"IT有得聊”是机械工业出版社旗下IT专业资讯和服务平台,致力于帮助读者在广义的IT领域里,掌握更专业、更实用的知识与技能,快速提升职场竞争力。 点击蓝色微信名可快速关注我们!

机器学习的概念与基本术语Machine Learning01
机器学习的概念
人类在成长、生活过程中积累了很多的历史与经验。人类定期地对这些经验进行“归纳”,获得了生活的“规律”。当人类遇到未知的问题或者需要对未来进行“推测”的时候,人类使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作。例如,我们经常听到的俗语“朝霞不出门,晚霞行千里”、“瑞雪兆丰年”等,都体现了人类的智慧。人类所具有的最独特创造力在于可以通过已有经验与常识进行学习,学习是人类具有的一种重要智能行为,因此具备学习能力是人类的一个极其重要的特征。然而,至今对学习的机理尚不清楚。究竟什么是学习,长期以来却众说纷纭。社会学家、逻辑学家、心理学家和计算机学家都有着各自的看法,有些观点甚至差别较大。H. A. Simon认为,学习是一个系统对环境的适应性变化,使得系统在下一次完成同样或类似的任务时更为有效。而R. S. Michalski认为,学习是构造或修改对于所经历事物的表示。从事专家系统研制的人们则认为学习是知识的获取。这些观点各有侧重,第一种观点强调学习的外部行为效果,第二种则强调学习的内部过程,而第三种主要是从知识工程的实用性角度出发的。
随着科学技术的发展,人们开始探索如何制造智能机器来替代人的繁复的智力劳动,并且在某些方面已经取得了巨大成功。然而,机器不是人,它不具备人的思维、学习创造能力。一个不具有学习能力的智能机器很难称得上是一个真正的智能机器,但是以往的智能机器都普遍缺少学习的能力。例如,它们遇到错误时不能自我校正;不会通过经验改善自身的性能;不会自动获取和发现所需要的知识。它们的推理仅限于演绎而缺少归纳,因此至多只能够证明已存在事实、定理,而不能发现新的定理、定律和规则等。随着人工智能的深入发展,这些局限性表现得愈加突出。如何使机器具备智能,使机器可以模拟人的大脑思维,可以像人一样地思考问题、学习新知识,就成为急需解决和发展的科学问题。正是在这种情形下,机器学习(Machine Learning,ML)逐渐成为人工智能领域的核心研究内容之一。
现在针对机器学习的应用已遍及人工智能领域的各个分支,如专家系统、自动推理、自然语言理解、模式识别、计算机视觉、智能机器人、生物信息学等领域。在这些研究中,如何获取知识成为突出的瓶颈,人们试图采用机器学习的方法加以克服。
机器学习是一门多领域交叉学科,其理论基础涉及概率论、统计学、逼近论、凸分析、最优化理论和计算复杂度理论等,研究如何使机器具备智能,使机器可以模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。这里所说的“机器”,指的就是计算机;现在是电子计算机,以后还可能是中子计算机、光子计算机或神经计算机等。机器学习是人工智能的核心,是使机器具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。目前,如何使机器具备拟人化的学习,进行更深层次的理解工作,还有很多问题有待探索和解决。
一般而言,机器学习的研究主要是从生理学、认知科学的角度出发,理解人类的学习过程,从而建立人类学习过程的计算模型或认知模型,并发展成各种学习理论和学习方法。在此基础上,研究通用的学习算法,进行理论上的分析,建立面向任务的具有特定应用的学习系统。但至今还没有统一的“机器学习”的定义,而且也很难给出一个公认的和准确的定义。
Langley(1996年)给出的定义是“机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”(Machine learning is a science of the artificial. The field’s main objects of study are artifacts, specifically algorithms that improve their performance with experience)。
汤姆·米切尔(Tom Mitchell)在1997年出版的著作《Machine Learning》中给出的定义是“机器学习是对能通过经验自动改进的计算机算法的研究”(Machine learning is the study of computer algorithms that improve automatically through experience)。他同时给出了一个更形式化的描述:“对于某类任务(Task)T和性能度量(Performance measure)P,如果计算机程序通过对经验(Experience)E的学习使得在任务T上的性能度量P得到了提升,那么就称这个计算机程序从经验E中进行了学习”(A computer program is said to learn from experience (E) with respect to some class of tasks(T) and performance(P) measure, if its performance at tasks in T, as measured by P, improves with experience E)。
Alpaydin (2004年)给出的定义是“机器学习是用样例数据或以往的经验对计算机编程以优化性能指标”(Machine learning is programming computers to optimize a performance criterion using example data or past experience)。
以无人驾驶汽车系统为例,机器学习的任务是根据路况确定驾驶方式。例如,遇到行人或障碍物时应当避让,遇到红灯时应当停车,等等。学习性能的度量可以是事故发生的概率。经验就是大量的人类驾驶数据。一般来说,训练一个无人驾驶汽车系统需要几百万公里且包含各种路况的人类驾驶数据。从这些数据中,机器学习算法能提取出在各种路况下人类的正确驾驶方式。然后,在无人驾驶的情况下,根据学习到的相应驾驶方式来操纵汽车。例如,如果路口亮起红灯,人类驾驶员就会刹车。机器学习算法提取出这一模式,从而能在传感器识别出红灯时发出刹车的指令。从上面的这个例子可以看出,机器学习的原理与人类学习十分相似,都是对已知的经验数据加以提炼,以掌握完成某项任务的方法。
02
基本术语
了解了机器学习的概念之后,再来关注所有机器学习方法都会涉及的一些基本术语。以“天气预报”为例,在预测之前,我们需要获取一些特征(Feature),比如是否出现了朝霞、是否出现了晚霞、温度、空气湿度、云量等等。通常,“特征”也被称为属性(Attribute)。为了能够进行数学计算,需要将这些特征表示为一个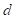 维的特征向量(Feature Vector),记作
维的特征向量(Feature Vector),记作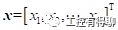 ,向量的每一个维度代表一个特征,总共选取了个特征。在监督式机器学习(Supervised Machine Learning)中,我们还要获得与特征向量对应的标签(Label)。特征向量及其对应的标签组成一个样本(Example)或实例(Instance)。标签可以是离散值,比如下雨、阴天、多云;标签也可以是连续值,比如下雨量、下雨持续时间等。标签的选取通常与需要完成的任务有关。当标签是连续值时,这样的机器学习任务称为回归(Regression)问题。回归用于预测输入变量与输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值随之发生变化。回归问题是指,给定一个新的未知模式,根据以往的经验数据推断它所对应的输出值(实数)是多少,是一种定量输出,也叫连续变量预测。例如,预测明天的气温是多少度,这是一个回归任务。当标签是有限数量的离散值时,这样的机器学习任务称为分类(Classification)问题。分类问题是指,给定一个新的未知模式,根据以往的经验数据推断它所对应的类别(例如,判断一幅图片上的动物是一只猫还是一只狗),是一种定性输出,也叫离散变量预测。例如,预测明天天气是阴天、晴天还是下雨,就是一个分类任务。当标签是标记序列或状态序列时,这样的机器学习任务称为标注(Tagging)问题。标注问题的输入是一个观测序列,输出的是一个标记序列或状态序列。例如,自然语言处理中的词性标注就是一个典型的标注问题:给定一个由单词组成的句子,对这个句子中的每一个单词进行词性标注,即对一个单词序列预测其对应的词性标记序列。标注问题可以看成是分类问题的一个推广。分类问题的输出是一个值,而标注问题输出是一个向量,向量的每个值属于一种标记类型。标注常用的机器学习方法有:隐性马尔可夫模型、条件随机场。
,向量的每一个维度代表一个特征,总共选取了个特征。在监督式机器学习(Supervised Machine Learning)中,我们还要获得与特征向量对应的标签(Label)。特征向量及其对应的标签组成一个样本(Example)或实例(Instance)。标签可以是离散值,比如下雨、阴天、多云;标签也可以是连续值,比如下雨量、下雨持续时间等。标签的选取通常与需要完成的任务有关。当标签是连续值时,这样的机器学习任务称为回归(Regression)问题。回归用于预测输入变量与输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值随之发生变化。回归问题是指,给定一个新的未知模式,根据以往的经验数据推断它所对应的输出值(实数)是多少,是一种定量输出,也叫连续变量预测。例如,预测明天的气温是多少度,这是一个回归任务。当标签是有限数量的离散值时,这样的机器学习任务称为分类(Classification)问题。分类问题是指,给定一个新的未知模式,根据以往的经验数据推断它所对应的类别(例如,判断一幅图片上的动物是一只猫还是一只狗),是一种定性输出,也叫离散变量预测。例如,预测明天天气是阴天、晴天还是下雨,就是一个分类任务。当标签是标记序列或状态序列时,这样的机器学习任务称为标注(Tagging)问题。标注问题的输入是一个观测序列,输出的是一个标记序列或状态序列。例如,自然语言处理中的词性标注就是一个典型的标注问题:给定一个由单词组成的句子,对这个句子中的每一个单词进行词性标注,即对一个单词序列预测其对应的词性标记序列。标注问题可以看成是分类问题的一个推广。分类问题的输出是一个值,而标注问题输出是一个向量,向量的每个值属于一种标记类型。标注常用的机器学习方法有:隐性马尔可夫模型、条件随机场。
现在再回顾机器学习的定义,为了能够在任务T上提高性能P,需要学习某种经验E。这里,需要学习的就是由一组样本或实例构成的数据集(Data Set),而为了确定性能P是否能够提高,还需要一个不同的数据集来测量性能P。因此,数据集需要分为两部分,用于学习的数据集称为训练集(Training Set),用于测试最终性能P的数据集称为测试集(Test Set)。为了保证学习的有效性,需要保证训练集和测试集不相交,并且还要满足独立同分布(Independently and Identically Distributed,i.i.d)假设,即每一个样本都需要独立地从相同的数据分布中提取。“独立”保证了任意两个样本之间不存在依赖关系;“同分布”保证了数据分布的统一,从而在训练集上的训练结果对于测试集也是适用的。例如,如果训练集的数据都是高速公路上的驾驶数据,而测试集的数据都是城区街道上的驾驶数据,这显然是不合理的。
机器学习的主要任务就是如何更好地利用数据集来构建“好”的模型(Model)。给定训练集,我们希望算法能够拟合一个函数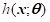 来完成从输入特征向量
来完成从输入特征向量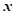 到标签的映射。对于连续的标签或者非概率模型,通常会直接拟合标签的值:
到标签的映射。对于连续的标签或者非概率模型,通常会直接拟合标签的值:
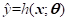
其中,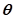 是预测函数的参数向量。对于离散的标签或者概率模型,通常会拟合一个条件概率分布函数:
是预测函数的参数向量。对于离散的标签或者概率模型,通常会拟合一个条件概率分布函数:
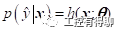
用于预测每一类的概率值。
为了获得这样的一组模型参数,需要有一套学习算法(Learning Algorithm)来优化这个函数映射,这个优化的过程就称为学习(Learning)或者训练(Training),这个需要拟合的函数就称为模型(Model)。模型定义了特征向量与标签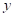 之间的关系。例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。利用训练集,使用学习算法得到的模型被称为假设(Hypothesis),在本书中会被称为学习器(Learner)。对于一个具体的回归或分类任务,所有可能的模型输入数据组成的集合称为输入空间(Input Space),所有可能的模型输出数据构成的集合称为输出空间(Output Space)。显然,机器学习任务的本质就是寻找一个从输入空间到输出空间的映射,并将该映射作为预测模型。我们将训练得到的模型称为一个假设,从输入空间到输出空间的所有可能映射组成的集合称为假设空间(Hypothesis Space)。换句话说,机器学习的目的就在于从这个假设空间中选择出一个最好的预测模型。机器学习的核心就是针对给定任务,设计出以训练数据为其输入,以模型为其输出的算法。所以,有时人们也说,机器学习算法的职责是通过训练数据来训练模型。
之间的关系。例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。利用训练集,使用学习算法得到的模型被称为假设(Hypothesis),在本书中会被称为学习器(Learner)。对于一个具体的回归或分类任务,所有可能的模型输入数据组成的集合称为输入空间(Input Space),所有可能的模型输出数据构成的集合称为输出空间(Output Space)。显然,机器学习任务的本质就是寻找一个从输入空间到输出空间的映射,并将该映射作为预测模型。我们将训练得到的模型称为一个假设,从输入空间到输出空间的所有可能映射组成的集合称为假设空间(Hypothesis Space)。换句话说,机器学习的目的就在于从这个假设空间中选择出一个最好的预测模型。机器学习的核心就是针对给定任务,设计出以训练数据为其输入,以模型为其输出的算法。所以,有时人们也说,机器学习算法的职责是通过训练数据来训练模型。
模型的训练可以看成是在假设空间中搜索所需模型的过程,模型训练算法在假设空间中搜索合适的映射,使得该映射的预测效果与训练样本所含的先验信息相一致。事实上,满足条件的映射通常不止一个,此时需要对多个满足条件的映射做出选择。在没有足够依据进行唯一性选择的情况下,有时需要做出具有主观倾向性的选择,即更愿意选择某个映射作为预测模型。这种选择的主观倾向性称为机器学习算法的模型偏好(Model Preference)。例如,当多个映射与训练样本所包含的先验信息一致时,可选最简单的映射作为预测模型,此时模型偏好为最简单的映射。这种在同等条件下选择简单事物的倾向性原则称为奥卡姆剃刀原则(Occam's Razor)。
对于训练得到的模型(学习器),我们可以使用测试集来评估其性能。
03
机器学习与人类学习的类比
通过上面的分析,可以看出机器学习与人类学习经验的过程是类似的。事实上,机器学习的一个主要目的就是把人类思考归纳经验的过程转化为计算机通过对数据的处理计算得出模型的过程。经过计算机得出的模型能够以近似于人的方式解决很多灵活复杂的问题。下图示意了机器学习与人类学习的类比。
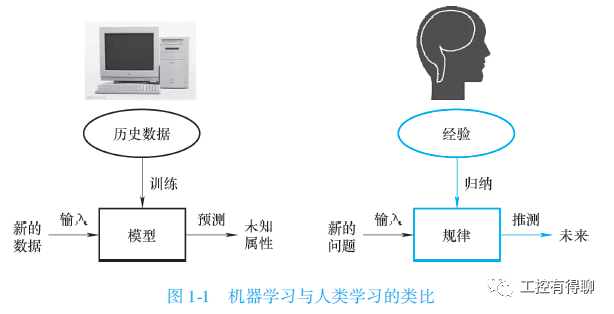
机器学习中的“训练”与“预测”过程可以对应到人类的“归纳”和“推测”过程。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。由于机器学习不是基于编程形成的结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关性结论。
那么机器学习与人类学习相比,有哪些优势?面临哪些问题?
首先,机器学习算法可以从海量数据中提取与任务相关的重要特征。
例如,在人脸识别技术中,机器学习算法能从人脸面部提取很多细节特征,来区别任意两个不同的人脸,其识别准确率超过人类。
其次,机器学习算法可以自动地对模型进行调整,以适应不断变化的环境。例如,在房价预测系统中,机器学习算法能自动根据类似的小区的最新交易记录,对某小区的房价预测做出迅速调整。这样的反应速度往往非人力所能及。
然而,机器学习也并非无所不能。机器学习面临的第一个问题是:机器学习算法需要大量的训练数据来训练模型。在训练数据不足的情况下,机器学习算法往往会面临两个挑战。第一,训练数据的代表性不够好。这使得模型在面对完全陌生的任务场景时会“不知所措”。例如,如果在无人驾驶汽车算法的训练数据中没有包含雪天的行驶记录,那么经训练得到的模型很可能无法在雪天给出正确的驾驶指令。第二,训练数据的一些特殊的特征可能将模型带入过度拟合的误区。过度拟合就是指算法过度解读训练数据,从而失去了模型的可推广性。
机器学习面临的第二个问题是:目前它还没有在创造性的工作领域中取得成效。例如,艺术创作还主要依赖于人类的情感与思维,许多构造性的数学证明还无法由机器学习来完成,许多猜想性质的科学研究也仍然需要科学家的灵感与智慧。
机器的能力是否能超过人的,很多持否定意见的人的一个主要论据是:机器是人造的,其性能和动作完全是由设计者规定的,因此无论如何其能力也不会超过设计者本人。这种观点对不具备学习能力的机器来说的确是成立的,可是对具备学习能力的机器来说就值得深思了,因为这种机器的能力在应用中不断地提高,过一段时间之后,设计者本人也不知它的能力到了何种水平。
END









