作者: 夕陌、谦言、莫申童、临在
导读
自监督学习(Self-Supervised Learning)利用大量无标注的数据进行表征学习,在特定下游任务上对参数进行微调,极大降低了图像任务繁重的标注工作,节省大量人力成本。近年来,自监督学习在视觉领域大放异彩,受到了越来越多的关注。在CV领域涌现了如SIMCLR、MOCO、SwAV、DINO、MoBY、MAE等一系列工作。其中MAE的表现尤为惊艳,大家都被MAE简洁高效的性能所吸引,纷纷在 MAE上进行改进,例如MixMIM,VideoMAE等工作。MAE详解请参考往期文章:MAE自监督算法介绍和基于EasyCV的复现 。
ConvMAE是由上海人工智能实验室和mmlab联合发表在NeurIPS2022的一项工作,与MAE相比,训练相同的epoch数, ImageNet-1K 数据集的finetune准确率提高了 1.4%,COCO2017数据集上微调 25 个 epoch相比微调100 个 epoch 的 MAE AP box提升2.9, AP mask提升2.2, 语义分割任务上相比MAE mIOU提升3.6%。在此基础上,作者提出了FastConvMAE,进一步优化了训练性能,仅预训练50个epoch,ImageNet Finetuning的精度就超过MAE预训练1600个epoch的精度0.77个点(83.6/84.37)。在检测任务上,精度也超过ViTDet和Swin。
EasyCV是阿里巴巴开源的基于Pytorch,以自监督学习和Transformer技术为核心的 all-in-one 视觉算法建模工具,覆盖主流的视觉建模任务例如图像分类,度量学习,目标检测,实例/语音/全景分割、关键点检测等领域,具有较强的易用性和扩展性,同时注重性能调优,旨在为社区带来更多更快更强的算法。
近期FastConvMAE工作在EasyCV框架内首次对外开源,本文将重点介绍ConvMAE和FastConvMAE的主要工作,以及对应的代码实现,最后提供详细的教程示例如何进行FastConvMAE的预训练和下游任务的finetune。
ConvMAE
ConvMAE是由上海人工智能实验室和mmlab联合发表在NeurIPS2022里的一项工作,ConvMAE的提出证明了使用局部归纳偏置和多尺度的金字塔结构,通过MAE的训练方式可以学习到更好的特征表示。该工作提出:
- 使用block-wise mask策略来确保计算效率。
- 输出编码器的多尺度特征,同时捕获细粒度和粗粒度图像信息。
原文参考:https://arxiv.org/abs/2205.03892
实验结果显示,上述两项策略是简洁而有效的,使得ConvMAE在多个视觉任务中相比MAE获得了明显提升。以ConvMAE-Base和MAE-Base相比为例:在图像分类任务上, ImageNet-1K 数据集的微调准确率提高了 1.4%;在目标检测任务上,COCO2017微调 25 个 epoch 的AP box达到53.2%,AP mask达到47.1%,与微调100 个 epoch 的 MAE-Base相比分别提升2.9% 和 2.2% ;在语义分割任务上,使用UperNet网络头,ConvMAE-Base在ADE20K上的mIoU达到51.7%,相比MAE-Base提升3.6%。
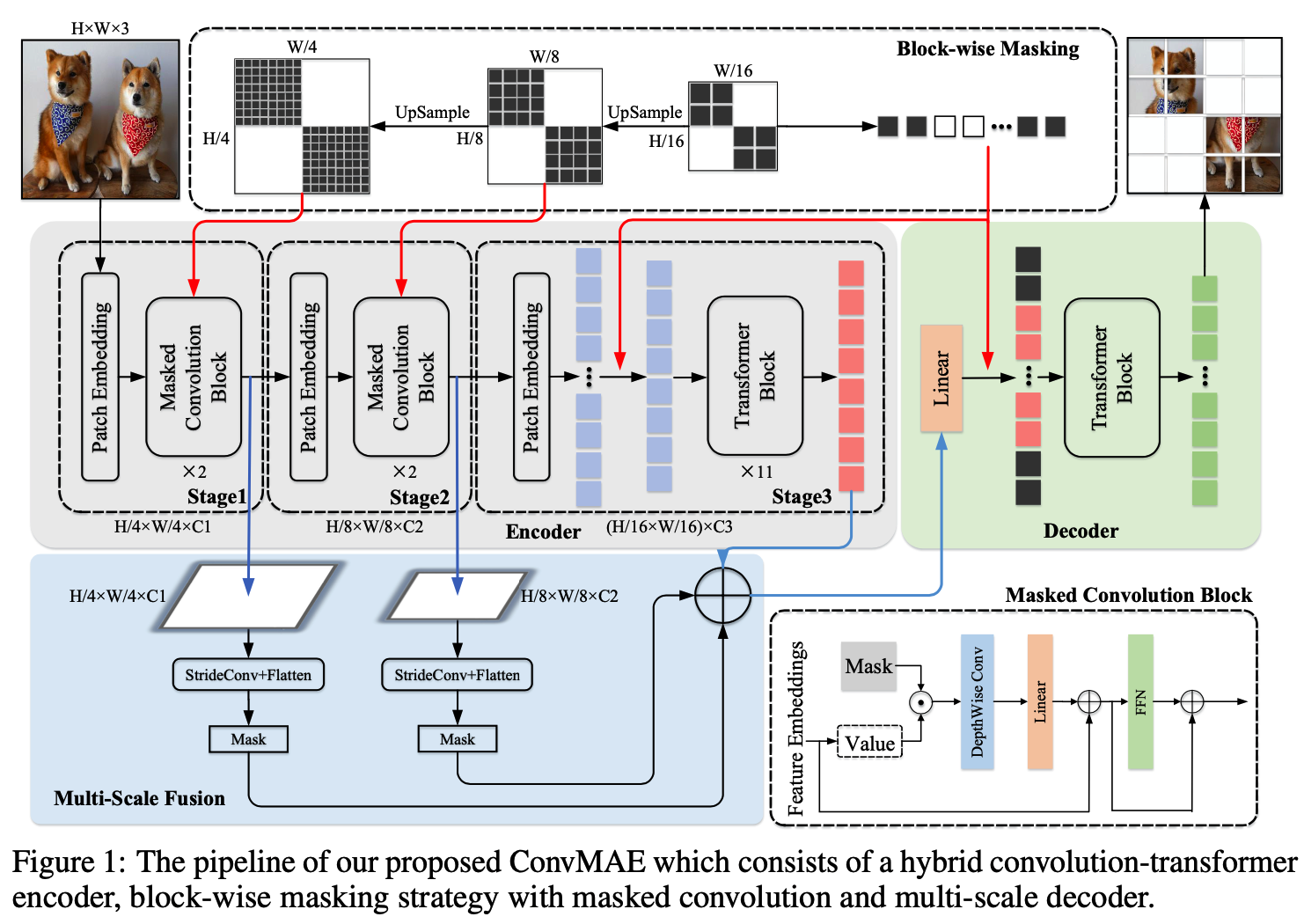
ConvMAE的总体流程
与MAE不同的是,ConvMAE的编码器将输入图像逐步抽象为多尺度token embedding,而解码器则重建被mask掉的tokens对应的像素。对于前面stage部分的高分辨率token embedding,采用卷积块对局部进行编码,对于后面的低分辨率token embedding,则使用transformer来聚合全局信息。因此,ConvMAE的编码器在不同阶段可以同时获得局部和全局信息,并生成多尺度特征。
当前的masked auto encoding框架,如BEiT,SimMIM,所采用的mask策略不能直接用于ConvMAE,因为在后面的transformer阶段,所有的tokens都需要保留。这导致对大模型进行预训练的计算成本过高,失去了MAE在transformer编码器中省去masked tokens的效率优势。此外,直接使用convolution-transformer结构的编码器进行预训练会导致卷积部分因为随机的mask而造成预训练的信息泄露,因而也会降低预训练所得模型的质量。
针对这些问题,ConvMAE提出了混合convolution-transformer架构。ConvMAE采用分块mask策略 (block-wise masking strategy):,首先随机在后期的获取transformer token中生成后期的mask,然后对mask固定位置逐步进行上采样到早期卷积阶段的高分辨率。这样,后期处理的token可以完全分离为masked tokens和visible tokens,从而并继承了MAE使用稀疏encoder的计算效率。
下面将分别针对encoder、mask策略以及decoder部分展开介绍。
Encoder
如总体流程图所示,encoder包括3 个阶段,每个阶段输出的特征维度分别是:H/4 × W/4, H/8 × W/8, H/16 × W/16,其中H × W为输入图像分辨率。前两个是卷积阶段,使用卷积模块将输入转换为token embeddings E1 ∈ R^(H/4 × W/4 ×C1) and E2 ∈ R^(H/8 × W/8 ×C2) 。其中卷积模块用5 × 5的卷积代替self-attention操作。前两个阶段的感受野较小主要捕捉图像的局部特征,第三个阶段使用transformer模块,将粗粒度特征融合, 并将感受野扩展到整个图像,获得token embeddings E3 ∈ R(H/16 × W/16 ×C3)。在每个阶段之间,使用stride为2的卷积对tokens进行下采样。
其他包含transformer的结构,如CPT、Container、Uniformer、CMT、Swin等,在第一阶段的输入用相对位置编码或零填充卷积替代绝对位置编码,而作者发现在第3个transformer stage中使用绝对位置编码可获得最优性能。class token也从编码器中移除。
Mask策略
MAE、BEiT等,对输入patch采用随机mask。但同样的策略不能直接应用于ConvMAE编码器:如果独立地从stage-1的H/4 × W/4个tokens中随机抽取mask,将导致降采样后的stage-3的几乎所有token都有部分可见信息,使得编码器不再稀疏。因此作者提出,从stage-3的输入tokens中以同样比例 (例如75%)生成mask,再对mask上采样2倍和4倍,分别作为stage-2和stage-1的mask。这样,ConvMAE在3个阶段都只含有很少的(例如25%)可见token,从而使得预训练时编码器的效率不受影响。而解码器的任务e则保持相同,即重建编码过程中被mask掉的tokens。
同时,前2个阶段的5X5卷积操作会在masked patches的边缘处泄漏不可见token的重建答案。为了避免这种情况保证预训练的质量,作者在前两个阶段采用了masked convolution, 使被mask掉的区域不参与编码过程。
Decoder
原始MAE的decoder的输入以编码器的输出和mask掉的tokens作为输入,然后通过堆叠的transformer blocks进行图像重建。ConvMAE编码器获得多尺度特征E1、E2、E3,同时捕获细粒度和粗粒度图像信息。为了更好地的预训练,作者通过stride-4和stride-2卷积将E1和E2下采样到E3的相同大小,并进行多尺度特征融合,再通过一个linear层得到最终要输入给 decoder 的可见token。目标函数和MAE相同,仅采用MSE作为损失函数,计算预测向量和被mask掉像素值之前的MSE loss,即只考虑mask掉的patches的重建。
下游任务

预训练之后,ConvMAE可以输出多尺度的特征用于检测分割任务。
检测任务中,先将第stage-3的输出特征E3通过2x2最大池化获得E4。由于ConvMAE stage-3有11个self-attention层(ConvMAE-base),计算成本过高,作者参考ViT的benchmark将stage-3中除第1、4、7、11之外的所有global self-attention layers替换为了Window size7×7 的 local self-attention 层。修改后的local self-attention仍然由预训练的global self-attention进行初始化。global transformer blocks之间共享global relative position bias,local transformer blocks之间共享local relative position bias,这样就大大减轻了stage-3的计算和GPU内存开销。然后将多尺度特征E1、E2、E3、E4送入MaskRCNN head进行目标检测。
而分割任务保留了stage-3的结构。
Benchmark
图像分类
ConvMAE基于ImageNet-1K,mask掉25%的input token做预训练,Decoder部分是一个8层的transformer,embedding 维度是512,head是12个。预训练参数和分类finetuning结果如下:
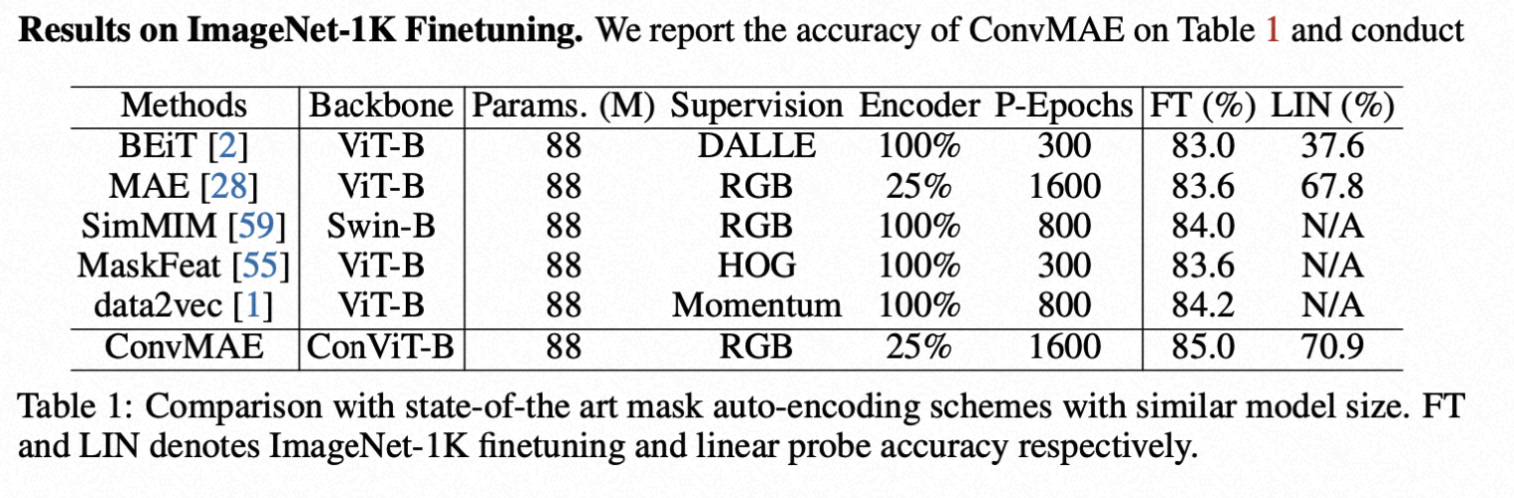
BEiT预训练300个epoch,finetune的精度达到83.0%,linear-prob的精度是37.6%。与BEiT相比,ConVMAE仅需要25%的token和一个轻量级的decoder finetune可达到85%,linear-prob可以达到70.9%。与原来的MAE相比,预训练相同的1600个epoch,ConVMAE比MAE提升1.4个点。与SimMIM(backbone使用Swin-B)相比提升了1个点。
检测
作者用ConvMAE替换Mask-RCNN的backbone,加载ConvMAE的预训练模型训练COCO数据集。
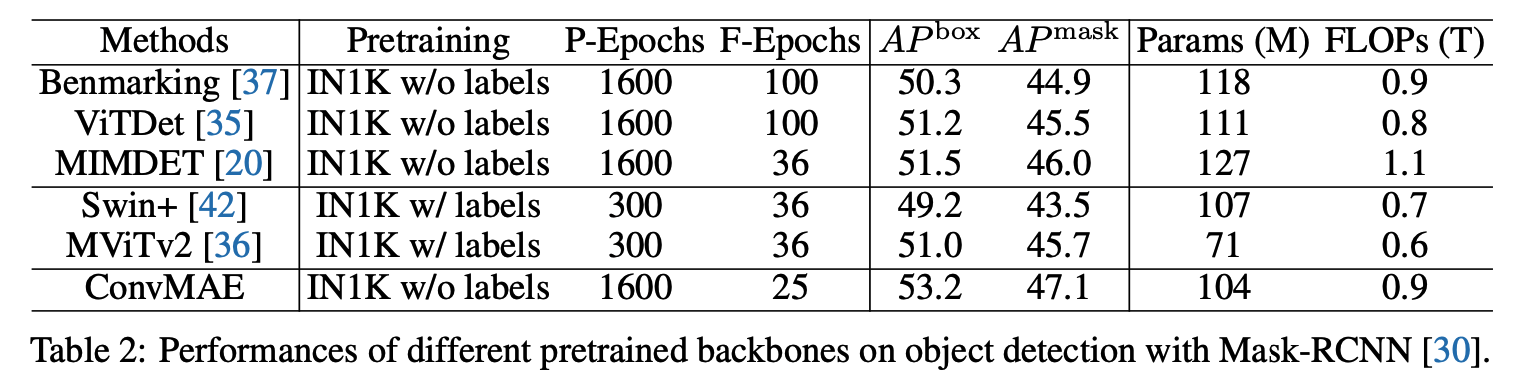

与ViT在COCO数据集上finetune100个epoch的结果相比,ConVMAE仅finetune 25个epoch在APbox和APmask就提升了2.9和2.2个点。
与ViTDet和MIMDet相比,ConvMAE finetune epoch更少、参数更少,分别超过了它们2.0%和1.7%。
与Swin和MViTv2相比,在APbox/APmask,其性能分别高出4.0%/3.6%和2.2%/1.4%。
分割
作者用ConvMAE替换UperNet的backbone,加载ConvMAE的预训练模型训练ADE20K数据集。
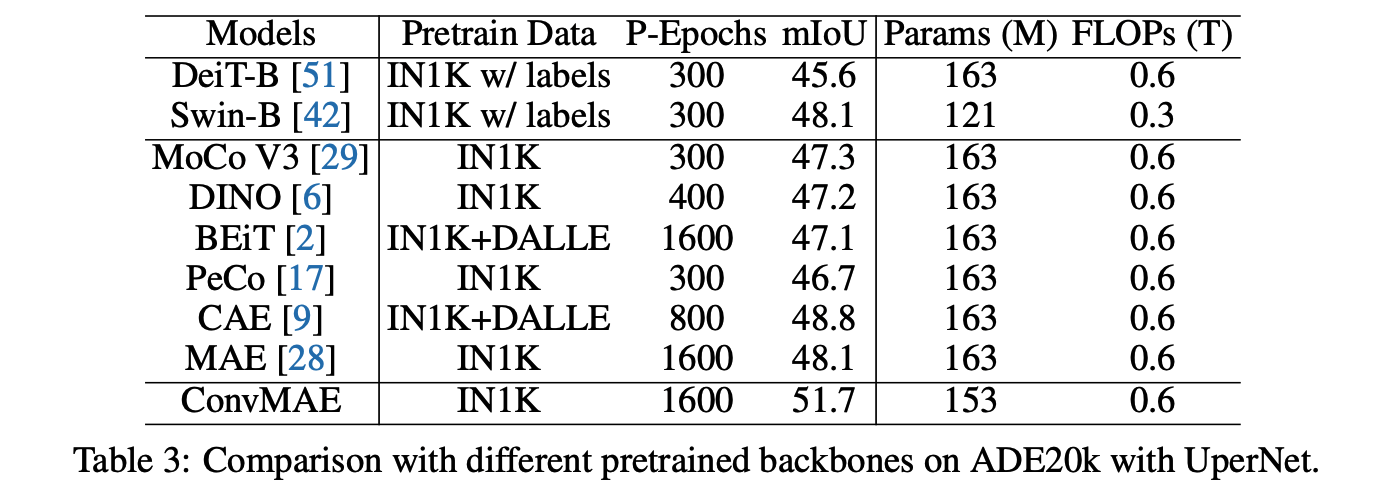
从结果中可以看出,相比与DeiT, Swin,MoCo-v3等网络ConvMAE取得了更高的性能(51.7%)。表明ConvMAE的多尺度特征大大缩小了预训练Backbone 和下游网络之间的传输差距。
Fast ConvMAE
ConvMAE虽然在分类、检测、分割等下游任务中有了精度提升,并解决了pretraining-finetuning 的差异问题,但是模型的预训练依然耗时,ConvMAE的结果中,模型预训练了1600个epoch,因此作者又在ConvMAE的基础之上做了进一步的性能优化,提出了Fast ConvMAE,FastConvMAE提出了mask互补和deocder融合的方案,来实现快速的mask建模方案,进一步缩短了预训练的时间,从原来预训练的1600epoch缩短到了50epoch。FastConvMAE的正式论文作者会在未来发出。

首先,FastConvMAE创新地设计出decoder互相融合的Mixture of Reconstructor (MoR),可以让masked patches从不同的tokenizer中学习到互补的信息,包括EMA 的self-ensembling性质,DINO的similarity-discrimination能力,以及CLIP的multimodal知识。MoR主要包括两个部分,Partially-Shared Decoder(PS-Decoder)和Mixture of Tokenizer(MoT), PS-Decoder可以避免不同tokenizer的不同知识之间会产生梯度的冲突,MoT是用来生成不同的token作为masked patches的target。
同时Mask部分采用了互补策略,原来的mask每次只会保留例如25%的tokens,FastConvMAE将mask分成了4份,每一份都保留25%,4份mask之间互补。这样,相当于1张图片被分成了4张图片进行学习,理论上达到了4倍的学习效果。
def random_masking(self, x, mask_ratio=None):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N = x.shape[0]
L = self.num_patches
len_keep = int(L * (1 - mask_ratio))
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(
noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep1 = ids_shuffle[:, :len_keep]
ids_keep2 = ids_shuffle[:, len_keep:2 * len_keep]
ids_keep3 = ids_shuffle[:, 2 * len_keep:3 * len_keep]
ids_keep4 = ids_shuffle[:, 3 * len_keep:]
# generate the binary mask: 0 is keep, 1 is remove
mask1 = torch.ones([N, L], device=x.device)
mask1[:, :len_keep] = 0
# unshuffle to get the binary mask
mask1 = torch.gather(mask1, dim=1, index=ids_restore)
mask2 = torch.ones([N, L], device=x.device)
mask2[:, len_keep:2 * len_keep] = 0
# unshuffle to get the binary mask
mask2 = torch.gather(mask2, dim=1, index=ids_restore)
mask3 = torch.ones([N, L], device=x.device)
mask3[:, 2 * len_keep:3 * len_keep] = 0
# unshuffle to get the binary mask
mask3 = torch.gather(mask3, dim=1, index=ids_restore)
mask4 = torch.ones([N, L], device=x.device)
mask4[:, 3 * len_keep:4 * len_keep] = 0
# unshuffle to get the binary mask
mask4 = torch.gather(mask4, dim=1, index=ids_restore)
return [ids_keep1, ids_keep2, ids_keep3,
ids_keep4], [mask1, mask2, mask3, mask4], ids_restore
前两个卷积阶段将输入转换为embeddings tokens E1和E2。然后E1和E2分别从4份mask中获取4份可见的tokens并进行拼接,作为decoder的输入,Decoder处理的是拼接后的tokens。代码参考如下:
def encoder_forward(self, x, mask_ratio):
# embed patches
ids_keep, masks, ids_restore = self.random_masking(x, mask_ratio)
mask_for_patch1 = [
1 - mask.reshape(-1, 14, 14).unsqueeze(-1).repeat(
1, 1, 1, 16).reshape(-1, 14, 14, 4, 4).permute(
0, 1, 3, 2, 4).reshape(x.shape[0], 56, 56).unsqueeze(1)
for mask in masks
]
mask_for_patch2 = [
1 - mask.reshape(-1, 14, 14).unsqueeze(-1).repeat(
1, 1, 1, 4).reshape(-1, 14, 14, 2, 2).permute(
0, 1, 3, 2, 4).reshape(x.shape[0], 28, 28).unsqueeze(1)
for mask in masks
]
s1 = self.patch_embed1(x)
s1 = self.pos_drop(s1)
for blk in self.blocks1:
s1 = blk(s1, mask_for_patch1)
s2 = self.patch_embed2(s1)
for blk in self.blocks2:
s2 = blk(s2, mask_for_patch2)
stage1_embed = self.stage1_output_decode(s1).flatten(2).permute(0, 2, 1)
stage2_embed = self.stage2_output_decode(s2).flatten(2).permute(0, 2, 1)
stage1_embed_1 = torch.gather(
stage1_embed,
dim=1,
index=ids_keep[0].unsqueeze(-1).repeat(1, 1, stage1_embed.shape[-1]))
stage2_embed_1 = torch.gather(
stage2_embed,
dim=1,
index=ids_keep[0].unsqueeze(-1).repeat(1, 1, stage2_embed.shape[-1]))
stage1_embed_2 = torch.gather(
stage1_embed,
dim=1,
index=ids_keep[1].unsqueeze(-1).repeat(1, 1, stage1_embed.shape[-1]))
stage2_embed_2 = torch.gather(
stage2_embed,
dim=1,
index=ids_keep[1].unsqueeze(-1).repeat(1, 1, stage2_embed.shape[-1]))
stage1_embed_3 = torch.gather(
stage1_embed,
dim=1,
index=ids_keep[2].unsqueeze(-1).repeat(1, 1, stage1_embed.shape[-1]))
stage2_embed_3 = torch.gather(
stage2_embed,
dim=1,
index=ids_keep[2].unsqueeze(-1).repeat(1, 1, stage2_embed.shape[-1]))
stage1_embed_4 = torch.gather(
stage1_embed,
dim=1,
index=ids_keep[3].unsqueeze(-1).repeat(1, 1, stage1_embed.shape[-1]))
stage2_embed_4 = torch.gather(
stage2_embed,
dim=1,
index=ids_keep[3].unsqueeze(-1).repeat(1, 1, stage2_embed.shape[-1]))
stage1_embed = torch.cat([
stage1_embed_1, stage1_embed_2, stage1_embed_3, stage1_embed_4
])
stage2_embed = torch.cat([
stage2_embed_1, stage2_embed_2, stage2_embed_3, stage2_embed_4
])
x = self.patch_embed3(s2)
x = x.flatten(2).permute(0, 2, 1)
x = self.patch_embed4(x)
# add pos embed w/o cls token
x = x + self.pos_embed
x1 = torch.gather(x, dim=1, index=ids_keep[0].unsqueeze(-1).repeat(1, 1, x.shape[-1]))
x2 = torch.gather(x, dim=1, index=ids_keep[1].unsqueeze(-1).repeat(1, 1, x.shape[-1]))
x3 = torch.gather(x, dim=1, index=ids_keep[2].unsqueeze(-1).repeat(1, 1, x.shape[-1]))
x4 = torch.gather(x, dim=1, index=ids_keep[3].unsqueeze(-1).repeat(1, 1, x.shape[-1]))
x = torch.cat([x1, x2, x3, x4])
# apply Transformer blocks
for blk in self.blocks3:
x = blk(x)
x = x + stage1_embed + stage2_embed
x = self.norm(x)
mask = torch.cat([masks[0], masks[1], masks[2], masks[3]])
return x, mask, ids_restore
Benchmark
EasyCV复现的结果如下:
ImageNet Pretrained
Config | Epochs | Download |
fast_convmae_vit_base_patch16_8xb64_50e | 50 | model - log |
ImageNet Finetuning
Algorithm | Fintune Config | Pretrained Config | Top-1 | Download |
Fast ConvMAE(EasyCV) | fast_convmae_vit_base_patch16_8xb64_100e_fintune | fast_convmae_vit_base_patch16_8xb64_50e | 84.4% | fintune model - log |
Fast ConvMAE(官方) | 84.4% |
Object Detection
Algorithm | Eval Config | Pretrained Config | mAP (Box) | mAP (Mask) | Download |
Fast ConvMAE(EasyCV) | mask_rcnn_conv_vitdet_50e_coco | fast_convmae_vit_base_patch16_8xb64_50e | 51.3% | 45.6% | finetune model |
Fast ConvMAE(官方) | 51.0% | 45.4% |
从结果可以看出,仅预训练50个epoch,ImageNet Finetuning的精度就超过MAE预训练1600个epoch的精度0.77个点(83.6/84.37)。在检测任务上,精度也超过ViTDet和Swin。
FastConvMAE的更多官方结果请参考:https://github.com/Alpha-VL/FastConvMAE 。
Tutorial
一、安装依赖包
如果是在本地开发环境运行,可以参考该链接安装环境。若使用PAI-DSW进行实验则无需安装相关依赖,在PAI-DSW docker中已内置相关环境。
二、数据准备
数据准备请参考文档:https://github.com/alibaba/EasyCV/blob/master/docs/source/prepare_data.md
三、模型预训练
FastConvMAE占用显存较大,建议使用A100资源。(FastConvMAE一次forward-backward等价于ConvMAE forward-backward 4次)
在EasyCV中,使用配置文件的形式来实现对模型参数、数据输入及增广方式、训练策略的配置,仅通过修改配置文件中的参数设置,就可以完成实验配置进行训练。
配置EasyCV路径
# 查看easycv安装位置
import easycv
print(easycv.__file__)
$ export PYTHONPATH=$PYTHONPATH:${your EasyCV root path}
训练
$ python -m torch.distributed.launch --nproc_per_node=8 --master_port=29930 \
tools/train.py \
configs/selfsup/fast_convmae/fast_convmae_vit_base_patch16_8xb64_50e.py \
--work_dir ./work_dir \
--launcher pytorch
下游任务finetune
下载预训练模型
$ wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/modelzoo/selfsup/FastConvMAE/pretrained/epoch_50.pth- 单卡
$ python tools/train.py \
${CONFIG_FILE} \
--work_dir ./work_dir \
--load_from=./epoch_50.pth
- 多卡
$ python -m torch.distributed.launch --nproc_per_node=8 --master_port=29930 \
tools/train.py \
${CONFIG_FILE} \
--work_dir ./work_dir \
--launcher pytorch \
--load_from=./epoch_50.pth
分类任务 CONFIG_FILE 请参考:https://github.com/alibaba/EasyCV/tree/master/benchmarks/selfsup/classification/imagenet/fast_convmae_vit_base_patch16_8xb64_100e_fintune.py
分类任务 CONFIG_FILE 请参考:https://github.com/alibaba/EasyCV/blob/master/benchmarks/selfsup/detection/coco/mask_rcnn_conv_vitdet_50e_coco.py
Reference
EasyCV:https://github.com/alibaba/EasyCV/blob/master/easycv/models/backbones/conv_mae_vit.py
EasyCV往期分享
- 基于EasyCV复现DETR和DAB-DETR,Object Query的正确打开方式
- 基于EasyCV复现ViTDet:单层特征超越FPN
- MAE自监督算法介绍和基于EasyCV的复现
- EasyCV开源|开箱即用的视觉自监督+Transformer算法库










