参考自https://github.com/ildoonet/pytorch-gradual-warmup-lr/blob/master/warmup_scheduler/scheduler.py
对其中的个别小bug进行了改动
所谓预热学习率调整机制, 就是在训练初期把学习率放的很低, 让模型可以先缓慢摸索,过程中逐渐提升学习率到正常的值
等把学习率提升到预定值后, 开始正常的阶梯下降, 或指数下降, 余弦退火, 自适应下降等
很遗憾pytorch目前还没有提供预热机制的官方接口, 接下来提供一个基于pytorch实现的预热机制代码, 可以先预热,再使用正常的学习率调整策略
基于上述链接改动后的预热机制代码如下:
WarmupLrScheduler.py
from torch.optim.lr_scheduler import _LRScheduler
from torch.optim.lr_scheduler import ReduceLROnPlateau
class GradualWarmupScheduler(_LRScheduler):
""" Gradually warm-up(increasing) learning rate in optimizer.
Proposed in 'Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour'.
在optimizer中会设置一个基础学习率base lr,
当multiplier>1时,预热机制会在total_epoch内把学习率从base lr逐渐增加到multiplier*base lr,再接着开始正常的scheduler
当multiplier==1.0时,预热机制会在total_epoch内把学习率从0逐渐增加到base lr,再接着开始正常的scheduler
Args:
optimizer (Optimizer): Wrapped optimizer.
multiplier: target learning rate = base lr * multiplier if multiplier > 1.0. if multiplier = 1.0, lr starts from 0 and ends up with the base_lr.
total_epoch: target learning rate is reached at total_epoch, gradually
after_scheduler: after target_epoch, use this scheduler(eg. ReduceLROnPlateau)
"""
def __init__(self, optimizer, multiplier, total_epoch, after_scheduler=None):
self.multiplier = multiplier
if self.multiplier < 1.:
raise ValueError('multiplier should be greater thant or equal to 1.')
self.total_epoch = total_epoch
self.after_scheduler = after_scheduler
self.finished = False
super(GradualWarmupScheduler, self).__init__(optimizer)
def get_lr(self):
if self.last_epoch > self.total_epoch:
if self.after_scheduler and (not self.finished):
self.after_scheduler.base_lrs = [base_lr * self.multiplier for base_lr in self.base_lrs]
self.finished = True
# !这是很关键的一个环节,需要直接返回新的base-lr
return [base_lr for base_lr in self.after_scheduler.base_lrs]
if self.multiplier == 1.0:
return [base_lr * (float(self.last_epoch) / self.total_epoch) for base_lr in self.base_lrs]
else:
return [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs]
def step_ReduceLROnPlateau(self, metrics, epoch=None):
if epoch is None:
epoch = self.last_epoch + 1
self.last_epoch = epoch if epoch != 0 else 1 # ReduceLROnPlateau is called at the end of epoch, whereas others are called at beginning
print('warmuping...')
if self.last_epoch <= self.total_epoch:
warmup_lr=None
if self.multiplier == 1.0:
warmup_lr = [base_lr * (float(self.last_epoch) / self.total_epoch) for base_lr in self.base_lrs]
else:
warmup_lr = [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs]
for param_group, lr in zip(self.optimizer.param_groups, warmup_lr):
param_group['lr'] = lr
else:
if epoch is None:
self.after_scheduler.step(metrics, None)
else:
self.after_scheduler.step(metrics,epoch - self.total_epoch)
def step(self, epoch=None, metrics=None):
if type(self.after_scheduler) != ReduceLROnPlateau:
if self.finished and self.after_scheduler:
if epoch is None:
self.after_scheduler.step(None)
else:
self.after_scheduler.step(epoch - self.total_epoch)
self._last_lr = self.after_scheduler.get_last_lr()
else:
return super(GradualWarmupScheduler, self).step(epoch)
else:
self.step_ReduceLROnPlateau(metrics, epoch)
主函数中调用:
from WarmupLrScheduler import GradualWarmupScheduler
...
#! 以下为阶梯下降, 自适应下降, 余弦退火热重启三种调整策略, 只演示后两种的用法
# exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft,step_size=4,gamma=0.8)
# exp_lr_scheduler=lr_scheduler.ReduceLROnPlateau(optimizer_ft,mode='min',factor=0.8,patience=5,verbose=False)
# exp_lr_scheduler=lr_scheduler.CosineAnnealingWarmRestarts(optimizer_ft,T_0=15,T_mult=2)
#! 自适应下降用法演示
optimizer_ft = optim.Adam(filter(lambda param: param.requires_grad == True,model.parameters()),lr=5e-3)
exp_lr_scheduler=lr_scheduler.ReduceLROnPlateau(optimizer_ft,mode='min',factor=0.8,patience=5,verbose=False)
my_lr_scheduler=GradualWarmupScheduler(optimizer_ft, multiplier=1.0, total_epoch=10, after_scheduler=exp_lr_scheduler)
model = train_model(model, optimizer_ft, my_lr_scheduler, num_epochs=225)
...
# 训练时,每个epoch结束后获取验证集loss
scheduler.step(metrics=loss)
#! 余弦退火热重启演示
exp_lr_scheduler=lr_scheduler.CosineAnnealingWarmRestarts(optimizer_ft,T_0=15,T_mult=2)
my_lr_scheduler=GradualWarmupScheduler(optimizer_ft, multiplier=2, total_epoch=5, after_scheduler=exp_lr_scheduler)
model = train_model(model, optimizer_ft, my_lr_scheduler, num_epochs=225)
# 训练时,每个epoch结束后
scheduler.step()
可视化效果展示
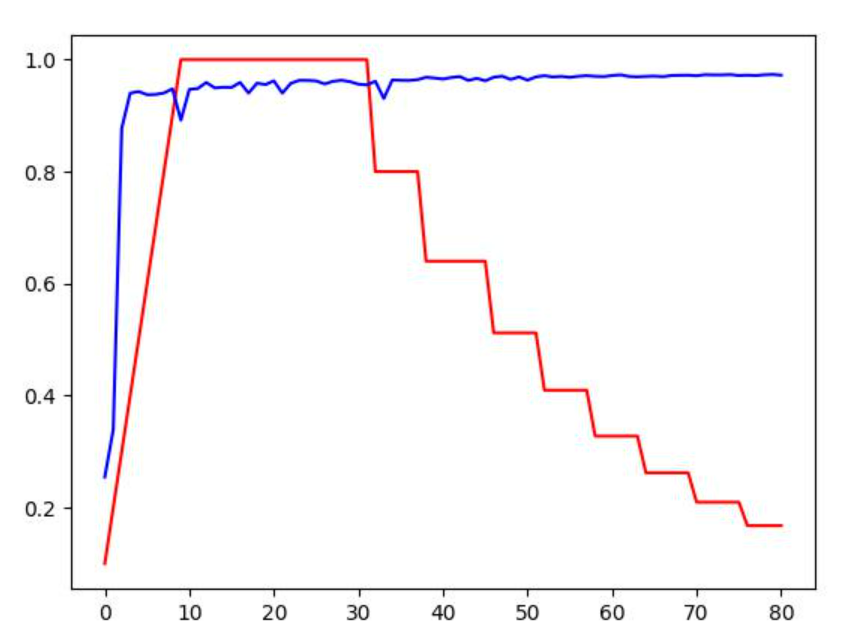
预热+自适应下降的效果, 蓝色为dice, 红色是学习率
预热+余弦退火热重启效果,蓝色为dice, 红色是学习率
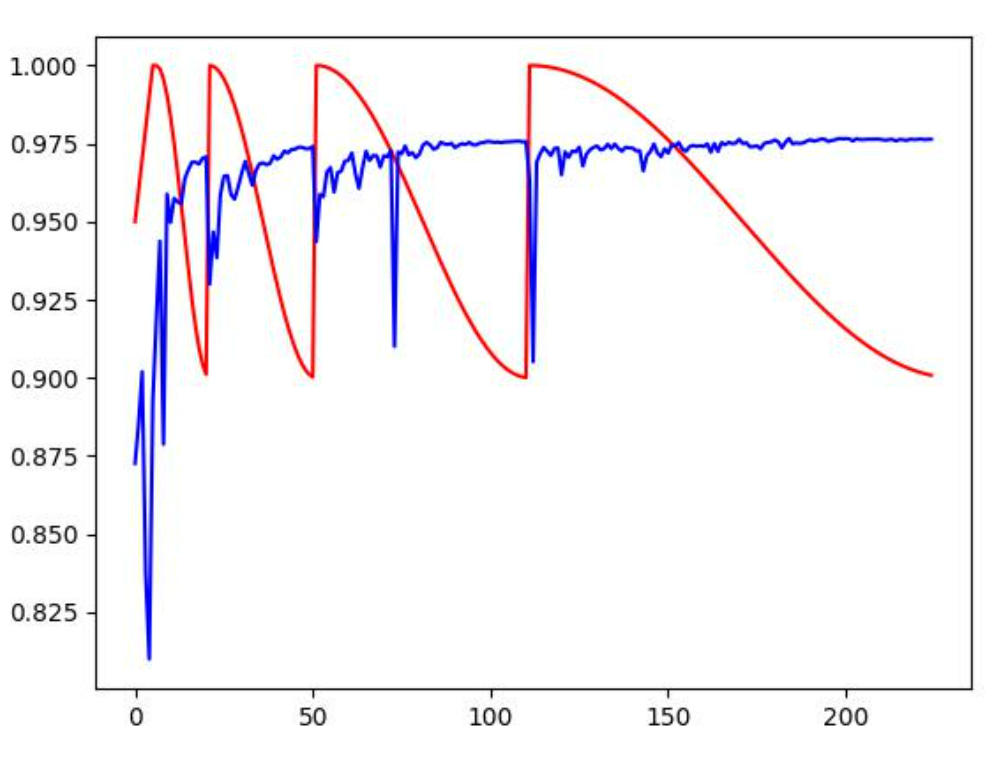
不同的数据集、网络有不同的效果, 对于此数据集,我更青睐于自适应下降







