前言
在faceNet和DeepFace的相关知识实现一个人脸识别系统。
人脸识别系统的实现,主要有两个部分组成:
- 人脸验证:解决识别目标是否为“人”
- 人脸识别:识别这个“人”是谁?
FaceNet神经网络能够将人脸图像转换为一个128维的向量,通过比较这些向量,可以确定两幅图像是否是同一个人。
人脸识别的实现,可以分为以下三个部分:
- 定义损失函数
- 使用预训练的模型将图像转换为128维的向量
- 利用编码后的向量进行人脸验证和识别
在整个人脸识别系统的实现之前,首先导入相关库
from keras.models import Sequential
from keras.layers import Conv2D, ZeroPadding2D, Activation, Input, concatenate
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D, AveragePooling2D
from keras.layers.merge import Concatenate
from keras.layers.core import Lambda, Flatten, Dense
from keras.initializers import glorot_uniform
from keras.engine.topology import Layer
from keras import backend as K
K.set_image_data_format('channels_first')
import cv2
import os
import numpy as np
from numpy import genfromtxt
import pandas as pd
import tensorflow as tf
from fr_utils import *
from inception_blocks import *
%matplotlib inline
%load_ext autoreload
%autoreload 2
np.set_printoptions(threshold=np.nan)
基本人脸验证
最基本的人脸识别是给出两张人脸的图片,直接比较两张图片对应位置的像素,如果像素间的距离小于指定阈值,则说明这两张图片来自同一个人,否则不是同一个人,这种验证方法虽然很简单,但是无法保证其精确度。

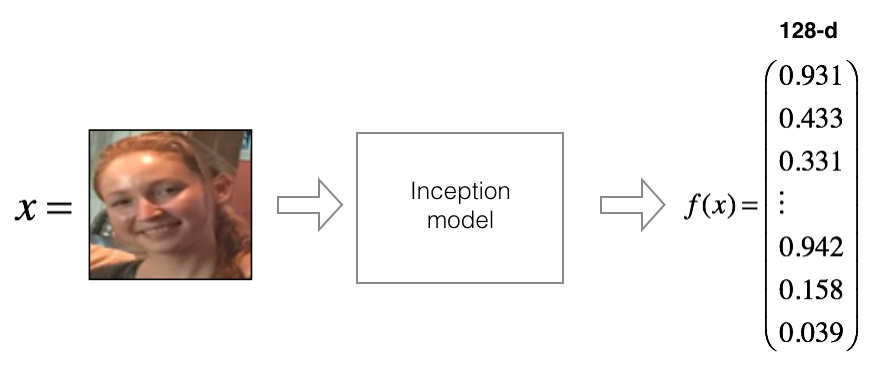
将原始图像编码为128维的向量
使用卷积网络计算图像编码
FaceNet模型的训练,已经花费了大量的时间,再本次任务中,会直接加载FaceNet模型已经训练好的权重参数来训练。在训练中,需要注意以下问题:
- FaceNet采用的输入时96*96的RGB图像,输入图像的张量为(,,,)=
- 输出是一个维的矩阵
加载已有FaceNet模型的代码如下所示:
FRmodel = faceRecoModel(input_shape=(3, 96, 96))
模型的最后一层使用的是一个128个单元的全连接网络,最后一层的结构确保了模型输出向量的编码是一个128维的向量,如下图所示:
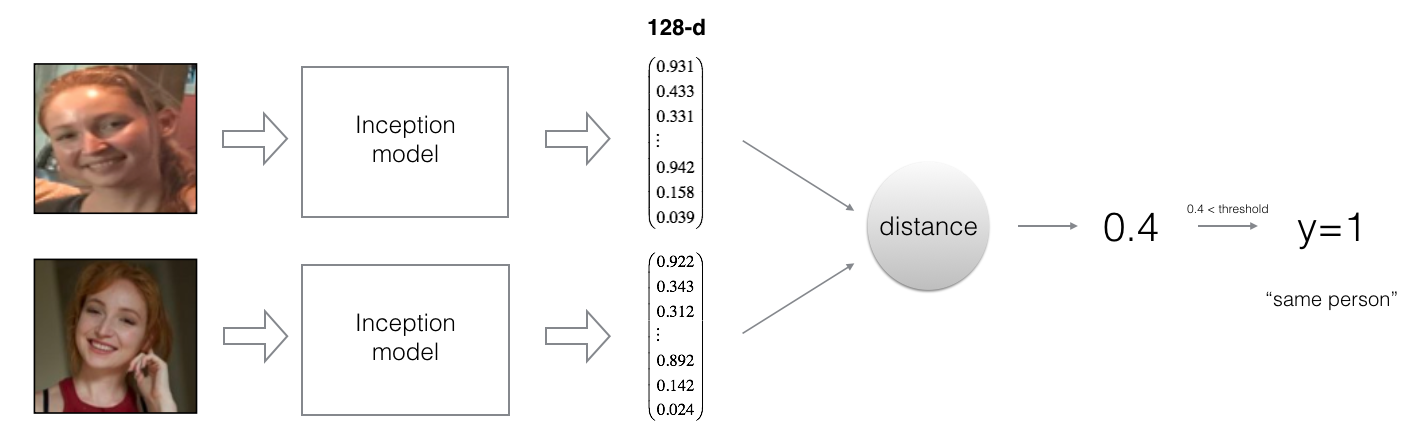
如上图所示,通过比较两张图像经过编码后的距离和阈值可以确定两张图像是否是同一个人,如果两幅图像是同一个人,则说明经过编码之后的图像距离小于阈值,否则大于给定阈值。
人脸识别中用到了triplet损失函数,triplet损失函数的主要思想是将同一人的两幅图像(正样本和人脸)的编码距离尽量缩小,而尽可能增大不同图像(负样本和人脸)的编码距离,如下图所示:

Triplet 损失
对于给定图像,将其通过神经网络计算得到的编码标记为,如下图所示:
定义triplet损失的图像为
- 为 “anchor”图像,表示人脸的图像
- 为 “Positive” 表示正样本,与anchor图像相同的人的图像
- 为“Negative” 表示负样本,与anchor图像不同的人的图像
用表示第个训练样本,在训练中,应该尽可能的保证与之间的距离尽可能接近,而和之间的距离应该尽量保持一个的间距,如下公式所示:
综上,对于所有样本,其损失函数的定义是:
注意:是一个超参数,一般需要手动选择,一般情况下设定为0.2
根据以上,triple损失函数的代码实现是
def triplet_loss(y_true, y_pred, alpha = 0.2):
"""
根据以上公式实现一个triplet损失函数
参数s:
y_true --真实的标签
y_pred -- 预测的标签
anchor -- anchor 图像的编码 shape (None, 128)
positive -- 正样本的编码,shape (None, 128)
negative -- 负样本的编码 shape (None, 128)
返回值:
loss -- 损失值,实数
"""
anchor, positive, negative = y_pred[0], y_pred[1], y_pred[2]
# Step 1: 计算anchor图像与正样本的距离
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,positive)))
# Step 2: 计算anchor图像与负样本的编码距离
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,negative)))
# Step 3: 减掉之前计算得到的值,并加上偏置参数alpha
basic_loss = tf.add(tf.subtract(pos_dist,neg_dist),alpha)
# Step 4:选择basic_loss和0的最大值(确保为正数),并累加所有的训练样本
loss = tf.reduce_sum(tf.maximum(basic_loss,0))
return loss
加载训练好的模型
FaceNet通过最小化triple损失训练模型,对于人脸识别的任务,可以通过加载一个预训练的模型,减少训练的时间和资源。具体如下代码所示:
FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
load_weights_from_FaceNet(FRmodel)
以下的图片表示样本中了不同个体经过编码之后的“距离”

人脸验证
利用人脸实现验证之前,首先,需要构建一个人脸验证的数据库,这个数据库的构成是通过将原始图像经过FaceNet的前向传播过程而生成的一个128维向量,具体如下代码所示:
database = {}
database["danielle"] = img_to_encoding("images/danielle.png", FRmodel)
database["younes"] = img_to_encoding("images/younes.jpg", FRmodel)
database["tian"] = img_to_encoding("images/tian.jpg", FRmodel)
database["andrew"] = img_to_encoding("images/andrew.jpg", FRmodel)
database["kian"] = img_to_encoding("images/kian.jpg", FRmodel)
database["dan"] = img_to_encoding("images/dan.jpg", FRmodel)
database["sebastiano"] = img_to_encoding("images/sebastiano.jpg", FRmodel)
database["bertrand"] = img_to_encoding("images/bertrand.jpg", FRmodel)
database["kevin"] = img_to_encoding("images/kevin.jpg", FRmodel)
database["felix"] = img_to_encoding("images/felix.jpg", FRmodel)
database["benoit"] = img_to_encoding("images/benoit.jpg", FRmodel)
database["arnaud"] = img_to_encoding("images/arnaud.jpg", FRmodel)
有了以上对图像的编码,实现人脸识别系统的验证模块可以分为以下三个部分:
- 计算输入图像的编码
- 计算数据库中经编码之后的图像与输入图像编码之间的距离
- 如果以上计算得到的距离小于0.7,则认为两张图片代表同一个人。
验证部分的代码如下所示:
# GRADED FUNCTION: verify
def verify(image_path, identity, database, model):
"""
参数:
image_path -- 图像路径
identity -- 字符串, 想验证的人的名称
database -- 字典,人名和人脸一一对应.
model -- keras实现的Inception模块
返回值:
dist -- 参数img_path和数据库中对应的identity编码后的距离
door_open -- 如果为真,表示同一个人,执行开门操作.
"""
# Step 1: 计算图像的编码,用img_to_enconding()函数
encoding = img_to_encoding(image_path)
# Step 2: 计算两张图像之间的距离
dist = np.linalg.norm(encoding,database[identity])
# Step 3: 如果距离值小于0.7执行开门,否则,关门
if dist<0.7:
print("It's " + str(identity) + ", welcome home!")
door_open = True
else:
print("It's not " + str(identity) + ", please go away")
door_open = False
return dist, door_open
人脸识别
人脸验证系统的并不能实现实时验证,尽管这一实现已经能够满足现实中大多数情景了,但是为了减少一些恶作剧的发生,需要搭建一个实时的人脸识别系统。
与人脸验证系统相比,人脸识别系统的实现可以分为以下几个步骤:
- 计算目标图像的编码
- 在数据库中找到与目标图像的编码距离最小的图像
- 初始化最小距离(
min_dist)足够大(设定为100) - 遍历整个数据库中图像
- 计算目标图像编码和当前数据库中的图像编码之间的L2距离
- 如果这个距离小于
min_dist,将min_dist值设定为当前距离(类似于寻找最小值)。
- 初始化最小距离(
综上,人脸识别系统的实现可以如下代码所示:
def who_is_it(image_path, database, model):
"""
参数:
image_path -- 输入图像的路径
database -- 包含图像编码与图像标签的字典
model -- keras实现的inception模块
返回值:
min_dist -- 设定的摩恩最小值,设定为100
identity --字符串,image_path中的人名
"""
## Step 1: 计算目标图像的编码
encoding = img_to_encoding(image_path)
## Step 2:寻找距离最小的图像的编码
# 初始化最小化,一般情况下尽可能大,设定为100
min_dist = 100
# 遍历字典中的名称和编码.
for (name, db_enc) in database.items():
# 计算当前字典中图像编码和目标图像的编码之间的L2距离
dist = np.linalg.norm(encoding,db_enc)
# 寻找整个字典中的编码距离最小的值
if dist<min_dist:
min_dist = dist
identity = name
if min_dist > 0.7:
print("Not in the database.")
else:
print ("it's " + str(identity) + ", the distance is " + str(min_dist))
return min_dist, identity
附录 人脸识别用到的一些代码
#### PART OF THIS CODE IS USING CODE FROM VICTOR SY WANG: https://github.com/iwantooxxoox/Keras-OpenFace/blob/master/utils.py ####
import tensorflow as tf
import numpy as np
import os
import cv
from numpy import genfromtxt
from keras.layers import Conv2D, ZeroPadding2D, Activation, Input, concatenate
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D, AveragePooling2D
import h5py
import matplotlib.pyplot as plt
_FLOATX = 'float32'
def variable(value, dtype=_FLOATX, name=None):
v = tf.Variable(np.asarray(value, dtype=dtype), name=name)
_get_session().run(v.initializer)
return v
def shape(x):
return x.get_shape()
def square(x):
return tf.square(x)
def zeros(shape, dtype=_FLOATX, name=None):
return variable(np.zeros(shape), dtype, name)
def concatenate(tensors, axis=-1):
if axis < 0:
axis = axis % len(tensors[0].get_shape())
return tf.concat(axis, tensors)
def LRN2D(x):
return tf.nn.lrn(x, alpha=1e-4, beta=0.75)
def conv2d_bn(x,
layer=None,
cv1_out=None,
cv1_filter=(1, 1),
cv1_strides=(1, 1),
cv2_out=None,
cv2_filter=(3, 3),
cv2_strides=(1, 1),
padding=None):
num = '' if cv2_out == None else '1'
tensor = Conv2D(cv1_out, cv1_filter, strides=cv1_strides, data_format='channels_first', name=layer+'_conv'+num)(x)
tensor = BatchNormalization(axis=1, epsilon=0.00001, name=layer+'_bn'+num)(tensor)
tensor = Activation('relu')(tensor)
if padding == None:
return tensor
tensor = ZeroPadding2D(padding=padding, data_format='channels_first')(tensor)
if cv2_out == None:
return tensor
tensor = Conv2D(cv2_out, cv2_filter, strides=cv2_strides, data_format='channels_first', name=layer+'_conv'+'2')(tensor)
tensor = BatchNormalization(axis=1, epsilon=0.00001, name=layer+'_bn'+'2')(tensor)
tensor = Activation('relu')(tensor)
return tensor
WEIGHTS = [
'conv1', 'bn1', 'conv2', 'bn2', 'conv3', 'bn3',
'inception_3a_1x1_conv', 'inception_3a_1x1_bn',
'inception_3a_pool_conv', 'inception_3a_pool_bn',
'inception_3a_5x5_conv1', 'inception_3a_5x5_conv2', 'inception_3a_5x5_bn1', 'inception_3a_5x5_bn2',
'inception_3a_3x3_conv1', 'inception_3a_3x3_conv2', 'inception_3a_3x3_bn1', 'inception_3a_3x3_bn2',
'inception_3b_3x3_conv1', 'inception_3b_3x3_conv2', 'inception_3b_3x3_bn1', 'inception_3b_3x3_bn2',
'inception_3b_5x5_conv1', 'inception_3b_5x5_conv2', 'inception_3b_5x5_bn1', 'inception_3b_5x5_bn2',
'inception_3b_pool_conv', 'inception_3b_pool_bn',
'inception_3b_1x1_conv', 'inception_3b_1x1_bn',
'inception_3c_3x3_conv1', 'inception_3c_3x3_conv2', 'inception_3c_3x3_bn1', 'inception_3c_3x3_bn2',
'inception_3c_5x5_conv1', 'inception_3c_5x5_conv2', 'inception_3c_5x5_bn1', 'inception_3c_5x5_bn2',
'inception_4a_3x3_conv1', 'inception_4a_3x3_conv2', 'inception_4a_3x3_bn1', 'inception_4a_3x3_bn2',
'inception_4a_5x5_conv1', 'inception_4a_5x5_conv2', 'inception_4a_5x5_bn1', 'inception_4a_5x5_bn2',
'inception_4a_pool_conv', 'inception_4a_pool_bn',
'inception_4a_1x1_conv', 'inception_4a_1x1_bn',
'inception_4e_3x3_conv1', 'inception_4e_3x3_conv2', 'inception_4e_3x3_bn1', 'inception_4e_3x3_bn2',
'inception_4e_5x5_conv1', 'inception_4e_5x5_conv2', 'inception_4e_5x5_bn1', 'inception_4e_5x5_bn2',
'inception_5a_3x3_conv1', 'inception_5a_3x3_conv2', 'inception_5a_3x3_bn1', 'inception_5a_3x3_bn2',
'inception_5a_pool_conv', 'inception_5a_pool_bn',
'inception_5a_1x1_conv', 'inception_5a_1x1_bn',
'inception_5b_3x3_conv1', 'inception_5b_3x3_conv2', 'inception_5b_3x3_bn1', 'inception_5b_3x3_bn2',
'inception_5b_pool_conv', 'inception_5b_pool_bn',
'inception_5b_1x1_conv', 'inception_5b_1x1_bn',
'dense_layer'
]
conv_shape = {
'conv1': [64, 3, 7, 7],
'conv2': [64, 64, 1, 1],
'conv3': [192, 64, 3, 3],
'inception_3a_1x1_conv': [64, 192, 1, 1],
'inception_3a_pool_conv': [32, 192, 1, 1],
'inception_3a_5x5_conv1': [16, 192, 1, 1],
'inception_3a_5x5_conv2': [32, 16, 5, 5],
'inception_3a_3x3_conv1': [96, 192, 1, 1],
'inception_3a_3x3_conv2': [128, 96, 3, 3],
'inception_3b_3x3_conv1': [96, 256, 1, 1],
'inception_3b_3x3_conv2': [128, 96, 3, 3],
'inception_3b_5x5_conv1': [32, 256, 1, 1],
'inception_3b_5x5_conv2': [64, 32, 5, 5],
'inception_3b_pool_conv': [64, 256, 1, 1],
'inception_3b_1x1_conv': [64, 256, 1, 1],
'inception_3c_3x3_conv1': [128, 320, 1, 1],
'inception_3c_3x3_conv2': [256, 128, 3, 3],
'inception_3c_5x5_conv1': [32, 320, 1, 1],
'inception_3c_5x5_conv2': [64, 32, 5, 5],
'inception_4a_3x3_conv1': [96, 640, 1, 1],
'inception_4a_3x3_conv2': [192, 96, 3, 3],
'inception_4a_5x5_conv1': [32, 640, 1, 1,],
'inception_4a_5x5_conv2': [64, 32, 5, 5],
'inception_4a_pool_conv': [128, 640, 1, 1],
'inception_4a_1x1_conv': [256, 640, 1, 1],
'inception_4e_3x3_conv1': [160, 640, 1, 1],
'inception_4e_3x3_conv2': [256, 160, 3, 3],
'inception_4e_5x5_conv1': [64, 640, 1, 1],
'inception_4e_5x5_conv2': [128, 64, 5, 5],
'inception_5a_3x3_conv1': [96, 1024, 1, 1],
'inception_5a_3x3_conv2': [384, 96, 3, 3],
'inception_5a_pool_conv': [96, 1024, 1, 1],
'inception_5a_1x1_conv': [256, 1024, 1, 1],
'inception_5b_3x3_conv1': [96, 736, 1, 1],
'inception_5b_3x3_conv2': [384, 96, 3, 3],
'inception_5b_pool_conv': [96, 736, 1, 1],
'inception_5b_1x1_conv': [256, 736, 1, 1],
}
def load_weights_from_FaceNet(FRmodel):
# Load weights from csv files (which was exported from Openface torch model)
weights = WEIGHTS
weights_dict = load_weights()
# Set layer weights of the model
for name in weights:
if FRmodel.get_layer(name) != None:
FRmodel.get_layer(name).set_weights(weights_dict[name])
elif model.get_layer(name) != None:
model.get_layer(name).set_weights(weights_dict[name])
def load_weights():
# Set weights path
dirPath = './weights'
fileNames = filter(lambda f: not f.startswith('.'), os.listdir(dirPath))
paths = {}
weights_dict = {}
for n in fileNames:
paths[n.replace('.csv', '')] = dirPath + '/' + n
for name in WEIGHTS:
if 'conv' in name:
conv_w = genfromtxt(paths[name + '_w'], delimiter=',', dtype=None)
conv_w = np.reshape(conv_w, conv_shape[name])
conv_w = np.transpose(conv_w, (2, 3, 1, 0))
conv_b = genfromtxt(paths[name + '_b'], delimiter=',', dtype=None)
weights_dict[name] = [conv_w, conv_b]
elif 'bn' in name:
bn_w = genfromtxt(paths[name + '_w'], delimiter=',', dtype=None)
bn_b = genfromtxt(paths[name + '_b'], delimiter=',', dtype=None)
bn_m = genfromtxt(paths[name + '_m'], delimiter=',', dtype=None)
bn_v = genfromtxt(paths[name + '_v'], delimiter=',', dtype=None)
weights_dict[name] = [bn_w, bn_b, bn_m, bn_v]
elif 'dense' in name:
dense_w = genfromtxt(dirPath+'/dense_w.csv', delimiter=',', dtype=None)
dense_w = np.reshape(dense_w, (128, 736))
dense_w = np.transpose(dense_w, (1, 0))
dense_b = genfromtxt(dirPath+'/dense_b.csv', delimiter=',', dtype=None)
weights_dict[name] = [dense_w, dense_b]
return weights_dict
def load_dataset():
train_dataset = h5py.File('datasets/train_happy.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_happy.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
import cv2
def img_to_encoding(image_path, model):
img1 = cv.imread(image_path, 1)
img = img1[...,::-1]
img = np.around(np.transpose(img, (2,0,1))/255.0, decimals=12)
x_train = np.array([img])
embedding = model.predict_on_batch(x_train)
return embedding










