
第十四章 冒泡排序法
::: hljs-center
目录
第十四章 冒泡排序法
●前言
●认识排序
●一、冒泡排序是什么?
1.简要介绍
2.具体情况
3.算法分析
●二、案例实现
1.案例一
2.案例二
●总结
:::
前言
排序算法是我们在程序设计中经常见到和使用的一种算法,它主要是将一堆不规则的数据按照递增或递减的方式重新进行排序。在如今的互联网信息时代,随着大数据和人工智能的发展,大型企业的数据库中有亿级的用户数据量。因此对其进行处理,排序算法也就成为了其中必不可缺的步骤之一。
认识排序
排序功能对计算机领域而言,是一项非常重要而且普遍的工作。排序中数据的移动方式可分为直接移动和逻辑移动两种方式,直接移动是直接交换存储数据的位置,而逻辑移动并不会移动数据存储的位置,仅改变指向这些数据辅助指针的值。排序通常按照数据量的多少和所使用的内存,可分为内部排序和外部排序,数据量小可以全部加载到内存来进行排序的,就称为内部排序,大部分排序属于此类。数据量大而无法一次性加载到内存中,必须借助磁带,磁盘等辅助存储器进行排序的,则称为外部排序。随着数据结构科学的进步,如今,陆续被提出的冒泡排序法,选择排序法,插入排序法,合并排序法,快速排序法,堆积排序法,希尔排序法,基数排序法,直接合并排序法等等,它们各有其特色和其应用场合。并且在算法中,我们非常关注算法程序代码的时间复杂度和空间复杂度,因为它会直接体现出我们程序代码的执行效率以及编程人员的逻辑思维等等的综合能力。当数据量相当庞大时,排序算法所花费的时间就显得相当重要,排序算法的时间复杂度可分为最好情况、最坏情况以及平均情况。另外,对于任何的排序算法都会有数据交换的操作,数据互换位置会暂时用到一个额外的空间,这也是排序算法中空间复杂度要考虑到的问题,而在排序算法中所使用的额外空间越小,它的空间复杂度就越好。
一、冒泡排序是什么?
1.简要介绍
冒泡排序法又被称为交换排序法,它的原理思维是从第一个元素开始,比较相邻元素的大小,如果大小顺序有误,则将其交换位置后继续进行与下一个元素的比较。如此经过这样的一次扫描操作之后就可以确保最后一个元素被排到了正确的位置上。接着继续进行下一次的扫描操作,直到完成所有的元素排序即可。
2.具体情况
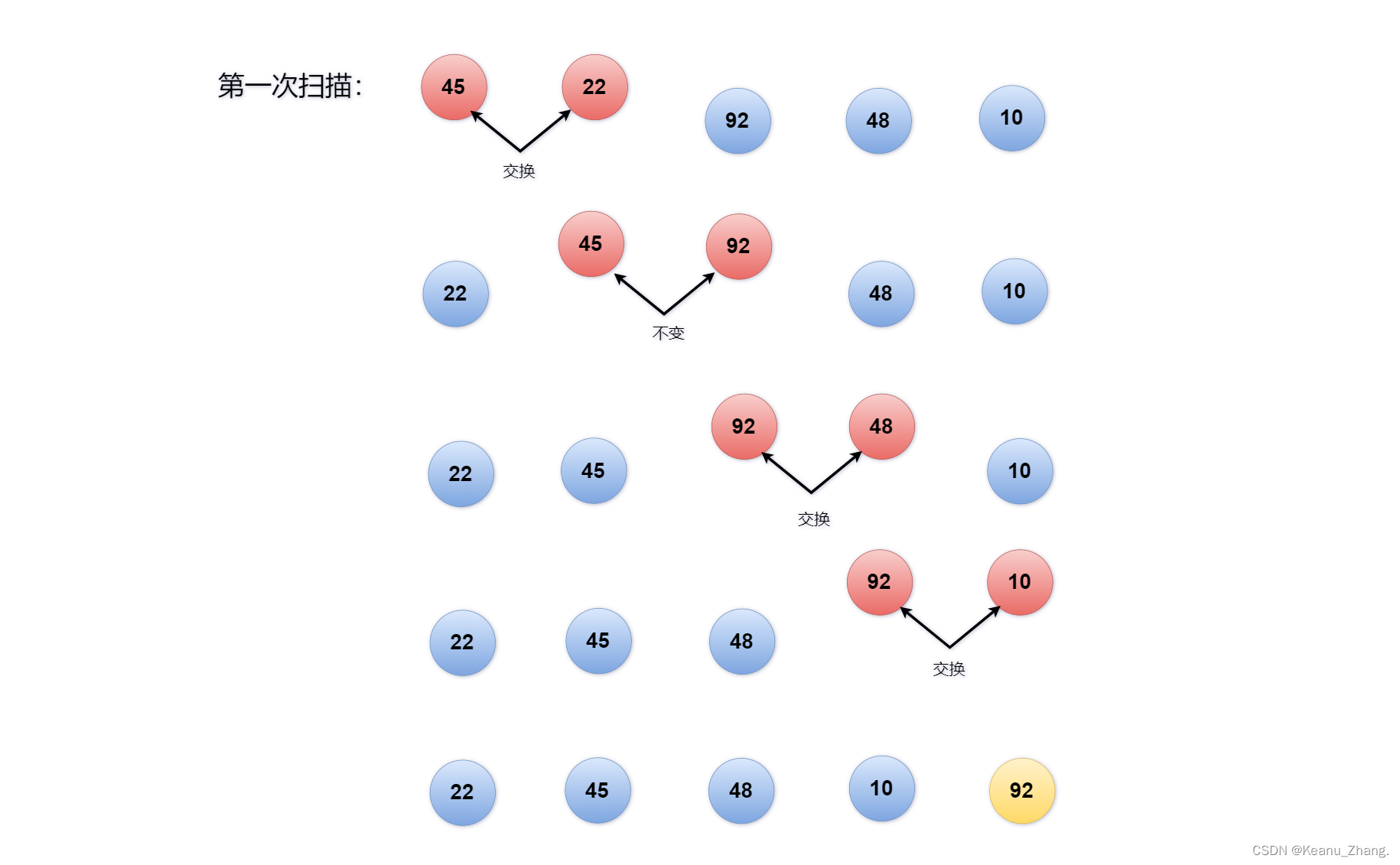
通过冒泡排序法,对下图的5个数据元素进行从小到大排序:
 第一次的扫描,将第一个元素45和第二个元素22进行比较,第二个元素小于第一个元素,我们就将两者进行互换;然后将交换后的第二个元素45与第三个元素92进行比较判断,两者不需要交换位置;就这样一直进行比较判断,到第四次就可以确定该组数据的最大值已经排到了这几个数据的最后面。
第一次的扫描,将第一个元素45和第二个元素22进行比较,第二个元素小于第一个元素,我们就将两者进行互换;然后将交换后的第二个元素45与第三个元素92进行比较判断,两者不需要交换位置;就这样一直进行比较判断,到第四次就可以确定该组数据的最大值已经排到了这几个数据的最后面。
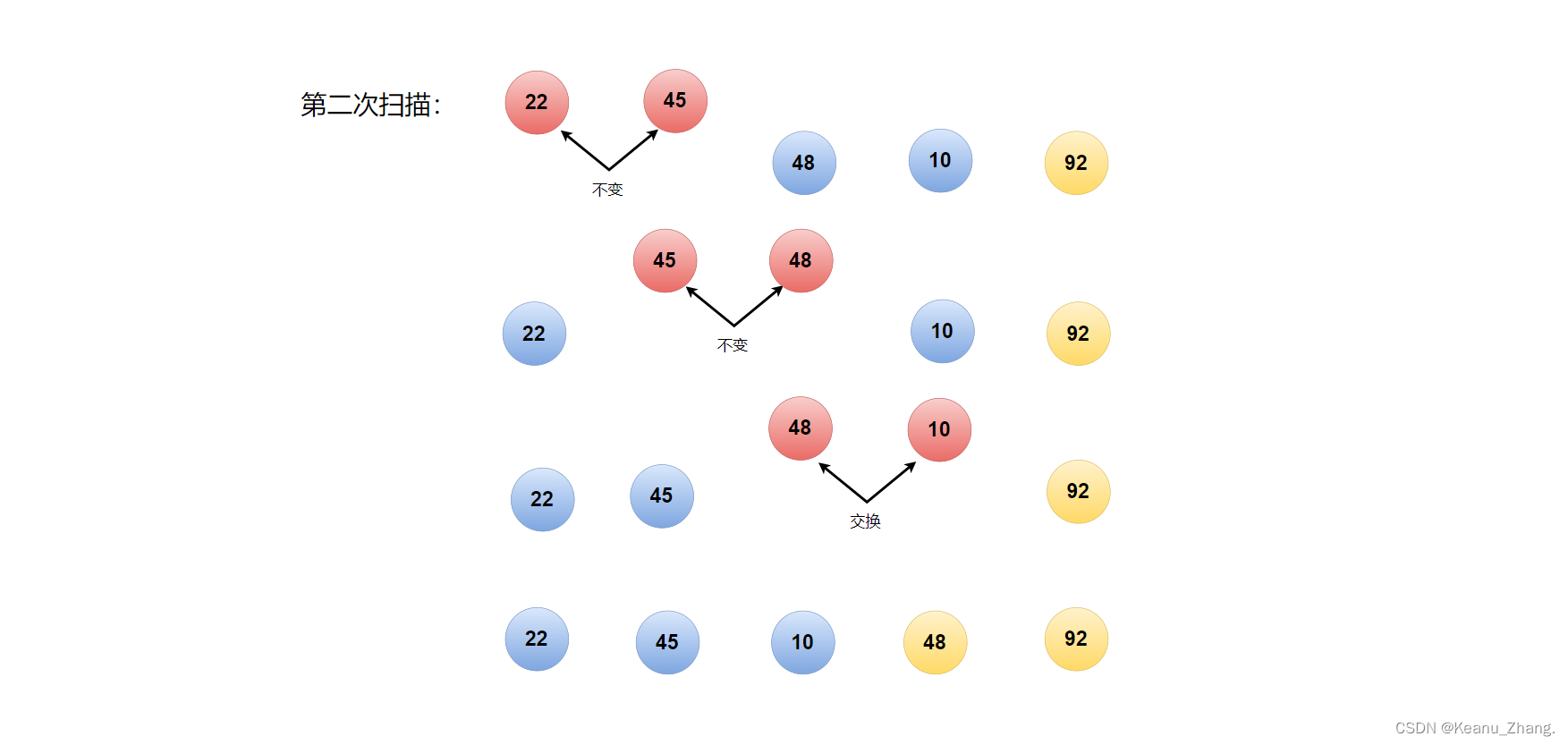
 第二次的扫描也是从头开始继续进行相邻比较,但因为在第一次的扫描时我们就已经将5个数据元素中的最大值确定了出来,所以这次扫描我们只需要比较3次就可以将剩余元素的最大值排到剩余数据元素的最后面。
第二次的扫描也是从头开始继续进行相邻比较,但因为在第一次的扫描时我们就已经将5个数据元素中的最大值确定了出来,所以这次扫描我们只需要比较3次就可以将剩余元素的最大值排到剩余数据元素的最后面。
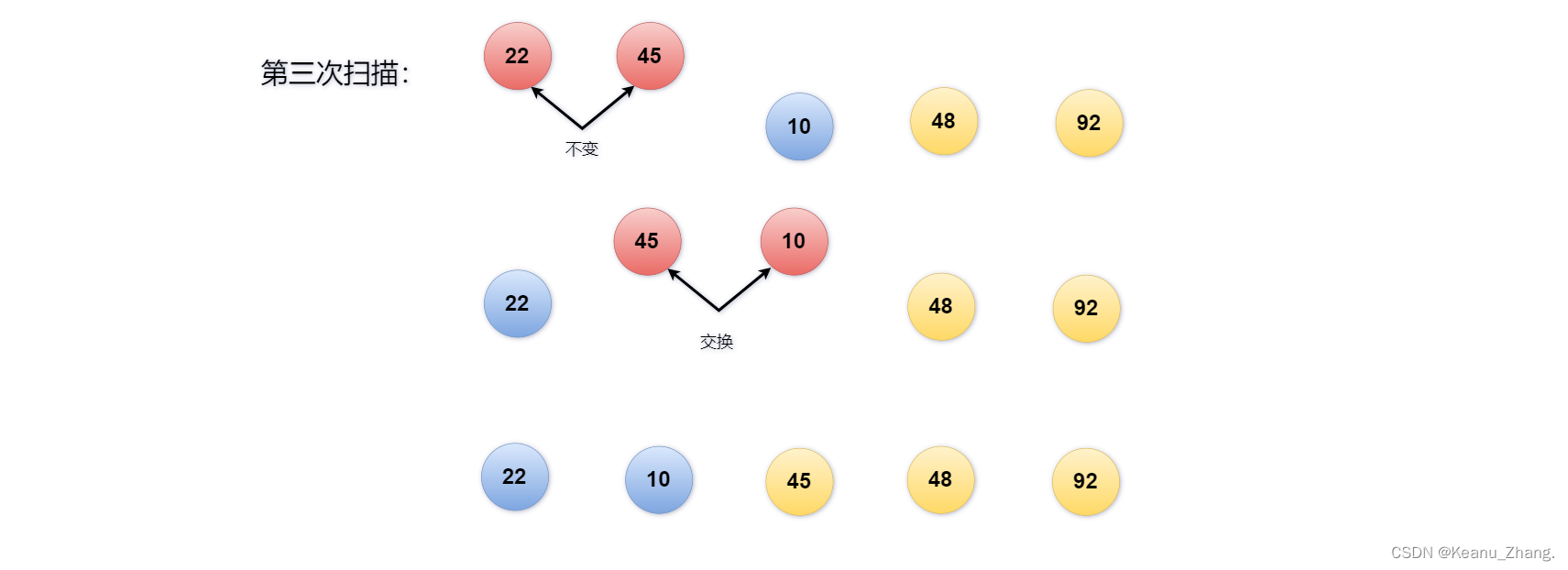
 第三次的扫描需要比较两次:
第三次的扫描需要比较两次:
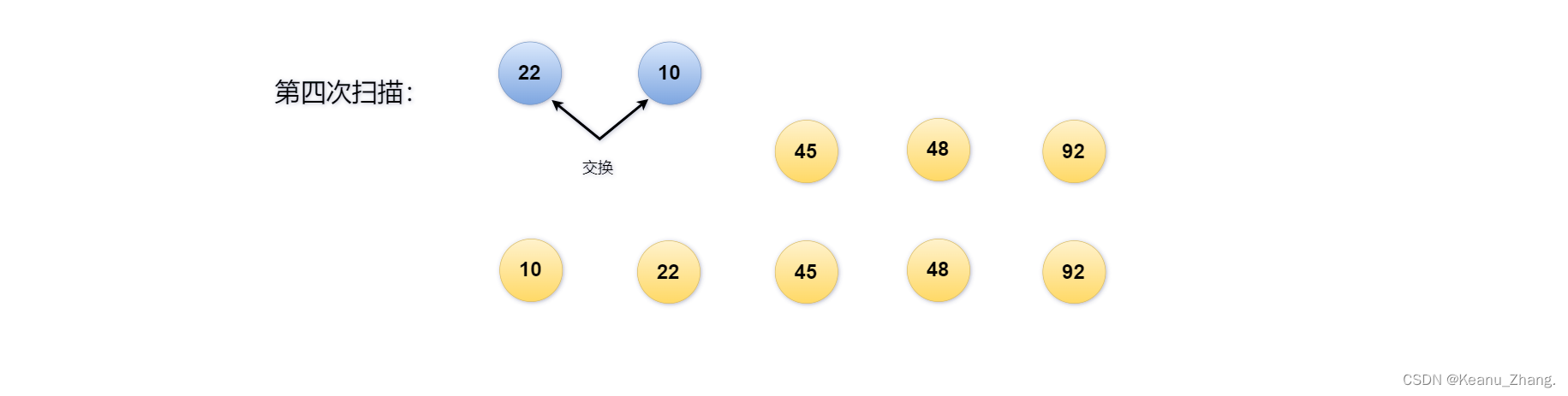
 第四次的扫描需要比较一次,即可完成5个数据元素的全部排序:
第四次的扫描需要比较一次,即可完成5个数据元素的全部排序:
3.算法分析
n个元素的冒泡排序法需要执行n-1次扫描排序操作: ①冒泡排序法为相邻两个数据元素进行比较判断后的排序方法,因此它不会改变原来数据排列的顺序,属于稳定排序法。 ②冒泡排序法只需要一个额外的空间,空间复杂度为最佳的。 ③冒泡排序法适用于数据量小的情况。 ④该排序方法最好的情况就是只需要进行一次扫描,这一次的扫描发现不需要对该组数据进行排序的操作,表示排序已经完成,所以只会进行n-1次的比较,时间复杂度为O(n);而最坏的情况和平均情况下的时间复杂度均为O(n^2)。
二、案例实现
1.案例一
①范例情况:使用冒泡排序法对6、5、9、7、2、8这几个数据进行排序,并且输出每次扫描后的排序情况。 ②代码展示:
#include<iostream>
#include<iomanip>
using namespace std;
#define size 6 //事先声明排序数据的个数
class bubble {
public:
int data[size];
void showresult(){
for (int i = 0; i < size; i++)
cout << setw(2) << data[i];
cout << endl;
}
void bubble_start() {
for (int i = 5; i > 0; i--) //扫描次数n-1,n为6个数据元素,则扫描次数为5
{
for (int j = 0; j < i; j++) //每次扫描需要比较、交换的次数
{
if (data[j] > data[j + 1]) //相邻比较
{
int temp;
temp = data[j];
data[j] = data[j + 1];
data[j + 1] = temp;
}
}
cout << "第" << size-i << "次扫描:";
showresult();
}
}
};
void text()
{
bubble b;
cout << "请输入要排序的"<<size<<"个数据"<< endl;
for (int i = 0; i < size; i++)
cin>>b.data[i];
cout << "排序前:" << endl;
b.showresult();
b.bubble_start();
cout << "排序后:" << endl;
b.showresult();
}
int main()
{
text();
}
③结果展示:
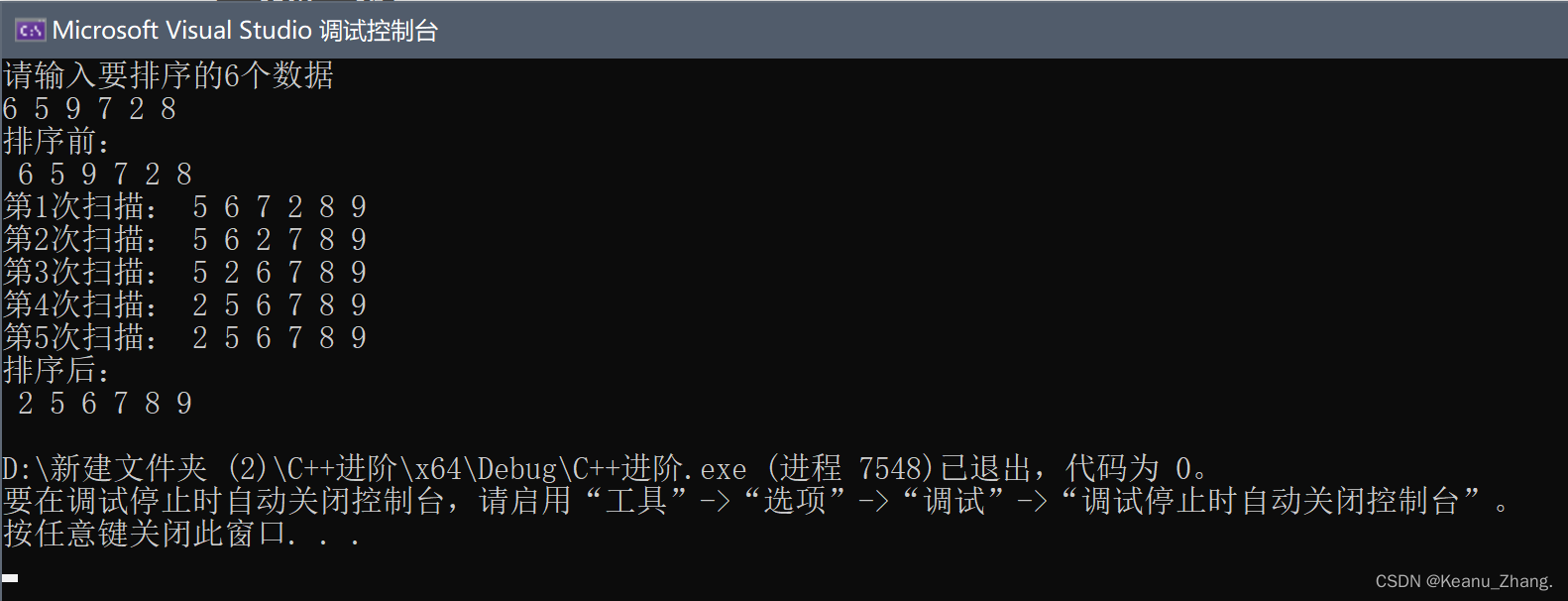
2.案例二
①范例情况:从案例一中我们可以看出冒泡排序法有一个缺点,就是它无论数据是否排序完成它的数据比较都会固定执行n(n-1)/2次,这样可能会造成程序不能以最优时间效率执行。所以我们在程序中加入一些条件和判断语句来判断是否可以结束排序,这样不光得到了正确的排序效果还可以提高程序的效率。利用优化的冒泡排序法对4、6、2、7、8、9这6个数据进行排序。 ②代码展示:
#include<iostream>
#include<iomanip>
using namespace std;
#define size 6 //事先声明排序数据的个数
class bubble {
public:
int data[size];
void showresult(){
for (int i = 0; i < size; i++)
cout << setw(2) << data[i];
cout << endl;
}
void bubble_start() {
for (int i = 5; i > 0; i--) //扫描次数n-1,n为6个数据元素,则扫描次数为5
{
int flag = 0; //定义一个标志
for (int j = 0; j < i; j++) //每次扫描需要比较、交换的次数
{
if (data[j] > data[j + 1]) //相邻比较
{
int temp;
temp = data[j];
data[j] = data[j + 1];
data[j + 1] = temp;
flag = 1;
}
}
if (flag == 0) //如果flag没变,说明没进行交换,则根本不需要输出这次的
break;
cout << "第" << size-i << "次扫描:";
showresult();
}
}
};
void text()
{
bubble b;
cout << "请输入要排序的"<<size<<"个数据"<< endl;
for (int i = 0; i < size; i++)
cin>>b.data[i];
cout << "排序前:" << endl;
b.showresult();
b.bubble_start();
cout << "排序后:" << endl;
b.showresult();
}
int main()
{
text();
}
③结果展示:
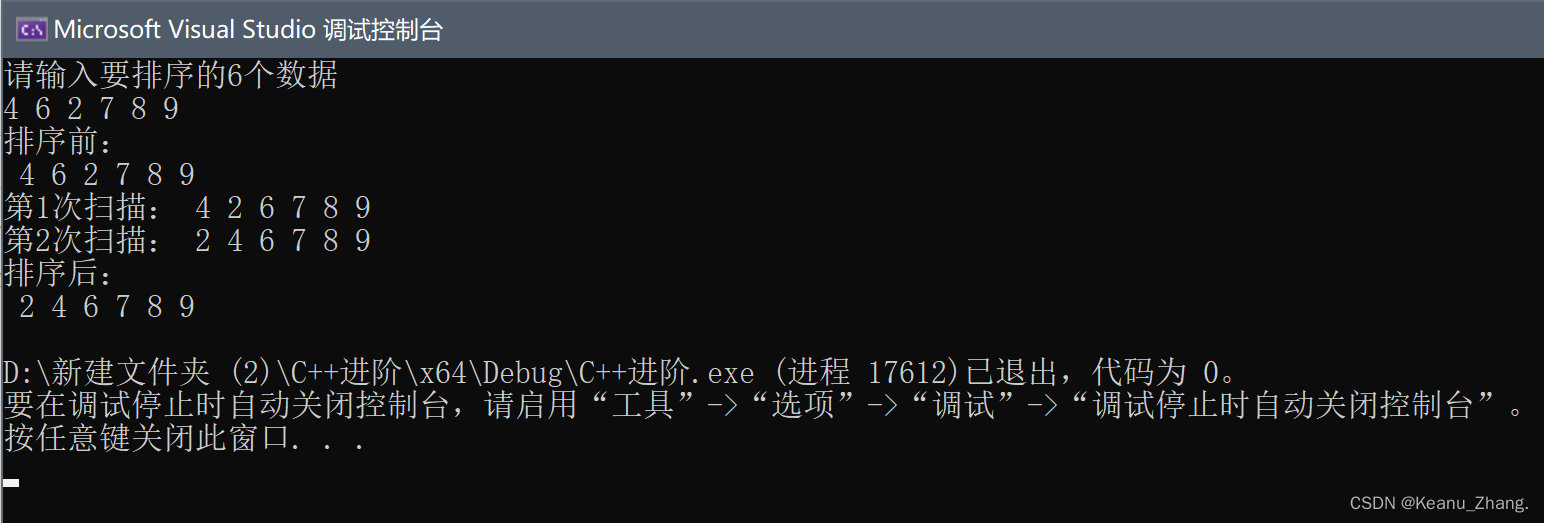
总结
以上就是冒泡排序法的内容,算法它更让我们体会的是一种计算机编程的思想,让我们在面对不同的问题时可以充分的利用算法去解决我们所需要解决的问题。程序=算法+数据结构,所以我们可以看的出算法的重要性。对于不同的排序算法,它们在计算机不同的领域都发挥着各自的作用,熟悉了解各种排序算法并且将它们充分合理的与其他算法结合运用。那么我相信我们可以在代码的这条路上走得更高更远。
<您的三连和关注是我最大的动力> 🚀 文章作者:Keanu Zhang 分类专栏:算法之美(C++系列文章)
