研究算法的人知道,排序算法真的很重要,也是算法研究中的最基础的东西,研究算法先研究排序算法,排序的问题无处不在..........
排序的定义:
输入:n个数:a1,a2,a3, ...,an
输出:n个数的排列:a1',a2',a3',...,an',使得a1'<=a2'<=a3'<=...<=an'。
In-place sort(不占用额外内存或占用常数的内存):插入排序、选择排序、冒泡排序、堆排序、快速排序。
Out-place sort:归并排序、计数排序、基数排序、桶排序。
stable sort:插入排序、冒泡排序、归并排序、计数排序、基数排序、桶排序。
unstable sort:选择排序(5 8 5 2 9)、快速排序、堆排序。
一、插入排序
插入排序对于少量的元素的排序,它是一个有效的算法。
特点:stable_sort 、in-place sort
最优复杂度:当属数组本来是有序的时候,其复杂度为O(n),二快速排序在这种情况下会产生O(n^2)的复杂度。
最差复杂度:当输入的数组为倒序的时候,其复杂度为O(n^2)。

void insert_sort3(vector<int> &a)
{
size_t len = a.size();
int j;
for (int i = 1; i < len; i++)
{
int key = a[i];
j = i - 1;
while (j >=0 && a[j]>key)
{
a[j + 1] = a[j];
j--;
}
a[j + 1] = key;
}
}
二、冒泡排序算法
特点:stable sort、In-place sort
思想:通过两两交换,像水中的泡泡一样,小的先冒出来,大的后冒出来。
最坏运行时间:O(n^2)
最佳运行时间:O(n^2)(当然,也可以进行改进使得最佳运行时间为O(n))
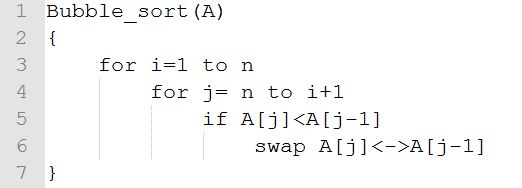
其思想是交换相邻的两个数,把大数沉到后面去。
void BubbleSort(vector<int> &a)
{
size_t n = a.size();
size_t temp;
for (int i = 0; i < n-1; ++i)
{
for (int j = 0; j < n-1-i; ++j)
{
if (a[j] > a[j + 1])
{
temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
}
}
在算法导论思考题中又问了”冒泡排序和插入排序哪个更快“呢?
一般的人回答:“差不多吧,因为渐近时间都是O(n^2)”。
但是事实上不是这样的,插入排序的速度直接是逆序对的个数,而冒泡排序中执行“交换“的次数是逆序对的个数,因此冒泡排序执行的时间至少是逆序对的个数,因此插入排序的执行时间至少比冒泡排序快。
三、选择排序算法
思想是,每一轮比较中选择最小的一个与第一个数据进行交换,有n个数,从第2到n数中选择比第一个小的数进行交换.......
特性:In-place sort,unstable sort。
思想:每次找一个最小值。
最好情况时间:O(n^2)。
最坏情况时间:O(n^2)。
#include<iostream>
#include<vector>
using namespace std;
void swap(int* a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void select_sort(vector<int> &a)
{
int len = a.size();
for (int i = 0; i < len; i++)
{
int min = i;
for (int j = i + 1; j < len; j++)
{
if (a[j] < a[i])
{
min = j;
}
}
if (i != min)
{
swap(&a[i], &a[min]);
}
}
}
int main()
{
vector<int> a = { 9, 8, 7, 6, 5, 4, 3, 2, 1, 0 };
select_sort(a);
for (auto i : a)
cout << i << " ";
cout << endl;
return 0;
}
四、归并排序
归并排序采用了算法设计中的分治法,分治法的思想是将原问题分解成n个规模较小而结构与原问题相似的小问题,递归的解决这些子问题,然后再去合并其结果,得到原问题的解。分治模式在每一层递归上有三个步骤:
分解(divide):将原问题分解成一系列子问题。
解决(conquer):递归地解答各子问题,若子问题足够小,则直接求解。
合并(combine):将子问题的结果合并成原问题的解。
归并排序(merge sort)算法按照分治模式,操作如下:
分解:将n个元素分解成各含n/2个元素的子序列
解决:用合并排序法对两个序列递归地排序
合并:合并两个已排序的子序列以得到排序结果
在对子序列排序时,长度为1时递归结束,单个元素被视为已排序好的。归并排序的关键步骤在于合并步骤中的合并两个已经有序的子序列,引入了一个辅助过程,merge(A,p,q,r),将已经有序的子数组A[p...q]和A[q+1...r]合并成为有序的A[p...r]。书中给出了采用哨兵实现merge的伪代码,课后习题要求不使用哨兵实现merge过程。在这个两种方法中都需要引入额外的辅助空间,用来存放即将合并的有序子数组,总的空间大小为n。
#include<iostream>
using namespace std;
//merge two array:对两个有序列进行合并
void merge(int a[], int temp[], int first, int mid, int end)
{
int i = first, j = mid + 1;
int m = mid, n = end;
int k = 0;
while (i <= m && j <= n)
{
if (a[i] <= a[j])
temp[k++] = a[i++];
else
temp[k++] = a[j++];
}
while (i <= m)
temp[k++] = a[i++];
while (j <= n)
temp[k++] = a[j++];
for (int i = 0; i < k; i++)/*把存储在temp中排好的序列copy到a中对应的下标上*/
a[first + i] = temp[i];
}
void merge_sort(int a[], int first, int last, int temp[])
{
if (first < last)
{
int mid = (first + last) / 2;
merge_sort(a, first, mid, temp); //it's let letf have a regular
merge_sort(a, mid + 1, last, temp); //it's let right have a regular
merge(a, temp, first, mid, last); //merge two in one
}
}
int main()
{
int a[] = { 1, 8, 6, 7, 9, 45, 68, 100, 5 };
int k = (sizeof(a) / sizeof(int));
int *p = new int[k];
merge_sort(a, 0, k - 1, p);
delete[] p;
for (int i = 0; i < k; i++)
cout << a[i] << " ";
return 0;
}
问:归并排序的缺点是什么?
答:他是Out-place sort,因此相比快排,需要很多额外的空间。
问:为什么归并排序比快速排序慢?
答:虽然渐近复杂度一样,但是归并排序的系数比快排大。
问:对于归并排序有什么改进?
答:就是在数组长度为k时,用插入排序,因为插入排序适合对小数组排序。在算法导论思考题中介绍了。复杂度为O(nk+nlg(n/k)) ,当k=O(lgn)时,复杂度为O(nlgn)
五、快速排序
Tony Hoare爵士在1962年发明,被誉为“20世纪十大经典算法之一”。
算法导论中讲解的快速排序的PARTITION是Lomuto提出的,是对Hoare的算法进行一些改变的,而算法导论7-1介绍了Hoare的快排。
特性:unstable sort、In-place sort。
最坏运行时间:当输入数组已排序时,时间为O(n^2),当然可以通过随机化来改进(shuffle array 或者 randomized select pivot),使得期望运行时间为O(nlgn)。
最佳运行时间:O(nlgn)
快速排序的思想也是分治法。
当输入数组的所有元素都一样时,不管是快速排序还是随机化快速排序的复杂度都为O(n^2),而在算法导论第三版的思考题7-2中通过改变Partition函数,从而改进复杂度为O(n)。
注意:只要partition的划分比例是常数的,则快排的效率就是O(nlgn),比如当partition的划分比例为10000:1时(足够不平衡了),快排的效率还是O(nlgn)
伪代码:
PARTITION(A,p,r)
x = A[r] //将最后一个元素作为主元素
i = p-1
for j=p to r-1 //从第一个元素开始到倒数第二个元素结束,比较确定主元的位置
do if A[j] <= x
i = i+1
exchange A[i] <-> A[j]
exchange A[i+1]<->A[r] //最终确定主元的位置
return i+1 //返回主元的位置
#include<iostream>
using namespace std;
void swap(int *x, int *y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//划分数组
int partition(int a[], int begin, int last)
{
int x = a[last];
int i = begin - 1;
for (int j = begin; j < last; j++)
{
if (x <= a[j])
{
i=i+1;
swap(&a[i], &a[j]);
}
}
swap(&a[i+1], &a[last]);
return (i + 1);
}
//利用递归排序
void quick_sort(int a[], int begin, int last)
{
if (begin < last)
{
int q = partition(a, begin, last);
quick_sort(a, begin, q-1);
quick_sort(a, q + 1, last);
}
}
int main()
{
int i;
int a[] = { 88, 1, 22, 99, 55, 77, 33, 66, 44, 70 };
cout << "After the quick sort,the data is:" << endl;
quick_sort(a, 0, 9);
for (const auto i : a)
cout << i << " ";
cout << endl;
return 0;
}
1964年Williams提出。
特性:unstable sort、In-place sort。
最优时间:O(nlgn)
最差时间:O(nlgn)
此篇文章介绍了堆排序的最优时间和最差时间的证明:javascript:void(0)
思想:运用了最小堆、最大堆这个数据结构,而堆还能用于构建优先队列。
优先队列应用于进程间调度、任务调度等。
堆数据结构应用于Dijkstra、Prim算法。
1、建堆
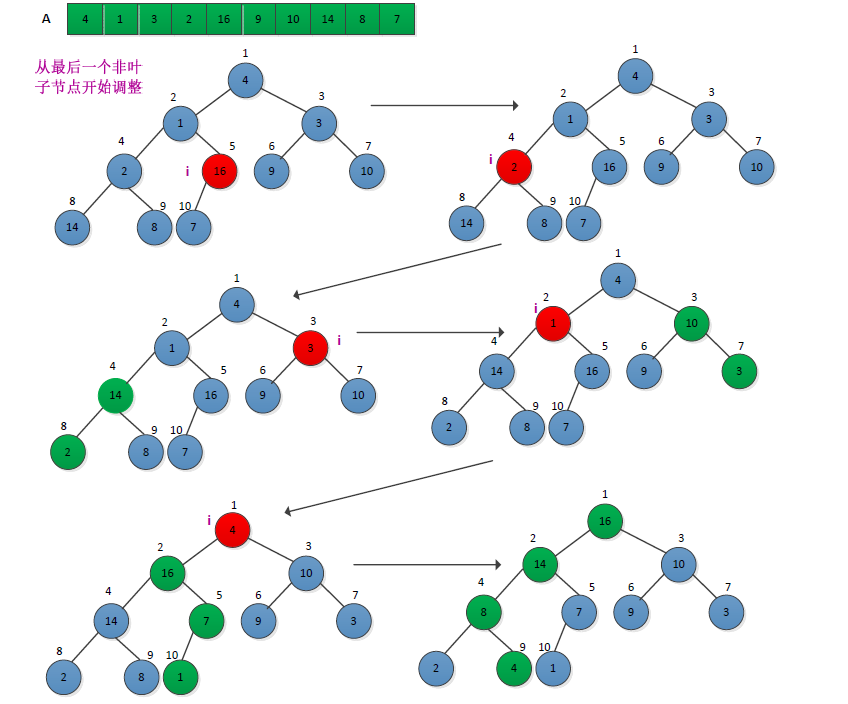
建立最大堆的过程是自底向上地调用最大堆调整程序将一个数组A[1.....N]变成一个最大堆。将数组视为一颗完全二叉树,从其最后一个非叶子节点(n/2)开始调整。调整过程如下图所示:
2、排序:
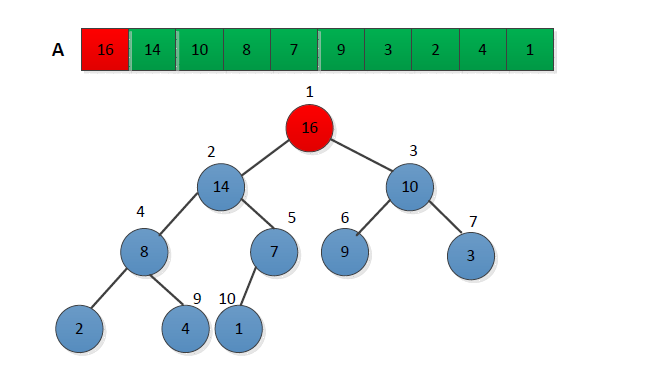
堆排序算法过程为:先调用创建堆函数将输入数组A[1...n]造成一个最大堆,使得最大的值存放在数组第一个位置A[1],然后用数组最后一个位置元素与第一个位置进行交换,并将堆的大小减少1,并调用最大堆调整函数从第一个位置调整最大堆。给出堆数组A={4,1,3,16,9,10,14,8,7}进行堆排序简单的过程如下:
(1)创建最大堆,数组第一个元素最大,执行后结果下图:
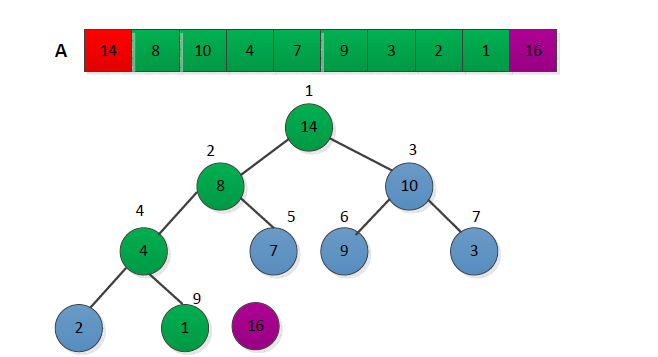
(2)进行循环,从length(a)到2,并不断的调整最大堆,给出一个简单过程如下:
/*****************************************************************************/
/*time:2014.11.15 author:chen stallman */
/*1.建立最大堆 */
/*2.把数组转换成最大堆 */
/*3.把建好的堆中数据与原数组进行数据交换 */
/*****************************************************************************/
#include<iostream>
#include<algorithm>
using namespace std;
void swap(int *x, int *y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//建立以root为i(即根节点为i)的最大堆,利用了递归的思想防止调整之后以largest为父节点的子树不是最大堆
void max_heapify(int a[], int i, int heapsize)
{
int l = 2 * i;//取其左孩子的坐标
int r = 2 * i + 1;//取其右孩子的坐标
int largest;//临时变量,用来保存r、l、r三个节点中最大的值
if (l<=heapsize&&a[l]>a[i])
largest = l;
else
largest = i;
if (r<=heapsize&&a[r]>a[largest])
largest = r;
if (largest != i)
{
swap(&a[i], &a[largest]);
max_heapify(a, largest, heapsize);
}
}
//***********************************************
//用自底向上的方法把数组转换成最大堆
void buil_max_heap(int a[], int heapsize)
{
int i;
//从heapsize/2+1到heapsize的节点都是叶节点,所以我们可以把他们都看成是包含一个元素的最大堆了
//所以从数组1到heapsize的有叶节点的节点建立最大堆
for (i = heapsize / 2; i >= 1; i--)
{
max_heapify(a, i, heapsize);
}
}
//有了上面这个两个辅助功能函数就可以对数组进行堆排序了
void heap_sort(int a[], int len)
{
int i;
buil_max_heap(a, len);
for (i = len; i >= 2; i--)
{
swap(&a[1], &a[len]);
len--;
max_heapify(a, 1, len);
}
}
int main()
{
//这里数组下标从1开始,数组第一个元素没有使用
int a[] = { 0,12,-3,88,52,6,4,33,2,100,5,20};
max_heapify(a, 1, 11);
for (auto i : a)
cout << i << endl;
heap_sort(a, 11);
for (auto i : a)
cout << i << " ";
cout << endl;
return 0;
}
七、计数排序
特性:stable sort、out-place sort。
最坏情况运行时间:O(n+k)
最好情况运行时间:O(n+k)
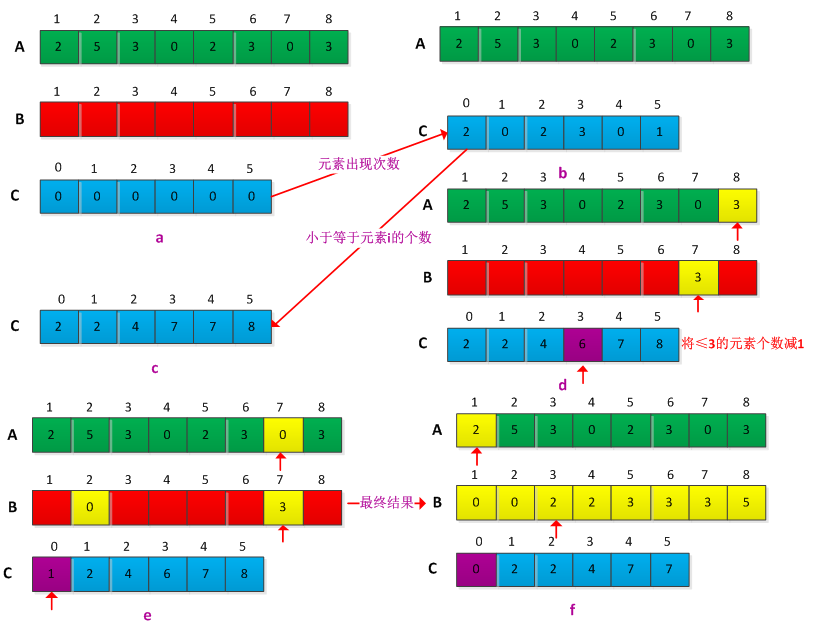
计数排序假设n个输入元素中的每一个都介于0和k之间的整数,k为n个数中最大的元素。当k=O(n)时,计数排序的运行时间为θ(n)。计数排序的基本思想是:对n个输入元素中每一个元素x,统计出小于等于x的元素个数,根据x的个数可以确定x在输出数组中的最终位置。此过程需要引入两个辅助存放空间,存放结果的B[1...n],用于确定每个元素个数的数组C[0...k]。算法的具体步骤如下:
(1)根据输入数组A中元素的值确定k的值,并初始化C[1....k]= 0;
(2)遍历输入数组A中的元素,确定每个元素的出现的次数,并将A中第i个元素出现的次数存放在C[A[i]]中,然后C[i]=C[i]+C[i-1],在C中确定A中每个元素前面有多个元素;
(3)逆序遍历数组A中的元素,在C中查找A中出现的次数,并结果数组B中确定其位置,然后将其在C中对应的次数减少1。
举个例子说明其过程,假设输入数组A=<2,5,3,0,2,3,0,3>,计数排序过程如下:
#include<iostream>
using namespace std;
void count_sort(int a[], int b[], int k, int length)
{
int i, j;
//each element in A between 0 and k [0,k],total k+1 elements;
// int *c = new int[k + 1];
int *c = (int*)malloc(sizeof(int)*(k+1));
memset(c, 0, (k+1)*sizeof(int));
//c[i] now contains the number of element equal to i;
for (i = 0; i < length; ++i)
c[a[i]] = c[a[i]] + 1;
//c[i] now contains the number of elements less than or equal to i;
for (j = 1; j <= k; ++j)
c[j] = c[j] + c[j - 1];
for (i = length - 1; i >= 0; i--)
{
b[c[a[i]] - 1] = a[i];
c[a[i]] = c[a[i]] - 1;
}//a[i]表示输入的元素,c[a[i]]表示出现的次数,那么b[c[a[i]] - 1]表示a[i]放到b数组中的位置
//放入之后,那么c[a[i]]的次数应该减少
}
int main()
{
int a[] = { 5, 6, 9, 5, 0, 8, 2, 1, 6, 9, 8, 3, 4, 8, 6, 7, 6, 3, 3, 3, 3, 3, 8, 8, 8,11 };
int len = sizeof(a) / sizeof(int);
//cout << len << endl;
int b[26];
count_sort(a, b, 11, len);
for (int i = 0; i < len;i++)
cout << b[i] << " ";
}
八、基数排序
特性:stable sort、Out-place sort。
最坏情况运行时间:O((n+k)d)
最好情况运行时间:O((n+k)d)
从计数排序的思想及过程可以看出,当输入数组A中的数较大的时候,就不适合。因为需要开辟最大元个辅助数组,统计每个元素的出现次数。通常计数排序用在基数排序中,作为一个子程序。
计数排序最重要的性质就是它是稳定的:具有相同值的元素在输出数组中的相对次序与它们在输入数组中的次序相同。
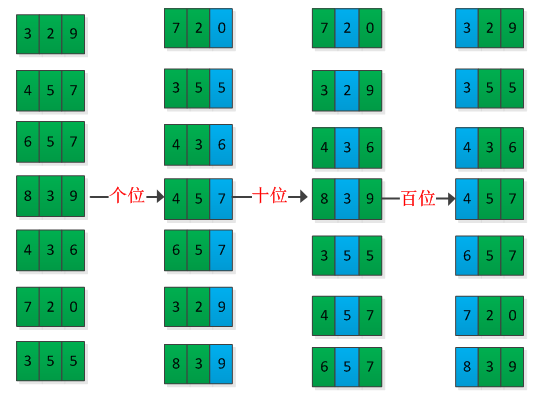
基数排序排序过程无须比较关键字,而是通过“分配”和“收集”过程来实现排序,它的时间复杂度可达到线性阶:O(n)。对于十进制数来说,每一位的在[0,9]之中,d位的数,则有d列。基数排序首先按低位有效数字进行排序,然后逐次向上一位进行排序,直到最高位排序结束。举例说明基数排序过程,如下图所示:
#include<iostream>
using namespace std;
int get_digit_num(int data)
{
int size=0;
while (data)
{
size++;
data = data / 10;
}
return size;
}
int get_digit(int data, int size)
{
int tmp;
tmp= data;
while (size)
{
tmp = tmp / 10;
size--;
}
return (tmp % 10);
}
void radix_sort(int *datas, int len, int size)
{
int i, j, k;
int *num = (int*)malloc(len * sizeof(int));
int *counts = (int*)malloc(len * sizeof(int));
int *save = (int*)malloc(len * sizeof(int));
//memset(temps, 0, 10 * sizeof(int));
//memset(tmpd, -1, 10 * sizeof(int));
//memset(rets, -1, 10 * sizeof(int));
for (i = 0; i < size; i++)
{
memset(num, 0, len * sizeof(int));
memset(counts, 0, len * sizeof(int));
memset(save, 0, len * sizeof(int));
for (j = 0; j < len; j++)
num[j] = get_digit(datas[j], i);
for (j = 0; j < len; j++)
counts[num[j]] = counts[num[j]] + 1;
for (k = 1; k < 10; k++)
counts[k] = counts[k] + counts[k - 1];
for (j = len - 1; j >= 0; j--)
{
save[counts[num[j]] - 1] = datas[j];
counts[num[j]] = counts[num[j]] - 1;
}
memcpy(datas, save, sizeof(int)*len);
}
free(num);
free(counts);
free(save);
}
int max(int *datas, size_t length)
{
int k = datas[0];
int i;
for (i = 1; i<length; ++i)
if (datas[i] > k)
k = datas[i];
return k;
}
int main()
{
int i;
int datas[] = { 1, 11, 99, 55, 432, 578, 256, 782, 691, 206, 942, 387, 696, 374, 123, 55556, 888888888 };
int len = sizeof(datas) / sizeof(int);
int k = max(datas, len);
int size = get_digit_num(k);
radix_sort(datas, len, size);
printf("After radix sort the result is:\n");
for (i = 0; i<len; i++)
printf("%d ", datas[i]);
exit(0);
}
九、桶排序
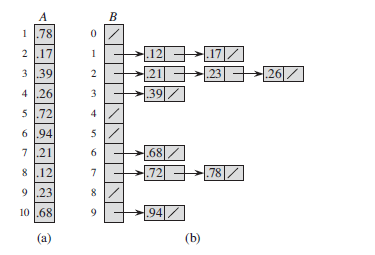
假设输入数组的元素都在[0,1)之间。
特性: out-place sort、stable sort 。
最坏情况运行时间:当分布不均匀时,全部元素都分到一个桶中,则O(n^2),当然[算法导论8.4-2]也可以将插入排序换成堆排序、快速排序等,这样最坏情况就是O(nlgn)。
最好情况运行时间:O(n)
桶排序的例子:
#include <iostream>
#include <vector>
#include <list>
#include <cstdlib>
using namespace std;
void bucket_sort(float *datas, size_t length)
{
int i, j;
int index;
float fvalue;
size_t lsize;
list<float> *retlist = new list<float>[length];
list<float>::iterator iter;
list<float>::iterator prioiter, enditer;
for (i = 0; i<length; ++i)
{
index = static_cast<int>(datas[i] * 10);
//insert a new element
retlist[index].push_back(datas[i]);
lsize = retlist[index].size();
if (lsize > 1)
{
//get the last element in the list[index]
iter = --retlist[index].end();
fvalue = *iter;
enditer = retlist[index].begin();
//insert the last element in right position
while (iter != enditer)
{
//get the second last element in the list[index]
prioiter = --iter;
//back up iter to the last element in the list[index]
iter++;
//compare two float values
if (*(prioiter)-*iter > 0.000001)
{
float temp = *(prioiter);
*(prioiter) = *iter;
*iter = temp;
}
iter--;
}
//the right inserted position
*(++iter) = fvalue;
}
}
//copy the result to datas
j = 0;
for (int i = 0; i<length; i++)
{
for (iter = retlist[i].begin(); iter != retlist[i].end(); ++iter)
datas[j++] = *iter;
}
delete[] retlist;
}
int main()
{
float datas[10] = { 0.78f, 0.17f, 0.39f, 0.76f, 0.23f, 0.67f, 0.48f, 0.58f, 0.92f, 0.12f };
bucket_sort(datas, 10);
cout << "after bucket_sort the result is:" << endl;
for (int i = 0; i<10; i++)
cout << datas[i] << " ";
cout << endl;
exit(0);
}









