欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
- 一起来实战部署spark2.2集群(standalone模式)
版本信息
- 操作系统 CentOS 7.5.1804
- JDK:1.8.0_191
- scala:2.12.8
- spark:2.3.2
机器信息
- 本次实战用到了三台机器,相关信息如下:
| IP 地址 | 主机名 | 身份 |
|---|---|---|
| 192.168.150.130 | master | spark的master节点 |
| 192.168.150.131 | slave1 | spark的一号工作节点 |
| 192.168.150.132 | slave2 | spark的二号工作节点 |
- 接下来开始实战;
关闭防火墙
- 执行以下命令永久关闭防火墙服务:
systemctl stop firewalld.service && systemctl disable firewalld.service设置hostname(三台电脑都做)
- 修改/etc/hostname文件,将几台电脑的主机名分别修改为前面设定的master、slave0等;
设置/etc/hosts文件(三台电脑都做)
- 在/etc/hosts文件尾部追加以下三行内容,三台电脑追加的内容一模一样,都是下面这些:
master 192.168.150.130
slave1 192.168.150.131
slave2 192.168.150.132创建用户(三台电脑都做)
- 创建用户和用户组,并指定home目录的位置:
groupadd spark && useradd -d /home/spark -g spark -m spark- 设置spark用户的密码:
passwd spark- 以spark账号的身份登录;
文件下载和解压(三台电脑都做)
- 分别去java、scala的官网下载以下两个文件:
jdk-8u191-linux-x64.tar.gz scala-2.12.8.tgz- 上述两个文件下载到目录/home/spark下,依次解压后,/home/spark下的内容如下所示:
[spark@localhost ~]$ ll
总用量 427836
drwxr-xr-x. 7 spark spark 245 10月 6 20:55 jdk1.8.0_191
-rw-r--r--. 1 spark spark 191753373 2月 2 08:49 jdk-8u191-linux-x64.tar.gz
drwxrwxr-x. 6 spark spark 50 12月 4 18:25 scala-2.12.8
-rw-r--r--. 1 spark spark 20467943 2月 2 08:49 scala-2.12.8.tgz- 修改/home/spark文件夹下的.bash_profile文件,在尾部增加以下内容(spark相关的是后面会用到的,这里把配置先写上):
export JAVA_HOME=/home/spark/jdk1.8.0_191
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export SCALA_HOME=/home/spark/scala-2.12.8
export PATH=${SCALA_HOME}/bin:$PATH
export SPARK_HOME=/home/spark/spark-2.3.2-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH- 执行以下命令,使得.bash_profile的修改生效:
source .bash_profile- 分别执行java -version和scala -version命令,检查上述设置是否生效:
[spark@localhost ~]$ java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
[spark@localhost ~]$ scala -version
Scala code runner version 2.12.8 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.spark的设置(只在master机器操作)
- 登录master机器:
- 去spark的官网下载文件spark-2.3.2-bin-hadoop2.7.tgz,下载到目录/home/spark下,在此解压;
- 进入目录/home/spark/spark-2.3.2-bin-hadoop2.7/conf;
- 执行以下命令,将"spark-env.sh.template"更名为"spark-env.sh":
mv spark-env.sh.template spark-env.sh- 打开文件spark-env.sh,在尾部增加以下内容:
export SPARK_MASTER_IP=node0
export SPARK_MASTER_PORT=7077
export SPARK_EXECUTOR_INSTANCES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=256M
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_CONF_DIR=/home/spark/spark-2.3.2-bin-hadoop2.7/conf
export JAVA_HOME=/home/spark/jdk1.8.0_191
export JRE_HOME=${JAVA_HOME}/jre- 进入目录/home/spark/spark-2.3.2-bin-hadoop2.7/conf,执行以下命令,将slaves.template更名为slaves:
mv slaves.template slaves- 打开文件slaves,将尾部的localhost删除,再增加以下内容:
slave1
slave2- 以上就是所有设置,接下来要将spark文件夹同步到其他机器上
将spark文件夹同步到其他机器
- 在master机器执行以下命令,即可将整个spark文件夹同步到slave1:
scp -r ~/spark-2.3.2-bin-hadoop2.7 spark@slave1:~- 期间会要求输入slave1的密码,输入密码后即可开始同步;
- 在master机器执行以下命令,即可将整个spark文件夹同步到slave2:
scp -r ~/spark-2.3.2-bin-hadoop2.7 spark@slave2:~- 期间会要求输入slave2的密码,输入密码后即可开始同步;
启动spark
- 以spark账号登录master机器,执行以下命令即可启动spark集群:
/home/spark/spark-2.3.2-bin-hadoop2.7/sbin/start-all.sh- 启动过程中,会要求输入slave1、slave2的密码,输入即可;
- 为了避免每次启动和停止都要输入slave1和slave2的密码,建议将三台机器配置ssh免密码登录,请参考《Docker下,实现多台机器之间相互SSH免密码登录》
- 启动成功后,可以通过浏览器查看启动情况,如下图,地址是:http://192.168.150.130:8080/
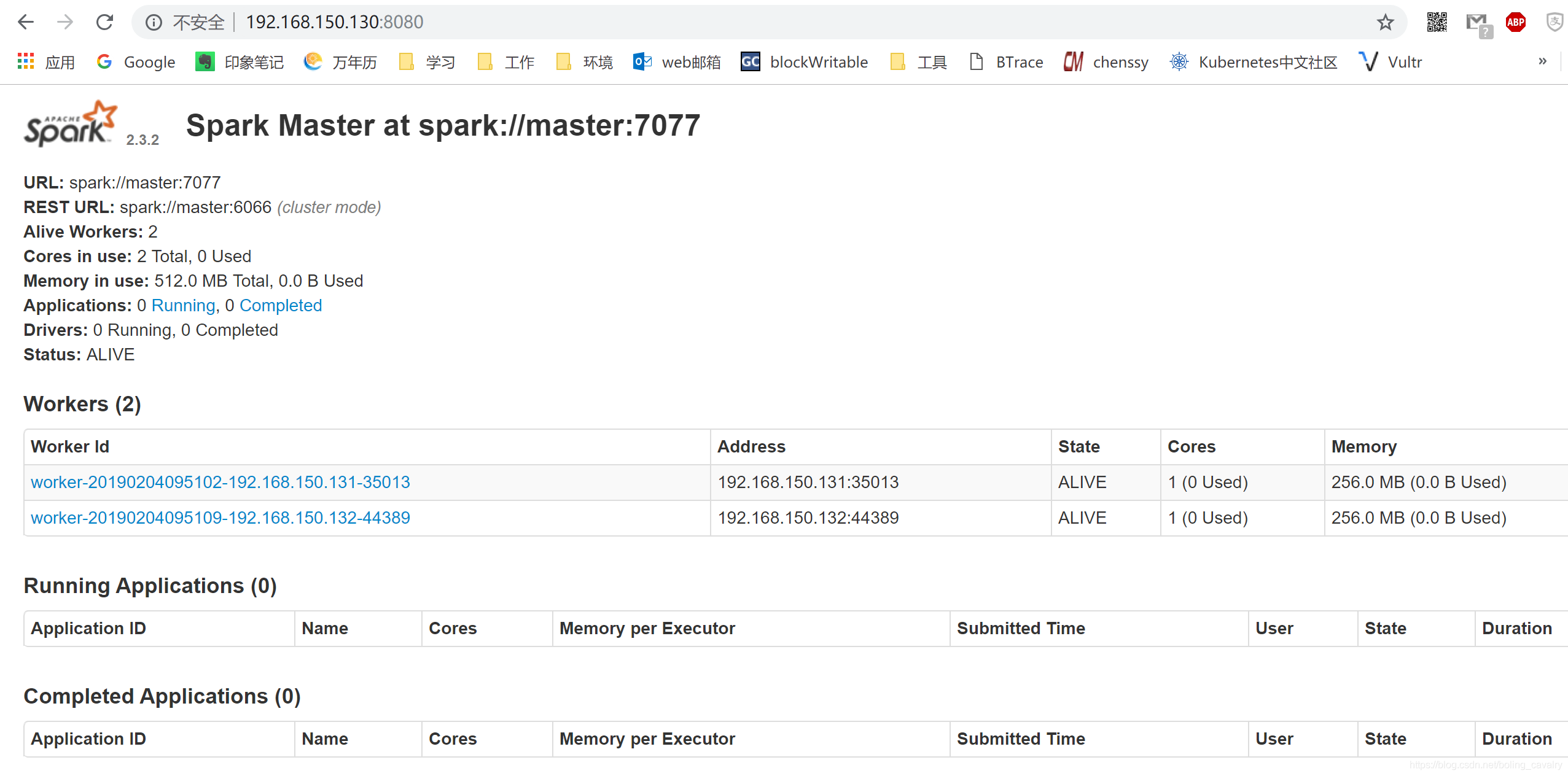
- 至此,spark集群部署成功,接下来的章节,我们会一起进行更多的spark实战;
欢迎关注51CTO博客:程序员欣宸
学习路上,你不孤单,欣宸原创一路相伴...










