网卡收包
- 内核网络模块如何初始化?
- 内核如何通过网卡驱动收发数据包?
- 驱动收到的数据怎么交给协议栈处理?
一,框架
网络子系统中,在本文中我们关注的是驱动和内核的交互。也就是网卡收到数据包后怎么交给内核,内核收到数据包后怎么交给协议栈处理。
在内核中,网卡设备是被net_device结构体描述的。驱动需要通过net_device向内核注册一组操作网卡硬件的函数,这样内核便可以使用网卡了。而所有的数据包在内核空间都是使用sk_buff结构体来表示,所以将网卡硬件收到的数据转换成内核认可的skb_buff也是驱动的工作。
在这之后,还有两个结构体也发挥了非常重要的作用。一个是为struct softnet_data,另一个是struct napi_struct。为软中断的方式处理数据包提供了支持。盗图一张:
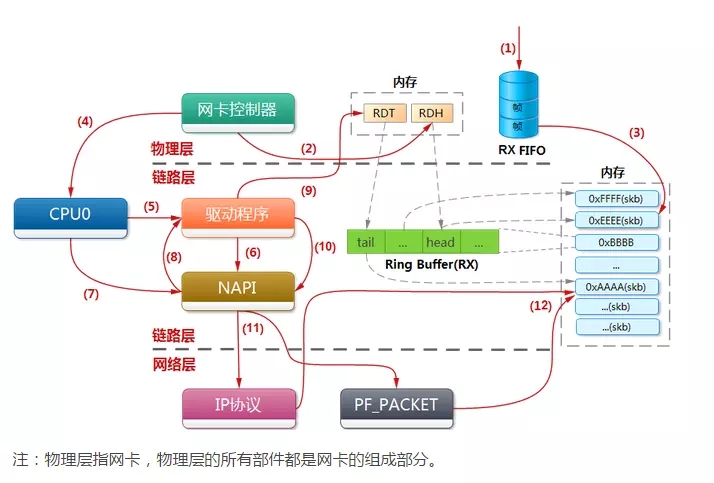
二,初始化
一切的起源都是上电那一刻,当系统初始化完毕后,我们的系统就应该是可用的了。网络子模块的初始化也是在Linux启动经历两阶段的混沌boost自举后,进入的第一个C函数start_kernel。在这之前是Bootloader和Linux的故事,在这之后,便是Linux的单人秀了。
网络子设备初始化调用链:start_kernel->rest_init->kernel_init->kernel_init_freeable->do_basic_setup->do_initcalls->do_initcalls->net_dev_init。
上面调用关系中的kernel_init是一个内核子线程中调用的:
pid = kernel_thread(kernel_init, NULL, CLONE_FS);
然后再一个问题就是当进入do_initcalls后我们会发现画风突变:
static void __init do_initcalls(void)
{
int level;
for (level = 0; level < ARRAY_SIZE(initcall_levels) - 1; level++)
do_initcall_level(level);
}
我是谁,我来自哪,我要到哪去。
如果do_initcalls还给了我们一丝看下去的希望,点开do_initcall_level可能就真的绝望了。
static void __init do_initcall_level(int level)
{
initcall_t *fn;
strcpy(initcall_command_line, saved_command_line);
parse_args(initcall_level_names[level],
initcall_command_line, __start___param,
__stop___param - __start___param,
level, level,
NULL, &repair_env_string);
trace_initcall_level(initcall_level_names[level]);
for (fn = initcall_levels[level]; fn < initcall_levels[level+1]; fn++)
do_one_initcall(*fn);
}
全局一个fn指针,实现调用全靠猜。反正我不管,我说调用了net_dev_init就是调用了。伟大的google告诉我只要被下面这些宏定义包裹的函数就会被do_one_initcall调用,用了什么黑科技,先不管:
#file:include/linux/init.h
#define pure_initcall(fn) __define_initcall(fn, 0)
#define core_initcall(fn) __define_initcall(fn, 1)
#define core_initcall_sync(fn) __define_initcall(fn, 1s)
#define postcore_initcall(fn) __define_initcall(fn, 2)
#define postcore_initcall_sync(fn) __define_initcall(fn, 2s)
#define arch_initcall(fn) __define_initcall(fn, 3)
#define arch_initcall_sync(fn) __define_initcall(fn, 3s)
#define subsys_initcall(fn) __define_initcall(fn, 4)
#define subsys_initcall_sync(fn) __define_initcall(fn, 4s)
#define fs_initcall(fn) __define_initcall(fn, 5)
#define fs_initcall_sync(fn) __define_initcall(fn, 5s)
#define rootfs_initcall(fn) __define_initcall(fn, rootfs)
#define device_initcall(fn) __define_initcall(fn, 6)
#define device_initcall_sync(fn) __define_initcall(fn, 6s)
#define late_initcall(fn) __define_initcall(fn, 7)
#define late_initcall_sync(fn) __define_initcall(fn, 7s)
在net_dev_init的定义下面,我们可以找到subsys_initcall(net_dev_init);。Ok,网络子系统的初始化入口已找到到。
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
BUG_ON(!dev_boot_phase);
if (dev_proc_init())
goto out;
if (netdev_kobject_init())
goto out;
INIT_LIST_HEAD(&ptype_all);
for (i = 0; i < PTYPE_HASH_SIZE; i++)
INIT_LIST_HEAD(&ptype_base[i]);
INIT_LIST_HEAD(&offload_base);
if (register_pernet_subsys(&netdev_net_ops))
goto out;
/*
* Initialise the packet receive queues.
*/
for_each_possible_cpu(i) {
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i);
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
#ifdef CONFIG_XFRM_OFFLOAD
skb_queue_head_init(&sd->xfrm_backlog);
#endif
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->cpu = i;
#endif
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
}
dev_boot_phase = 0;
/* The loopback device is special if any other network devices
* is present in a network namespace the loopback device must
* be present. Since we now dynamically allocate and free the
* loopback device ensure this invariant is maintained by
* keeping the loopback device as the first device on the
* list of network devices. Ensuring the loopback devices
* is the first device that appears and the last network device
* that disappears.
*/
if (register_pernet_device(&loopback_net_ops))
goto out;
if (register_pernet_device(&default_device_ops))
goto out;
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
rc = cpuhp_setup_state_nocalls(CPUHP_NET_DEV_DEAD, "net/dev:dead",
NULL, dev_cpu_dead);
WARN_ON(rc < 0);
rc = 0;
out:
return rc;
}
在net_dev_init中,初始化了内核收发包队列,开启了对应的软中断NET_TX_SOFTIRQ和NET_RX_SOFTIRQ。在其中,该函数为每个CPU初始化了一个softnet_data来挂载需要处理设备的napi_struct。这个结构非常重要,软中断的处理就是从这个链表上取napi_struct,然后收包的。这也是内核和驱动的接口之一。
再就是开启的两个软中断,当驱动在硬终端完成必要的上半部工作后,就会拉起对应的软中断。让数据包下半部软中断中处理。
net_dev_init执行完后,我们内核就有了处理数据包的能力,只要驱动能向softnet_data挂载需要收包设备的napi_struct。内核子线程ksoftirqd便会做后续的处理。接下来就是网卡驱动的初始化了。
各种网卡肯定有不同的驱动,各驱动封装各自硬件的差异,给内核提供一个统一的接口。我们这不关心,网卡驱动是怎么把数据发出去的,如何收回来的。而是探究网卡收到数据了,要怎么交给内核,内核如何将要发的数据给网卡。总之,驱动需要给内核提供哪些接口,内核又需要给网卡哪些支持。我们以e1000网卡为例子。看看它和内核的缠绵故事。
e1000网卡是一块PCI设备。所以它首先得要让内核能通过PCI总线探测到,需要向内核注册一个pci_driver结构,PCI设备的使用是另一个话题,这里不会探究,我也不知道:
static struct pci_driver e1000_driver = {
.name = e1000_driver_name,
.id_table = e1000_pci_tbl,
.probe = e1000_probe,
.remove = e1000_remove,
#ifdef CONFIG_PM
/* Power Management Hooks */
.suspend = e1000_suspend,
.resume = e1000_resume,
#endif
.shutdown = e1000_shutdown,
.err_handler = &e1000_err_handler
};
其中e1000_probe就是给内核的探测回调函数,算是网卡的初始化函数吧,驱动需要在这里初始化网卡设备。去掉总线相关的代码,错误处理的代码,硬件相关的代码:
static int e1000_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
{
struct net_device *netdev;
netdev = alloc_etherdev(sizeof(struct e1000_adapter));//申请net_device设备
netdev->netdev_ops = &e1000_netdev_ops; //注册操作设备的回调函数
e1000_set_ethtool_ops(netdev);
netdev->watchdog_timeo = 5 * HZ;
netif_napi_add(netdev, &adapter->napi, e1000_clean, 64);//软中断里会调用poll钩子函数
strncpy(netdev->name, pci_name(pdev), sizeof(netdev->name) - 1);
err = register_netdev(netdev);
}
每一个网络设备都有一个对应的net_devie结构体来描述。其中像设备文件操作一样,保存了一种操作设备的接口函数netdev_ops,对e1000网卡是e1000_netdev_ops。当通过终端输入ifup,ifdowm命令操作网卡时,对应的open,close函数就会被调用。这段代码最重要的还是netif_napi_add的调用,它向内核注册了e1000_clean函数,用来给上面的CPU收包队列调用。
通过初始化,驱动注册了网卡描述net_device, 内核可以通过它操作到网卡设备。通过e1000_clean函数内核软中断也可以收包了。
三,驱动收包
前面有一个内核软中断来收包,但这个软中断怎么触发呢?硬中断。当有数据到网卡时,会产生一个硬中断。这中断的注册是上面,e1000_netdev_ops中的e1000_up函数调用的。也就是网卡up时会注册这个硬中断处理函数e1000_intr。
/**
* e1000_intr - Interrupt Handler
* @irq: interrupt number
* @data: pointer to a network interface device structure
**/
static irqreturn_t e1000_intr(int irq, void *data)
{
struct net_device *netdev = data;
struct e1000_adapter *adapter = netdev_priv(netdev);
struct e1000_hw *hw = &adapter->hw;
u32 icr = er32(ICR);
/* disable interrupts, without the synchronize_irq bit */
ew32(IMC, ~0);
E1000_WRITE_FLUSH();
if (likely(napi_schedule_prep(&adapter->napi))) {
adapter->total_tx_bytes = 0;
adapter->total_tx_packets = 0;
adapter->total_rx_bytes = 0;
adapter->total_rx_packets = 0;
__napi_schedule(&adapter->napi);
} else {
/* this really should not happen! if it does it is basically a
* bug, but not a hard error, so enable ints and continue
*/
if (!test_bit(__E1000_DOWN, &adapter->flags))
e1000_irq_enable(adapter);
}
return IRQ_HANDLED;
}
去掉unlikely的代码,其中通过if (likely(napi_schedule_prep(&adapter->napi)))测试,网卡设备自己的napi是否正在被CPU使用。没有就调用__napi_schedule将自己的napi挂载到CPU的softnet_data上。这样软中断的内核线程就能轮询到这个软中断。
/**
* __napi_schedule - schedule for receive
* @n: entry to schedule
*
* The entry's receive function will be scheduled to run.
* Consider using __napi_schedule_irqoff() if hard irqs are masked.
*/
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
____napi_schedule(this_cpu_ptr(&softnet_data), n);
local_irq_restore(flags);
}
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ); //设置软中断标志位NET_RX_SOFTIRQ
}
这里的softnet_data就是前面net_dev_init函数为每个CPU初始化的。到这里硬件中断就处理完了,但我们依然没有发现任何有关数据包的处理,只知道了有一个napi被挂载。这是因为硬件中断不能显然太长,的确不会去做数据的处理工作。这些都交给软中断的内核线程来处理的。
四,内核处理
硬中断将一个napi结构体甩给了内核,内核要怎么根据它来接收数据呢?前面说到,内核为每个CPU核心都运行了一个内核线程ksoftirqd。软中断也就是在这线程中处理的。上面的硬件中断函数设置了NET_RX_SOFTIRQ软中断标志,这个字段处理函数还记得在哪注册的么?是的,net_dev_init中。
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
显然,后续处理肯定是由net_rx_action来完成。
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies +
usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll); //在这回调驱动的poll函数,这个函数在napi中
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 ||
time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}
上面看到budget -= napi_poll(n, &repoll);他会去调用我们驱动初始化时注册的poll函数,在e1000网卡中就是e1000_clean函数。
/**
* e1000_clean - NAPI Rx polling callback
* @adapter: board private structure
**/
static int e1000_clean(struct napi_struct *napi, int budget)
{
struct e1000_adapter *adapter = container_of(napi, struct e1000_adapter,
napi);
int tx_clean_complete = 0, work_done = 0;
tx_clean_complete = e1000_clean_tx_irq(adapter, &adapter->tx_ring[0]);
adapter->clean_rx(adapter, &adapter->rx_ring[0], &work_done, budget);//将数据发给协议栈来处理。
if (!tx_clean_complete)
work_done = budget;
/* If budget not fully consumed, exit the polling mode */
if (work_done < budget) {
if (likely(adapter->itr_setting & 3))
e1000_set_itr(adapter);
napi_complete_done(napi, work_done);
if (!test_bit(__E1000_DOWN, &adapter->flags))
e1000_irq_enable(adapter);
}
return work_done;
}
e1000_clean函数通过调用clean_rx函数指针来处理数据包。
/**
* e1000_clean_jumbo_rx_irq - Send received data up the network stack; legacy
* @adapter: board private structure
* @rx_ring: ring to clean
* @work_done: amount of napi work completed this call
* @work_to_do: max amount of work allowed for this call to do
*
* the return value indicates whether actual cleaning was done, there
* is no guarantee that everything was cleaned
*/
static bool e1000_clean_jumbo_rx_irq(struct e1000_adapter *adapter,
struct e1000_rx_ring *rx_ring,
int *work_done, int work_to_do)
{
struct net_device *netdev = adapter->netdev;
struct pci_dev *pdev = adapter->pdev;
struct e1000_rx_desc *rx_desc, *next_rxd;
struct e1000_rx_buffer *buffer_info, *next_buffer;
u32 length;
unsigned int i;
int cleaned_count = 0;
bool cleaned = false;
unsigned int total_rx_bytes = 0, total_rx_packets = 0;
i = rx_ring->next_to_clean;
rx_desc = E1000_RX_DESC(*rx_ring, i);
buffer_info = &rx_ring->buffer_info[i];
e1000_receive_skb(adapter, status, rx_desc->special, skb);
napi_gro_frags(&adapter->napi);
return cleaned;
}
/**
* e1000_receive_skb - helper function to handle rx indications
* @adapter: board private structure
* @status: descriptor status field as written by hardware
* @vlan: descriptor vlan field as written by hardware (no le/be conversion)
* @skb: pointer to sk_buff to be indicated to stack
*/
static void e1000_receive_skb(struct e1000_adapter *adapter, u8 status,
__le16 vlan, struct sk_buff *skb)
{
skb->protocol = eth_type_trans(skb, adapter->netdev);
if (status & E1000_RXD_STAT_VP) {
u16 vid = le16_to_cpu(vlan) & E1000_RXD_SPC_VLAN_MASK;
__vlan_hwaccel_put_tag(skb, htons(ETH_P_8021Q), vid);
}
napi_gro_receive(&adapter->napi, skb);
}
这个函数太长,我就保留了e1000_receive_skb函数的调用,它调用了napi_gro_receive,这个函数同样是NAPI提供的函数,我们的skb从这里调用到netif_receive_skb协议栈的入口函数。调用路径是napi_gro_receive->napi_frags_finish->netif_receive_skb_internal->__netif_receive_skb。具体的流程先放放。毕竟NAPI是内核为了提高网卡收包性能而设计的一套框架。这就可以让我先挖个坑以后在分析NAPI的时候在填上。总之有了NAPI后的收包流程和之前的区别如图:
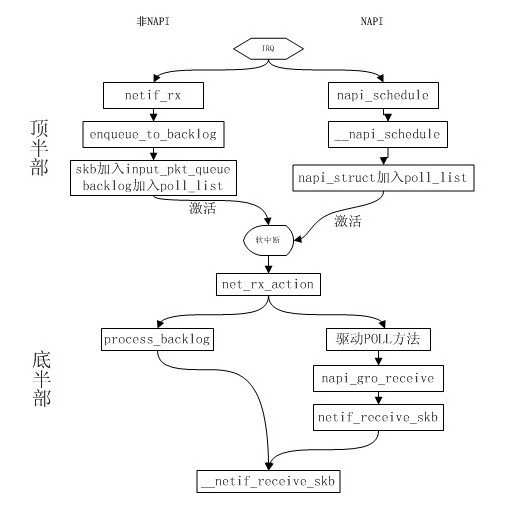
到这里,网卡驱动到协议栈入口的处理过程就写完了。










