线上故障通常是指大规模的影响线上服务可用性的问题或者事件,而对于线上故障的处理不仅是一项技术活,更是对技术人员/技术团队应急反应能力的考验。本文主要从线上故障的分类、应对思路、出现原因等方面入手,总结一些经验和问题解决方法,以求与各位同仁探讨交流。
一、在线故障分类
■ 意料之外的错误、无响应或响应缓慢
■ 服务中,影响用户体验
■ 不能停机或大面积停机
■ 需要尽快修复
二、应对思路
根据经验来分析,如果应急团队中有人对相应的问题有经验,并确定能够通过某种手段恢复系统的正常运行,那么应该第一时间恢复(回滚等),同时务必要保留现场,以备后续对问题的定位和修复;如果没有人有经验,则需要使用比较粗暴的办法保证服务可用,如定时重启、限流、降级等。
业务负责人、技术负责人、核心研发人员、架构师、运维工程师以及运营人员对问题的原因进行快速分析。分析的过程需要首先考虑系统近期的变化,包括以下几个方面:
■ 系统最近是否进行了发布上线工作?
■ 服务的使用方是否有运营活动?
■ 网络是否有流量的波动?
■ 最近的业务量是否上升?
■ 运营人员是否在系统中做了变动?
■ 依赖的基础平台和资源是否进行了发布上线?
■ 依赖的其他系统是否进行了发布上线?
三、可能的原因
■ 代码Bug:逻辑不严谨、连接未释放
■ 代码性能:循环外部调用、未使用批量读取、正则循环等
■ 内存泄漏:本地缓存
■ 异常流量:DDOS
■ 业务量提升:容量预估失误
■ 外部系统问题:数据库、搜索引擎、分布式缓存、消息队列等中间件的性能问题
CPU、内存、IO指标异常
四、三步走
■ 监控:“我并不知道我要做什么”。需要监控机制来发现、暴露系统的性能问题。这里一般依赖于系统级别或者业务级别的监控工具。
■ 分析:“我知道我要做什么”。需要计算机基础知识和分析工具。
■ 解决:“我知道我需要知道什么了”。系统、程序参数的调整、代码的重构优化。
理解一个系统应该如何工作并不能使人成为专家,只能靠调查系统为何不能正常工作才行。
1. 准备工作

 编辑
编辑
故障分析的准备工作、需要掌握的知识,based on CentOS 6.5 && JDK 1.8.0_121
■ 计算机基础知识:计算机网络、操作系统、计算机组成原理
■ Java内存管理:垃圾回收算法、垃圾回收器、关键GC参数、JVM内存模型等
■ Java代码基准性能测试:可以使用JMH(微基准测试框架)来进行,能够去除JIT热点代码编译对性能的影响
■ HotSpot虚拟机体系结构
■ 系统参数调优
■ 掌握系统常用诊断工具、JDK自带诊断工具以及其他诊断工具的使用
■ 了解业务系统:总体架构、压力方向、容量预估、系统相关软件的版本、模式以及参数
2. 常用系统诊断工具-CentOS自带
■ uptime:系统的运行时间、平均负荷,包括1分钟、5分钟、15分钟内可以运行的任务平均数量,包括正在运行的任务、虽然可以运行但正在等待某个处理器空闲以及阻塞在不可中断休眠状态的进程(等待IO,状态为D)的任务。
第一部分显示的是系统时间。左起第一条信息是22:36:32,这就是当前系统时间,以24小时格式输出。
第二部分显示的是系统运行时间。up 10 days,11:21,表示该机的系统已经运行了10天11小时21分钟。当系统重启后将会清零。
第三部分的信息是显示已登陆用户的数量。显示的是1 user ,即当前登录用户数量为1。
最后一个信息是系统的平均负载量。0.00,,0.05, 0.07分别代表着过去1分钟、5分钟、15分钟系统的平均负载量。负载量越低意味着系统性能越好。
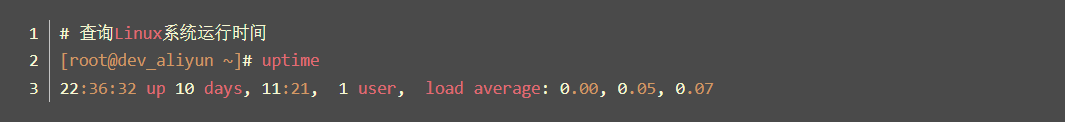
编辑
■ dmesg | tail:该命令会输出系统日志的最后10行。常见的OOM kill和TCP丢包在这里都会有记录。
■ free -m:该命令可以查看系统内存的使用情况,-m参数表示按照兆字节显示。Buffer和Cache都被计算在了used里面。真正反映内存使用状况的是第二行。如果可用内存较少,会使用swap区,增加IO开销,降低性能。

编辑
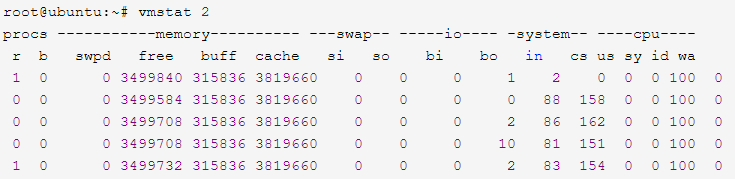
■ vmstat 1:实时性能检测工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率、内存使用、虚拟内存交换情况、IO读写情况等系统核心指标。r,等待CPU资源的进程数,这个比平均负载load更能体现CPU的繁忙状况;b,阻塞在不可中断休眠状态的进程数;si、so,swap区的使用情况,如果不为0说明已经开始使用swap区;us、sy、id、wa、st,CPU使用状况,id + us + sy = 100。
编辑
这表示vmstat每2秒采集数据,一直采集,直到结束程序。
■ top:包含了系统全局的很多指标信息,包括系统负载情况、系统内存使用情况、系统CPU使用情况等等,基本涵盖了上述几条命令的功能。
■ netstap -tanp:查看TCP网络连接状况。
iproute工具集:ss,ip,可以替代netstat
3. 常用系统诊断工具-Sysstat
■ mpstat -P ALL 1:该命令用来显示每个CPU的使用情况。如果有一个CPU占用率特别高,说明有可能是一个单线程应用程序引起的。
■ sar -n DEV 1:sar命令主要用来查看网络设备的吞吐率。可以通过网络设备的吞吐量,判断网络设备是否已经饱和。
■ sar -n TCP,ETCP 1:查看TCP连接状态。active/s,每秒主动发起的连接数目(connect);passive/s,每秒被动发起的连接数目(accept);retrans/s,每秒重传的数量,能够反映网络状况和是否发生了丢包。
■ iostat -xz 1:查看机器磁盘IO情况。await(ms),IO操作的平均等待时间,是应用程序在和磁盘交互时,需要消耗的时间,包括IO等待和实际操作的耗时;avgqu-s,向设备发出的平均请求数量;%util,设备利用率。
sar、iostat、mpstat、pidstat属于sysstat软件套件
4. JDK诊断工具
■ jstack:Java堆栈跟踪工具,主要用于打印指定Java进程的、核心文件或远程调试服务器的Java线程的堆栈跟踪信息。
■ jmap:Java内存映射工具(Java Memory Map),主要用于打印指定Java进程、核心文件或远程调试服务器的共享对象内存映射或堆内存细节。
■ jhat:Java堆分析工具(Java Heep Analysis Tool),用于分析Java堆内存中的对象信息。
■ jinfo:Java配置信息工具(Java Configuration Information),用于打印指定Java进程、核心文件或远程调试服务器的配置信息,也可以动态修改JVM参数配置。
■ jstat:JVM统计检测工具(Java Statistics Monitoring Tool),主要用于监测并显示JVM的性能统计信息,包括gc统计信息。
■ jcmd:Java命令行(Java Command),用于向正在运行的JVM发送诊断命令请求。由于jmap官方标注的是unsupported,jcmd可以作为其替代工具。
■ visualvm:通过JMX接口连接JVM进程,从而能够看到JVM上的线程、内存、类等信息。可以安装各种插件。(通过CATALINA_OPTS开启Tomcat jmx接口)
■ jconsole:功能类似于visualvmv,可以显示具体的线程堆栈信息以及内存中各个年代的占用情况,并支持直接远程执行MBEAN。
5. 其他工具
■ jmc:Java Mission Control,是一款采样型的集诊断、分析和监控于一体的非常强大的工具。由于收费的原因,用的不是太多。
■ greys-atonomy:在线诊断工具,通过动态修改字节码能够达到无须重启JVM添加日志、监测方法耗时等动态增强代码的目的。
■ arthas:阿里开源的Java诊断工具箱,基于greys-atonomy而来,包括在线诊断、反编译字节码、查看最耗费资源的Java线程等。
■ jwebap:JavaEE性能检测框架,基于ASM增强字节码实现。支持:HTTP请求、JDBC连接、method的调用轨迹跟踪以及次数、耗时的统计。二次开发的suishen-webap,加入了对Java8的支持以及Redis连接的监控。
■ awesome-scripts:封装了很多常用诊断工具、脚本等,包括greys-atonomy、sjk、VJTools以及获取最耗资源的线程堆栈信息、统计TCP连接数目等脚本。(未完待续)










