大家好,我是不温卜火,是一名计算机学院大数据专业大三的学生,昵称来源于成语—不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!
目录
- 一、网页的访问过程
- 1.1、网页访问的具体过程
- 1.2、网页访问过程(动图演示)
- 二、HTTP
- 2.1 HTTP版本的技术特征
- 2.2、网络爬虫主要的操作对象
- 1、HTTP请求(Request)
- 2、HTTP响应(Response)
- 3、HTTP请求和响应都由两部分组成
- 2.3、GET和POST
- 1. GET
- 2. POST
- 2.4、HTTP常用协议

本篇文章主要介绍HTTP协议相关知识、目标网页的解析、爬虫抓取策略。
一、网页的访问过程
在讲解之前,我们先来想一下在浏览器地址栏中输入网址后,会发生什么。下图为效果图:

1.1、网页访问的具体过程
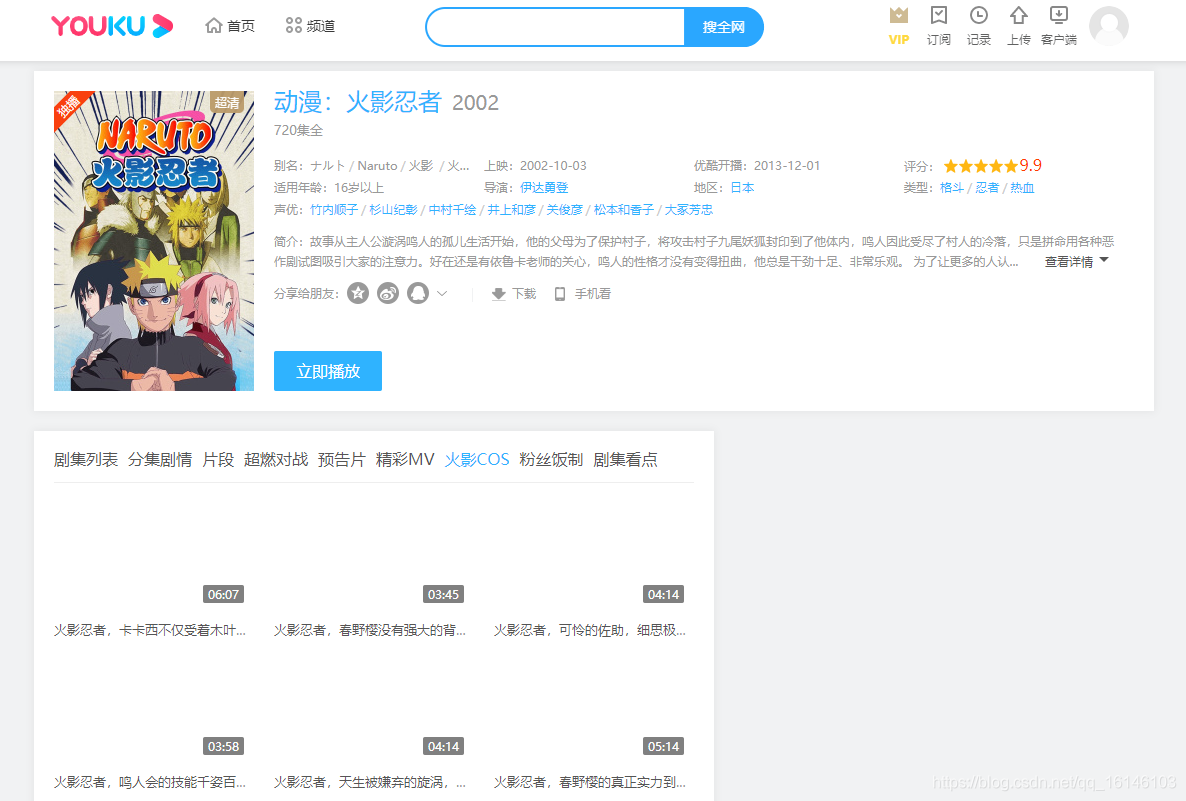
在此学长以《火影忍者》为例,大体过程,可能会有一些小瑕疵。
- 第一步:网络浏览器通过本地或者远程DNS,获取域名对应的IP地址

- 第二步:根据获取的IP地址与访问内容封装HTTP请求
- 第三步:浏览器发送HTTP请求
- 第四步:服务器接收信息,根据HTTP内容寻找web资源
- 第五步:服务器创建HTTP请求并封装
- 第六步:服务器将HTTP响应返回到客户端浏览器
这时并不是我们普通人看到得视角。 - 第七步:浏览器解析,渲染服务器返回得资源,显示给用户
1.2、网页访问过程(动图演示)
由于网页结构有所变动,因此演示以《火影忍者》百度百科为例。

如果想要深入了解网络爬虫的工作原理,我们需要详细了解HTTP请求和响应
二、HTTP

HTTP的大体分为下面几种
- HTTP请求过程
- HTTP请求
- HTTP响应
- HTTP方法
- HTTP头
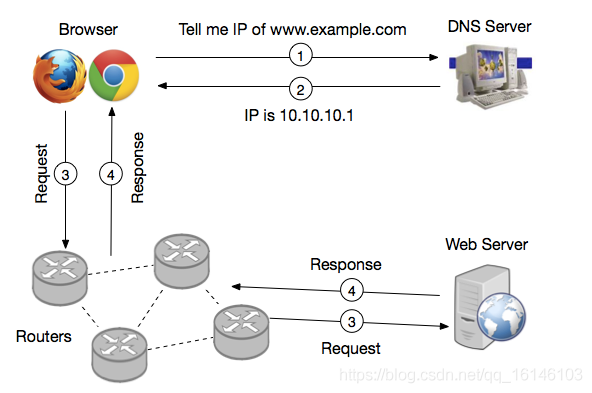
HTTP请求的一般步骤:
- 获取想要访问的URL的IP地址(标号1、2)
- 向Web Server 请求资源(标号3)
- Web Server 收到请求,将 响应返回给客户端(标号4)
2.1 HTTP版本的技术特征
HTTP/1.1是目前使用最广泛的HTTP协议版本,于1997年发布。HTTP/1.1与之前的版本相比,改进主要集中在提高性能、安全性以及数据类型处理等方面。
- 与HTTP/1.0最大的区别在于,HTTP/1.1默认采用持久连接。客户端不需要在请求头中特别声明:Connection:
keep-alive,但具体实现是否声明依赖于浏览器和Web服务器。请求响应结束后TCP连接默认不关闭,降低了建立TCP连接所需的资源和时间消耗。 - HTTP/1.1支持管道(pipelining)方式,可以同时发送多个请求。在发送请求的过程中,客户端不需要等待服务器对前一个请求的响应,就可以直接发送下一个请求。管道方式增加请求的传输速度,提高了HTTP协议的效率。但是,服务器在响应时,必须按照接收到请求的顺序发送响应,以保证客户端收到正确的信息。
- HTTP/1.1添加Host请求头字段。随着虚拟主机这种应用架构技术的发展,在一台物理服务器上可以存在多个虚拟主机,这些虚拟主机共享一个IP地址。HTTP/1.1在请求头中加入host请求头字段,指出要访问服务器上的哪个网站。
2.2、网络爬虫主要的操作对象
1、HTTP请求(Request)

上图表示的是HTTP Request的结构。其中Request Line 包含了请求的方法,如GET、POST、PUT、DELETE、HEAD、OPTIONS等所请求的资源,如/doc/test.html,以及客户端所用的HTTP协议版本(0.9、1.0、1.1等),目前浏览器默认采用的都是HTTP1.1版本。
Request Line 之后是一些请求头,表明了请求的主句名称(Host),请求的资源类型(Accept),客户端的身份(User-Agent),可用的压缩方式(Accept-Encoding),消息体的长度(Content-Length)等。请求头后面是一个空行,用来分隔请求头和消息体。空行后面紧接着就是消息体,消息体中可以包含任何内容(文本或二进制)。
2、HTTP响应(Response)
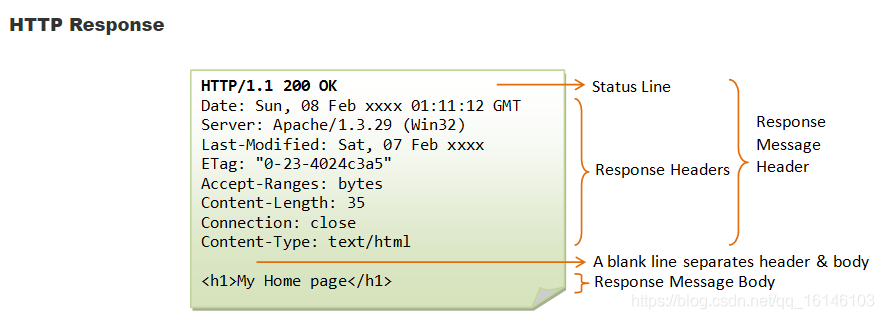
上图表示的是HTTP Request的结构。可以看出Response和Request的结构是很相似的。Response中的Status Line包含了服务器所使用的HTTP版本(通常会自动与客户端保持一致),状态码(Status Code)和状态描述,如"200 OK","404 Not Found"等。Status Line后面是响应头。表明了服务器的时间(Data),服务器的类型(Server),消息体的类型(Content-Type),消息体长度(Content-Length)等。
3、HTTP请求和响应都由两部分组成
- 消息头(
Message Header)
构成头部 - 消息头(
Message Body)
存放web资源和想要请求的内容
2.3、GET和POST
HTTP的请求方法有很多,但是在爬虫方面,我们通常使用GET和POST方法。
1. GET
GET 方法会将需要的参数附在 URL 的后面(是 URL 的一部分,即包含在 Request Line 中),以 “?” 分隔 URL和参数,多个参数之间用 “&” 连接。 例如,豆瓣阅读的 URL 为 https://read.douban.com/?dcn=entry&dcs=book-nav&dcm=douban ,其中包含了3个 key-value 参数。服务器会根据这些参数对用户所请求的资源进行筛选和过滤。尽管 RFC2616 没有对 URL 的长度进行限制,但通常服务器或浏览器都会限制 URL 的长度,如 Chrome 的 URL 长度不能超过 8KB。所以,如果要向服务器发送大量的数据 POST 是更好的选择。
另外,为了保证客户端和服务器之间的一致性,RFC2616 规定 URL 中只能使用 ASCII 中的可见字符, 所以如果 URL 中包含了中文等非 ASCII 字符, 就要对 URL 进行编码。通常采用的编码方式是百分号编码,即用 ‘%’ 分隔十六进制的 UTF-8 编码。如对于 URL:https://movie.douban.com/tag/喜剧 ,“喜剧"的 UTF-8编码是”\xE5\x96\x9C\xE5\x89\xA7",经过编码之后 URL 就变成了 https://movie.douban.com/tag/%E5%96%9C%E5%89%A7 。
可能有人已经发现了这样一个问题:’ ‘(空格),’+’,’%’,’?'等字符都是 ASCII 字符,为什么有的时候要编码,有的时候不要编码呢?你发现的这个问题是一个很好的问题,能发现这个问题,说明你是一个善于观察和思考的人。不过让我们暂时先把这个问题放一放,这个问题困扰了很多人,甚至包括专业的爬虫工程师,学长将在后续的文章中用实例进行更加详细的讲解。
2. POST
与 GET 方法不同,POST 方法是将数据放在消息体中,并用 Content-Type 标明采用的是何种格式。不过,RFC2616 并没有规定消息体的格式,实际上,开发者完全可以开发自己的传输格式,只要保证客户端和服务器之间能正确解析即可。另外,通过 POST 传递的数据,不会被浏览器缓存,所以 POST 方法要比 GET 方法的安全性高一点。因为这些原因,现行的网站大多都采用 POST 方法实现注册、登录等交互功能。为了方便传输,人们定义了一些公开的数据格式,如:
application/x-www-form-urlencoded :这是向服务器提交表单数据最常用的方式。与 GET 方法类似,传输的参数也是 key-value 形式的,并且也需要进行像 URL 一样的编码,只不过是把这些数据放在了消息体中。将数据放在消息体中也意味着可以传输的数据长度是没有限制的。你可以在 http://httpbin.org/forms/post 得到更加直观的体验。
application/json 或 application/xml :JSON 和 XML 支持比 key-value 对复杂得多的结构化数据。要传输的对象会被转换成 JSON 或 XML 格式,然后放在消息体中。现在越来越多的服务都会选择用 JSON 作为数据传输的格式。XML 因为其冗余度较高,正在慢慢退出历史舞台。http://httpbin.org/headers 将我们的请求头用 JSON 的格式返回回来。可以看到响应头中的 Content-Type 采用的正是 application/json。
multipart/form-data :如果表单中包含要上传的文件,多采用这种格式。这种格式会指定一个 boundary,用来分隔不同的部分。RFC1867 有对这种格式详细的规定和示例。通常情况下,面向数据分析的爬虫最常采用的 Content-Type 是 application/x-www-form-urlencoded 和 application/json,很少使用 multipart/form-data,所以,我们可以暂时大胆地跳过这些内容。
GET和POST的误区:
- 误区一:POST可以比GET提交更多更长的数据?
由于使用GET方法提交数据时,数据会以&符号作为分隔符的形式,在URL后面添加需要提交的参数,有人就会说了,浏览器地址栏输入的参数是有限的,而POST不用再地址栏输入,所以POST就比GET可以提交更多的数据。难道真的是这样的么?
而实际上,URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
同时,POST是没有大小限制的,HTTP协议规范也没有进行大小限制。POST数据是没有限制的,起限制作用的是服务器的处理程序的处理能力。
总归一句话,这个限制是针对所有HTTP请求的,与GET、POST没有多少关系。
- 误区二:POST比GET安全?
首先,我们要承认安全的概念有很多种,要是从最基本的肉眼看到就不安全,肉眼看不到那就是安全的概念说呢,GET确实没有POST安全,毕竟小白用户确实可以看到在URL中带有的数据信息,这个你无法狡辩。那么要是往严谨了说呢,POST是不是要比GET安全呢?其实不是的。只能说由于POST方法是将数据放在消息体中,这些数据不会被浏览器存储,所以安全性更好点。
如果想要深入了解Content-Type是如何定义的,学长在此给出链接:MIME Content-Type Header Field
2.4、HTTP常用协议
HTTP 协议包含几十种 header,分为 General Headers(通用头域,既可用于 Request Header,也可用于 Response Header),Request Headers,Response Headers。Response Headers 不需要我们操心,因为这是服务器的事儿,等用到的时候再研究也不迟。我们只讲解在爬虫领域比较常用的 Request Headers:
Accept :客户端支持的 MIME 类型。如 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8。
User-Agent :代表客户端标识。如Mac OS 上 Chrome 浏览器为User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36。服务器常用这一个header判断是否是爬虫。
Accept-Encoding :客户端支持的压缩方式。如:Accept-Encoding: gzip, deflate。
Host :表示请求的服务器域名。通常与所请求的 URL 保持一致。如:Host: www.douban.com。服务器常用这个域判断请求是否合法。
Referer :用于标识当前请求的来源页面。点击豆瓣主页中的电影链接 https://movie.douban.com/ ,浏览器会给请求头自动加上 “Referer:https://www.douban.com/” 。
Cookie :Cookie 是一些 key-value 对,代表着客户端的状态。如:Cookie: ll="1888"; gr_user_id=10597129-7a112d79a723。
在 Header Field Definitions,你可以看到各种头部的定义格式。如下图:

美好的日子总是短暂的,虽然还想继续与大家畅谈,但是本篇博文到此已经结束了,如果还嫌不够过瘾,不用担心,我们下篇见!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!








