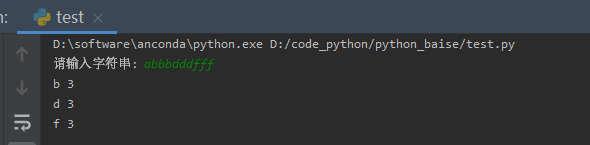
1、【问题描述】
输入字符串,输出字符串中出现次数最多的字母及其出现次数。如果有多个字母出现次数一样,则按字符从小到大顺序输出字母及其出现次数。
【输入形式】
一个字符串。
【输出形式】
出现次数最多的字母及其出现次数
【样例输入】
abcccd
【样例输出】
c 3
代码实现:
str=input('请输入字符串:')
a=set(str) #set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
count={}
#遍历集合a
for i in a:
count[i]=str.count(i) #count()函数统计字符串str中的各个字符出现的次数。
#统计字典中最大的values
max1 = max(count.values())
# items()函数以列表返回可遍历的(键, 值)元组数组
data = list(count.items())
# 将元组以字母顺序对列表进行排序:
data.sort()
# 判断元组values是否等于最大值,满足则输出对应字母字符及出现次数
for i in data:
if i[1] == max1:
print(i[0], i[1])
结果:

P2【问题描述】
定义一个电话簿,里头设置以下联系人:
'mayun':'13309283335',
'zhaolong':'18989227822',
'zhangmin':'13382398921',
'Gorge':'19833824743',
'Jordan':'18807317878',
'Curry':'15093488129',
'Wade':'19282937665'
现在输入人名,查询他的号码。
【输入形式】
人名,是一个字符串。
【输出形式】
电话号码。如果该人不存在,返回"not found"
【样例输入】
mayun
【样例输出】
13309283335
代码实现:
address_list={'mayun':'13309283335',
'zhaolong':'18989227822',
'zhangmin':'13382398921',
'Gorge':'19833824743',
'Jordan':'18807317878',
'Curry':'15093488129',
'Wade':'19282937665'}
while True:
name=input('请输入名字:')
if name in address_list.keys():
print(address_list[name])
else:
print('not found')结果:

P3 【问题描述】
先输入多个英文单词及其译文,接着输入英文单词,输出该单词的译文。
【输入形式】
第一行是整数n,表示n个英文单词及其译文。
接下来输入n行是英文单词和译文,中间用空格隔开。
接下来输入的一行是一个英文单词。
【输出形式】
输出最后输入的英文单词的译文。如果没有检索到该单词,输出"not found"。
【样例输入】
3
word zi
go qu
input shuru
go
【样例输出】
qu
【样例说明】
qu是go单词的译文。
代码实现:
num = input("请输入一个整数n:")
Eng2CH = {} #创建一个字典
for i in range(int(num)):
str = input("输入多个英文单词及其译文:") #输入单词
sList = str.split(' ') #split() 通过指定分隔符对字符串进行切片
Eng2CH[sList[0]] = sList[-1]
word = input("请输入待查找的单词:")
if word.strip(' ') in Eng2CH:
print(Eng2CH[word.strip(' ')])
else:
print("not found")结果:

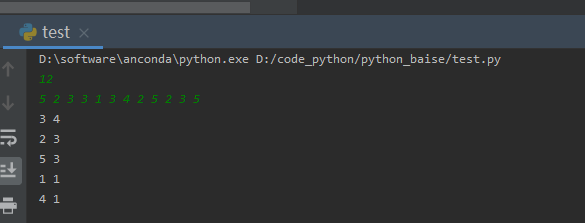
4、【问题描述】
给定n个整数,请统计出每个整数出现的次数,按出现次数从多到少的顺序输出。
【输入形式】
第一行包含一个整数n,表示给定数字的个数; 第二行包含n个整数,相邻的整数之间用一个空格分隔,表示所给定的整数。
【输出形式】
输出有多行,每行包含两个整数,分别表示一个给定的整数和它出现的次数。按出现次数递减的顺序输出。如果两个整数出现的次数一样多,则先输出值较小的,然后输出值较大的。
【样例输入】
12
5 2 3 3 1 3 4 2 5 2 3 5
【样例输出】
3 4
2 3
5 3
1 1
4 1
【样例说明】
n不超过1000,给出的数为2,000,000,000以内的非负整数。
代码实现
n = eval(input())
s = input().split(" ") #split() 指定分隔符对输入的字符串进行切片
s.sort() # 1.将所有数字升序排序
dit = {} # 创建一个字典
for x in s: # 2.统计数字出现的次数
dit[x] = dit.get(x, 0) + 1 #get() 函数返回指定键的值 返回指定键的值,如果键不在字典中返回默认值 None 或者设置的默认值。
# 3.按照字典的值降序排列
dit1 = dict(sorted(dit.items(), key=lambda x: x[1], reverse=True)) # dict() 函数用于创建一个字典。items() 函数以列表返回可遍历的(键, 值) 元组数组。
for key in dit1:
print(key, dit1[key])结果:
5、【问题描述】
学习了字典之后,同学们都想学以致用创建一个自己的通信录。小明是这么做的:
(1)先根据三位舍友的联系方式创建一个字典dicTXL。
(2)然后将隔壁舍长已经建好的字典dicOther合并进了自己的通信录。
(3)合并之后,小明又打算给通信录增加一列“微信号”,为此他询问了相关同学的微信号并存储在了字典dicWX中,然后合并进入自己的通信录,而没有询问到微信号的同学都默认微信号为其手机号。
请按照小明的步骤完成通信录dicTXL的创建,并测试如下功能:
(1)将“大王”的手机号更改为13914000004。
(2)输入姓名查找对应同学的手机号、QQ号和微信号,如果输入的姓名不存在,则返回“没有该同学的联系方式”。
【输入形式】
使用input()函数获取用户输入的姓名。
【输出形式】
使用print()函数输出对应的手机号、QQ号和微信号。
【样例输入】
小刚
【样例输出】
13913000003
18191220003
gang1004
代码实现:
#字典diicTXL和dicOther分别存储小明的通讯录和舍友通讯录信息,通信录中包括姓名、手机号和QQ号信息
dicTXL={'小新':['13913000001','18181220001'],
'小亮':['13913000002','18191220002'],
'小刚':['13913000003','18191220003']}
dicOther={'大刘':['13914000001','18191230001'],
'大王':['13914000002','18191230002'],
'大张':['13914000003','18191230003']}
#将字典dicOther合并到字典dicTXL中
dicTXL = dict(dicTXL, **dicOther)
print(dicTXL)
#dicWX字典存储同学的微信号
dicWX={'小新':'xx9907',
'小刚':'gang1004',
'大王':'jack_w',
'大刘':'liu666'}
#将微信号添加至字典dicTXL中
for dicTXL_k,dicTXL_v in dicTXL.items():
if dicTXL_k in dicWX:
#dicTXL.update(dicWX)
dicTXL_v.append(dicWX[dicTXL_k])
else:
dicTXL_v.append(dicTXL_v[0])
print(dicTXL)
结果:

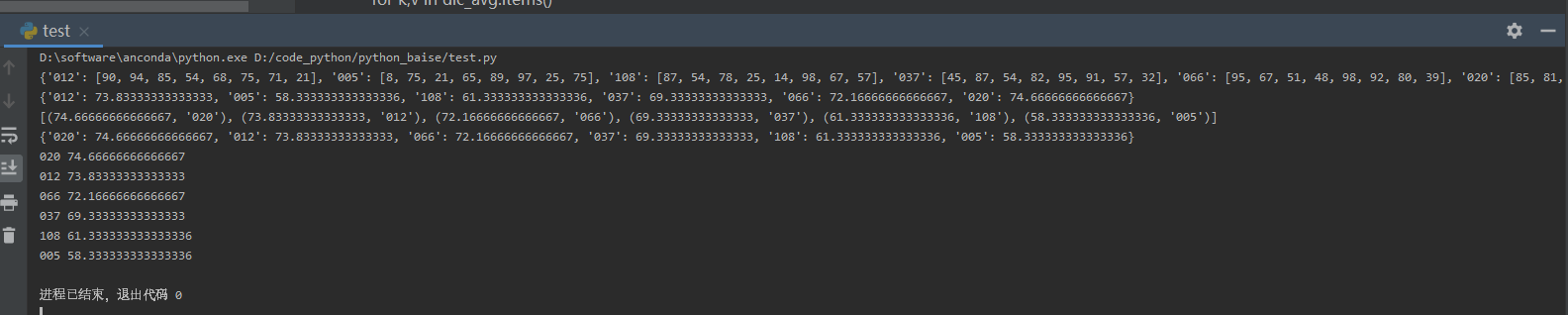
6、【问题描述】
一年一度的校园好声音进行到了激烈的决赛环节,8位评委对入围的6名选手给出了最终的评分,请根据评分表,将每位选手的得分去掉一个最高分和一个最低分后求平均分,并按照平均分由高到低的顺序输出选手编号和最后得分。
代码实现:
dic_score={ '012':[90,94,85,54,68,75,71,21],
'005':[8,75,21,65,89,97,25,75],
'108':[87,54,78,25,14,98,67,57],
'037':[45,87,54,82,95,91,57,32],
'066':[95,67,51,48,98,92,80,39],
'020':[85,81,65,97,35,62,71,84]}
print(dic_score)
dic_avg={} #存放平均分
for k,v in dic_score.items():
v_min= min(v) # 求最低分
v_max = max(v) # 求最高分
v_sum = sum(v) # 求总分
v_sum = v_sum - v_max - v_min # 从总分中去除最大值和最小值
v_avg = v_sum / (len(v) - 2) # 求平均分
dic_avg[k]=v_avg # 将参赛者编号和平均值存入字典dic_avg中
print(dic_avg)
#按照平均分由大到小排序
lt_avg=[(v,k) for k,v in dic_avg.items()]
lt_avg.sort(reverse=True)
print(lt_avg)
lt_avg=[(v,k) for k,v in lt_avg]
dic_avg=dict(lt_avg)
print(dic_avg)
#输出结果
for k,v in dic_avg.items():
print(k,v)结果: