一、需要的知识
xpath语法,数据类型转化,基础的爬虫。
xpath适用于在网页数据为html时进行数据清洗,从而达到提取数据的目的。我这里推荐一个特别好用的插件,xpath-helper。如果各位友友有需要的话可以私聊我,我后续会更新安装教程以及使用操作。
数据类型转化:重点 从网页上拿下来的数据都是字符串格式数据<class 'str'> 是不能直接通过xpath语法进行提取数据的就需要转换数据类型 str>>xpath对象。如此一来我们通过第三方库进行格式的转化。通过html模块里面的etree类里面的大写的HTML方法 返回可通过xpath语法提取数据的对象 html。
二、第三方库的下载以及介绍
第三方库下载:cmd中输入pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
作用:将爬虫拿到的字符串类型的数据转化为可提取的html类型的数据。
三、爬取思路
抓取数据流程1抓包,,发送请求2数据清洗3数据保存
目标url:https://movie.douban.com/top250。如果对于爬虫的基本流程不知道,建议看一下我的第一篇文章熟悉一下
爬虫实战https://blog.csdn.net/qq_54857095/article/details/122268948?spm=1001.2014.3001.5501
四、页面分析
这是我们打开的界面
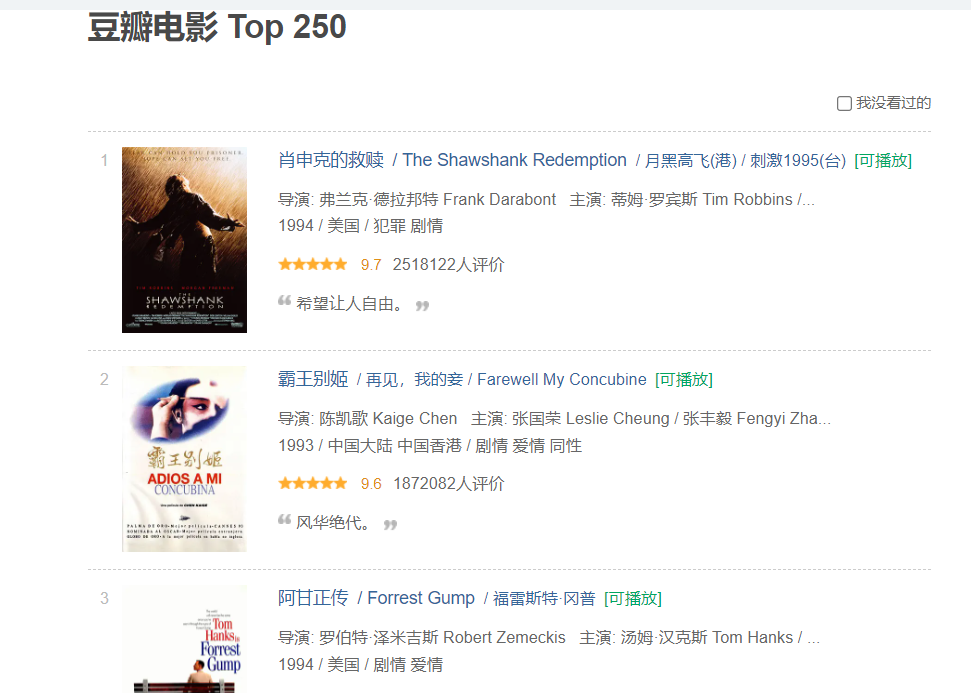
我们可以得知一页25个电影。右键检查之后发现数据很是规整,这正好符合我们爬虫工程师的口味。
然后通过点击
随后鼠标点击想要提取的文本会加载到
如上页面(按照肖申克的救赎举例),随后根据xpath语法进行对目标文本进行提取。(鼓励大家自己写xapth语法,当然也可以直接复制粘贴xath,但是可能提取的不准确。)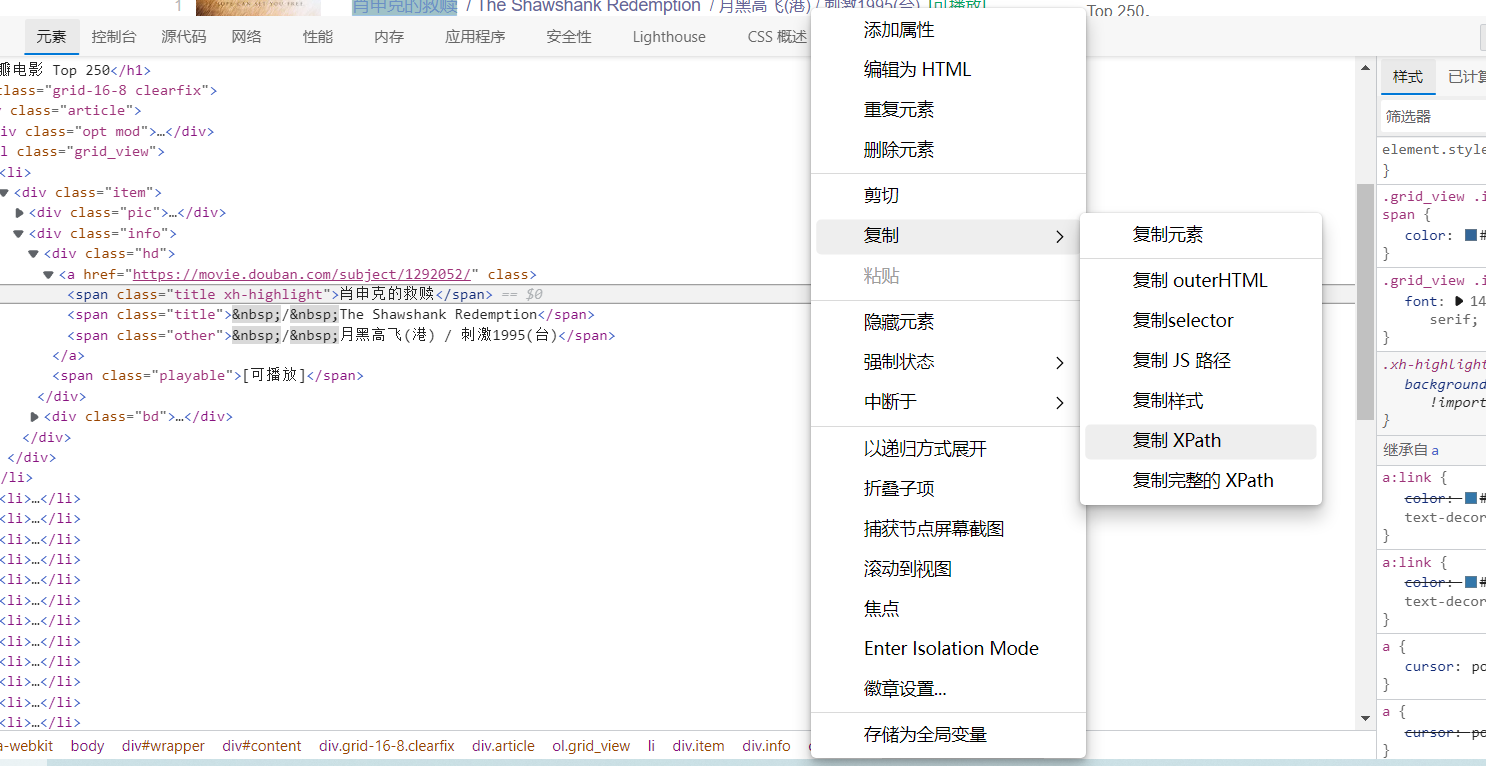
简易做法如上图,直接复制xpath。随后就用到了我们的神奇小插件。废话不多说直接看图。
左边:xpath语法。右边:相应内容。如此一来我们的xpath语法就构造完成了。但是我们需要的拿到本页的25项数据。在xpath语法中*表示此类节点之下的所有数据。我们根据这个可以知道,每一个li节点包含一个电影数据。
随后我们修改xpath语法进行操作 
修改后便拿到25项数据。按照同样的方法可以拿到,电影链接,以及评分。
五、代码实现、
"""提取html格式数据 安装模块 lxml
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
任务:通过lxml去提取豆瓣电影数据
1电影名
2评分
3链接
4.简介
使用:
"""
from lxml import etree
import requests
import json
"""
抓取数据流程
1抓包,,发送请求
2数据清洗
3数据保存
https://movie.douban.com/top250
"""
# 1抓包,,发送请求
# 确认url
url="https://movie.douban.com/top250"
# 构建用户代理
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36"
}
# 发送请求,获取响应
response=requests.get(url=url,headers=headers)
print(response.encoding)
res_data=response.content.decode()
# 重点 从网页上拿下来的数据都是字符串格式数据<class 'str'> 是不能直接通过xpath语法进行提取数据的
# 就需要转换数据类型 str>>xpath对象
# print(res_data)
# 通过html模块里面的etree类里面的大写的HTML方法 返回可通过xpath语法提取数据的对象 html
html=etree.HTML(res_data)
print(html)
# 现在就能通过xpath语法进行数据提取
# 通过html对象的xpath方法进行提取 xpath不会自动生成 自己手写 语法同样的也是字符串形式
# 通过xpath语法提取返回的对象(变量) 列表类型 文件保存 判断 if 变量==[]:没数据
# 1电影名字数据
title=html.xpath('//div[@class="hd"]/a/span[1]/text()')
# print(title)
# 2评分数据
score=html.xpath('//div[@class="bd"]/div[@class="star"]/span[2]/text()')
# print(score)
# 3链接
link=html.xpath('//div[@class="info"]/div[@class="hd"]/a/@href')
# tips 当观察提取的数据时 发现只有两个节点 就可以通过 数量来确认节点
# //div[@class="info"]/div[1]/a/@href
# print(link)
# 4.简介
# breif=html.xpath('//div[@class="bd"]/p[2]/span/text()')
# print(link)
with open("豆瓣.json","w",encoding="utf-8")as file1:
for node in zip(title,score,link):
item={}
item["title"]=node[0]
item["score"]=node[1]
item["link"]=node[2]
# item["breif"]=node[3]
print(item)
str_data=json.dumps(item,ensure_ascii=False,indent=2)
file1.write(str_data+",\n")
# 豆瓣翻页(前十页)数据提取 保存为json格式数据 截图发我
#
#
#
# 问问题复制源码
#/html/body/app-wos/div/div/main/div/div[2]/app-input-route/app-base-summary-component/div/div[2]/app-records-list/app-record[1]/div[2]/div[1]/app-summary-title/h3/a/@href
#/html/body/app-wos/div/div/main/div/div[2]/app-input-route/app-base-summary-component/div/div[2]/app-records-list/app-record[2]/div[2]/div[1]/app-summary-title/h3/a/@href
#/html/body/app-wos/div/div/main/div/div[2]/app-input-route/app-base-summary-component/div/div[2]/app-records-list/app-record[5]/div[2]/div[1]/app-summary-title/h3/a/@href
这就是我的代码以及实现过程。最终效果如下。
其中还包括一个文件(写入文件操作,如果有不会的可以来私信我。)效果如下。
五、小tips
在写入文件时有美化操作。在写入文件时写此代码可以实现美化操作
with open("豆瓣.json","w",encoding="utf-8")as file1:
for node in zip(title,score,link):
item={}
item["title"]=node[0]
item["score"]=node[1]
item["link"]=node[2]
# item["breif"]=node[3]
print(item)
str_data=json.dumps(item,ensure_ascii=False,indent=2)
file1.write(str_data+",\n")
其中zip函数可以很好的处理多个可迭代对象的遍历。
六、最后
感谢诸位友友们能够看到这里,希望我所写的东西对你有所帮助。爆肝希望得到友友们的支持与鼓励。










