yarn默认只管理内存资源,虽然也可以申请cpu资源,但是在没有cpu资源隔离的情况下效果并不是太好.在集群规模大,任务多时资源竞争的问题尤为严重.
还好yarn提供的LinuxContainerExecutor可以通过cgroup来隔离cpu资源
微信排版一直很蛋疼,我虽然全部代码配置转化为图片,但是也可能有遗漏。大家如果想跟着步骤做,建议访问原文链接。
cgroup
cgroup是系统提供的资源隔离功能,可以隔离系统的多种类型的资源,yarn只用来隔离cpu资源
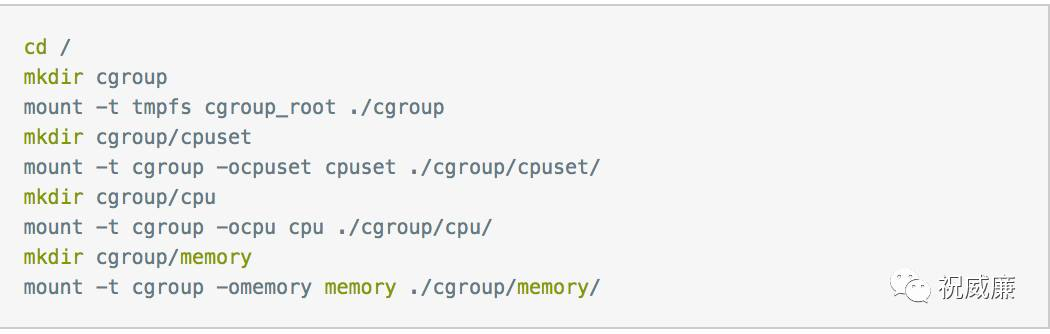
安装cgroup
默认系统已经安装了cgroup了,如果没有安装可以通过命令安装

然后通过命令启动

查看/cgroup目录,可以看到里面已经创建了一些目录,这些目录就是可以隔离的资源

如果目录没有创建可以执行
通过cgroup隔离cpu资源的步骤为
- 在cpu目录创建分组
cgroup以组为单位隔离资源,同一个组可以使用的资源相同
一个组在cgroup里面体现为一个文件夹,创建分组直接使用mkdir命令即可.
组下面还可以创建下级组.最终可以形成一个树形结构来完成复杂的资源隔离方案.
每当创建了一个组,系统会自动在目录立即创建一些文件,资源控制主要就是通过配置这些文件来完成
- yarn默认使用
hadoop-yarn组作为最上层,任务运行时yarn会为每个container在hadoop-yarn里面创建一个组
yarn主要使用cpu.cfs_quota_us cpu.cfs_period_us cpu.shares3个文件
yarn使用cgroup的两种方式来控制cpu资源分配
- 严格按核数隔离资源
可使用核数 = cpu.cfs_quota_us/cpu.cfs_period_us
在yarn中cpu.cfs_quota_us被直接设置为1000000(这个参数可以设置的最大值)
然后根据任务申请的core来计算出cpu.cfs_period_us - 按比例隔离资源
按每个分组里面cpu.shares的比率来分配cpu
比如A B C三个分组,cpu.shares分别设置为1024 1024 2048,那么他们可以使用的cpu比率为1:1:2
- 将进程id添加到指定组的tasks文件
创建完分组后只需要将要限制的进程的id写入tasks文件即可,如果需要解除限制,在tasks文件删除即可
yarn配置
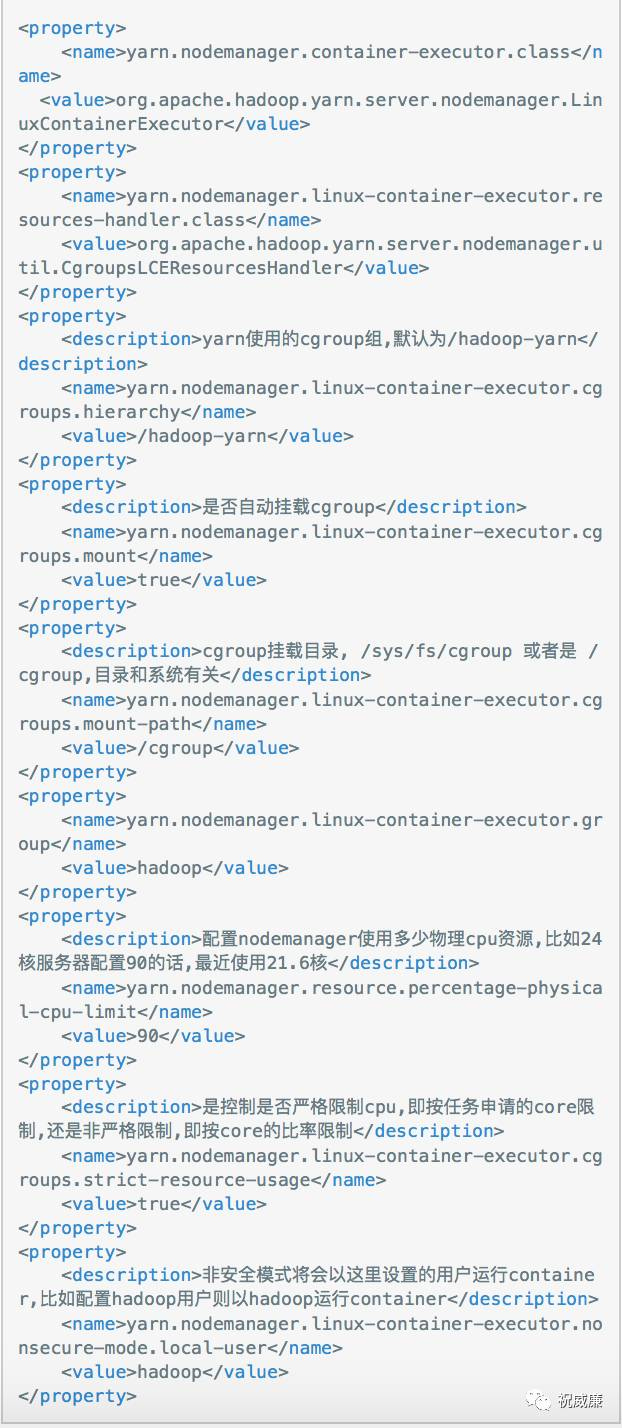
启动cgroup需要配置几个配置文件
etc/hadoop/yarn-site.xml配置
可以参考http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/NodeManagerCgroups.html 配置
这些配置大部分都是固定配置
etc/hadoop/container-executor.cfg配置
这个配置文件每项都需要填,要不然会报错

权限设置
在配置中文件的权限有特殊要求

系统还要求etc/hadoop/container-executor.cfg 的所有父目录(一直到/ 目录) owner 都为 root
这个路径是默认${HADOOP_HOME}/etc/hadoop/container-executor.cfg,如果不方便修改所有父级目录为root权限,可以重新编译代码到其他目录,比如/etc/hadoop/目录

配置好以后检测是否配置成功

如果没有任何输出表示配置成功
如果一切顺利就可以启动集群了
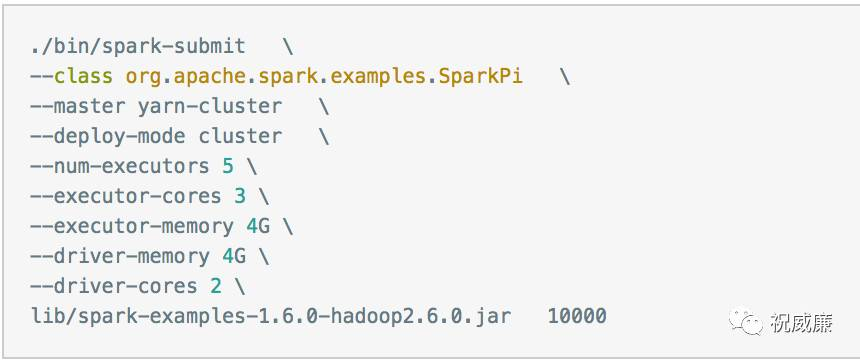
测试cgroup
可以运行测试脚本测试系统
查看系统是否生效只能登录到服务器查看
通过top查看信息

查看是否创建了cgroup分组,ll /cgroup/hadoop-yarn/
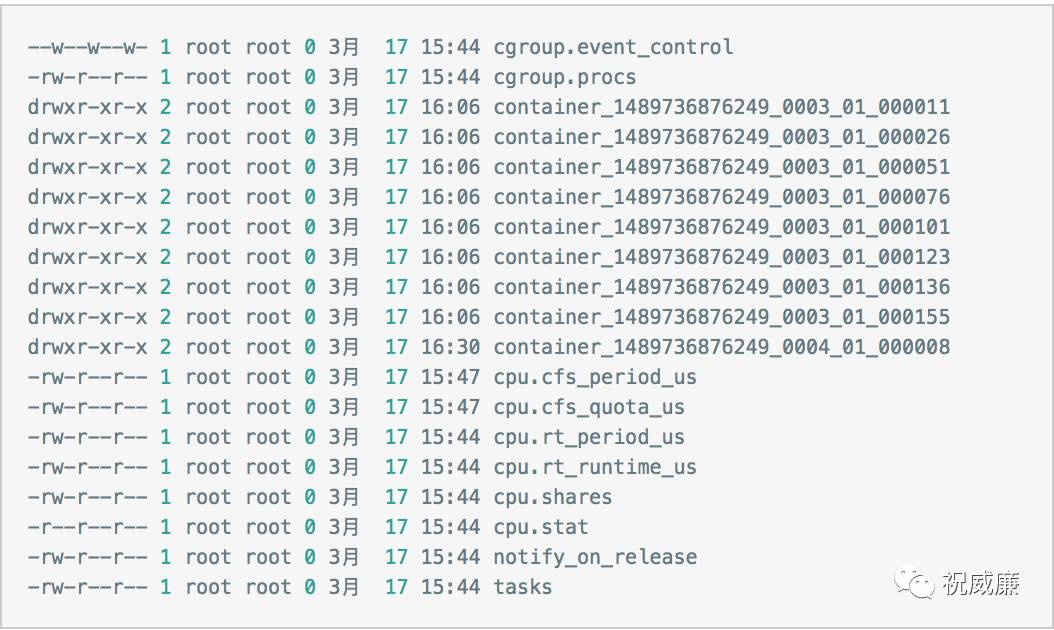
查看container_*目录下 cpu.cfs_period_us,计算cpu.cfs_quota_us/cpu.cfs_period_us即可知道分配的核数
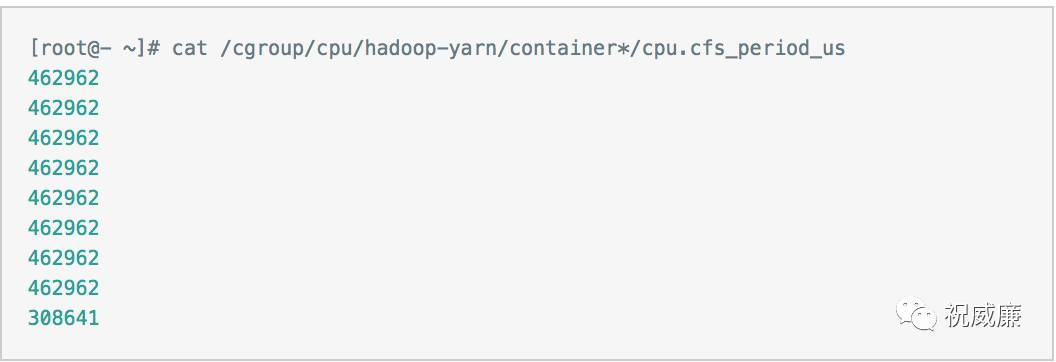
问题处理
配置的过程中免不了会碰上一些问题,以下是我碰到的问题
spark任务申请了core,node manager分配不正确,都是分配1个核
这个是由于目前使用的capacity scheduler的资源计算方式只考虑了内存,没有考虑CPU
这种方式会导致资源使用情况统计不准确,比如一个saprk程序启动命令资源参数如下

DefaultResourceCalculator 统计占2核
DominantResourceCalculator 统计占4核
修改配置文件即可解决

container-executor运行时报缺少GLIBC_2.14库

这个和系统版本有关,只能通过重新编译container-executor来解决

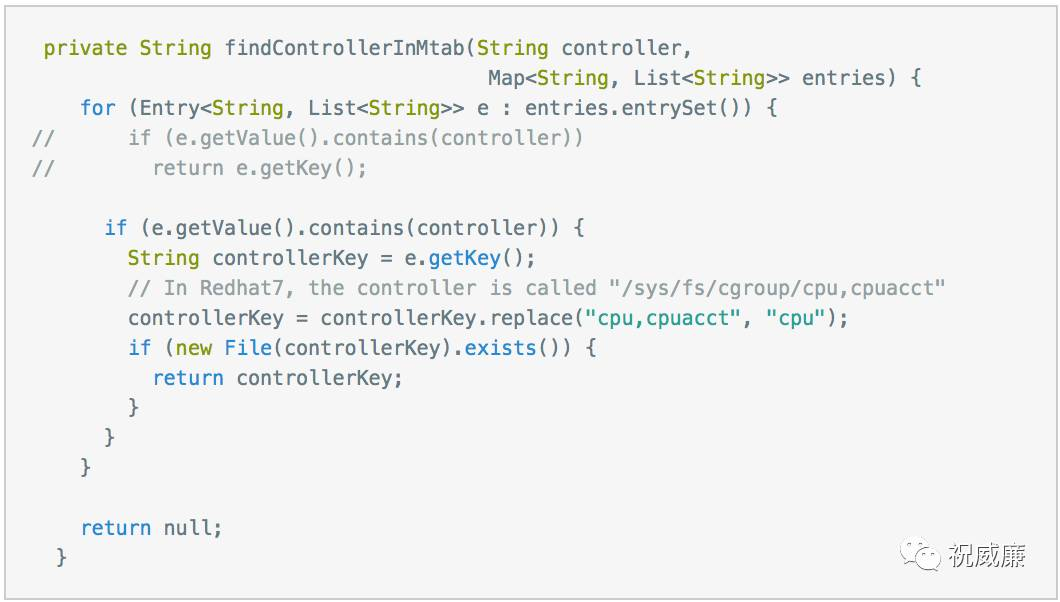
centos 7系统container启动报错,不能写入/cgroup/cpu
这个是yarn在centos 7下的一个bug,hadoop 2.8以后的版本才会解决
这个bug主要是因为centos 7下cgroup的目录和centos 6不一致导致,centos 7 cpu目录合并成cpu,cpuacct, 这个,导致的错误,需要打补丁后编译 https://issues.apache.org/jira/browse/YARN-2194
升级的风险
由于改变了资源的隔离方式,升级可能有几个方面的影响
任务资源分配问题
升级cgroup后单个任务如果以前资源分配不合理可能会出现计算延时情况,出现资源问题时需要调整任务资源
在集群规模小的时候可能没有资源可以调整,那么可以修改为非严格模式,非严格模式不能按配置限制资源,只能保证资源不被少数进程全部占用

spark driver资源问题
spark任务的driver在集群模式deploy-mode cluster时,如果没有配置driver-cores的话默认分配1核,1核在任务规模大时有可能资源会紧张.采用deploy-mode client模式的不受cgroup限制
