本文是【从ORACLE/MySQL到OceanBase】序列第二篇。6月27日(本周四)晚在云和恩墨旗主办的DTC线上数据库技术实战峰会做1小时的直播分享,主题为《从ORACLE、MySQL到OceanBase:入门介绍》,查看直播回放请到:`https://cs.enmotech.com/course/play/12`,第4章 。
概述
OceanBase是阿里巴巴和蚂蚁金服完全自主研发的通用的分布式关系型数据库,定位商用企业数据库。OceanBase能提供金融级别的可靠性,目前主要应用用于金融行业,同时也适用于非金融行业场景。
OceanBase从1.0版本架构重构后就闭源,目前主要有1.x和2.x两个版本序列。1.x版本兼容MySQL 常用语法,2.x版本以兼容ORACLE常用语法为目标。OceanBae支持多租户,即在一个OceanBase集群里会划分出多个租户(即实例),而租户的类型是兼容MySQL或者ORACLE。业务方使用的只是租户(实例),是集群能力的一个子集。在使用体验上会感觉租户像MySQL或ORACLE,但又不完全一样。OceanBase并不是在重造一个MySQL或ORACLE,而只是在功能接口上兼容它们,在底层架构上,不管哪种租户都有分布式能力。
所以,当业务开发和运维从ORACLE/MySQL转OceanBase后,需要了解一些OceanBase的原理和不同之处,本文主要就是对OceanBase跟ORACLE/MySQL的相同之处和不同之处做个概要说明。
OceanBase是什么样子?
ORACLE软件是多进程程序,启动后会开辟一块共享内存。ORACLE部署形态有单实例、集群RAC、主备Dataguard。MySQL软件是单进程,进程名叫mysqld,有的还会有守护进程mysql_safe。MySQL的部署形态有单实例、主从单向同步或主主双向同步和MySQL Cluster(用的比较少)。
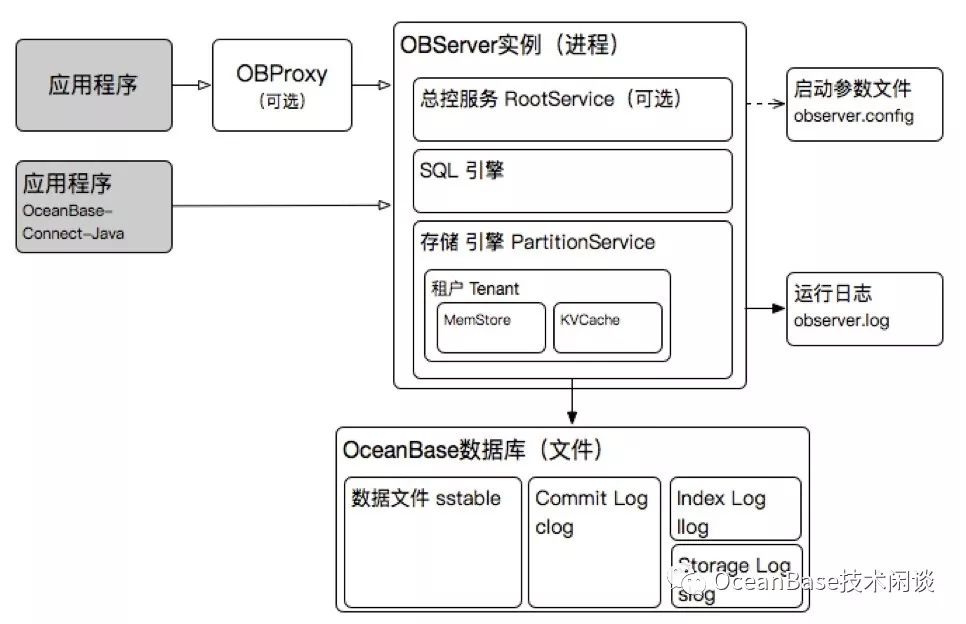
OceanBase的软件是单进程,名字叫observer。OceanBase是分布式数据库,集群部署,通常每个机器(后面统一称为节点)上会启动一个observer进程,各个节点的observer进程组成一个集群运行。虽然应用可以直接访问任意一个节点的实例,但不推荐。
通常是在OceanBase集群前面启动一个或多个反向代理OBProxy。OBProxy只负责数据路由和传输,不涉及到数据运算(如连接、统计、合并或排序等)。OBProxy的作用类似ORACLE的监听程序,不同的是数据返回的时候也是从OBProxy回去。这个以后再专门详细介绍。对于业务而言,OBProxy就是数据库的代表,可用性也很重要。所以一般会部署多个OBProxy挂载负载均衡设备或软件下面以VIP形式对外提供服务。
observer架构
每个observer进程包含两个基本模块,一是SQL引擎,负责SQL解析、执行计划生成、SQL运算等;一是存储引擎,负责存取数据、合并冻结等。这两项功能实际上ORACLE和MySQL都有,只是很少这么提。在OceanBase集群里,还需要一个总控服务rootservice,负责集群级别的一些任务调度,详情可以参看《OceanBase数据库实践入门——了解总控服务》。总控服务只需要存在某个节点上,所以是可选的。
observer进程启动后发生什么?
observer进程启动时,默认会将所在节点(即机器)的绝大部分资源据为己有。比如说内存,会占有80%左右,数据目录的空间,会占有90%左右,CPU,会保留2个给OS,其他全部声明为OB的。当然我们都知道,除了OS自身,谁也不能独占CPU。observer进程本质上也只是OS里的一个进程。所以对CPU的占有是声明式的。当然这里的比例都是参数指定的,保存在参数文件里,可以在启动命令行里修改参数。
observer数据目录会有一个数据文件,默认大小是数据目录的90%。这个文件承载了这个节点所有的OB数据。所以OB里没有表空间文件、或者每个表一个文件这种提法。不过OB有事务日志文件,叫Commit Log,简称clog。还有Index log, Storage Log等。observer还有运行日志文件,方便排查问题。目前日志信息量非常大,主要是面向内核开发的。
OceanBase集群样子
要搭建一个OceanBase集群,至少需要3台机器。实际生产多是3的倍数。这些都是三副本架构的要求。机器会被等分为3份,每份划归一个Zone。Zone是逻辑划分,实际可以对应为机房、单个机房的包间或者单个包间里的机柜。OceanBase集群是无共享架构的,不依赖共享存储,不需要直连线。搭建方法请参考《OceanBase数据库实践入门——手动搭建OceanBase集群》。

当每个机器上都启动observer进程后,集群初始化成功后架构图就如下:
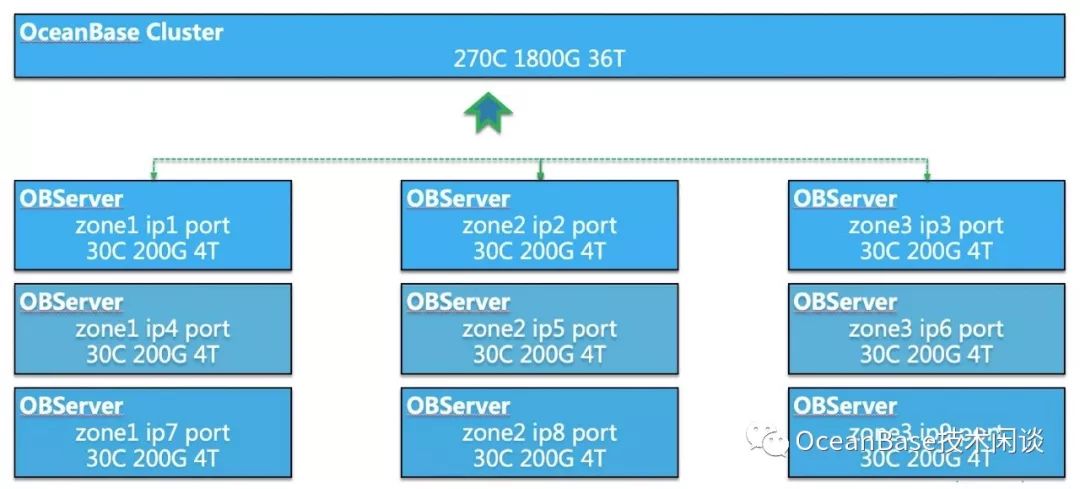
每个observer节点都有一定的资源能力,组成集群后,所有资源就聚集为集群的能力,总共有270C 1800G 36T。
OceanBase数据组织形式
当业务数据很多时,并不一定会放在一个数据库下。会根据业务模块划分多个集合。
在ORACLE里,每个实例下会分多个schemas,通常schema就是用户。不同用户的数据逻辑上彼此隔离,除非明确授权,否则不能跨用户访问。
在MySQL里,每个实例下会分多个databases,也有多个用户,不同用户可以访问不同的database,除非明确授权、否则不能访问其他用户的database。
在OceanBase里,首先会有多个租户(实例)。租户与租户之间的数据是逻辑隔离的,彼此无法互通。租户的兼容模式有ORACLE和MySQL两种(2选一)。兼容ORACLE时,租户下面会分多个schemas,跟ORACLE行为一致;兼容MySQL时,租户下面会分多个databases,跟MySQL行为一致。

所以,有的人使用OceanBase会问支持多个数据库吗?当理解上面这个设计后,答案不言自明。
OceanBase的原理
OceanBase怎样利用机器资源?
数据库的性能好不好取决于内外两方面,内部因素就是内核产品自身能力,外部因素就是机器资源。传统ORACLE/MySQL以单实例形态部署的时候,最大只能发挥一台机器的能力,使用主备架构或者集群部署的时候,倒是可以发挥多台主机能力。但是这种机器资源管理的粒度还是很粗。
云数据库在机器资源管理上就好一些,能够根据客户需求定制特别规格的实例。云数据库本质上就是在卖机器资源,按资源规格付费。其中一种实现方案就是单机多实例部署。单机多实例部署的时候,内存资源各自是独占的,可以分。但是磁盘的IOPS能力和CPU能力通常是共享的。云数据库厂商的一种做法就是利用linux的cgroup对cpu和iops做资源隔离。现在流行的docker虚拟化技术更好一些,可以单机起多个docker,每个docker里一个mysql实例。当然这只是云厂商其中一个解决方案,更好的解决方案还有计算与存储分离,大量使用分布式存储产品。这是另外一个话题。
在OceanBase里,前面我们看到了集群把所有机器资源聚合在一起,然后又按需求分配给多个租户。这个本身就是一种云数据库思想。所以OceanBase天然就适合云数据库,不过跟云数据库业务没有必然联系。OceanBase目前主要都是私有化部署,在物理机上部署。不建议部署在虚拟机上(规模小的时候虚拟化没有意义,只会带来性能损耗)。
每个租户的资源是一个小的资源池(Resource Pool),是集群资源池的子集。租户的资源池由至少三个资源单元(Unit)组成。Unit存在于节点内部,不能跨节点存在。Unit在节点内的位置并不固定。同一个Zone内节点数如果大于等于2的话,Unit是可以在同一个Zone内部多个节点之间自由迁移。这是OceanBase负载均衡的第一个方法。
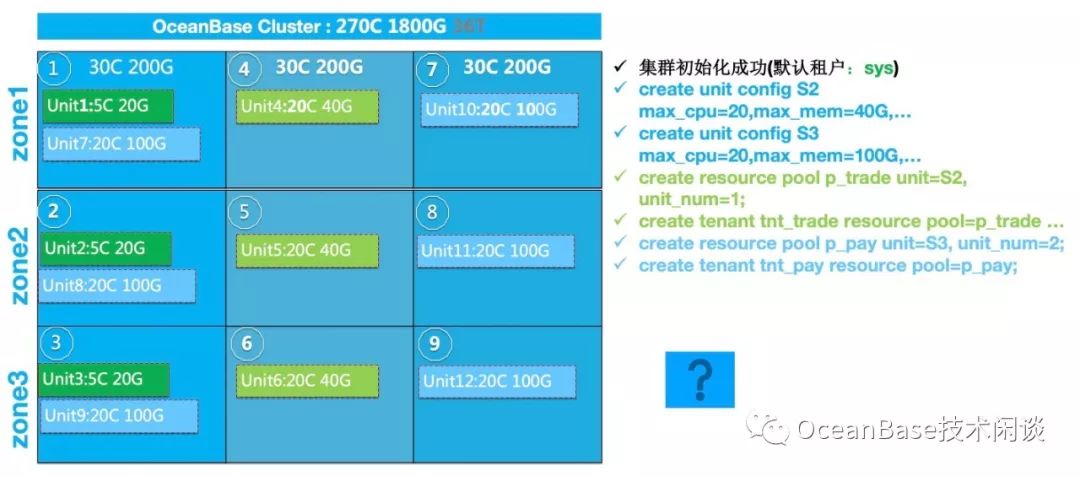
有关OceanBase对资源的使用方式和负载均衡详情参见文章《揭秘OceanBase的弹性伸缩和负载均衡原理》。
OceanBase怎样分配数据存储?
跟ORACLE一样,OceanBase使用表存储业务数据。OceanBase的表是索引组织表,有非分区表和分区表两种。非分区表只有一个分区,分区表有多个分区。分区就是表的子集。
每个分区只能在租户的Unit内部创建,分区不能跨越Unit存在。当租户的资源池在每个Zone里有多个Unit时,分区创建时就有多个选择。并且分区也不会固定在某个Unit内部。
每个分区会有三个副本,其中角色是1个Leader副本,2个Follower副本。默认只有Leader副本提供读写服务,哪个节点内部有Leader分区副本,哪个节点就可能会有访问。分区可以在同一个Zone的多个Unit之间自由迁移,这就是OceanBase负载均衡的第二个方法。
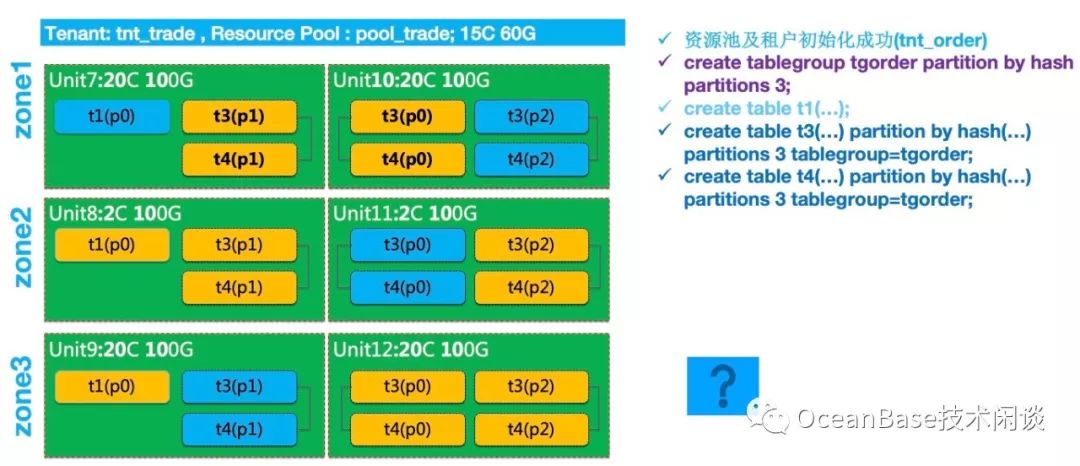
图中t3和t4业务上关联非常密切(有表连接逻辑),二者分区策略完全一样,可以放到一个表分组(tablegroup)里,这样两个表的同号分区以及Leader就被约束在同一个Unit内部。当t3和t4做表连接时,可以规避跨节点请求。
有关OceanBase对分区的使用方式和负载均衡详情参见文章《揭秘OceanBase的弹性伸缩和负载均衡原理》。
OceanBase的多副本原理
多副本是一种数据冗余技术,在ORACLE/MySQL里也有,只是不常这么提。
ORACLE的主备架构Dataguard可以说是两副本。ORACLE多副本之间内容同步是靠主库传输Redo给多个备库,然后备库应用该Redo。在同步Redo的方式上ORACLE就有多种策略。最大保护、最大可用、最大性能。其中最大保护最安全,主库事务提交会等一个备库Redo落盘成功,所以Redo有保障了,可以保证主备强一致。缺点是性能不是最好,并且如果备库都不可用的时候,主库也拒绝服务了。所以通常建议1主2备。这时候也是三副本形态。还有个问题是主库不可用的时候,需要DBA做主备切换,DBA必须能正确选择出拥有全部Redo的那个备库。
MySQL的主从复制架构也可以说是两副本,副本之间内容同步靠从库拉取主库的Binlog以及应用Binlog。Binlog里面是SQL,是逻辑同步,这个跟Redo比不了。不过MySQL还是尽力的保证Binlog可靠性,所以就推出半同步(Semi-Sync)技术,主库的事务提交也会等待备库的Binlog接收确认(不一定是落盘确认),如果等待超时主库就降级为异步同步(完全不等待备库确认了)。所以通常也建议使用半同步时配置1主2从。同样主故障时,也需要DBA手动激活从库,需要选择拥有全部Binlog的从库。
OceanBase至少三副本,副本之间使用Paxos协议同步Leader副本的Redo到Follower副本。策略是三个成员里只要有超过半数以上成员接收Redo并落盘成功确认后,Leader副本上的事务即可提交。在Leader出现故障时,只要还有多数成员存活,OB就会从中选出新的Leader,并且确保这个新Leader拥有全部的Redo。所以OB的三副本是保证绝对不丢数据,自动故障切换两个能力。这点跟ORACLE/MySQL的三副本有很大区别。
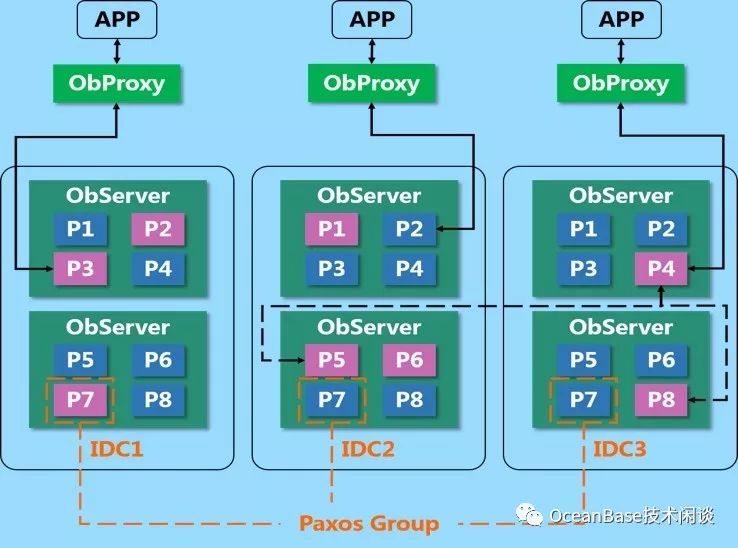
在上面描述多副本原理过程中也提到了高可用。这里就多说一点。ORACLE/MySQL的主备切换的粒度是实例维度,而OceanBase里的故障切换的粒度是分区。每个分区的三副本是一个独立的Paxos Group,可以自行独立选主。一个节点故障时,也只有节点内部为Leader的副本服务会中断,并自动选出新的Leader。这是OceanBase跟ORACLE/MySQL相比最大的区别。
OceanBase的开发
锁、事务和超时机制
OceanBase的租户兼容MySQL或ORACLE,常用的数据类型和语法都还支持。这点使用没什么问题。需要注意的是在锁和事务方面。
OceanBase的锁是行锁,也有表锁,但是没有锁升级策略。OceanBase的事务都有版本号,类似于ORACLE的SCN,读默认是快照读,不阻塞写。OceanBase的事务隔离级别目前只支持读已提交(RC)。如果要规避不可重复读问题,则需要在读上加锁(支持SELECT ... FOR UPDATE).
在租户内,如果事务修改的分区跨越节点了,就是分布式事务,OceanBase目前也是支持的,原理是两阶段提交,强一致。业务感知不到也不需要知道这个是分布式事务。如果业务事务跨越了租户边界,则这种分布式事务需要借助于分布式事务中间件产品解决。详情请参见《说说数据库事务和开发(下)—— 分布式事务》。
OceanBase针对慢SQL有个超时机制,以防止慢SQL占用数据库资源,默认时间是10秒。慢SQL不仅包括查询慢的SQL,还包括SQL自身性能没问题但是被阻塞的DML SQL。在MySQL里对于锁等待也有超时机制,对于慢SQL也有强制中断机制(默认没有启用)。
OceanBase对于长事务(长时间不提交)采取的是强制超时机制,默认时间是100秒。由于OceanBase没有UNDO,并且事务未提交之前,Redo都在内存里,所以大事务会占用一定内存资源。
这两个超时参数都可以调整。调整为很大时效果就等同于不干预,跟ORACLE/MySQL就一致了。我们并不建议简单调大。慢SQL和长事务是业务设计问题,需要业务层面尽可能的解决。详细描述请查看文章《从ORACLE/MySQL到OceanBase:数据库超时机制》。
SQL调优
OceanBase的SQL执行设计参照了ORACLE的设计,有硬解析、软解析,有执行计划缓存。执行计划目前也很丰富,连接算法有嵌套循环、哈希、归并连接、半连接(semi-join)、anti-jon。支持左连接或右连接,子查询等,支持SQL改写等等。这块以后再详细总结。
查看执行计划的命令是explain,这点跟MySQL保持一致(简洁)。
OceanBase提供一序列内部视图(gv$视图或v$视图)用于诊断性能。这点跟ORACLE的性能视图比较类似。
同时OceanBase还有一个视图gv$sql_audit拥有集群执行过的全部SQL,无论SQL是否成功还是失败。从中可以查看SQL的执行时间、节点、执行计划类型、报错代码、执行时间、等待时间、读取块数、返回行数、影响行数等等。详情请查看文章《阿里数据库性能诊断的利器——SQL全量日志》。
更值得一提的是OceanBase也实现了ORACLE的Outline功能,能在线干预执行计划。如调整连接算法、顺序或者索引等。对于那些不可调整的慢SQL,为了消除它的影响,Outline支持对该慢SQL做限流处理。如强制串行执行等。详情请查看文章《阿里数据库性能诊断的利器——SQL执行干预》。
用户问题
本次直播回放地址:https://cs.enmotech.com/course/play/17 第3章。
直播用户问题精选。
- Q:分区的leader承担读写,follow只是用来容灾嘛
A:默认是这样的,至少要三副本才可以提供自动故障切换并且不丢数据的能力。如果业务可以接受延时,也可以读取follower副本以实现读写分离效果。 - Q:咱们有OB的培训教材和推荐书籍吗?
A:请查看《OceanBase学习资源》。 - Q:分区的标准是什么?业务嘛?
A: 是的。分区是水平拆分其中一种方法,要基于业务场景考虑。详细分析请查看《分布式数据库选型——数据水平拆分方案》。 - Q:增加节点实现硬件扩容,需要重启整个集群吗?如何把新加入的硬件资源添加到整个集群?
A:不需要。OceanBase的扩容有集群扩容和租户扩容两种,都是在线进行,对业务无影响。详情请查看《揭秘OceanBase的弹性伸缩和负载均衡原理》。 - Q:节点数改变,数据是如何进行数据重分布?
A:节点数改变后,资源单元Unit会在节点间发生迁移,节点内的数据自然也就重新分布了。这个是在线自动负载均衡机制。详情请查看《揭秘OceanBase的弹性伸缩和负载均衡原理》。 - Q:和mycat相比,应用需要单独开发的地方多吗?
A:和mycat相比,相同的地方都是应用需要选择拆分维度,核心高并发SQL尽可能带上拆分键。不同的是应用不需要关注数据重分布、分布式事务、扩容缩容等。 - Q:SQL超时后,所说的应用回滚是指应用要捕获这个超时,然后做补偿是吗?
A:应用需要捕获数据库异常,然后自行决定处理逻辑(提交还是回滚)。
更多后续分享敬请关注公众号:obpilot











