前言:Hadoop1.0、Hadoop2.0核心组件及其区别
Hadoop1.0
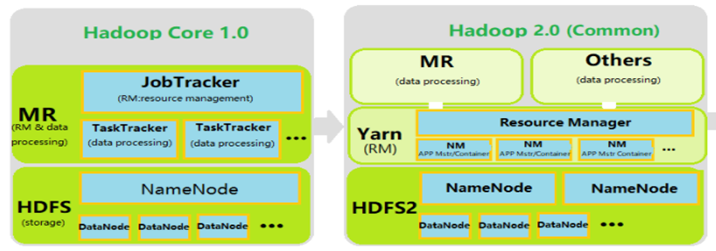
核心组件
- HDFS 1.0:单个NameNode、单个Secondary NameNode、多个DataNode
- MapReduce 1.0
Hadoop1.0的问题
-
单点故障
只有一个NameNode,所有元数据由唯一的NameNode负责管理。如果该NameNode失效,则任何与集群有关的历史操作都将失效,整个集群也就处于基本不可用状态。
-
水平扩展性差
元数据存储在NameNode的内存中,因此集群规模受限于单个NameNode的内存大小
-
MapReduce1.0扩展性差、低可靠性、资源利用率低、无法执行非MapReduce任务无法支持多种计算框架
-
在MRv1中,JobTracker同时兼备了集群资源的管理和作业的调度与控制两大功能,使得JobTracker负载过重,增加了JobTracker失效的风险,造成Hadoop集群的扩展性差和低可靠性
MRv1采用了基于槽位(slot)的资源分配模型,需要为map任务和reduce任务预先配置tasktracker槽位,当一个任务用不完槽位对应的所有资源其他任务也无法使用,而且为map任务保留的slot无法用于reduce任务,这造成资源利用率低
MRv1中资源管理器JobTracker、TaskTracker耦合高,导致MRv1无法执行非MapReduce任务
Hadoop2.0
核心组件
-
HDFS2.0:双NameNode(Active NameNode、Standby NameNode)、DataNode
HDFS2.0中存在两个NameNode,为区分两者,将主NameNode称为Active NameNode,将备用NameNode称为Standy NameNode。两者通过Journal Node实现元数据同步。 -
YARN(MapReduce2.0)
Hadoop1.0与Hadoop2.0对比
HDFS角度
Hadoop2.0增加了HDFS HA(高可用)机制,解决了HDFS 1.0中的单点故障问题,通过HA进行Standby NameNode的热备份。
Hadoop2.0增加了HDFS Federation(联邦)水平扩展,支持多个NameNode同时运行,每一个NameNode分管一批目录,然后共享所有DataNode的存储资源,从而解决1.0当中单个NameNode节点内存受限问题。
MapReduce角度
在Hadoop2.0当中增加了YARN框架,针对hadoop1.0中主JobTracker压力太大的不足,把JobTracker资源分配和作业控制分开,利用Resource Manager在NameNode上进行资源管理调度,利用ApplicationMaster进行任务管理和任务监控。由NodeManager替代TaskTracker进行具体任务的执行,因此MapReduce2.0只是一个计算框架。对比hadoop1.0中相关资源的调用全部给Yarn框架管理。
Hadoop3.0
Hadoop2.0之后版本就相对稳定,大部分实际生产环境中都使用的是2.0,Hadoop3.0主要增加了一些性能上的优化和支持:
- java运行环境升级为1.8,对低版本的java不再支持
- HDFS3.0支持数据的擦除编码,调高存储空间的使用率
- 一些默认端口的改变
- 增加一些MapReduce的调优
的java不再支持
2. HDFS3.0支持数据的擦除编码,调高存储空间的使用率
3. 一些默认端口的改变
4. 增加一些MapReduce的调优










