【C/C++】空间换时间,使用函数调用的方式间接对除法操作进行优化
最近用godbolt看汇编代码时,发现对整型常量作为除数时,编译器会把除法操作优化成乘法与移位操作,证明见Labor of Division。之后搜了一下,发现除法操作的耗时相当的大。
有一篇博文放了某个特定处理器执行不同指令的延时核吞吐量的数据
从上面的数据可以看到,各种类型的除法操作比其他操作都慢了至少一个数量级,因此如何让CPU不执行除法指令变的相当重要。现在的编译器,无论是否开启编译器优化,只要识别到除数是一个整型常量,会将除法操作转化成乘法与移位操作。但是如果除数不是一个常量,即使开到-O3,编译器也无可奈何。在这我有个想法,通过switch打表的方法,先判断除数是多少,再去执行这个除数对应的乘法优化的操作。

对应的汇编代码如下:
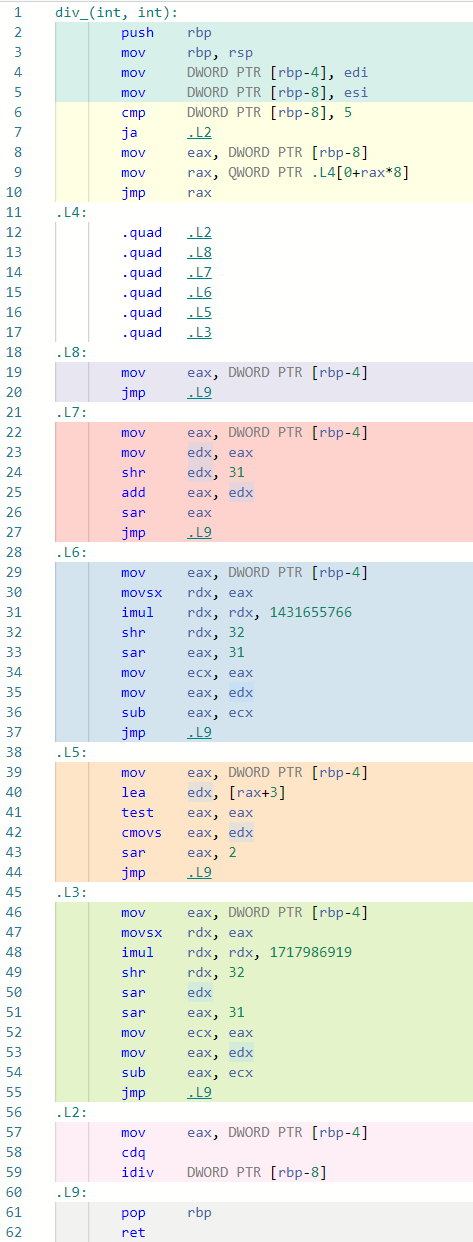
因为判断的case都是连续的值,因此可以直接通过计算偏移量,一步操作(line 9)就能找到需要跳转到的代码块(.L2 ~ .L8)。这样就能将case中列出来的除数对应的除法操作给优化掉。但是这样做的空间开销特别大,如果要将所有的INT_32给放到switch中,二进行程序的空间会直接爆炸,假设一个case会增加8 * 64bits的二进制空间,那么2^32个case就是256GB的空间,显然不现实。
通过上述分析,可以得出结论,做一个通用的映射去优化除法操作不现实。但是假设有这样一种场景,某一段区间内的数值被选作除数的概率较大,则可以对这部分的除法进行特定的优化,如我仅当除数在 0~511 这个范围内,才进行打表优化操作。这样的话,对这些值的除法操作的时间性能会有提升,但是其他区间的数值反而会有负面影响,额外带来了函数调用的开销,和查表跳转的开销。
接下来的实验会比较这种做法对实际运行时间的影响如何。
主要比较不同大小(512、1024)的打表操作对除法操作的影响。
观察了一下汇编代码,与没设置编译优化相比,开了-O3能稍微优化一下函数调用的开销,然后在循环内的i++操作,可以穿插到除法操作的范围内,应该是为了更好的流水线吧。
#include <bits/stdc++.h>
using namespace std;
using namespace chrono;
#define N9 1000000000
#define N8 100000000
int div_512(int i, int j) {
switch (j) {
case 1 : return i / 1;
case 2 : return i / 2;
case 3 : return i / 3;
case 4 : return i / 4;
case 5 : return i / 5;
case 6 : return i / 6;
case 7 : return i / 7;
// ......
case 511 : return i / 511;
case 512 : return i / 512;
default : return i / j;
}
}
int div_1024(int i, int j) {
switch (j) {
case 1 : return i / 1;
case 2 : return i / 2;
case 3 : return i / 3;
case 4 : return i / 4;
case 5 : return i / 5;
case 6 : return i / 6;
case 7 : return i / 7;
// ......
case 1023 : return i / 1023;
case 1024 : return i / 1024;
default : return i / j;
}
}
int main() {
int res = 0;
auto t0 = steady_clock::now();
for (int i = 0; i <= 10000; i++) {
for (int j = 1; j <= 1000; j++) {
res += N8 / j;
}
}
auto t1 = steady_clock::now();
auto d = duration_cast<nanoseconds>(t1 - t0);
cout << "orignal div opcode, divisor in range(1, 1000):\t" << d.count() << "ns" << endl;
int res1 = 0;
t0 = steady_clock::now();
for (int i = 0; i <= 10000; i++) {
for (int j = 1; j <= 1000; j++) {
res1 += div_512(N8, j);
}
}
t1 = steady_clock::now();
d = duration_cast<nanoseconds>(t1 - t0);
cout << "using div_512, divisor in range(1, 1000):\t" << d.count() << "ns" << endl;
t0 = steady_clock::now();
for (int i = 0; i <= 10000; i++) {
for (int j = 1; j <= 1000; j++) {
res1 += div_1024(N8, j);
}
}
t1 = steady_clock::now();
d = duration_cast<nanoseconds>(t1 - t0);
cout << "using div_1024, divisor in range(1, 1000):\t" << d.count() << "ns" << endl;
cout << "print for avoid erase loop\t" << res + res1 << endl;
t0 = steady_clock::now();
for (int j = 1; j <= 10000000; j++) {
res += N8 / j;
}
t1 = steady_clock::now();
d = duration_cast<nanoseconds>(t1 - t0);
cout << "orignal div opcode, divisor in range(1, 10000000):\t" << d.count() << "ns" << endl;
t0 = steady_clock::now();
for (int j = 1; j <= 10000000; j++) {
res1 += div_512(N8, j);
}
t1 = steady_clock::now();
d = duration_cast<nanoseconds>(t1 - t0);
cout << "using div_512, divisor in range(1, 10000000):\t\t" << d.count() << "ns" << endl;
t0 = steady_clock::now();
for (int j = 1; j <= 10000000; j++) {
res1 += div_512(N8, j);
}
t1 = steady_clock::now();
d = duration_cast<nanoseconds>(t1 - t0);
cout << "using div_1024, divisor in range(1, 10000000):\t\t" << d.count() << "ns" << endl;
cout << "print for avoid erase loop\t" << res + res1 << endl;
}
gcc version 8.1.0 (x86_64-posix-seh-rev0, Built by MinGW-W64 project) :
PS D:\VSworkspace\a_code> g++ div.cpp -O3 -o div
PS D:\VSworkspace\a_code> ./div
orignal div opcode, divisor in range(1, 1000): 57149100ns
using div_512, divisor in range(1, 1000): 46229900ns
using div_1024, divisor in range(1, 1000): 73678900ns
print for avoid erase loop 260009052
orignal div opcode, divisor in range(1, 10000000): 40623800ns
using div_512, divisor in range(1, 10000000): 40749100ns
using div_1024, divisor in range(1, 10000000): 41381900ns
print for avoid erase loop 958885988
gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.12) :
ljq@ljq1:~/fujx_test_cpp$ g++ -std=c++14 div.cpp -O3 -o div
ljq@ljq1:~/fujx_test_cpp$ ./div
orignal div opcode, divisor in range(1, 1000): 30892666ns
using div_512, divisor in range(1, 1000): 25682050ns
using div_1024, divisor in range(1, 1000): 49336470ns
print for avoid erase loop 260009052
orignal div opcode, divisor in range(1, 10000000): 25391691ns
using div_512, divisor in range(1, 10000000): 25821234ns
using div_1024, divisor in range(1, 10000000): 26270255ns
print for avoid erase loop 958885988
gcc version 10.2.0 (Debian 10.2.0-16) :
┌──(kali㉿kali)-[~/testCpp]
└─$ g++ div.cpp -std=c++14 -O3 -o div
┌──(kali㉿kali)-[~/testCpp]
└─$ ./div
orignal div opcode, divisor in range(1, 1000): 60122623ns
using div_512, divisor in range(1, 1000): 45949276ns
using div_1024, divisor in range(1, 1000): 79166201ns
print for avoid erase loop 260009052
orignal div opcode, divisor in range(1, 10000000): 41608982ns
using div_512, divisor in range(1, 10000000): 41650935ns
using div_1024, divisor in range(1, 10000000): 41851488ns
print for avoid erase loop 958885988
在除数范围较小的情况下,即命中div函数switch内的优化代码部分的概率较大。调用div_512比直接做除法性能上有明显的提升,但是令人费解的是,div_1024的效率却有了明显的下降,这个原因我初步的推测是div_1024的代码太长加上for循环,导致cache的命中率降低。
我将外层的for去掉后,结果如下:
orignal div opcode, divisor in range(1, 1000): 5731ns
using div_512, divisor in range(1, 1000): 29666ns
using div_1024, divisor in range(1, 1000): 31129ns
div方法的效率比直接做除法差了好多,这里应该是因为第一次访问到div代码段的开销较大。
如果除数的氛围很大,即命中优化代码的概率较小。此时三种方法的时间开销也基本相同,虽然div方法有额外的调用开销,但是平均执行时间仍然和直接做除法差不多。
根据实验结果可以推断,如果除数不为整型常量,且除数的取值范围较为集中,并且在程序在短时间内有较多的除法操作,可以用调用函数加switch打表的方式,来提升除法操作的效率。








