差异基因筛选
差异系数,可以体现对象数据与标准数据的相对差异,数值越大,表示不平衡程度越大[1]
设x与y分别为对象数据和标准数据,则差异系数k的表达式为:
^{2} / \sum y_{i}^{2}}")
差异倍数
差异表达基因分析:差异倍数(fold change), 差异的显著性(P-value) | 火山图 - Life·Intelligence - 博客园Differential gene expression analysis:差异表达基因分析 Differentially expressed gene (DEG):差异表达基因 Volcano Pl
关于R中p值的理解_yangnuanyang的博客-CSDN博客_r语言p值进行线性回归lm后执行summary函数之后,会有Coefficients:Estimate Std. Error t value Pr(>|t|) 这样的值出现,其中P值我是这样理解的P值是用来判定假设检验结果的一个参数,也可以根据不同的分布使用分布的拒绝域进行比较。P值(P value)就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。这样定义原假设,我们希望成立实现的研究假...javascript:void(0)
df = read.delim('DEG_nofiltered.xls',
header = T, sep = '\t')
#### 3.1.1 根据差异倍数大于2且P值小于0.05筛选
dim(subset(df, FC > 2 & pval < 0.05 |
FC < 0.5 & pval < 0.05))
df$logFC = log2(df$FC)
deg = subset(df, abs(logFC) > 1 & pval < 0.05)
dim(deg)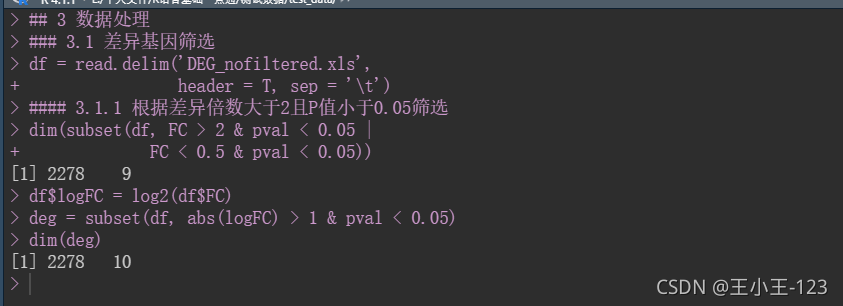
### 3.2 排序
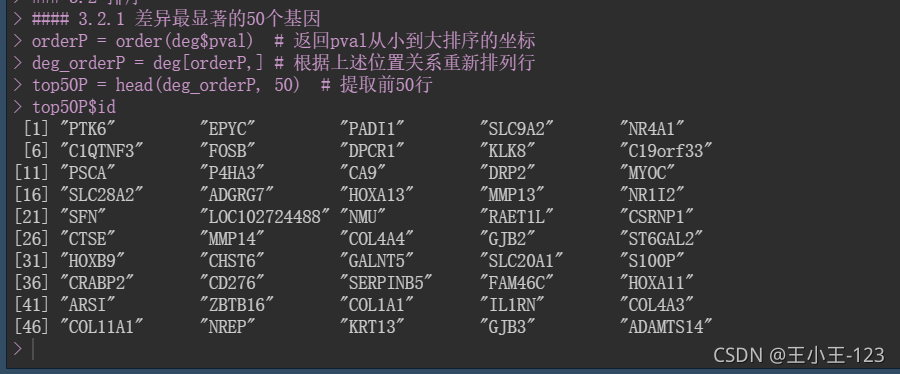
#### 3.2.1 差异最显著的50个基因
orderP = order(deg$pval) # 返回pval从小到大排序的坐标
deg_orderP = deg[orderP,] # 根据上述位置关系重新排列行
top50P = head(deg_orderP, 50) # 提取前50行
top50P$id
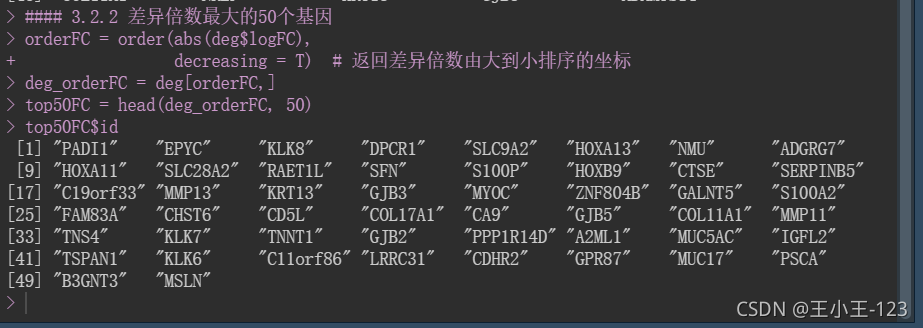
#### 3.2.2 差异倍数最大的50个基因
orderFC = order(abs(deg$logFC),
decreasing = T) # 返回差异倍数由大到小排序的坐标
deg_orderFC = deg[orderFC,]
top50FC = head(deg_orderFC, 50)
top50FC$id
将数据写入
### 4.2 txt文件
write.table(deg_TF_all, 'deg_TF_all.xls',
col.names = T, row.names = F,
sep = '\t', quote = F)
### 4.3 xlsx文件
library(writexl)
write_xlsx(list(mysheet=deg_TF_all),
'deg_TF_all.xlsx')
每文一语
这个世界上没有单纯的一如既往,有条件的人绝对不会选择为善意付出时间!










