Python数据探索性分析和预处理
https://blog.csdn.net/ertyee42/article/details/103566905?ops_request_misc=&request_id=&biz_id=102&utm_term=%E6%95%B0%E6%8D%AE%E6%8E%A2%E7%B4%A2%E4%B8%8E%E9%A2%84%E5%A4%84%E7%90%86&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-4-103566905.142v38pc_rank_v38&spm=1018.2226.3001.4187
讲在前面
开始讲解之前,我们需要有数据,而我们这里使用的也是经典的数据集----Titanic数据集,关于数据集的下载,大家可以通过Kaggle自行下载。数据集下载
数据包括三部分:训练集、测试集和一个用于检测准确性的数据集。
一.探索性分析
探索性分析就是在数据处理前对数据有个全面的了解,探索性分析的目的如下:
- 快速描述一份数据集:行/列数、数据的类型、数据预览。
- 脏、差数据分析:数据丢失情况、异常数据、无效的数据类型和不正确的值情况分析。
- 可视化数据分布:条形图,直方图,箱型图等。
- 了解变量之间的相关性(关系):为后续分析做基础
探索性分析我们从两个方面讲解,分别是数据质量分析和数据特征分析。
1.数据质量分析
数据质量分析是数据挖掘中数据准备过程的重要一环,是数据预处理的前提,也是数据挖掘分析结论有效性和准确性的基础。只有可信的数据才能保证数据挖掘的可靠。
如果数据质量不高,则会影响数据挖掘的结果。一般数据的预处理包括异常点检测,噪声数据检测,缺失值的处理和重复数据的处理。我们这里主要介绍缺失值和异常值分析。
1.缺失值
查看缺失情况
在搜集数据的某些情况下,有些时候并不一定会收集到数据,因而会造成观测值或变量的数据有缺失,这些缺失的数据就称之为缺失值。缺失值有可能是因为某些原因没有收集到信息,也有可能是对于这些个体来说这些属性是不可用的。我们分析缺失值只要有下面三个目的。
1. 明确存在缺失值的属性有哪些?
2. 明确每个属性(特征)缺失的数量是好多?
3. 明确 缺失率是多少?
我们结合上面三点,使用实际的例子讲解。
# 加载需要的包
import pandas as pd
# 加载训练数据集
data = pd.read_csv(r"E:\数据分析\train.csv")
data.head()
# 数据的属性
data.columns
# 数据的总体状况(类型,缺失)
data.info()
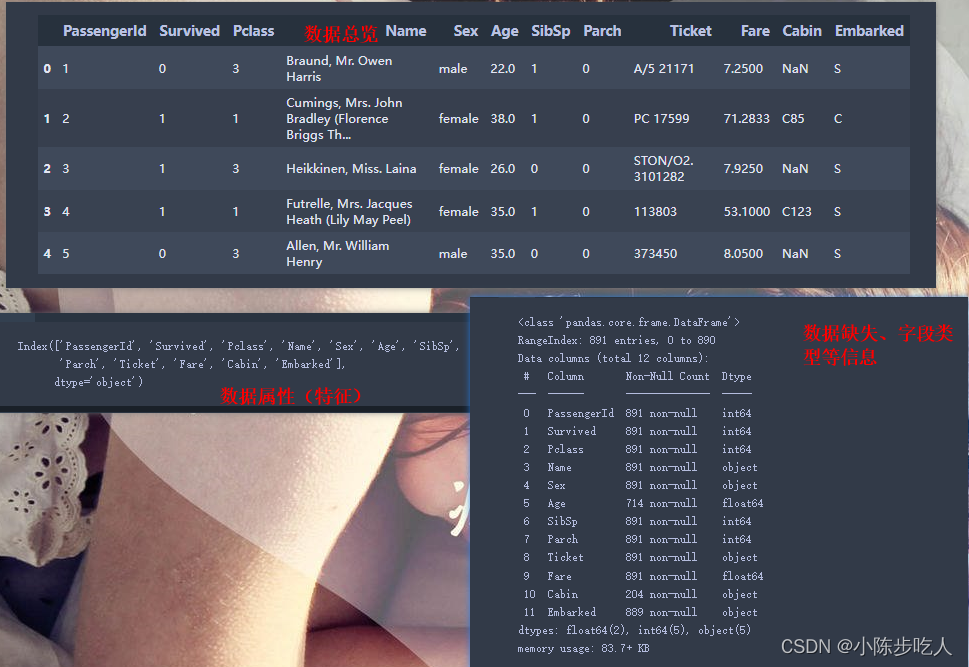
从分析结果来看,存在缺失值的属性有两个,分别是Age和Cabin,对于Age属性,缺失177条数据,缺失率在20%左右;而对于Cabin属性,缺失687条数据,缺失率几乎达到80%。
缺失值处理
- 删除:删除的情况适用于缺失率很小(5%以下)或者很大(80%以上),但个人建议还是能不删除的不删除,毕竟数据带有一些价值,当然,确定无用的直接删除没得关系。
- 替换:替换前要考虑缺失在业务上的含义,缺失是否对后续有影响,然后利用缺失变量的均值、中位数或众数替换该变量中的缺失值;或者使用其他列/行的数据填充。其好处是缺失值的处理速度快;弊端是易产生有偏估计
- 插补:利用有监督的机器学习方法(如回归模型、树模型、网络模型等)对缺失值作预测。其优势在于预测的准确性高;缺点是需要大量的计算,导致缺失值的处理速度大打折扣
数据源这样:
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
def knn_filled_func(x_train, y_train, test, k = 3, dispersed = True):
# params: x_train 为目标列不含缺失值的数据(不包括目标列)
# params: y_train 为不含缺失值的目标列
# params: test 为目标列为缺失值的数据(不包括目标列)
if dispersed:
knn= KNeighborsClassifier(n_neighbors = k, weights = "distance")
else:
knn= KNeighborsRegressor(n_neighbors = k, weights = "distance")
knn.fit(x_train, y_train)
return knn.predict(test)
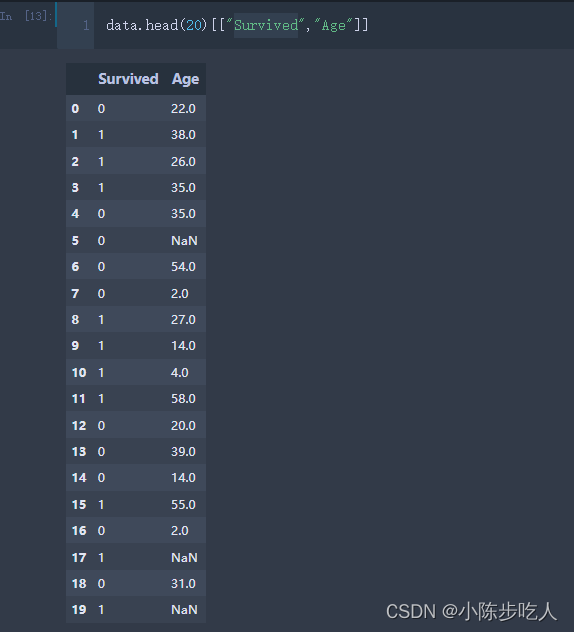
# 我们使用Survived插值Age(前20条记录),实际中用其他所有特征去计算,这里选了一个特征
x_train = data.head(20)[~data.head(20)["Age"].isnull()][["Survived"]]
y_train = data.head(20)[~data.head(20)["Age"].isnull()]["Age"]
test = data.head(20)[data.head(20)["Age"].isnull()][["Survived"]]
y_predict = knn_filled_func(x_train, y_train, test, k = 3, dispersed = True)
y_predict
# 结果输出
array([22., 26., 26.])
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
def knn_filled_func(x_train, y_train, test, k = 3, dispersed = True):
# params: x_train 为目标列不含缺失值的数据(不包括目标列)
# params: y_train 为不含缺失值的目标列
# params: test 为目标列为缺失值的数据(不包括目标列)
if dispersed:
rf= RandomForestRegressor()
else:
rf= RandomForestClassifier()
rf.fit(x_train, y_train)
return rf.predict(test)
y_predict_rf = knn_filled_func(x_train, y_train, test, k = 3, dispersed = True)
y_predict_rf
# 预测输出
array([24.21604776, 30.34354648, 30.34354648])
总之,处理缺失值是需要研究数据规律与缺失情况来进行处理的,复杂的算法不一定有好的效果,因此,还要具体问题具体分析,尤其是要搞明白字段含义以及缺失意义,这往往容易被忽略。个人经验,数据处理需要去探索,没有一成不变的万全之策。
2.异常值
异常值是指样本中的个别值,其数值明显偏离它(或他们)所属样本的其余观测值。
异常值检测(查看)
简单方法:
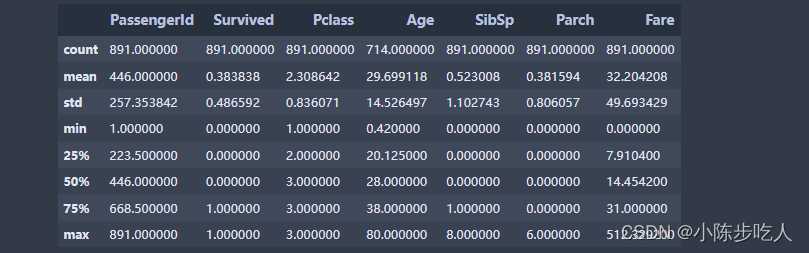
对于异常值的最简单方法就是使用pandas库的describe(),此方法简单,但是只是看个大概,代码如下:
data.describe()
3∂原则方法
我们还是直接使用上面例子数据的Age字段,计算其3σ区间,代码如下:
def three_sigma(s):
mu, std = np.mean(s), np.std(s)
lower, upper = mu-3*std, mu+3*std
return lower, upper
three_sigma(data["Age"])
(-13.84984580539313, 73.24808109951077)
从结果来看,区间范围是-13.84, 73.24,但是我们知道对于年龄来说,不可能是负数,所以,实际中还是要考虑特征的实际意义来判定是否是异常值。不能只单一的使用某个理论方法判定。
箱型图
箱型图是根据数据的四分位对数据进行的判定规则,具体定义如下:
箱型图作为图,那必然是需要作图直观的反应异常值的,作图代码如下:
# 输出上下限
def boxplot(s):
q1, q3 = s.quantile(.25), s.quantile(.75)
iqr = q3 - q1
lower, upper = q1 - 1.5*iqr, q3 + 1.5*iqr
return lower, upper
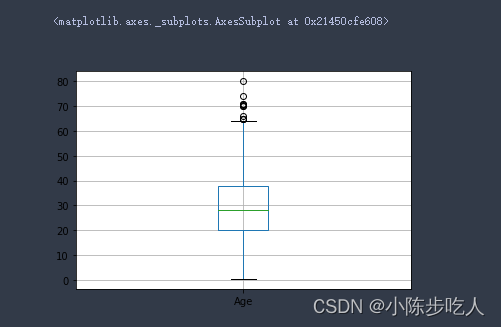
boxplot(data["Age"])
(-6.6875, 64.8125)
# 画图
data[["Age"]].boxplot()
除了上面介绍的三种基于分布的方法,还有使用算法基于距离的异常值判定,比如:使用KNN算法,依次计算每个样本点与它最近的K个样本的平均距离,再利用计算的距离与阈值进行比较,如果大于阈值,则认为是异常点。优点是不需要假设数据的分布,缺点是仅可以找出全局异常点,无法找到局部异常点。或者是基于密度的LOF算法,但总有缺点。
总之,还是那句话,数据异常值的判断都必须基于业务考虑,业务上合理的,在数据表现上再异常,它也是个正常数据。
异常值处理
异常值的处理也是根据实际业务和选用的算法模型相关,这里只给出简单的、可能的处理思路。
- 删除含有异常值的记录
- 视为缺失值:将异常值视为缺失值,按照缺失值进行处理
- 平均值修正:可用前后两个观测值的平均值修正该异常值
- 不处理:不直接在具有异常值的数据集上进行数据挖掘
2.数据特征分析
1.分布
分布分析,研究数据的分布特征和分布类型,分为定量数据和定性数据。现在就两种数据的分布分析做如下的简要介绍和讲解。
定量数据
对于定量变量而言,做频率分布分析是最重要的问题,一般按照以下步骤进行。还是以年龄特征为例。
- 求极差
- 决定组距和组数
- 决定分点
- 列出频率分布表
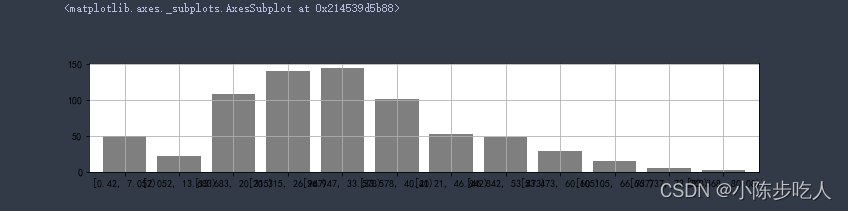
# 求分组区间,cut等距切分;Qcut等量切分
gcut = pd.cut(data["Age"],12,right=False)
gcut_count = gcut.value_counts(sort=False)
gcut_count
[0.42, 7.052) 50
[7.052, 13.683) 21
[13.683, 20.315) 108
[20.315, 26.947) 140
[26.947, 33.578) 144
[33.578, 40.21) 101
[40.21, 46.842) 52
[46.842, 53.473) 48
[53.473, 60.105) 28
[60.105, 66.737) 15
[66.737, 73.368) 5
[73.368, 80.08) 2
Name: Age, dtype: int64
- 绘制频率分布直方图
r_zj = pd.DataFrame(gcut_count)
r_zj['Age'].plot(kind = 'bar',
width = 0.8,
figsize = (12,2),
rot = 0,
color = 'k',
grid = True,
alpha = 0.5)
定性数据
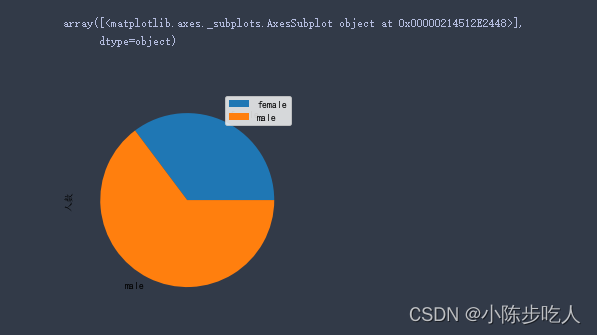
对于定性数据(分类数据)而言,常常根据变量的分类类型来分组,可以采用饼图和条形图来描述定性变量的分布。
我们使用上面例子中的Sex特征,做一个饼图,用来研究性别的分布,实现如下:
sex_group = data.groupby("Sex")[["PassengerId"]].count()
sex_group.rename(columns={"PassengerId":"人数"},inplace=True)
sex_group.plot.pie(subplots=True)
2.对比
对比分析就是用两组或两组以上的数据进行比较,是最通用的方法。我们知道孤立的数据、图像没有意义,有对比才有差异。比如在时间维度上的同比和环比、增长率、定基比,与竞争对手的对比、类别之间的对比、特征和属性对比等。对比法可以发现数据变化规律,使用频繁,经常和其他方法搭配使用,这里不加赘述。
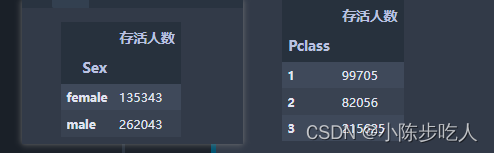
比如性别之间的存活率差异、船票等级之间的存活率差异:
sex_group1 = data.groupby("Sex")[["PassengerId"]].sum()
sex_group1.rename(columns={"PassengerId":"存活人数"},inplace=True)
sex_group1
Pclass_group1 = data.groupby("Pclass")[["PassengerId"]].sum()
Pclass_group1.rename(columns={"PassengerId":"存活人数"},inplace=True)
Pclass_group1
3.统计量分析
对于定量数据,通常需要对其进行统计量分析,通常使用前面介绍的describe()分析,一些特殊的数据使用单独统计分析。
这里关于统计量分析不做过多的赘述。
4.相关性
判断两个变量是否具有线性相关关系的最直观的方法是直接绘制散点图。
定量数据相关性
定量数据相关性分析大致步骤如下:
- 找出两个变量的正确相应数据。
- 画出散点图,通过散点图判断相关性。
- 散点图有线性趋势时,计算相关系数
- 对结果进行评价和检验
代码示例如下:
# 参数method指定选用哪种相关系数,可选参数'pearson', 'kendall', 'spearman'
data.corr(method='pearson')
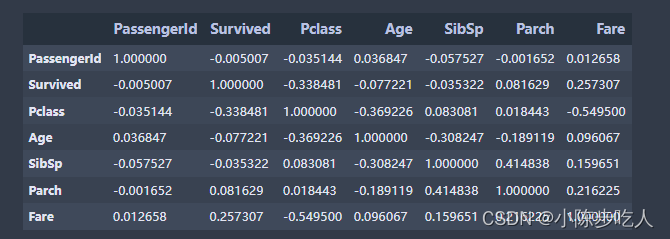
另外,关于两个相关系数的数学公式如下:

需要注意的是,皮尔逊相关系数是基于数据正态分布的假设,而斯皮尔曼则没有这个限制。
定性数据相关性

二.预处理
1.数据取样
数据取样也叫做数据抽样,那为什么要进行数据抽样呢?试想一下,我们有1000w+的数据,直接使用这些数据进行数据分析,会很费时,那就需要挑一些代表性的数据进行分析,这就是抽样;还有一种情况是,正负比例9:1,这样的数据进行后续的算法分析时,很难得到正确的分析结果,也要用到抽样。
对于抽样来说,有很多种方法,我们就简单个做个总结:
- 随机抽样:是指将调查总体的观察个体全部编号,再随机抽取部分观察个体,组成样本。
data_sample = random.sample(range(len(data)),100) # 在数据集中随机抽取100个样本
data.loc[data_sample,::]
- 分层抽样:是先把要研究的总体按照某些行政分类,再在各类中分别抽取样本。比如:按照教育程度把感兴趣的人群分成几类,再在每一类中调查和该类成比例数目的人,以确保每一类都有相应比例的代表。
# 数据先分男女两层(实际业务中分层比这复杂)
data_man = data[data["Sex"] == "male"]
data_woman = data[data["Sex"] == "female"]
# 每层数据各自进行随机取样(实际中,按照每层的占比抽取,这里都抽取50条)
data_sample_man = random.sample(range(len(data_man)),50)
data_man.reset_index(inplace=True)
data1 = data_man.loc[data_sample_man,::]
data_sample_woman = random.sample(range(len(data_woman)),50)
data_woman.reset_index(inplace=True)
data2 = data_woman.loc[data_sample_woman,::]
# 合并成最终的样本数据
data_sample = pd.concat([data1,data2])
- 整群抽样:指先把总体分成若干群,再从这些群中抽取几群,然后再在这些抽取的群中对个体进行简单的随机抽样。
# 这里就不再代码演示了,讲一下思路
# 我们之前加载了泰坦尼克的训练数据集,比如我们有8个这样的数据集
# 我们先在8个里面抽取4个,再把抽到的这四个进行随机抽样
# 就完成了整群抽样
- 系统抽样(等距抽样):是先把总体中的每个单元编号,然后随机选取其中之一,作为抽样开始点进行抽样。在选取开始点之后,通常从开始点开始控制编号,进行所谓等距抽样。由于开始点随机,如果编号随机,所以系统抽样类似于随机抽样。
data_sys = [i * 3 for i in range(len(data)) if i * 3 < len(data)]
data.loc[data_sys,::]
2.数据清洗
这里说的数据清洗,包括缺失数据处理、异常数据处理、重复数据处理,这些再前面讲解探索性分析时已经说明,这里就不再赘述。
3.数据变换
数据变换主要是对数据进行规范化处理,将数据转换成“适当的"形式,以适用于挖掘任务及算法的需要。
数据变换主要有下面四种,分别是**简单的函数变换、数据规范化、数据离散化和属性构造。**下面,将一一详细介绍。
1.简单函数变换
函数变换主要是对数据形式的改变,比如下面几种函数变换:
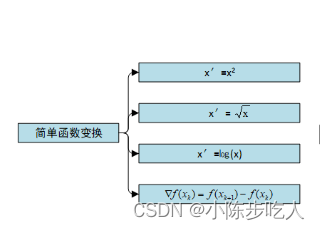
上边的几种变换中,对数变换是常用的一种变化形式,比如右偏的数据经过对数变换后,数据类似正态分布了,更适合进行数据挖掘。
2.数据规范化
数据规范化使属性数据按比例缩放,这样将原来的数值映射到一个新的特定区域中。常用的方法有最小—最大规范化,Z-score规范化,按小数定标规范化。
max-min标准化
可以将数据转换到[0,1]范围内,但是由于采用了数据集的数据特征,所以需要再标准化前做好异常值剔除。计算公式如下:
Z-score规范化
Z-score标准化是一种最为常见的量纲化处理方式。其计算公式为:
小数定标规范化
这种方法通过移动数据的小数点位置来进行标准化。但是对于有异常值的数据需要先处理。
3.数据离散化
将连续属性离散化成若干组能够满足数据挖掘的要求,主要的方法有以下几种,我们还是使用前面例子数据,把年龄字段进行离散化处理。
- 等宽法:将数据填入等分的区间,类似频率分布
gcut = pd.cut(data["Age"],10,right=False)
gcut_count = gcut.value_counts(sort=False)
gcut_count
[0.42, 8.378) 54
[8.378, 16.336) 46
[16.336, 24.294) 177
[24.294, 32.252) 169
[32.252, 40.21) 118
[40.21, 48.168) 70
[48.168, 56.126) 45
[56.126, 64.084) 24
[64.084, 72.042) 9
[72.042, 80.08) 2
Name: Age, dtype: int64
- 等频法:将数据按照百分比填入不同区间
qgcut = pd.qcut(data["Age"],10)
qgcut_count = qgcut.value_counts(sort=False)
qgcut_count
(0.419, 14.0] 77
(14.0, 19.0] 87
(19.0, 22.0] 67
(22.0, 25.0] 70
(25.0, 28.0] 61
(28.0, 31.8] 66
(31.8, 36.0] 91
(36.0, 41.0] 53
(41.0, 50.0] 78
(50.0, 80.0] 64
Name: Age, dtype: int64
- 基于聚类方法
该方法是基于无监督KMeans聚类算法衍生而来的分箱方法,关于KMeans聚类算法这里不再赘述。
关于实际中选择数据分箱选择等宽还是等频,要按实际来,它们各自的特点如下:
4.属性构造
顾名思义,就是创造新的变量,当然这个基于你对业务的理解程度。一个好的衍生变量不管是对于模型还是实际业务都有很重要的意义(当然,不好找真正有意义的衍生变量)。
这里不再对衍生变量做更多的解释,后面使用数据实际分析时,慢慢引入。










