一、学习框架
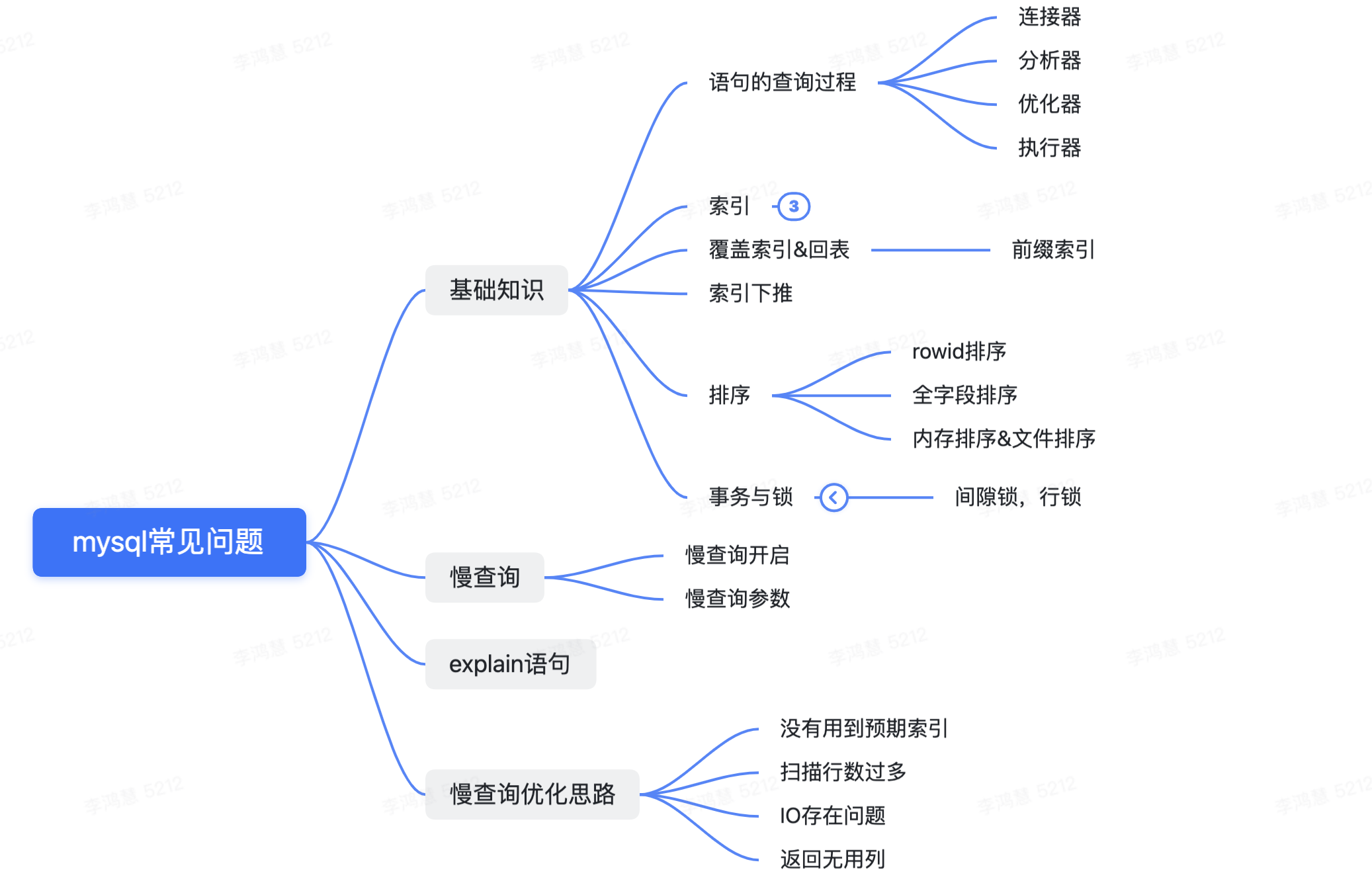
- 一条查询语句的执行过程:一条语句在客户端执行,通过连接器跟服务器建立起连接,通过连接器控制连接的数量,获知客户端的状态,为每一个客户端建立起TCP连接。然后到词法分析器,进行词法分析和语法分析,词法分析将语句解析成一个个token词,语法分析将token词生成语法树。优化器负责生成执行计划,选择索引。根据优化器选择的索引,执行器调用存储引擎的接口取数据,执行语句。
重点:优化器如何选择索引?
- 扫描行数:扫描行数怎么判断?一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好 。MySQL是通过采样统计的方式来判断的。但是扫描行数只是个预估值,存在对mysql误导的情况
- 是否使用临时表 --见下方关于排序的讲解
- 是否需要排序
索引:索引需要知道索引的结构,聚集索引和非聚集索引的区别,普通索引和唯一索引的区别,什么时候适合用普通索引,普通索引能够用上change buffer的优化
覆盖索引&回表:如果需要查询的字段,都包含在索引里面(通常是联合索引),那么就不需要去主键索引回表,因为只有主键索引的叶子结点包含row数据行,这也是一种常见的优化手段。
需要注意的是回表扫描的行数不会体现在rows_examed里,因为rows_examed是表示执行引擎从存储器取了多少次数据,而是否回表是取决于不同的存储引擎,例如innoDb需要回表,myslam就不需要回表
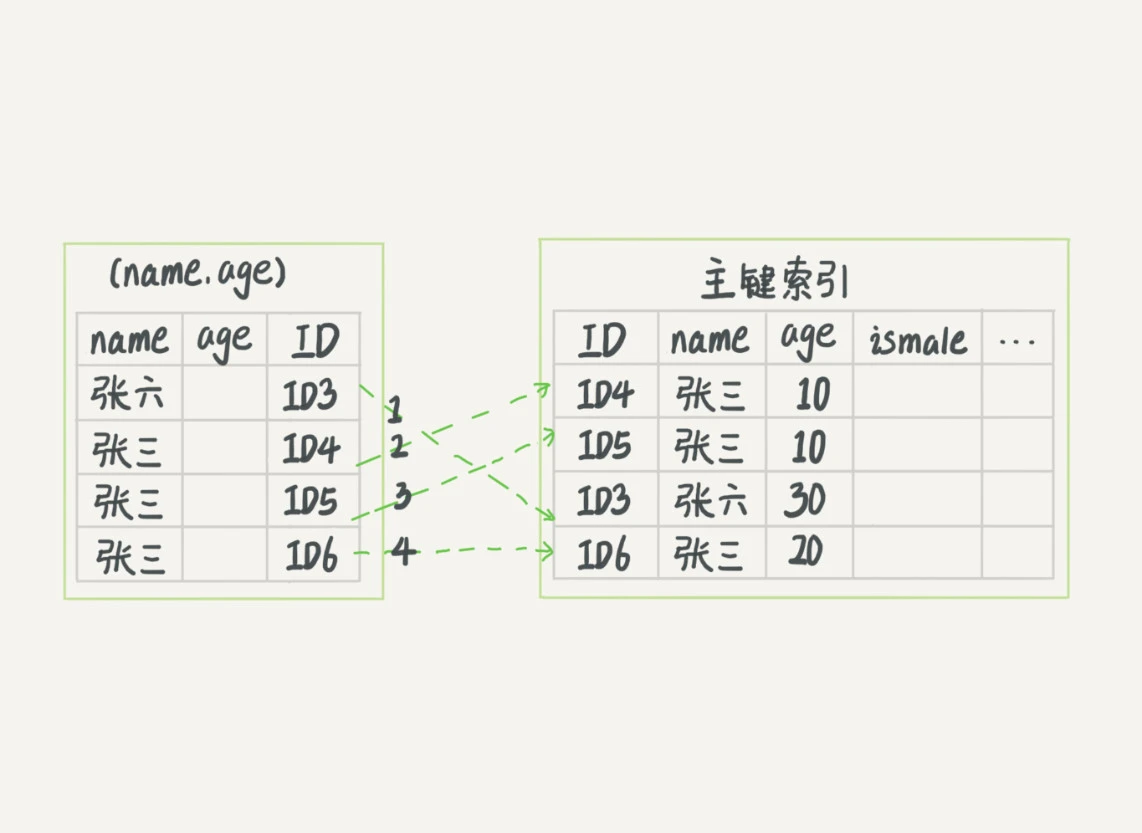
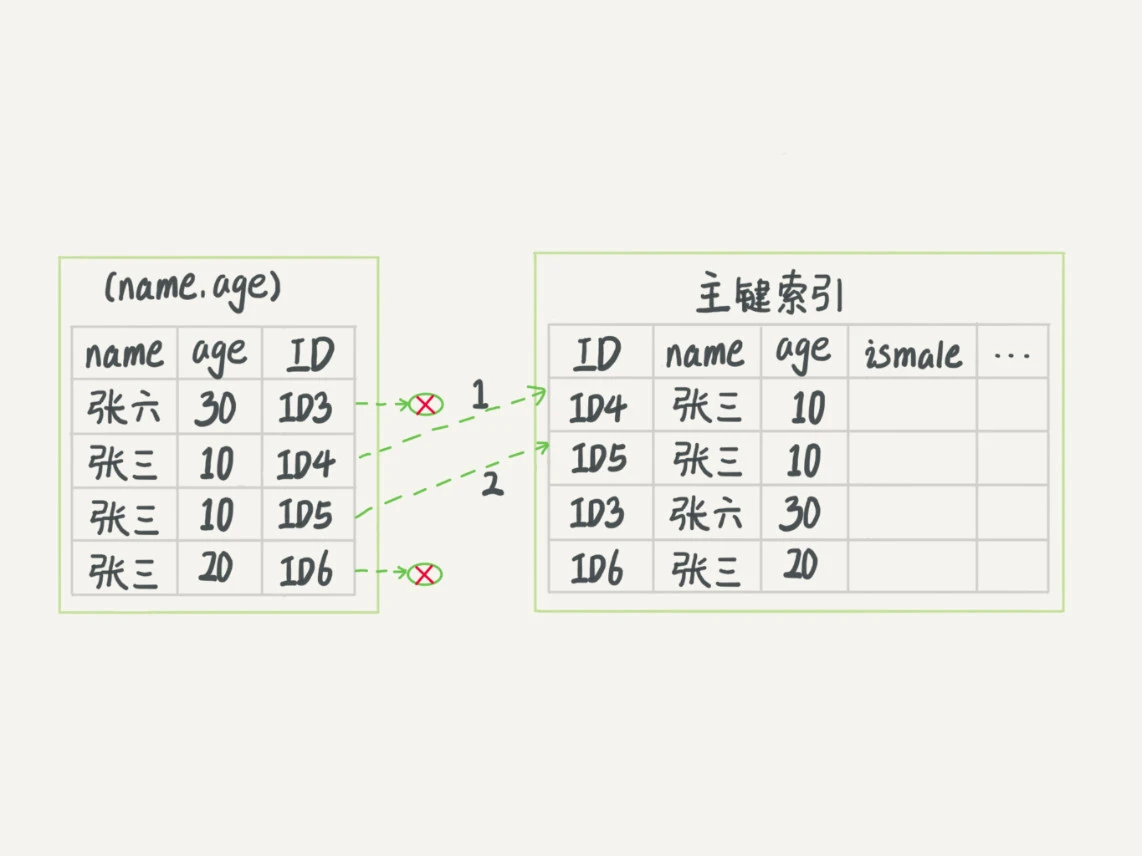
如果有联合主键索引(a,b),和索引c,a,c,ac,abc都可以走索引索引下推:索引下推的前提是有覆盖索引,通过索引下推,在覆盖索引遍历的时候将一些不符合的行过滤掉,减少回表的次数。
无索引下推:
有索引下推:
- 排序---总结,如果排序字段有索引,能够自然有序,
- rowid排序
- 全字段排序
- 内排序
- 外排序
- 慢查询
- 开启:slow_query_log 慢查询开启状态,long_query_time 查询超过多少秒才记录
- 参数
在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的

- explain语句
通常看
possible_keys以及key两个字段possible_keys的内容取决于where语句 +EXPLAIN TABLE的结果,即where会用到哪些EXPLAIN TABLE中能看到的索引key表示 MySQL 存储引擎实际选择的索引。这个索引可能不是possible_keys中列出来的key_len表示实际使用的索引的长度,通常能根据这个字段 +key来判断用了key的哪几个字段
当前表的关联方式,也对查询性能影响较大。对应的在 EXPLAIN 结果中,有个 type 字段来参考关联方式。通常问题 SQL 中会出现 type=ALL 或者 type=index 的情况,即全表扫描。下面列举了下 type 的可能值,按照性能从好到差来排序。
system & const: 表示你条件可以被转换为常数列(即能通过条件确定唯一值),比如
只有一行记录的系统表:system
where 条件是 pk or unique key 的唯一值,例如
a=1 & a is pk or ukeq_ref & ref & ref_or_null
eq_ref:previous table 的内容能在当前 table 唯一确认一列
ref:用了索引,但是做不到 eq_ref 那么好,就是 ref
ref_or_null:等价 ref,比 ref 多比较了一个 null 的情况
-
fulltext:使用了
FULLTEXT索引- index_merge
采用了多个索引,此时
key列会展示用到的具体索引unique_subquery & index_subquery
针对 IN 类型的 subquery 优化
range
用了索引,判断采用范围读取的方式比较好
通常会出现在范围类型的 operator & 当前索引中用到的列,其区分度比较小的情况
range对 column 相关 operator 是有要求的,支持的有:=, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, or IN()index & all
都是全表扫描,区别是用非主键还是主键
要注意的是,不同索引的扫描,数据的返回顺序是不一样的
rows:预估扫描行
二、排查思路
- 索引使用不符合预期
没有用索引---选择合适的索引
优化器选择了错误索引---优化器为什么会选错索引呢?force_index或者使用order by 引导优化器使用合适的索引
索引没有实现覆盖索引---根据业务决定如何用上覆盖索引的优化
- 扫描行数过多---limit m,n 跳过m行取n行,会出现扫描m+n的结果
- IO存在问题,获取不到连接,或者被无效的连接占有
- 返回不需要的列,慎用select * 尤其是一些字段是json,如果使用select *会造成IO压力
三、分析慢查询的思路
- explain查看情况
- 分析语句的执行计划和执行过程
- 结合业务寻找优化点
SQL优化---while true 并且limit m,n导致的SQL扫描行数过多。limit m,n会取出m+n行数据,然后跳过m行,因此rows_examed会是m+n。
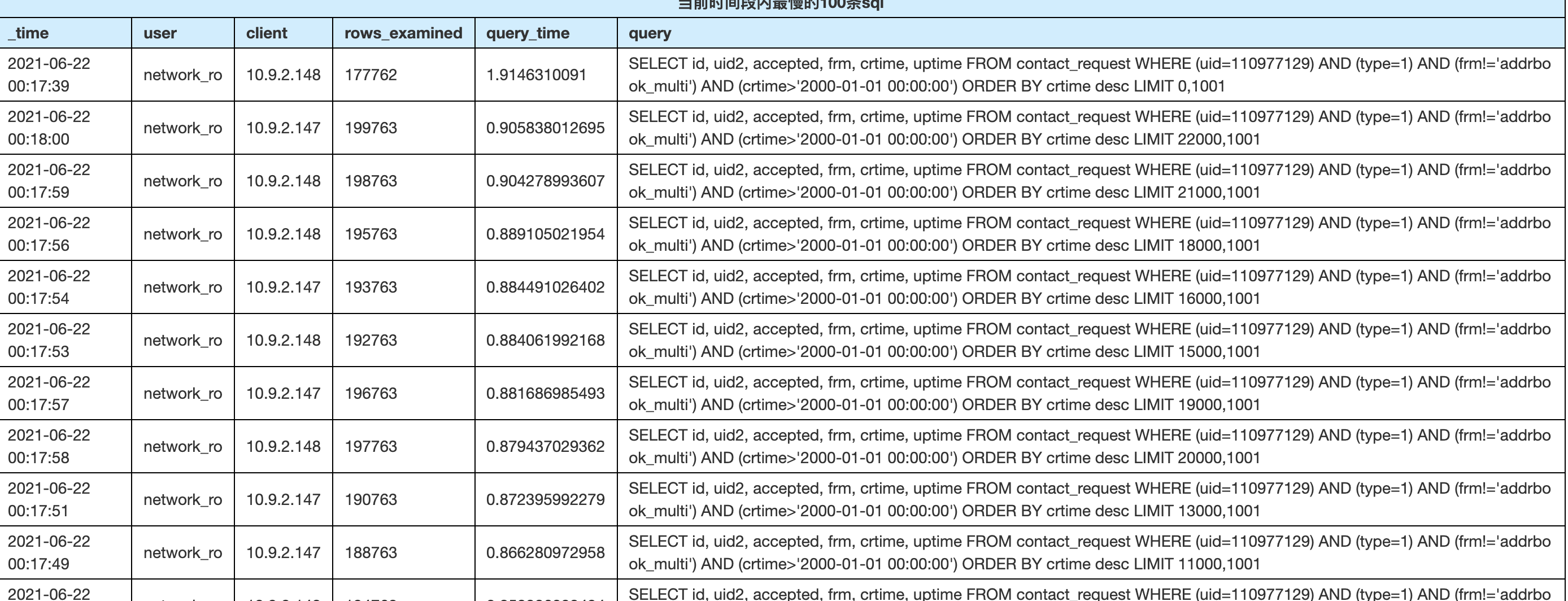
SELECT id, uid2, accepted, frm, crtime, uptime FROM contact_request WHERE (uid=110977129) AND (type=1) AND (frm!='addrbook_multi') AND (crtime>'2000-01-01 00:00:00') ORDER BY crtime desc LIMIT 0,1001
def get_exclude_talent_ids_add_fr(manager, uid, start):
to_uids = []
ht = {}
page = 0
size = 1000
while True:
cr_rows = network_service.get_cttreq_all_addfr_requests(manager=manager, uid=uid, crtime=start,
page=page * size, count=size + 1)
remain = 0
if cr_rows:
if len(cr_rows) > size:
remain = 1
for cr_row in cr_rows:
to_uid = cr_row['uid2']
if to_uid not in ht:
to_uids.append(to_uid)
ht[to_uid] = to_uid
if remain:
page += 1
else:
break
return to_uids
Limit m,n-->id>max_fid limit n
explain SELECT count(*) FROM contact_request WHERE (uid=110977129) AND (type=1) AND (frm!='addrbook_multi') AND (crtime>'2000-01-01 00:00:00') and id>max_id ORDER BY crtime desc LIMIT 1001
def get_exclude_talent_ids_add_fr_new(manager, uid, start):
to_uids = []
ht = {}
size = 1000
max_id = 0
while True:
cr_rows = network_service.get_cttreq_addfr_requests_by_crtime(manager=manager, uid=uid, crtime=start, limit=size+1, id=max_id)
remain = 1 if len(cr_rows) > size else 0
if cr_rows:
start = cr_rows[len(cr_rows) - 1]['crtime']-datetime.timedelta(seconds=1)
max_id = cr_rows[len(cr_rows) - 1]['id']
for cr_row in cr_rows:
to_uid = cr_row['uid2']
if to_uid not in ht:
to_uids.append(to_uid)
ht[to_uid] = to_uid
if not remain:
break
return to_uids









