近日,阿里云视频云音频技术团队与新加坡国立大学李海洲教授团队合作论文 《基于时频感知域模型的单通道语音增强算法 》(Time-Frequency Attention for Monaural Speech Enhancement ) 被 ICASSP 2022 接收, 并受邀于今年 5 月在会议上向学术和工业界做研究报告。ICASSP(International Conference on Acoustics, Speech and Signal Processing)是全世界最大的,也是最全面的融合信号处理、统计学习、及无线通信的语音领域顶级会议。
七琦|作者
本次合作论文提出了融合语音分布特性的 T-F attention (TFA) 模块,可以在几乎不额外增加参数量的情况下显著提高语音增强的客观指标。
arxiv 链接:https://arxiv.org/abs/2111.07518
往期研究成果回顾:
INTERSPEECH 2021:《Temporal Convolutional Network with Frequency Dimension Adaptive Attention for Speech Enhancement》
链接:
https://www.isca-speech.org/archive/pdfs/interspeech_2021/zhang21b_interspeech.pdf
1.背景
语音增强算法旨在去除语音信号中的背景噪声等多余信号成分,它是许多语音处理应用的基本组件,例如在线视频会议与通话,智能短视频剪辑,实时视频直播,社交娱乐与在线教育等。
2.摘要
目前大多数关于语音增强的监督学习算法的研究中,通常没有在建模的过程中明确考虑时频域(T-F)表示中语音的能量分布,而其对于准确预测掩码或频谱至关重要。 在本文中,我们提出了一个简单而有效的 T-F 注意力(TFA)模块,使得在建模过程中可以显式引入对语音分布特性的先验思考。 为了验证我们提出的 TFA 模块的有效性,我们使用残差时序卷积神经网络(ResTCN)作为基础模型,并使用语音增强领域中两个常用的训练目标 IRM [1](The ideal ratio mask)和 PSM [2] (The phase-sensitive mask)分别进行了探索实验。 我们的实验结果表明,应用所提的 TFA 模块可以在几乎不额外增加参数量的情况下显著提高常用的五个客观评估指标,且 ResTCN+TFA 模型始终以较大的优势优于其他 baseline 模型。
3.方法解析
图 1 展示了所提 TFA 模块的网络结构,其中 TA 和 FA 模块分别以黑色和蓝色虚线框标识。AvgPool 和 Conv1D 分别为 average pooling 和 1-D convolution operation 的缩写。⊗ 和 ⊙ 分别表示矩阵乘法和元素级乘法。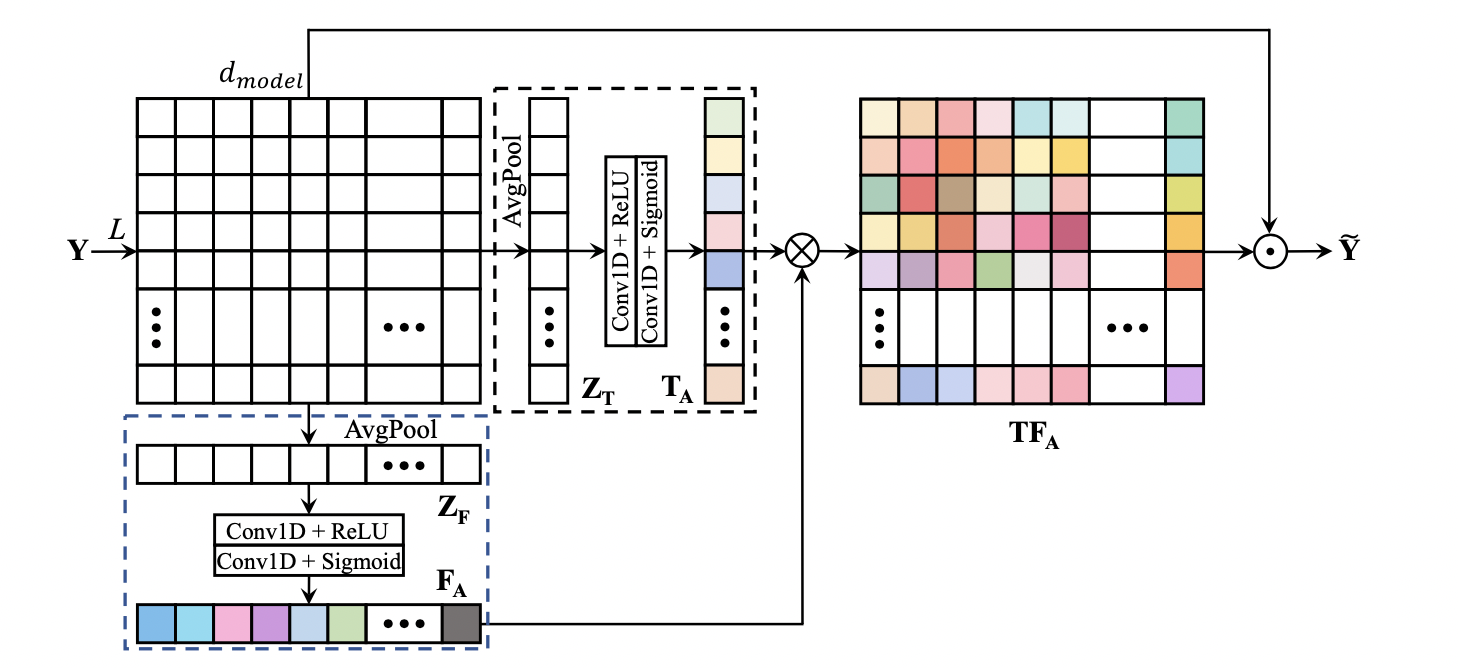
图 1
TFA 模块以变换后的时频表示 $Y\in\mathbb{R}^{L×d{model}}$ 为输入,利用两个独立的分支来分别进行 1-D time-frame attention map $T{A} \in \mathbb{R} ^{L\times 1}$ 和 1-D frequency-dimension attention map $F{A} \in \mathbb{R} ^{1\times d{model} }$ 的生成,然后将其融合为最终需要的 2-D T-F attention map $TF{A} \in \mathbb{R} ^{L\times d{model} }$ ,最终的结果可以重写为:$\widetilde{Y} =Y\odot TF_{A}$ 。
4.实验结果
训练误差曲线
图 2-3 显示了每个模型在 150 epoch 训练中产生的训练和验证集误差曲线。可以看出,与 ResTCN 相比,使用了所提出的 TFA(ResTCN+TFA)的 ResTCN 产生的训练和验证集误差显著降低,这证实了 TFA 模块的有效性。同时,与 ResTCN+SA 和 MHANet 相比,ResTCN+TFA 实现了最低的训练和验证集误差,并显示出明显的优势。在三个 baseline 模型中,MHANet 表现最好,ResTCN+SA 优于 ResTCN。此外,ResTCN、ResTCN+FA 和 ResTCN+TA 之间的比较证明了 TA 和 FA 模块的功效。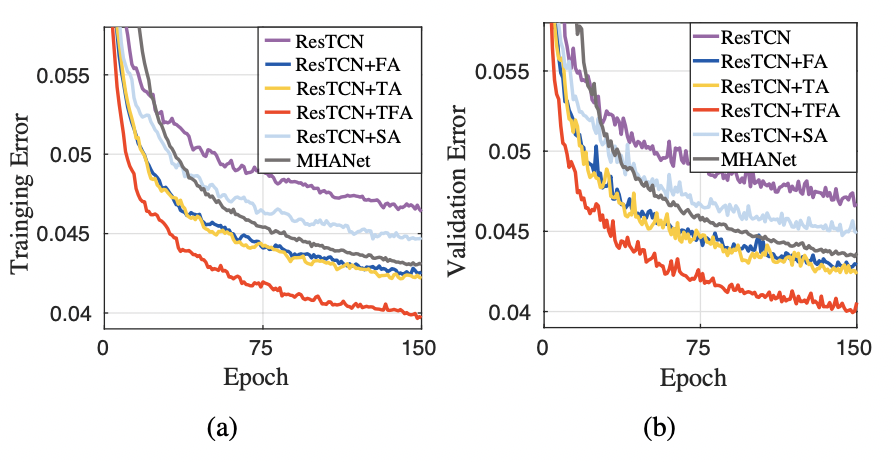
图 2 IRM 训练目标下的训练误差曲线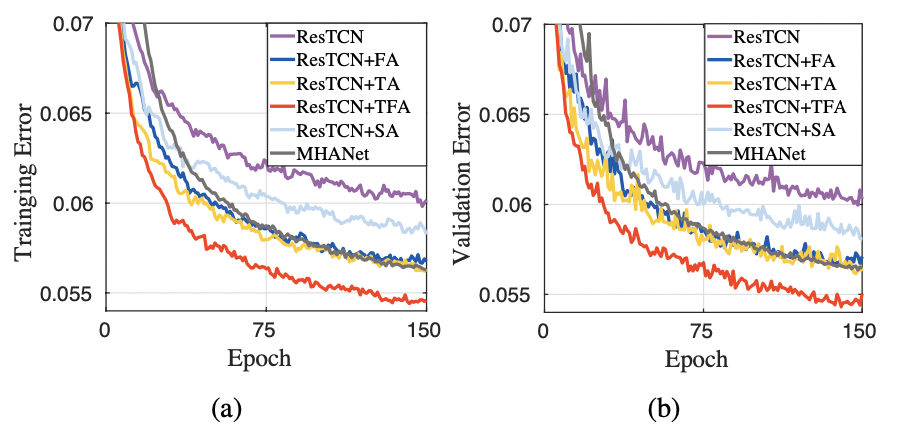
图 3 PSM 训练目标下的训练误差曲线
语音增强客观指标评估
我们使用了五个指标用于对增强性能的评估,包括 wideband perceptual evaluation of speech quality (PESQ) [3], extended short-time objective intelligibility (ESTOI) [4], 以及三个综合指标 [5], mean opinion score (MOS) predictors of the signal distortion (CSIG), background-noise intrusiveness (CBAK), overall signal quality (COVL)。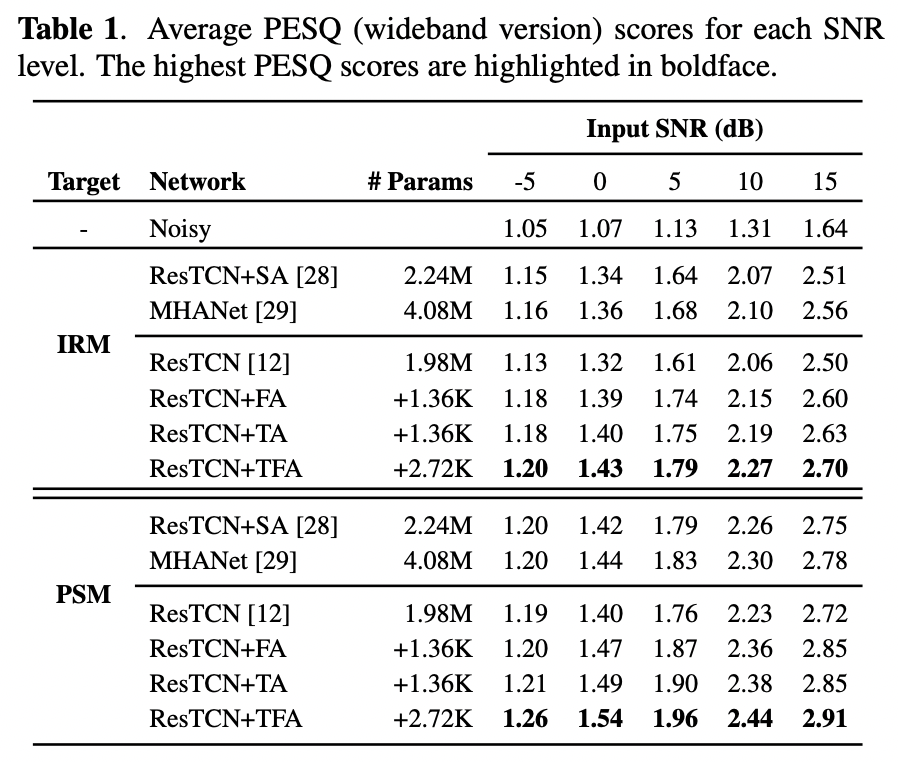
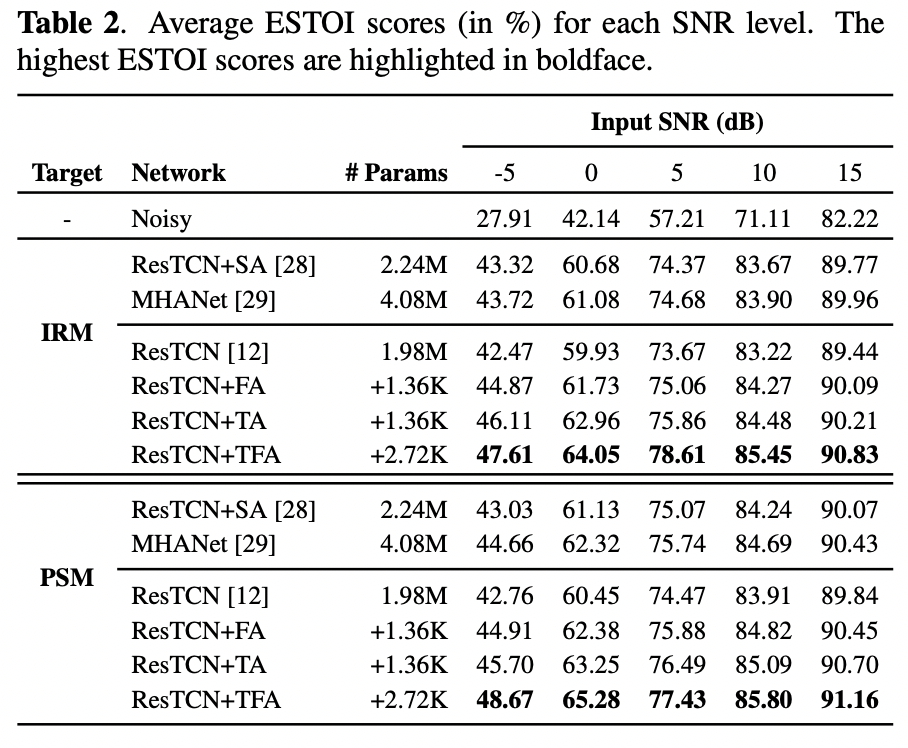
表 1 和表 2 分别显示了每个信噪比等级下(含四个噪声源)的平均 PESQ 和 ESTOI 分数。评估结果表明,我们提出的 ResTCN+TFA 在 IRM 和 PSM 上的 PESQ 和 ESTOI 方面始终比 ResTCN 取得显著改进,且参数增量可以忽略不计,这证明了 TFA 模块的有效性。具体而言,在 5 dB 条件下,IRM 训练目标下的 ResTCN+TFA 相比baseline ResTCN来说,在 PESQ 指标上提高了 0.18,在 ESTOI 指标上提高了 4.94%。与 MHANet 和 ResTCN+SA 相比,ResTCN+TFA 在所有情况下都表现最好,并且表现出明显的性能优势。在三个 baseline 模型中,整体看下来效果排名是 MHANet > ResTCN+SA > ResTCN。同时,ResTCN+FA 和 ResTCN+TA 相比 ResTCN 也有了可观的改进,这进一步证实了 FA 和 TA 模块的有效性。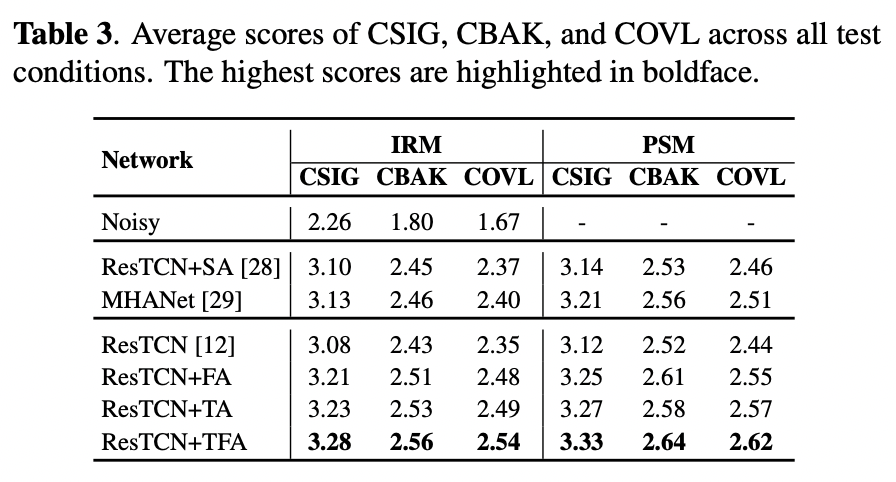
表 3 列出了所有测试条件下的平均 CSIG、CBAK 和 COVL 分数。与在表 1和表 2中观察到的趋势一致,所提的 ResTCN+TFA 在三个指标上显著优于 ResTCN,并且在所有模型中表现最好。具体而言,与 ResTCN 相比,PSM 训练目标下 ResTCN+TFA 的 CSIG 提高了 0.21,CBAK 提高了 0.12,COVL 提高了 0.18。
关于阿里云视频云音频技术团队
阿里云视频云音频技术团队,专注于采集播放-分析-处理-传输等全面的音频技术,服务于实时通信、直播、点播、媒体生产、媒体处理,长短视频等业务。通过神经网络与传统信号处理的结合,持续打磨业界领先的 3A 技术,深耕设备管理与适配、qos 技术,持续提升各场景下的直播、实时音频通信体验。
参考文献
[1] Y. Wang, A. Narayanan, and D. Wang, “On training targets for supervised speech separation,” IEEE/ACM Trans. Audio, speech, Lang. Process., vol. 22, no. 12, pp. 1849–1858, 2014.
[2] H. Erdogan, J. R. Hershey, S. Watanabe, and J. Le Roux, “Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks,” in Proc. ICASSP, 2015, pp. 708–712.
[3] R. I.-T. P. ITU, “862.2: Wideband extension to recommendation P. 862 for the assessment of wideband telephone networks and speech codecs. ITU-Telecommunicatio.
[4] J. Jensen and C. H. Taal, “An algorithm for predicting the intelligibility of speech masked by modulated noise maskers,” IEEE/ACM Trans. Audio, speech, Lang. Process., vol. 24, no. 11, pp. 2009–2022, 2016.
[5] Y. Hu and P. C. Loizou, “Evaluation of objective quality measures for speech enhancement,” IEEE Trans. Audio, Speech, Lang. process., vol. 16, no. 1, pp. 229–238, 2007.










