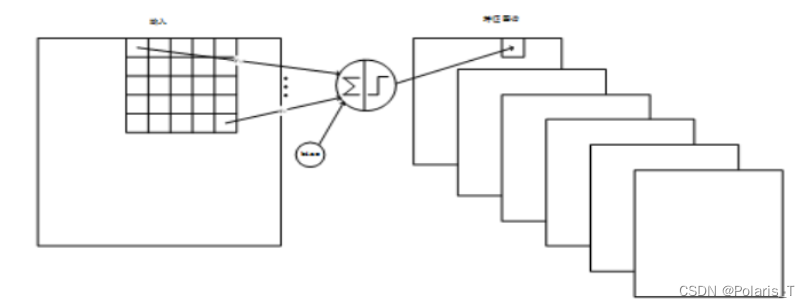
2.2 S2池化层
输入图像尺寸:6 × 28 × 28
采样核大小:2 × 2
采样步长:2
池化方式:最大池化
激活函数:sigmoid
输出图像尺寸:6 × 14 × 14
输出图像尺寸:28 × 28
连接数:(2 × 2 + 1) × 14 × 14 × 6 = 5880(6个输出图像分别与其对应的输入图像中的2 × 2像素加一个偏置之间存在连接)
说明:输入图像为6张Feature Map,大小为28 × 28,经过步长为2,采样核为2 × 2的最大池化后生成6张下采样图,输出图像大小为14 × 14。根据图像局部相关性的原理可知,对图像进行下采样,可以在减少数据处理量的同时保留有用信息。
S2层的连接结构如下所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kKpLDypo-1656297527167)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20211212101744459.png)]](https://file.cfanz.cn/uploads/png/2022/06/28/4/36G7G0823K.png)
2.3 C3卷积层
输入图像尺寸:6 × 14 × 14
卷积核大小:5 × 5
卷积核种类:16
输出图像尺寸:16 × 10 × 10
可训练参数:6 × (3 × 5 × 5 + 1) + 6 × (4 × 5 × 5 + 1) + 3 × (4 × 5 × 5 + 1) + 1 × (6 × 5 × 5 + 1) = 1516
连接数:10 × 10 × 1516 = 151600(6个Feature Map分别与其对应的输入图像中的5×5像素加一个偏置之间存在连接)
说明:C3的前6个Feature Map分别与S2层的第0 1 2, 第1 2 3, …, 第5 0 1个Feature Map相连接,后面6个Feature Map分别与S2层的第0 1 2 3, 第1 2 3 4, …, 第5 0 1 2个Feature Map相连接,后面3个Feature Map分别与S2层部分不相连的4个Feature Map相连接,最后一个Feature Map与S2层的所有Feature Map相连。所以共有6 × (3 × 5 × 5 + 1) + 6 × (4 × 5 × 5 + 1) + 3 × (4 × 5 × 5 + 1) + 1 × (6 × 5 × 5 + 1) = 1516个参数。而图像大小为10 × 10,所以共有151600个连接。
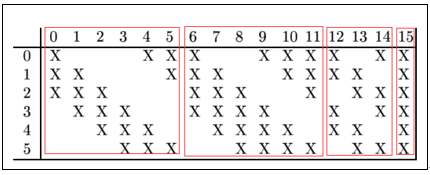
2.4 S4池化层
输入图像尺寸:16 × 10 × 01
采样核大小:2 × 2
采样步长:2
池化方式:最大池化
激活函数:sigmoid
输出图像尺寸:16 × 5 × 5
连接数:16 × (2 × 2 + 1) × 5 × 5 = 2000(16个输出图像分别与其对应的输入图像中的2 × 2像素加一个偏置之间存在连接)
说明:S4池化层的作用方式和结果与S2层类似,不再赘述。
2.5 C5卷积层
输入图像尺寸:16 × 5 × 5
卷积核大小:5 × 5
卷积核种类:120
输出图像尺寸:120 × 1 × 1
可训练参数:120 × (16 × 5 × 5 + 1) = 48120
连接数:120 × (16 × 5 × 5 + 1) = 48120(120个Feature Map分别与其对应的输入图像中的5×5像素加一个偏置之间存在连接)
说明:输入图像是16张大小为5 × 5的图,而卷积核大小为5 × 5,所以卷积后形成的图的大小为1 × 1。得到的120个卷积结果图每个都与上一层的16个图相连,所以共有120 × (16 × 5 × 5 + 1) = 48120个参数,同样有48120个连接。
2.6 FC6全连接层
输入:120 × 1 × 1
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置
激活函数:tanh
输出:84 × 1 × 1
可训练参数:84 × (120 + 1) = 10164
说明:FC6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,每个符号的比特图的黑白色对应于一个编码。
2.7 FC7全连接层
输入:84 × 1 × 1
输出:10 × 1
连接数:84 × 10 = 840
说明:Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设
x
x
x是上一层的输入,
y
y
y是RBF的输出,则RBF输出的计算方式是:
y
i
=
∑
j
(
x
j
−
w
i
j
)
2
y_i = \sum_{j}(x_j-w_{ij})^2
yi=j∑(xj−wij)2
上式
w
i
j
w_{ij}
wij的值由
i
i
i的比特图编码确定,
i
i
i从0到9,
j
j
j取值从0到83。RBF输出的值越接近于0,则越接近于
i
i
i,即越接近于
i
i
i的ASCII编码图,表示当前网络输入的识别结果是字符
i
i
i。该层有84x10=840个参数和连接。
四、实验步骤
-
配置实验环境
-
下载MNIST数据集
-
根据LeNet-5的网络结构编写代码
-
利用训练集训练模型
-
绘制第一个epoch的损失下降曲线
-
在测试集上验证模型的预测准确性
五、实验结果
我设定的超参数如下:
- 学习率 lr = 0.01
- 动量因子 momentum = 0.9
- 遍历训练集10次 epochs = 10
- 每次训练的批大小为64张图片 train_batch_size = 64
- 每次测试的批大小为1024张图片 test_batch_size = 1024
说明:为了在较大程度上复现原文,我编写的网络结构基本上遵循了原文的设定。根据LeCun的论文原文,LeNet-5网络中的第五层不是全连接层,但目前主流的方法是将其视为全连接层处理;此外,最后一个输出层那里我用nn.Linear()简化了原文中采用的径向基RBF函数。
第1次迭代:训练误差从2.30降低到0.20左右,测试集预测准确率为93.42%:
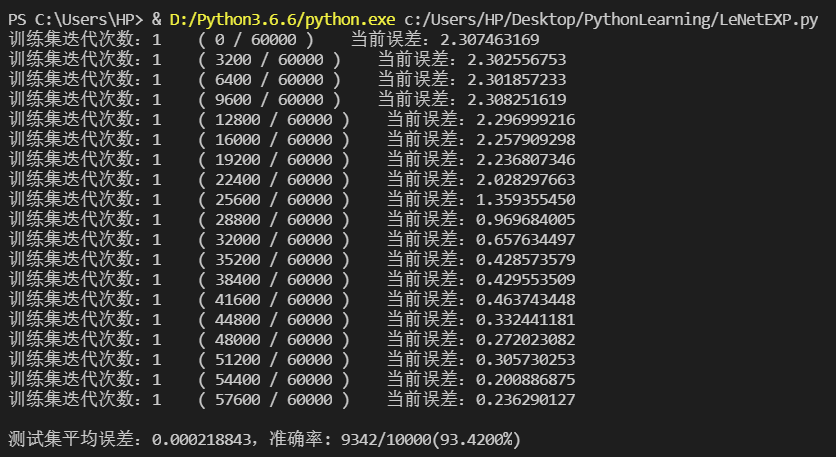
第1次迭代的训练误差曲线如下:
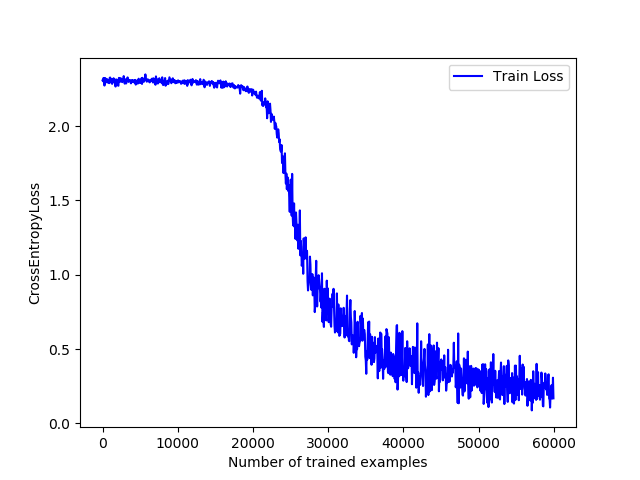
可以明显发现,得到的误差下降曲线并不是非常令人满意。误差在训练到20000个样本之后才开始有显著的下降,且对于后面的30000个样本,误差开始出现比较明显的上下波动。
分析网络结构,我认为该现象是由于采用SGD梯度下降法+激活函数为sigmoid+train_batch_size稍小导致的。
第2次迭代:训练误差从0.25降低到0.05左右,测试集预测准确率为97.45%:

再经过若干次迭代…
第10次迭代:训练误差从0.16降低到0.02左右,测试集预测准确率为98.70%:

分析:总体而言,经过这10轮的迭代训练,LeNet模型的预测准确率已经可以达到98.70%,且误差可以降到0.02左右。但是值得注意的有两个情况:
1.在经过两三轮的训练后,此后每轮迭代中的误差虽然都很小,但并没有进一步降低到下一个数量级,而是在某个小值附近波动,这似乎表明模型并没有进一步从训练中学到新的东西。
2.预测准确率从一开始的93.42%上升到第10轮训练后的98.70%,提高确实是提高了,但是经过尝试发现,即使再增加几个epoch的训练,准确率也并不会有明显的进一步提升,初步分析我觉得应该是激活函数的缘故,导致神经网络的表达能力受到了限制。
六、案例分类预测
在训练完LeNet-5模型后,我保存了模型,然后利用另一个Python程序利用训练好的模型对于MNIST测试集中的前128张具体图像进行了手写数字识别的检测,实验结果如下:
训练集中前128张图像的集合可视化图:
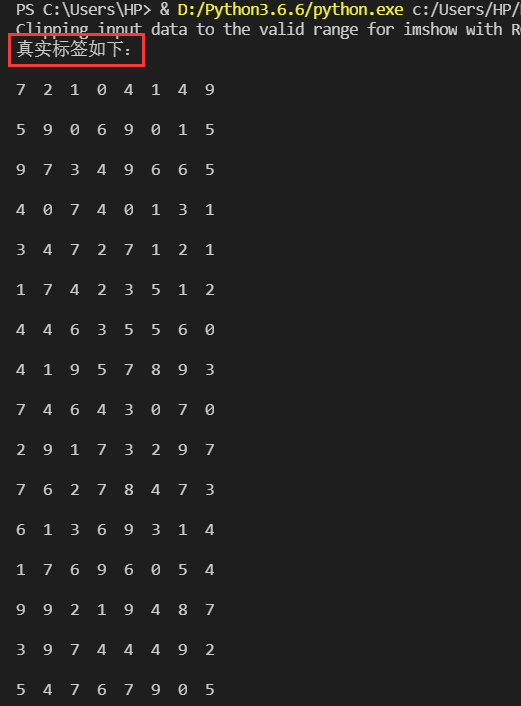
这批图像的真实标签:
这批图像的LeNet-5预测标签:
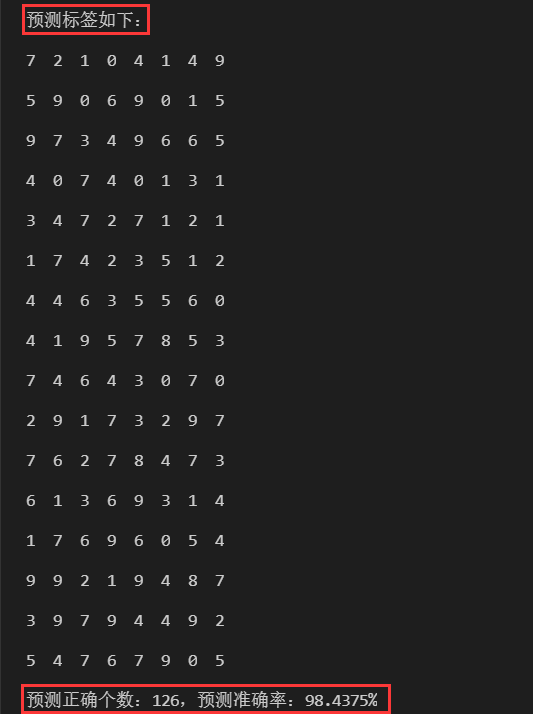
最终正确分类126/128张图片,分类准确率为98.4375%,准确率还是比较高的。
七、对比实验
根据上文所述,我遵循LeCun原文构建出的LeNet-5网络似乎分类准确率并没有达到一个很高的水准,因此我尝试着改变网络中激活函数的类型然后进行了对比实验。
我将两个池化层后面的激活函数由sigmoid换成了ReLU,然后又把第二个全连接层的激活函数由tanh换成了ReLU,其余结构不变。
第1次迭代训练及测试集验证准确率的结果如下:
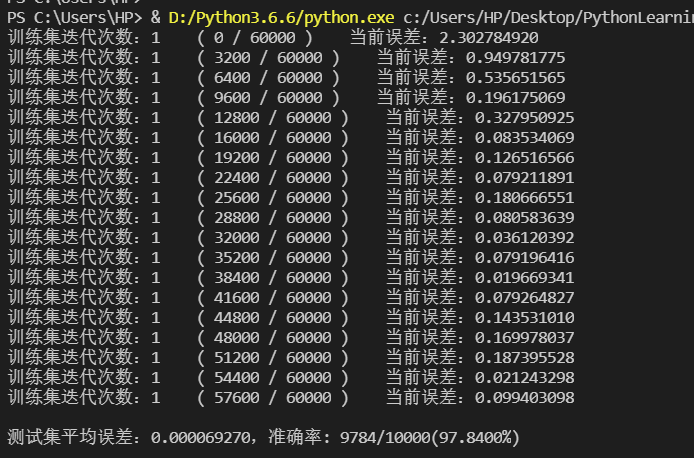
第1次迭代训练的误差下降曲线如下:
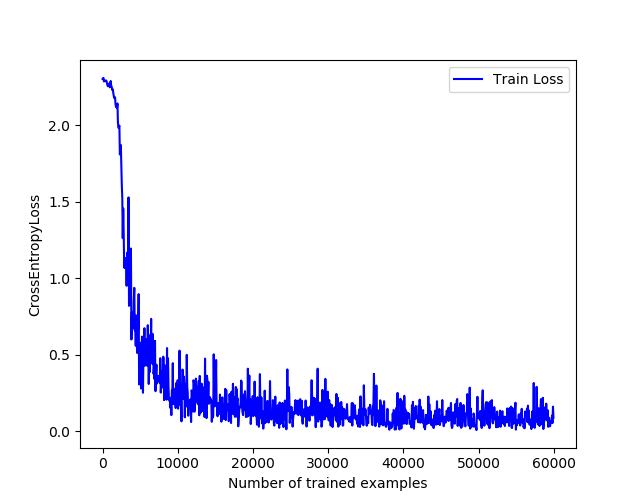
可以发现,相比于使用sigmoid作为激活函数而言,在ReLu的激励下第一个epoch训练的误差曲线会变得比较漂亮,一开始就呈现显著下降趋势,到后面虽有些上下波动(SGD的缘故),但仍旧比之前采用sigmoid的波动小了不少。
第9次迭代训练及测试集验证准确率的结果如下:
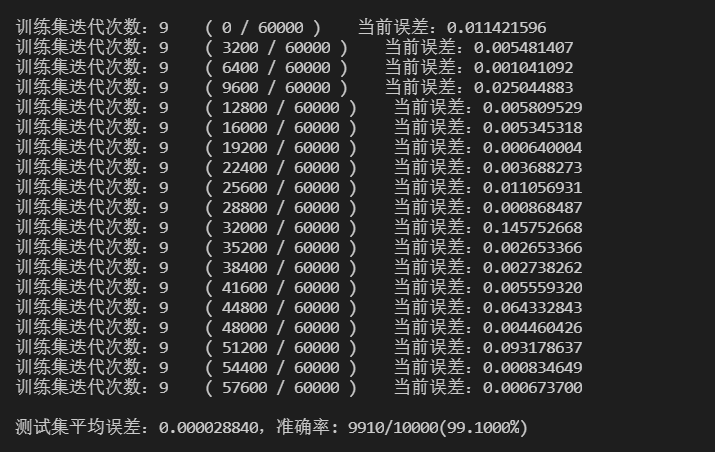
不难看出,当采用了ReLU作为激活函数后,只在第1个epoch训练结束后便能达到接近98.00%的准确率,而当训练到第9个epoch时,准确率已经上升到了99.10%,这说明ReLU函数对于训练神经网络的效果确实有很大的提升。
查阅资料后,可以归纳出ReLU有以下几点优势(相比sigmoid和tanh而言):
- 相比Sigmoid和tanh,ReLU摒弃了复杂的计算(幂运算),提高了运算速度
- 对于深层的网络而言,Sigmoid和tanh函数反向传播的过程中,饱和区域非常平缓,接近于0,容易出现梯度消失的问题,而Relu的梯度大多数情况下是常数,有助于解决深层网络的收敛问题
- ReLU会使一部分神经元的输出为0,造就网络的稀疏性,减少了参数的相互依存关系,缓解了过拟合问题的发生
- Relu拥有生物上的合理性:它是单边的,相比sigmoid和tanh,更符合生物神经元的特征。ReLU更容易学习优化。因为其分段线性性质,导致其前传,后传,求导都是分段线性。而传统的sigmoid函数,由于两端饱和,在传播过程中容易丢弃信息
八、探究学习率及训练批次大小对分类准确率的影响
1. 学习率对分类准确率的影响
为了能够使得梯度下降法有较好的性能,我们需要把学习率的值设定在合适的范围内。学习率过小,会极大降低收敛速度,增加训练时间;学习率过大,可能导致参数在最优解两侧来回振荡,导致网络难以收敛甚至无法收敛。
为了探究学习率对本次实验图像分类结果的影响,我保持其他超参数不变(控制变量),将lr分别设置为0.001,0.005,0.01,0.05,0.1并分别记录了不同lr下的测试集准确率从第1个epoch到第10个epoch的变化,结果如下:
| 学习率 | 0.001 | 0.005 | 0.01 | 0.05 | 0.1 |
|---|---|---|---|---|---|
| 测试集准确率 | 11.35% → 93.61% | 76.11% → 98.31% | 93.42% → 98.70% | 95.95% → 98.80% | 97.65% → 98.56% |
分析实验过程可知,对于LeNet网络而言,若学习率设置得过小(如0.001),会导致网络的loss下降非常慢,容易陷入过拟合的局面,具体体现在第1轮epoch的测试集准确率非常低;在此基础上稍微增大学习率至0.005,就可以使准确率在一开始就获得很大的提升;设置学习率为0.01,从头至尾的准确率都已经能达到90%以上;设置学习率为0.05,可以看到准确率有了进一步提升;设置学习率为0.1,基础准确率进一步提高,但对于后面的每一个epoch而言,准确率并不会得到太大的提升了。
综上,在本实验中选取lr = 0.01比较合适。
2. 训练批次大小对分类准确率的影响
为了探究训练批次大小对本次实验图像分类结果的影响,我保持其他超参数不变(控制变量),将train_batch_size分别设置为32,64,128,256,512并分别记录了不同train_batch_size下的测试集准确率从第1个epoch到第10个epoch的变化,结果如下:
| 训练批次大小 | 32 | 64 | 128 | 256 | 512 |
|---|---|---|---|---|---|
| 测试集准确率 | 96.28% → 98.49% | 93.42% → 98.70% | 75.92% → 98.18% | 11.35% → 97.24% | 11.35% → 94.81% |
当batch size较小时,收敛速度似乎较快。当batch size较大时,好处是跑完一次epoch所需的训练批次数减少,并且在一定范围内batch size提高后,其确定的下降方向越准,引起训练震荡越小,但是大的batch size会导致收敛速度变慢。
如下图所示,在第1个epoch下,train_batch_size取32时需要大约10000张训练图片才能收敛,train_batch_size取64时需要大约20000张训练图片才能收敛,而当我把train_batch_size取到128时需要大约40000张训练图片才能收敛:
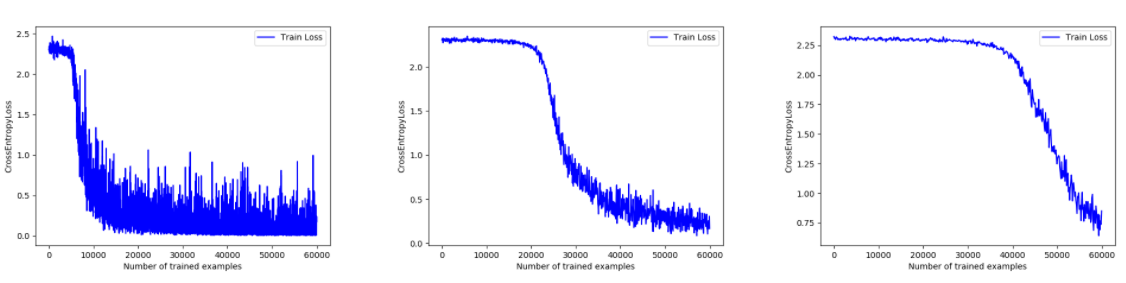
显然,batch size不能盲目增大。比如,可以感受到当batch size取到256时我的电脑运算速度比取64时慢了一些。此外,可以发现在大的batch size下测试集分类准确率稍有下降。这是应该是因为epoch不够多,在同样的epoch数下参数更新变少了,因此需要更多的迭代次数才能达到和小batch一样的准确率。
综上,在本实验中选取train_batch_size = 64比较合适。
CV第三次上机实验源码+数据










