各位好,我是乾颐堂大堂子。领取完整实战指南可以私信我,关键词:实战指南
通过 jieba 文字分词库对邮件数据集的垃圾邮件和进行文本处理,提取特征。然后调用 sklearn 机器学习库中的朴素贝叶斯算法训练模型,最后推理测试集中邮件是否为垃圾邮件。

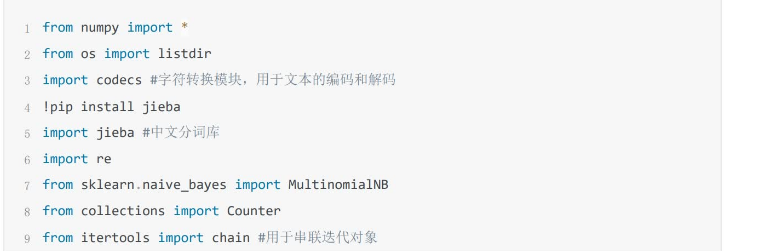
步骤 1 引入相关依赖的包
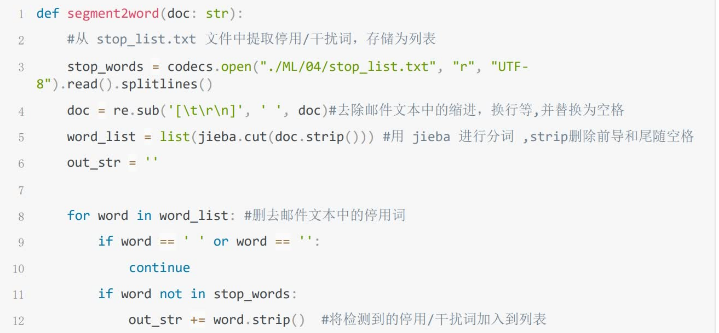
步骤 2 构建文本处理函数
删除其中的干扰字符,例如【】*。,等等,然后分词,剩下的词汇认为是有效词汇。

步骤3构建文本读取函数
获取文件中所有词,进行文本处理
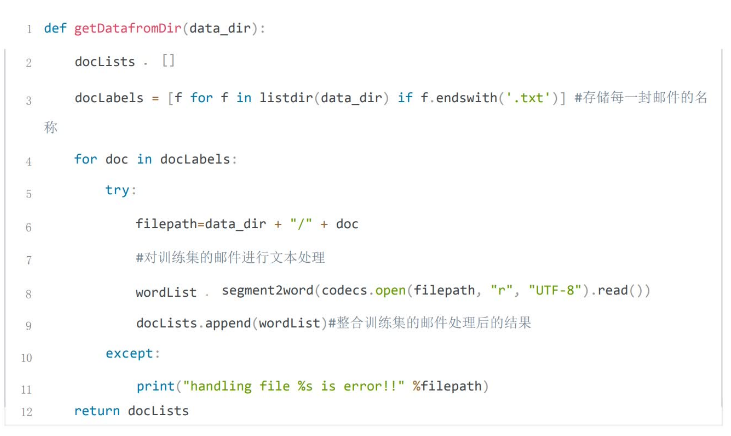
步骤4构建数据集
统计全部训练集中每个有效词汇的出现次数,截取出现次数最多的前500个根据预处理后的垃圾邮件和非垃圾邮件内容生成特征向量,统计得到的500个词语分别在该邮件中的出现概率
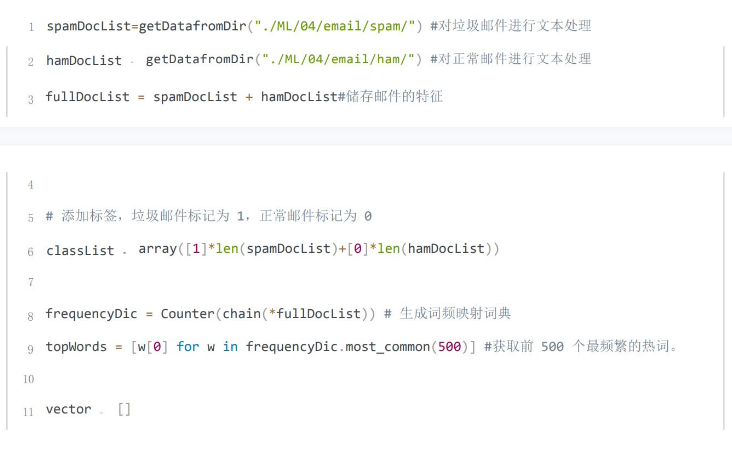
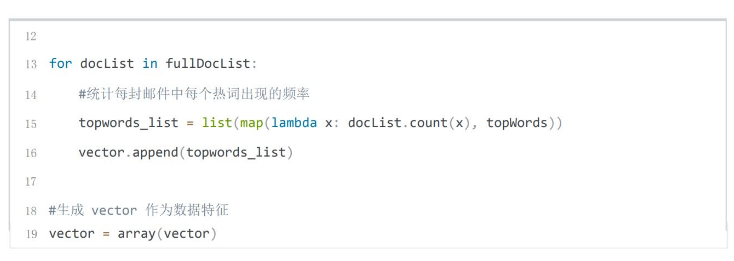
得到特征向量和已知邮件分类创建并训练朴素贝叶斯模型。

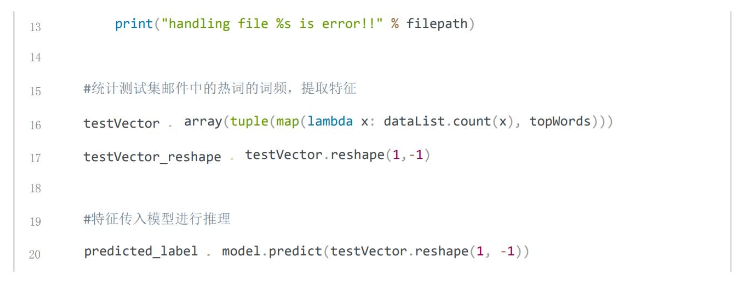
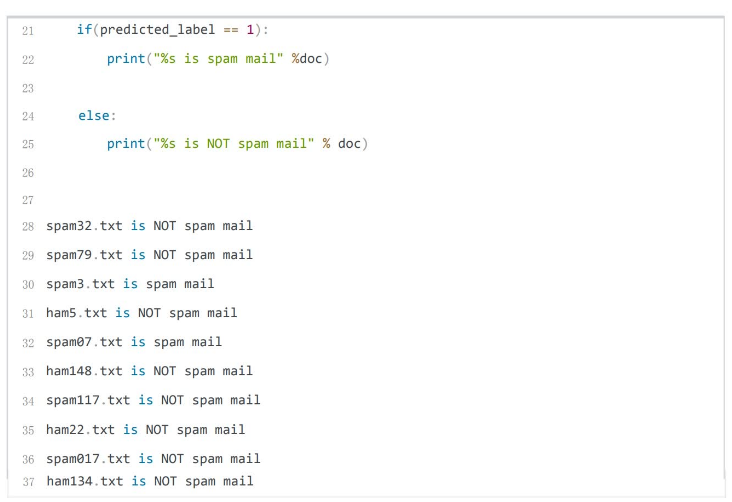
步骤6模型测试
读取测试邮件,对邮件文本进行预处理,提取特征向量。使用训练好的模型,根据提取的特征向量对邮件进行分类