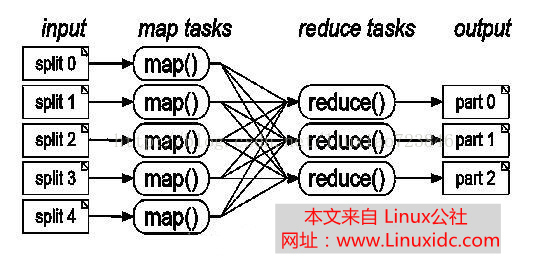
mapreduce作业会根据输入目录产生多个map任务, 通过多个map任务并行执行来提高作业运行速度, 但如果map数量过少, 并行量低, 作业执行慢,;如果map数过多, 资源有限, 也会增加调度开销. 因此, 根据输入产生合理的map数,为每个map分配合适的数据量, 能有效的提升资源利用率, 并使作业运行速度加快.
InputFormat这个类是用来处理Map的输入数据的,任务开始时,InputFormat先将HDFS里所有输入文件里的数据分割成逻辑上的InputSpilt对象。这里的split是HDFS中block的部分或者一整块或几个快中的数据的逻辑分割,一个split对应于一个Map,所以Map的数量是由split的数量决定的。
假设put一个160M的文件到HDFS上,blockSize为默认的64M,那么该文件在HDFS上会分成3个block保存。mapper的数量是由输入的分片决定的。默认情况下输入的分片和block的数量一样,计算公式为:splitSiz=Math.max(minSize,Math.min(maxSize,blockSize));
mapred.min.split.size设置minSize,mapred.max.split.size设置maxSize,minSize默认为1,maxSize默认为Long.MAX_VALUE?
所以默认情况下用该文件作为mapreduce的输入文件的话,160/64=3,会生成3个mapper用来处理输入。
按照这个公式,若想减少分片的数量,那么可以增大minSize,比如将minSize改为80,160/80=2,只会产生2个分片即两个map.
若想增加分片的数量,那么可以减小maxSize,比如将maxSize改为32,160/32=6,产生6个分片即6个map.
每个文件是单独分片的,比如两个文件一个65M,一个129M,第一个文件默认分成了64,1,第二个分成64,64,1,剩下的第一个文件的1M碎片和第二个文件的1M碎片再合并成一个分片,总共4个分片即4个map.
一个job的总map数量是可以控制的,每个节点上的map数量也是可以控制的.
简单来讲就是切分的原则是splitSize不会小于minSize,不会大于maxSize,如果blockSize能够满足以上要求就取blockSize,如果不能的话就在maxSize和minSize中取值










