前置知识:图的相关术语和图的表示
图的遍历
和树数据结构类似,我们可以访问图的所有节点。由两种算法可以对图进行遍历:广度优先搜索(breadth-first search,BFS)和深度优先搜索(depth-first search,DFS)。图遍历可以用来寻找特定的顶点或寻找两个顶点之间的路径,检查路径是否相同,检查图是否有环,等等。
在实现算法之前,让我们来更好的理解一下图遍历的思想。
图遍历算法的思想是必须追踪每个第一次访问的节点,并且追踪有哪些节点还没有完全被探索,对于两种图遍历算法,都需要明确指出第一个被访问的顶点。
完全探索第一个顶点要求我们查看该顶点的每一条边。对于每一条边所连接的没有被访问过的顶点,将其标注为被发现的,并将其加入待访问的定点列表中。
为了保证算法的效率,务必访问每个顶点至多两次。连通图中每条边和顶点都会被访问到。
广度优先搜索算法和深度优先搜索算法基本上是相同的,只有一点不同,那就是待访问顶点列表的数据结构。如下表所示
| 算法 | 数据结构 | 描述 |
|---|---|---|
| 深度优先搜索 | 栈 | 将顶点存入栈,顶点是沿着路径被探索的,存在新的相邻顶点就去访问 |
| 广度优先搜索 | 队列 | 将顶点存入队列,最先入队列的顶点先被搜索 |
当要标注已经访问过的顶点时,我们用三种颜色来反映它们的状态。
- 白色:表示该顶点还没有被访问。
- 灰色:表示该顶点被访问过,但并未被探索过。
- 黑色:表示该顶点被访问过且被完全探索过。
这就是之前提到的务必访问每个顶点最多两次的原因。
为了有助于在广度优先和深度优先算法中标记定点。我们要使用 Colors 变量(作为一个枚举器),声明如下。
const Colors = {
WHITE: 0,
GREY: 1,
BLACK: 2
};
两个算法还需要访问一个辅助对象来帮助存储顶点是否被访问过。在每个算法的开头,所有的顶点都会被标记为未访问(白色)。我们要用下面的函数来初始化每个顶点的颜色。
const initColor = vertices => {
const color = {};
for(let i = 0; i < vertices.length; i++){
color[vertices[i]] = Colors.WHITE;
}
return color
}
广度优先搜索
广度优先搜索算法会从指定的第一个顶点开始遍历图,先访问其所有邻点(相邻顶点),就像一次访问图的一层。换句话说,就是先宽后深的访问顶点,如下图所示
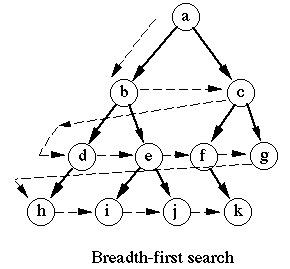
以下是从顶点v开始的广度优先搜索算法所遵循的步骤。
(1) 创建一个队列 Q。
(2) 标注 v 为被发现的(灰色),并将 v 入队列 Q。
(3) 如果 Q 非空,则运行以下步骤:
(a) 将 u 从 Q 中出队列;
(b) 标注 u 为被发现的(灰色);
© 将 u 所有未被访问过的邻点(白色)入队列;
(d) 标注 u 为已被探索的(黑色)。
让我们来实现广度优先搜索算法。
export const breathFirstSearch = (graph, startVertex, callback) => {
const startVertex = graph.getVertices;
const adjList = graph.getAdjList;
const color = initColor(vertices);
const queue = new Queue();
queue.enqueue(startVertex);
while(!queue.isEmpty()){
const u = queue.dequeue();
const neighbors = adjList.get(u);
color[u] = Colors.GREY;
for(let i = 0; i < neighbors.length; i++){
const w = neighbors[i];
if(color[w] === Colors.WHITE){
color[w] = Colors.GREY;
queue.enqueue(w);
}
}
color[u] = Colors.BLACK;
if(callback){
callback(u);
}
}
};
深度优先搜素
深度优先搜索算法将会从第一个指定的顶点开始遍历图,沿着路径直到这条卢静最后一个顶点被访问了,接着原路回退并探索下一条路径。换句话说,它是是先深度后广度地访问顶点,如下图所示
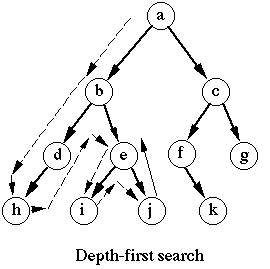
深度优先搜索算法不需要一个源顶点。在深度优先搜索算法中,若图中顶点 v 未访问,则访问该顶点 v。
要访问顶点 v,照如下步骤做:
(1) 标注 v 为未被发现的(灰色);
(2) 对于 v 的所有未访问(白色)的邻点 w,访问顶点 w;
(3) 标注 v 为已被探索的(黑色);
深度优先搜索的步骤是递归的,这意味着深度优先搜索算法使用栈来存储函数调用(由递归调用所创建的栈)。
让我们来实现一下深度优先算法。
const depthFirstSearch = (graph, callback) => {
const startVertex = graph.getVertices();
const adjList = graph.getAdjList();
const color = initColor(vertices);
for(let i = 0; i < neighbors.length; i++){
if(color[vertices[i]] === Colors.WHITE){
depthFirstSearchVisit(vertices[i], color, adjList, callback);
}
}
};
const depthFirstSearchVisit = (u, color, adjList, callback) => {
color[u] = Colors.GRAY;
if(callback){
callback(u)
}
const neighbors = adjList.get(u);
for(let i = 0; i < neighbors.length; i++){
const w = neighbors[i];
if(color[w] === Colors.WHITE){
depthFirstSearchVisit(w, color, adjList, callback);
}
}
color[u] = Colors.BLACK;
};
写此文的原因是在面试时面试官看我在简历上写了数据结构与算法(Leetcode120+),便询问做的题以哪方面为主,答曰数组和树。一面让手写了一下先序遍历,这个写出来了,二面换了个人问广度优先搜索和深度优先搜索。啊这,答不上来。因为当时是在学习图的时候看到这两个概念,但是图已经是书本介绍的最后一个数据结构了,而且感觉不怎么常见,就没把那章节看完。加上当时已经学到Node.js、计网、异步等信息量比较大的知识,后续更是在学框架写东西,就没再研究数据结构与算法了









